硬核长文预警!2026机器学习全栈通关指南:从KNN到XGBoost,手推公式+代码实战,这一篇就够了!
📝 正文内容
🌌 序章:机器学习的星辰大海
机器学习不是魔法,而是数学与代码的艺术。当我们谈论人工智能时,我们实际上是在谈论如何让计算机从数据中学习规律。
本篇博客将带你通过八个核心关卡,从最直观的KNN算法出发,穿越线性回归的数学迷雾,攀爬决策树的逻辑阶梯,最终在集成学习的巅峰俯瞰数据全景。
🧩 模块一:机器学习概述与基石
核心思想: 机器学习主要分为监督学习(分类、回归)、无监督学习(聚类)和强化学习。
在我们的探索中,首先要明确几个概念:
- 特征: 描述事物的属性(如房子的面积、颜色)。
- 标签: 我们想要预测的结果(如房价、是否患病)。
- 模型: 从数据中学到的函数 y=f(x)。
💡 深度洞察: 机器学习的本质是优化。我们定义一个损失函数(Loss Function)来衡量预测值与真实值的差距,然后通过优化算法(如梯度下降)去寻找让损失最小的参数。
📏 模块二:KNN算法——近朱者赤,近墨者黑
K-Nearest Neighbors (KNN) 是最直观的“懒惰学习”算法。它没有显式的训练过程,而是把数据存起来,预测时看“邻居”是谁。
核心三要素:
K值的选择: K太小容易受噪声影响(过拟合),K太大容易忽略局部特征(欠拟合)。通常通过交叉验证选择。
距离度量: 最常用的是欧氏距离:
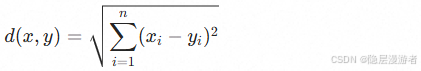
决策规则: 分类问题看多数表决,回归问题看平均值。
代码实战:手写KNN分类器
import numpy as np
from collections import Counter
class KNNClassifier:
def __init__(self, k):
self.k = k
def fit(self, X_train, y_train):
self.X_train = X_train
self.y_train = y_train
def predict(self, X_predict):
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
# 1. 计算距离
distances = [np.sqrt(np.sum((x - x_train) ** 2)) for x_train in self.X_train]
# 2. 找到最近的k个点
nearest = np.argsort(distances)[:self.k]
# 3. 投票
top_k_y = [self.y_train[i] for i in nearest]
votes = Counter(top_k_y)
return votes.most_common(1)[0][0]📉 模块三 & 四:线性回归——拟合的艺术
线性回归试图找到一条直线(或超平面)来拟合数据。
1. 损失函数
我们使用均方误差来衡量拟合程度:
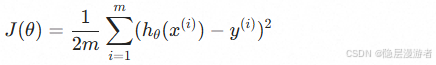
2. 求解方法:正规方程 vs 梯度下降
- 正规方程: 直接通过矩阵运算求解最优解。
![]()
*优点:* 不需要选择学习率,一次运算得出。
*缺点:* 当特征数量 $ n $ 很大时,矩阵求逆复杂度为 $ O(n^3) $ ,速度极慢。- 梯度下降: 沿着梯度的反方向逐步迭代更新参数。
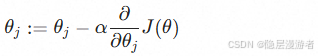
其中 $ \alpha $ 是学习率。代码实战:梯度下降实现
def gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
J_history = []
for i in range(num_iters):
# 计算预测误差
error = np.dot(X, theta) - y
# 计算梯度
gradient = np.dot(X.T, error) / m
# 更新参数
theta = theta - alpha * gradient
J_history.append(compute_cost(X, y, theta))
return theta, J_history🧪 模块五:逻辑回归——分类的利器
尽管名字叫“回归”,逻辑回归却是解决二分类问题的王者。
核心变换:Sigmoid函数
它将线性回归的输出压缩到 (0,1)(0,1) 之间,解释为概率:
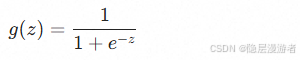
损失函数:
由于Sigmoid是非线性的,均方误差会导致非凸函数,存在局部最优解。因此我们使用对数损失函数:
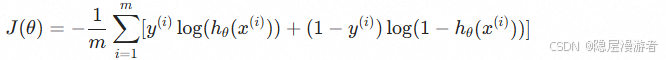
评估指标:
在分类问题中,准确率往往不够全面。我们需要关注:
- 混淆矩阵: TP, FP, FN, TN
- 精确率: P=TP/(TP+FP)
- 召回率: R=TP/(TP+FN)
- F1-Score: 精确率和召回率的调和平均数。
🌳 模块六:决策树——if-else的智慧
决策树通过树状结构进行决策,其核心在于如何选择最优特征进行分裂。
三大流派:
- ID3: 使用信息增益。倾向于选择取值较多的特征(如“身份证号”),容易导致过拟合。
- 信息熵:
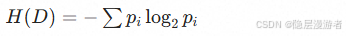
- 信息熵:
- C4.5: 使用信息增益比。对取值较多的特征进行惩罚。
- CART (分类与回归树):
- 分类树使用基尼系数:

- 回归树使用平方误差最小化。
- 分类树使用基尼系数:
剪枝策略:
为了防止树长得太深(过拟合),我们需要“修剪”树枝。
- 预剪枝: 限制树的最大深度、叶子节点最小样本数。
- 后剪枝: 先生成完整的树,再自底向上考察非叶子节点,如果将其替换为叶子节点能提升泛化性能,则进行替换。
🛡️ 模块七 & 八:集成学习——三个臭皮匠,顶个诸葛亮
集成学习通过构建并结合多个学习器来完成学习任务,通常比单一模型效果更好。
1. Bagging与随机森林
- 思想: 并行训练多个独立的模型,最后投票或平均。
- 随机森林: 在Bagging基础上,不仅对样本进行随机采样(Bootstrap),还对特征进行随机选择。这增加了模型的多样性,极大地降低了方差。
2. Boosting与提升树
- 思想: 串行训练,每一个新模型都致力于修正前一个模型的错误。
- AdaBoost: 提高被前一轮弱分类器错误分类样本的权重。
- GBDT (梯度提升决策树): 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
- XGBoost: GBDT的工程优化版。
- 目标函数: 加入了正则化项 Ω(f)Ω(f) 控制模型复杂度。
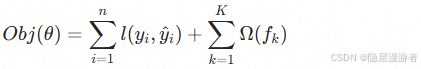
- **二阶泰勒展开:** 利用一阶和二阶梯度信息,收敛更快。
- **加权分位数 sketches:** 高效处理稀疏数据。XGBoost 核心代码逻辑(简化版):
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 加载数据
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)
# 转换数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 参数设置
param = {
'max_depth': 3,
'eta': 0.1,
'objective': 'reg:squarederror',
'eval_metric': 'rmse'
}
# 训练
bst = xgb.train(param, dtrain, num_boost_round=100)
# 预测
preds = bst.predict(dtest)🏁 结语:算法之外的思考
掌握了这些算法,只是迈出了第一步。在实际工程中,数据和特征决定了模型的上限,而算法和参数优化只是逼近这个上限。
2026年的今天,虽然大模型风头正劲,但传统的机器学习算法(如XGBoost、随机森林)在结构化数据处理上依然占据统治地位。希望这篇长文能成为你案头的常备手册。
如果你觉得这篇文章对你有帮助,请点赞、收藏、关注!你的支持是我持续输出硬核内容的最大动力!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)