【论文阅读】Learning while Deploying: Fleet-Scale Offline-to-Online Reinforcement Learning for Generalist
快速了解部分
基础信息:
- 题目: Learning while Deploying: Fleet-Scale Offline-to-Online Reinforcement Learning for Generalist Robot Policies
- 时间: 2026.05
- 机构: Shanghai Innovation Institute, AGIBOT Finch, Columbia University
- 3个英文关键词: Generalist Robot, Offline-to-Online RL, VLA
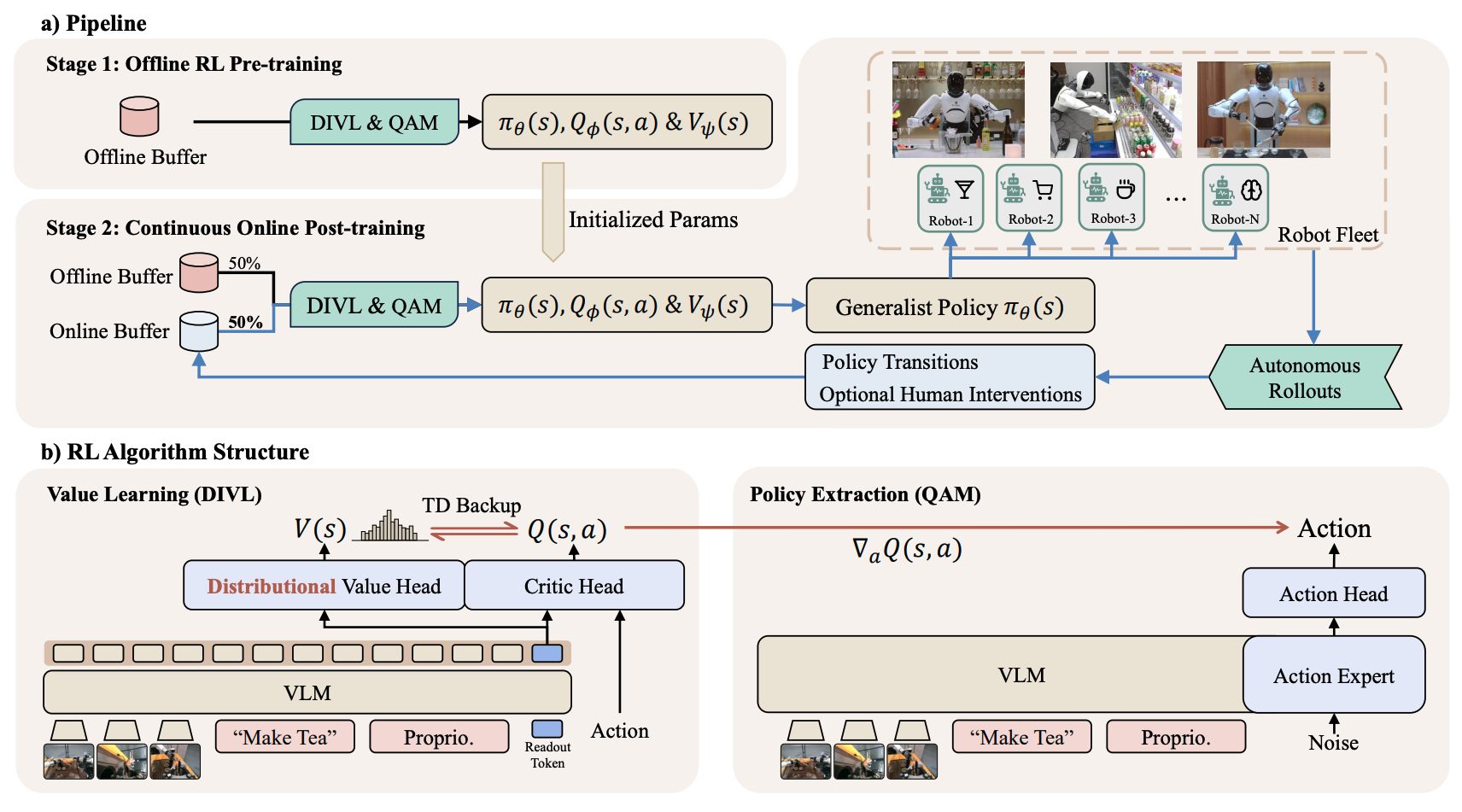
1句话通俗总结
通过让机器人大军在实际干活时边干边学(Online RL),用分布式的强化学习算法,把预训练好的通用机器人模型(VLA)从“理论派”变成“实战派”,解决了离线数据无法覆盖真实世界复杂情况的痛点。
研究痛点
纯离线预训练(Offline Pretraining)搞不定真实世界的“长尾分布”和“突发状况”,模型部署后遇到没见过的场景就会抓瞎,现有方法无法高效利用部署后的实时交互数据进行自我进化。
核心方法
搞了一套“离线预训练+在线微调”的闭环流水线(LWD),核心是用分布式的值函数学习(DIVL)处理车队杂乱数据,再用QAM算法把改进信号注入到VLA模型里。
深入了解部分
作者核心主张
部署不应该只是模型的“终点考试”,而应该是模型“持续进修”的源头;利用车队(Fleet)的规模效应,能把稀疏的现实世界经验变成模型能力的飞轮。
创新本质
相比SOTA,真正新在应用场景与训练策略的结合:首次在真实世界的多任务通用机器人(Generalist VLA)上实现了大规模的离线到在线强化学习闭环,且算法层面适配了VLA的流匹配(Flow Matching)架构。
方法直觉解释
输入:预训练好的VLA模型 + 车队实时跑出来的杂乱数据(含成功、失败、人类干预)。
处理:先用DIVL算法把这些乱七八糟的数据变成“价值地图”(分布式的值函数),再用QAM算法像“导航纠偏”一样,通过伴随匹配(Adjoint Matching)告诉VLA模型下一步怎么生成动作更好。
输出:一个越用越聪明、能处理长周期复杂任务(如泡茶、理货)的通用机器人策略。
关键实现细节
- DIVL (Distributional Implicit Value Learning):不用单一数值代表状态价值,而是用分布(Categorical Distribution)来保留数据中的多模态信息(比如某些动作在特定情况下能成功),并根据不确定性自适应调整乐观程度(Adaptive τ\tauτ)。
- QAM (Q-learning with Adjoint Matching):不直接反向传播Q值梯度(那样太贵且不稳定),而是将其转化为对流模型(Flow Policy)的局部回归目标,实现了对VLA生成过程的精准微调。
技术传承
继承了 IQL (Implicit Q-Learning) 的隐式策略改进思想和 Flow Matching 的生成式建模架构;改进了IQL的标量值估计为分布式的(Distributional),并将QAM算法从模拟环境迁移到了真实世界的VLA模型训练中。
实验验证(只列最关键的2-3个)
exp1: 多任务真实机器人性能对比
- 设置: 16台双臂机器人,8个真实世界任务(包括4个长周期任务如功夫茶、果汁制作)。
- 数据: 真实物理环境,对比SFT, RECAP, HG-DAgger等基线。
- 结论: LWD (Online) 平均得分达到0.95,尤其在长周期任务上大幅领先(0.91 vs SFT的0.68),且循环时间缩短了23.75秒。
exp2: 消融实验(Ablation Study)
- 设置: 对比DIVL与标量Expectile回归,对比自适应τ\tauτ策略与固定τ\tauτ。
- 数据: 离线与在线阶段的消融。
- 结论: 分布式值学习(DIVL)在长周期任务上带来了显著提升(+16.7%),证明了处理异构数据分布的重要性。
同类工作对比
- RECAP (2025): 同样是迭代式离线RL,但RECAP主要依赖优势权重筛选数据,且未实现真正的在线部署闭环;LWD直接利用在线交互和人类干预数据,通过DIVL处理异构数据更鲁棒。
- HG-DAgger (2019): 依赖人类专家不断提供演示修正(Imitation Learning);LWD利用RL直接从结果(Reward)优化,能探索更广的状态空间,且不完全依赖人类标定动作。
- SOP (2026): SOP提供了可扩展的在线微调系统架构;LWD在此基础上提供了具体的RL算法内核(DIVL+QAM),解决了SOP中未详细涉及的长周期稀疏奖励问题。
强相关文献(3篇)
- π₀: A vision-language-action flow model for general robot control (2024)
- Implicit Q-Learning (2021)
- Q-learning with Adjoint Matching (2026)
局限与适用边界
作者承认的limitation:当前在线学习调度策略较简单(Real-time schedule),未针对超大规模部署优化;复杂长周期任务依赖单一高层指令,缺乏细粒度的视觉语言推理分解;安全性机制未显式建模。
你判断的适用场景:适合拥有机器人车队(Fleet)的规模化部署场景(如仓储物流、零售理货、家庭服务),用于解决长周期、稀疏奖励的通用任务;不适用于单机、无云端协同、或对安全性要求极高且无法容忍试错的场景。
我的
- 大规模的RL训练VLA。RL上面有一点创新,部分原理没太看懂。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)