不可不知小技巧|Triton-TLE实践,告别手动Barrier,用生产消费模型释放Hopper架构算力极限
在大模型推理的长文本场景里,SparseMLA 已经成了 DeepSeek 系列模型的核心性能卡点。它对每个 query 只访问 TopK 个最相关的 KV token,从而大幅减少 Attention 的计算量。但它的优化难度堪称 “硬骨头”:稀疏索引导致 KV 访问不连续、主维度 512 太宽,寄存器和共享内存很容易撞墙,手写同步屏障更是让人头大。
今天,我们要用Triton-TLE,带你告别手动 barrier,把 SparseMLA 性能拉到 FlashMLA 的 90%,全程只用 Triton 语法,不用碰 CUDA。
SparseMLA 是什么,为什么难优化?
SparseMLA 是 DeepSeek 模型的核心算子,针对每个 query,仅访问TopK 个最相关 KV token,计算逻辑拆分为两段:
-
主维度
D = 512:q_main @ k_main -
尾部维度
TD = 64:q_tail @ k_tail -
最终 score =
q_main @ k_main + q_tail @ k_tail,输出仍然是softmax(score) @ v。
SparseMLA的优化,主要有三大痛点:访存不友好,稀疏 indices 导致 KV gather 不连续,对 global memory 的访问很不友好;资源冲突,D=512 宽维度下,单个 warp group 同时承担 QK 计算与 PV 计算,寄存器、共享内存、同步操作相互挤占;同步复杂,跨 warp-group 协作需要精细的屏障控制,手动编写 mbarrier 极易出错,需反复查阅 PTX 手册。
朴素实现:SparseMLA 在 Triton 中怎么写?
在深入优化之前,我们先理解朴素实现是怎么写的,这是后续所有优化的起点。
先明确 kernel 的形状,所有后续优化都建立在同一个数据布局上:
-
Query:
q: [B, SQ, H, DQK] -
KV:
kv: [B, SKV, HKV, DQK],这里DQK = DV + TD = 512 + 64 = 576 -
TopK indices:
indices: [B, SQ, HKV, topk]
为什么 DQK=576? 因为 DeepSeek 的设计把 KV 缓存分成两部分:主维度 512 用于主要的注意力计算,尾部 64 用于补充细节信息,两者拼接起来就是 576。
对于 prefill 场景(B=1, S=4096),每一个 query head block 要处理 topk=2048 个 KV token。朴素 Triton 的做法是把 topk 按 BK=64 的 tile 逐个遍历,每个 tile 做四件事:
-
根据 indices 从 global 中 gather 出
kv_main和kv_tail -
计算
qk = q_tail @ tkv_tail^T + q_main @ kv_main^T -
online softmax 更新
max_prev / sum_exp / acc -
累积
acc = softmax(score) @ kv_main
核心循环大致如下:
NK = tl.cdiv(topk_len, BK) for ck in tl.range(NK, num_stages=2): t_ptr = BK * ck + offs_t kv_ids = tl.load(t_base + t_ptr, t_ptr < topk_len, other=-1) mask_ids = (kv_ids <= max_col) & (kv_ids >= 0) kv_blk = tl.load(kv_base + kv_ids[:, None] * stride_kvn + offs_d[None, :], mask_ids[:, None] & mask_d[None, :], other=0.0) tkv_blk = tl.load(tkv_base + kv_ids[:, None] * stride_kvn + offs_td[None, :], mask_ids[:, None] & mask_td[None, :], other=0.0) qk = tl.full([BH, BK], 0.0, dtype=tl.float32) qk = tl.where(mask_ids[None, :], qk, float("-inf")) qk = tl.dot(tq_blk, tl.trans(tkv_blk), qk, out_dtype=tl.float32) qk = tl.dot(q_blk, tl.trans(kv_blk), qk, out_dtype=tl.float32) new_max = tl.maximum(max_prev, tl.max(qk, axis=1)) alpha = tl.math.exp2((max_prev - new_max) * log_scale) exp_qk = tl.math.exp2(qk * log_scale - new_max[:, None] * log_scale) sum_exp = sum_exp * alpha + tl.sum(exp_qk, axis=1) acc = tl.dot(exp_qk.to(tl.bfloat16), kv_blk, acc * alpha[:, None], out_dtype=tl.float32) max_prev = new_max这段代码的几个关键点需要解释一下:
-
q_blk和tq_blk在循环外只加载一次,但每个 K tile 都要重新 gatherkv_blk和tkv_blk。gather 访存模式本身已经拉了,再加上DQK=576的大宽度,一个 warp group 既要从 global 搬数,又要做两段矩阵乘,最后还要把 exp 后的结果再乘一遍kv_blk,寄存器压力极大。 -
qk不是完整的 attention matrix,而是[BH, BK]的小块,online softmax 靠max_prev和sum_exp把每个 tile 串起来。 -
num_stages=2给了两层软件流水,但因为 gather 和 compute 都挤在同一个 warp group 里,pipeline 的效果很有限。实测中这个朴素实现作为 reference 是正确且清晰的,但性能只能在 196 - 236 TFLOPS 徘徊。
朴素实现的问题在哪? 如果看共享存储的硬件利用情况,会发现:真正在干活的 cycle 大概只有一半,另一半都在等 memory。要继续提速,就得把"搬运"和"计算"拆给不同 warp group,同时让左右两半 V 并行消费同一份 softmax 概率。
优化思路:TileLang-Pipelined 的三泳道分工
为解决朴素实现的瓶颈,TileLang-Pipelined 重新组织了每个 CTA 内的执行分工,核心是拆分计算任务、分离数据搬运与计算:把 DV=512 拆成左右两半 DPH=256;Q 的三个部分 q_l、q_r 和 q_tail 只 staging 一次;三个 warp group 各司其职。
| 泳道 | 角色 | 每个 ck 的动作 |
| Producer WG | KV staging | acquire kv[ck] -> load indices -> load kv_l / kv_r / tkv / valid -> commit kv[ck] |
| Left Consumer WG | QK + softmax + 左半 PV | wait q -> wait kv[ck] -> q_tail@tkv + q_l@kv_l + q_r@kv_r -> online softmax -> acc_l += P@kv_l -> commit score[ck] |
| Right Consumer WG | 右半 PV | wait q -> wait kv[ck] -> wait score[ck] -> acc_r = acc_r*alpha + P@kv_r -> release |
这个设计为什么聪明? 一个 K tile 的两个半区(kv_l 和 kv_r)由 producer 一块儿准备好,left consumer 完整地算 QK 和 softmax,然后自己只用左半 V 做 PV;右半 V 的 PV 则交给 right consumer,它复用的是 left consumer 产出的 prob 和 alpha / sum_exp。这样 left consumer 的负担减轻了一半,原本闲置的 warp 也有了工作(right consumer),两份 PV 计算可以并行进行。
但也有一定代价。 引入了显式的 score_pipe,左 consumer 要 commit probability/alpha,右 consumer 要 wait 后才开始累加自己的输出。这种跨 warp-group 的生产消费关系,用常规 Triton 是无法实现的。TileLang 版本用显式 shared memory + barrier 把它实现出来了,把 Triton baseline 从 200 TFLOPS 拉到 327 - 430 TFLOPS。
接下来要解决的问题是:能不能用更少的同步心智,在 Triton 里重新表达这套 producer / consumer 流水?这就是 Triton-TLE 要补的那块拼图。
Triton-TLE 是什么?如何用 TLE-Pipe 复刻上述流水线?
TLE(Triton Language Extensions) 不是一个新的 DSL。你不用放弃熟悉的 tl.arange、tl.load、tl.dot。它补的是一层结构化编排能力,让你不用写 CUDA,就能把上面那种复杂的 warp-specialized 数据流直接写成可维护的 Triton 代码。
尤其是在写 WASP / warp-specialized pipeline 时,你只需要声明不同 warp group 之间的生产-消费关系。至于每个 mbarrier 需要多少 arrive_count、cp.async 的 arrive/commit/wait_group 该怎么插入,编译器会从 pipe 的读写语义自动推导。这对写过手写同步的人意味着:再也不用翻 PTX 手册配平屏障了。
对开发者来说,最重要的两个 API 是:
-
tle.pipe(...)—— 定义 CTA 内的一条数据流边,支持 SPSC / SPMC,payload 是 shared memory buffered tensor。写端用acquire / commit,读端用wait / release。每一个 pipe 同时是编译器推导 arrive / wait 关系的源级契约。 -
tle.gpu.warp_specialize(...)—— 把一个 kernel 中的不同 JIT 函数分配到不同的 warp partition,可以指定每个 partition 的 warp 数和 requested registers。
那么,如何用 TLE-Pipe 复刻 TileLang-Pipelined?在 TLE-Pipe 实现里,我们直接把上文 TileLang-Pipelined 的数据流映射成三个 pipe 和三个 warp specialized 函数:
q_pipe = tle.pipe(
capacity=1, scope="cta", name="sparse_mla_q",
readers=("left", "right"), one_shot=True,
q_l=q_l_smem, q_r=q_r_smem, q_tail=q_tail_smem,)
kv_pipe = tle.pipe(
capacity=PIPE_CAPACITY, scope="cta", name="sparse_mla_kv",
readers=("left", "right"),
kv_l=kv_l_pipe_smem, kv_r=kv_r_pipe_smem,
tkv=tkv_pipe_smem, valid=valid_pipe_smem,)
score_pipe = tle.pipe(
capacity=1, scope="cta", name="sparse_mla_score",
alpha=score_alpha_smem, sum_exp=score_sum_exp_smem,)
tle.gpu.warp_specialize(
[
(_tle_pipe_sparse_mla_producer, (...)),
(_tle_pipe_sparse_mla_left_consumer, (...)),
(_tle_pipe_sparse_mla_right_consumer, (...)),
],
[4, 4],
[240, 168],)这段配置有几个关键点:
-
kv_pipe是一个 SPMC 管道,left 和 right consumer 都会等待同一个 KV tile。但 right reader 只取kv_r字段,避免传递不需要的kv_l,shared memory 不至于被无用的数据填满。 -
score_pipe只传alpha和sum_exp,概率prob本身放在一个单独的 shared buffer 里,走另一个路径。这样 TLE 编译器可以只针对 pipe fields 生成读端和写端的 mbarrier,而不是把整个 buffer 打包交给一个粗粒度的 barrier。 -
warp_specialize中 producer 是 default partition,两个 consumer 是 worker,各自的 warp 数和寄存器预算也直接写在了参数里。这比自己去数launch_bounds要省心得多。
程序员写的只是谁生产什么、谁消费什么、什么时候 commit。下层的 lowering 负责把 pipe 展开成 NVWS / mbarrier / barrier 序列。你不需要手算 arrive_count,也不需要担心 cp.async.arrive 和 mbarrier.arrive 的配平问题。
再看 producer / consumer 里面真正的 pipe API。下面是删掉地址计算后的核心结构:
@triton.jit
def _tle_pipe_sparse_mla_producer(kv_writer, kv_base, tkv_base, t_base, ...):
for ck in tl.range(NK):
# writer.acquire(ck) 取得这一轮可写的 shared-memory slot。
kv_slot = kv_writer.acquire(ck)
kv_l_smem_ptr = tle.gpu.local_ptr(kv_slot.kv_l)
kv_r_smem_ptr = tle.gpu.local_ptr(kv_slot.kv_r)
tkv_smem_ptr = tle.gpu.local_ptr(kv_slot.tkv)
valid_smem_ptr = tle.gpu.local_ptr(kv_slot.valid)
kv_ids = tl.load(t_base + BK * ck + offs_t, mask=t_msk, other=-1)
kv_l_blk = tl.load(kv_l_ptr, mask=kv_l_msk, other=0.0)
kv_r_blk = tl.load(kv_r_ptr, mask=kv_r_msk, other=0.0)
tkv_blk = tl.load(tkv_ptr, mask=tkv_msk, other=0.0)
tl.store(kv_l_smem_ptr, kv_l_blk, mask=kv_l_msk)
tl.store(kv_r_smem_ptr, kv_r_blk, mask=kv_r_msk)
tl.store(tkv_smem_ptr, tkv_blk, mask=tkv_msk)
tl.store(valid_smem_ptr, mask_ids.to(tl.int32))
# commit 后,等待这个 ck 的 reader 才能继续。
kv_writer.commit(ck)Left Consumer 的实现: 对 kv_pipe.reader("left") 调 wait,拿到 producer 刚 commit 的 slot;算完 QK、softmax 和左半输出后,再把右 consumer 需要的状态写入 score_pipe。
@triton.jit
def _tle_pipe_sparse_mla_left_consumer(q_reader, kv_left_reader,
score_writer, score_prob_smem, ...):
q_slot = q_reader.wait(0).slot
q_l = tl.load(tle.gpu.local_ptr(q_slot.q_l))
q_r = tl.load(tle.gpu.local_ptr(q_slot.q_r))
q_tail = tl.load(tle.gpu.local_ptr(q_slot.q_tail))
for ck in tl.range(NK):
kv_wait = kv_left_reader.wait(ck)
kv_slot = kv_wait.slot
kv_l = tl.load(tle.gpu.local_ptr(kv_slot.kv_l))
kv_r = tl.load(tle.gpu.local_ptr(kv_slot.kv_r))
tkv = tl.load(tle.gpu.local_ptr(kv_slot.tkv))
valid = tl.load(tle.gpu.local_ptr(kv_slot.valid)) != 0
qk = tl.dot(q_tail, tl.trans(tkv), out_dtype=tl.float32)
qk = tl.dot(q_l, tl.trans(kv_l), qk, out_dtype=tl.float32)
qk = tl.dot(q_r, tl.trans(kv_r), qk, out_dtype=tl.float32)
prob, alpha, sum_exp = online_softmax_update(qk, valid)
acc_l = tl.dot(prob, kv_l, acc_l, out_dtype=tl.float32)
score_slot = score_writer.acquire(ck)
tl.store(tle.gpu.local_ptr(score_slot.alpha), alpha)
tl.store(tle.gpu.local_ptr(score_slot.sum_exp), sum_exp)
tl.store(tle.gpu.local_ptr(score_prob_smem), prob)
score_writer.commit(ck)
# release 告诉 kv_pipe:left reader 已经不再使用这个 slot。
kv_left_reader.release(ck)Right Consumer 的实现:这里 kv_pipe.reader("right", fields=("kv_r",)) 会让编译器知道它只消费 kv_r,不需要把 kv_l/tkv/valid 也纳入这个 reader 的等待/可见性关系。
@triton.jit
def _tle_pipe_sparse_mla_right_consumer(q_reader, kv_right_reader,
score_reader, score_prob_smem, ...):
q_slot = q_reader.wait(0).slot
q_r_smem_ptr = tle.gpu.local_ptr(q_slot.q_r)
for ck in tl.range(NK):
kv_wait = kv_right_reader.wait(ck)
score_wait = score_reader.wait(ck)
kv_r = tl.load(tle.gpu.local_ptr(kv_wait.slot.kv_r))
prob = tl.load(tle.gpu.local_ptr(score_prob_smem))
alpha = tl.load(tle.gpu.local_ptr(score_wait.slot.alpha))
sum_exp = tl.load(tle.gpu.local_ptr(score_wait.slot.sum_exp))
acc_r = acc_r * alpha[:, None]
acc_r = tl.dot(prob, kv_r, acc_r, out_dtype=tl.float32)
score_reader.release(ck)
kv_right_reader.release(ck)
tl.store(q_r_smem_ptr, (acc_r / sum_exp[:, None]).to(OUT_DTYPE))这就是 TLE-Pipe 最核心的可读性。核心模式非常清晰,writer.acquire -> store payload -> writer.commit,consumer 侧 reader.wait -> load payload -> reader.release。同步语义就在这些 API 里,不需要在业务代码旁边手写一堆 barrier phase 和 arrive 数量。性能结果也证实了这种表达力的价值:
| SKV | Triton | TileLang-Pipelined | TLE-Pipe |
| 8192 | 236.1 | 430.1 | 483.5 |
| 32768 | 208.4 | 363.5 | 439.1 |
| 65536 | 200.5 | 340.3 | 407.7 |
| 98304 | 197.4 | 327.3 | 391.2 |
| 131072 | 196 | 327.1 | 381.7 |
TLE-Pipe 没有改变 SparseMLA 的任何数学步骤,只是把“加载 KV”和“两半输出计算”拆给了不同 warp group。结果它超过了 TileLang-Pipelined,并把 Triton baseline 从约 196 - 236 TFLOPS 推到了约 382 - 484 TFLOPS。
挑战升级:Triton-TLE用 TLE-FlashMLA 复刻 Seesaw 模式
如果说 TileLang-Pipelined 的优化是“把 PV 拆给两个 consumer”,那 FlashMLA phase1 做得更激进:每个 consumer 都参与 QK 计算,而且 K tile 成对处理,两个 consumer 做 seesaw。
一个 pair 包括 k0 和 k1,数据流大致如下:
FlashMLA seesaw 数据流
| 泳道 | 角色 | 关键块 |
| Producer | sparse gather / staging | ids0/ids1 -> K0L -> K1R+tail -> K0R+tail -> K1L -> valid |
| WG0 | K0 owner,left output owner | QK0 -> local max0 -> sM0 -> P0*K0L -> wait sM1 -> scale P0 -> sS0 -> wait sS1/K1L -> P1*K1L -> sum exchange -> O_l |
| WG1 | K1 owner,right output owner | QK1 -> wait sM0 -> max_next/sM1 -> P1*K1R -> sS1 -> wait sS0/K0R -> P0*K0R -> sum exchange -> O_r + lse |
这个设计和前面有什么不同? 不再是一个 consumer 负责完整 score 然后"施舍"给另一个;而是 QK 并行做,max 交叉合并,PV 两半交错吃。这极大提升了 compute 和 data movement 的重叠,但对应的同步网比 TileLang-Pipelined 复杂得多:sM、sS、sL 多条小管道在 pair 间交替使用。
用 TLE 写这个 seesaw,pipe 声明几乎就是数据流图的直接翻译:
k0_l_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sK0_l", sK=sK0_smem)
k0_r_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sK0_r",
readers=("qk", "remote"), sK=sK0_smem, sK_tail=sK0_tail_smem)
k1_l_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sK1_l",
readers=("qk", "remote"), sK=sK1_smem)
k1_r_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sK1_r",
sK=sK1_smem, sK_tail=sK1_tail_smem)
sM_wg0_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_wg0_bunch_0_ready", sM=sM_smem)
sM_wg1_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_wg1_bunch_0_ready", sM=sM_smem)
sS0_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sS0", sS0=sK0_tail_smem)
sS1_pipe = tle.pipe(capacity=1, scope="cta", name="flashmla_sS1", sS1=sS1_smem)warp specialization 的分配也体现了资源权衡:
tle.gpu.warp_specialize(
[
(_tle_flashmla_prefill_consumer0, (...)),
(_tle_flashmla_prefill_consumer1, (...)),
(_tle_flashmla_prefill_producer, (...)),
],
[4, 4],
[216, 72],)为什么给 producer 分配更少的寄存器? 这里第一个函数是 default partition,因此 consumer0 位于 default partition;producer 被放到最后一个 worker 并分配了较少的寄存器(72)。这是因为 producer 只负责稀疏 gather 和 staging,计算量远小于两个 consumer,把寄存器留给更需要的人。
seesaw 中的同步代码示例(WG0 发布 local max 然后等待合并后的 max_next):
# WG0: publish local max for k0
sM_wg0_slot = sM_wg0_writer.acquire(pair)
tl.store(tle.gpu.local_ptr(sM_wg0_slot.sM), local_max)
sM_wg0_writer.commit(pair)
sM_wg1_wait = sM_wg1_reader.wait(pair)
max_next = tl.load(tle.gpu.local_ptr(sM_wg1_wait.slot.sM))
final_scale = tl.math.exp2((local_max - max_next) * log_scale)
prob0_scaled = prob0 * final_scale[:, None]
WG1 的合并逻辑:
sM_wg0_wait = sM_wg0_reader.wait(pair)
candidate0 = tl.load(tle.gpu.local_ptr(sM_wg0_wait.slot.sM))
candidate1 = tl.maximum(max_prev, tl.max(qk1, axis=1))
max_next = tl.maximum(candidate1, candidate0)
sM_wg1_slot = sM_wg1_writer.acquire(pair)
tl.store(tle.gpu.local_ptr(sM_wg1_slot.sM), max_next)
sM_wg1_writer.commit(pair)注意: 不需要手动管理 mbarrier 的 arrive_count,也不用去数这个 barrier 究竟有几个 named reader。编译器从 pipe 的 readers 声明自动推导。
这个实现非常完整地证明了:FlashMLA 级别的 WG 协同数据流,可以在 Triton 中用结构化 pipe 表达出来。性能上,TLE-FlashMLA 把基线从 196 - 236 TFLOPS 推到 397 - 547 TFLOPS,大约达到手写 FlashMLA 的 0.77x - 0.90x:
| SKV | Triton | TLE-Pipe | TLE-FlashMLA | FlashMLA | TLE-FlashMLA / FlashMLA |
| 8192 | 236.1 | 483.5 | 546.8 | 606.9 | 0.90x |
| 32768 | 208.4 | 439.1 | 483.3 | 567.5 | 0.85x |
| 65536 | 200.5 | 407.7 | 440.4 | 537.4 | 0.82x |
| 98304 | 197.4 | 391.2 | 417.3 | 525.4 | 0.79x |
| 131072 | 196 | 381.7 | 396.9 | 515.3 | 0.77x |
TLE-FlashMLA 并不是“神奇地自动等于手写 CUDA FlashMLA”。它真正证明的是:FlashMLA 这类复杂 WG 数据流,可以在 Triton kernel 里用 TLE 的结构化 pipe 表达出来,且性能已经非常接近。对于不想常年抱着 CUDA 和 Hopper 手册的工程师来说,这条路径显著降低了尝试极致优化数据流 kernel 的门槛。
性能总览:各方案横向对比
理解了前面的优化路径后,我们再来看各方案的性能对比,就更有感觉了。
*测试条件:H800 平台,B=1, S=4096, H=128, HKV=1, DQK=576, DV=512, topk=2048,无 attn_sink
| 实现 | 主要优化手段 | CTA / 并行形态 | H800 TFLOPS |
| Triton baseline | 每 K tile 直接从 global gather KV/tail,两段 QK、online softmax、PV | 普通 Triton program,8 warps,2 stages | 196.0 - 236.1 |
| TileLang-Pipelined | 显式 shared memory staging,producer/consumer 分工,V 左右拆半,score pipe 供右半输出复用 | ~384 threads,3 个 WG | 327.1 - 430.1 |
| TileLang-Seesaw | 两个 consumer 分别处理偶/奇 K block,交换 max/prob/sum,左右半输出交错累加 | ~384 threads,producer + WG0/WG1 seesaw | 394.9 - 452.8 |
| TLE-Pipe | 用 tle.pipe + warp_specialize 复刻 TileLang-Pipelined 数据流 | producer + left consumer + right consumer | 381.7 - 483.5 |
| FlashMLA | phase1 seesaw:两条 consumer 分别处理 K0/K1,互换 max/prob/sum,重叠两半 V 的 PV | CUDA/Hopper 专用 | 515.3 - 606.9 |
| TLE-FlashMLA | 用多个 TLE pipe 复刻 FlashMLA prefill seesaw 数据流,producer-last low-reg 映射 | consumer0 + consumer1 + producer | 396.9 - 546.8 |
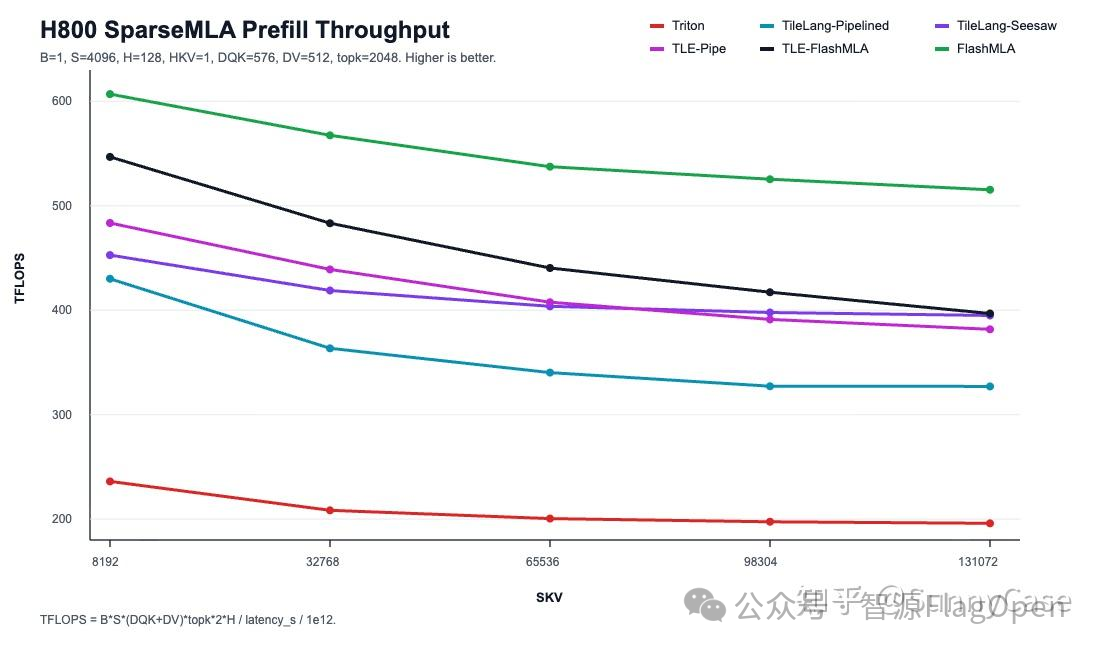
H800 SparseMLA Prefill Throughput
从图中可以直观看到:Triton baseline 在最长的 SKV 上只有约 196 TFLOPS;TLE-Pipe 拉到约 382 TFLOPS,接近 2x;TLE-FlashMLA 再推到最高 547 TFLOPS,大约已经摸到 FlashMLA 的 0.77x - 0.90x。虽然还没追上,但这是在 纯 Triton 语法下做到的,你不需要写一行 CUDA,就能获得接近极致优化的性能。
结语
回顾一下本文的优化路径,我们从一个朴素 Triton 实现出发,分析了 TileLang-Pipelined 的三泳道分工,把"搬运"和"计算"拆开;接着我们用 TLE-Pipe 复刻了这个数据流。
可以看到,SparseMLA 算法并不复杂,难的是让 sparse gather、QK、softmax 和 PV 在 Hopper 的 warp group 之间流起来。 没有合适的编排工具,开发者很容易在“先算哪一半、在哪同步”里踩坑。
TLE-Pipe 证明了 TileLang-Pipelined 这种 producer/consumer 分工可以用 Triton + TLE 清晰表达,并带来接近 2x 的实际性能提升。 写 pipe 和 warp_specialize 比手拼 mbarrier 直观一个数量级。
TLE-FlashMLA 则进一步证明,FlashMLA phase1 的 seesaw 双 consumer 同步模式也能用 TLE 复刻。 它不是对手写 CUDA 的全面替代,但已经把复刻成本从“翻几百行 PTX 和 CUDA barrier 代码”降低到“写几十行 pipe 声明 + 几个消费者函数”。
如果你已经能写 Triton attention kernel,TLE 要你多理解的不是一门新语言,而是三件事:shared memory buffer、typed pipe、warp partition。
SparseMLA 正好说明,这三件事加在一起,足够把一个朴素 kernel 推到 FlashMLA 附近,全程不用碰 CUDA,不用翻 PTX 手册,不用手算 barrier 的 arrive_count。
安装、详细手册及代码参考:
-
TLE Pipeline PR 和 SparseMLA 算子实现:https://github.com/flagos-ai/FlagTree/pull/592

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)