Agent开发面经
一.Agent与大模型的本质区别
Agent本质上是一个能自主完成目标的AI系统,区别于传统AI的区别在于[自主性][能行动][有记忆]
传统AI你问一个问题它回答一个问题,每次都是独立的没有记忆,你给它一个输入,它给你一个输出,不会去主动做任何事情
Agent有自主规划的能力,你给它一个复杂目标,它会把任务拆分为多步,通过调用工具,访问记忆,感知环境来一步步执行,不只是一个简单的问答机器人
传统大模型的局限性
1.知识的局限性,模型的训练数据有截止日期,它给你的回答局限于它训练的数据
2.无法行动,比如你让他发送一份邮件,它做不到,因为它本质上就是一个文本生成器,通过训练数据去推测下一个token最有可能的结果,它的输出是一个token一个token输出的,每一步都是输出概率最大的token
3.无状态,这里的状态就指在一个复杂任务中的中间记忆,这次的对话无法接上上次的记录
Agent怎么解决这些问题?
Agent组成:LLM(传统大模型),工具,记忆模块,规划模块
- LLM:agent的大脑,推理决策和调用工具都靠它决定
- 工具:可以理解为封装好的函数,是agent的四肢,让agent有了改变外部环境的能力,LLM只能决定调用那个,并不能真正的去执行调用
- 记忆模块:分为长期记忆和短期记忆,长期记忆就是用户的习惯,画像等,短期记忆就是运行时上下文(一次请求),运行时上下文包括了用户query,历史对话,工具调用,工具输出结果等信息
- 规划模块:有两种模式,Plan-and-Excute(先规划再执行)和ReAct(边执行边规划),其实说的就是agent的行动方式
Agent有自主规划能力,能行动(改变外部环境),有闭环(每步的行动都会反馈回来指导下一步),模型本身只是大脑,工具的执行是写的代码,模型只做决策
1.Agent如何解决知识的局限性
引入外部知识库,LLM就像人的大脑一样,我们只能输出我们学习过的东西,没有学习过的东西只能通过,已有的知识去推理它可能的输出,拿考试举例,闭卷考试我们只能靠大脑中的知识库,但开卷考试,我们可以通过去查询外部知识库去(书)解决问题,Agent解决LLM训练数据又截止日期的问题其实也是这个原理,这块其实我认为和Agent关系不大,是通过引入RAG技术去接入外部知识库
2.Agent如何解决LLM无法行动的问题
Agent组成部分之一就是工具,相对于给LLM接上了手和脚,让LLM有了接触外部环境的能力,回到刚刚LLM无法发送邮件的问题,我们写一个发送邮件的函数,当LLM觉得需要完成发送邮件这个事情的时候,就可以通过调用这个函数来完成
3.Agent如何解决LLM无状态的问题
通过上下文窗口去解决,Agent在执行的时候会维护一个上下文窗口,可以理解为,人在做某件事情的过程中的记忆,上下文窗口中包括了用户的query,历史对话,工具调用,工具调用结果等,通过上下文窗口解决LLM无状态的问题
二.Agent如何去调用工具——Function Calling
LLM在没有Function Calling之前,想让模型帮你调工具,完全靠解析自然语言,模型输出[查询一下北京的天气],再写if/esle去判断,完全没有标准
那么我理解的Function Calling就是一种协议,用于规范模型调用工具的输出,模型判断协议调用工具的时候不直接输出自然语言,而是直接输出一段结构化标准的tool_call Json,告诉你要调那个函数,参数是什么,这样只需要写一套解析结构化Json的代码即可
整个调用工具的过程本质上有两个流程:第一轮[模型说我需要调用工具],第二轮[代码去通过解析Json真实的去调用结果,再返回给模型],模型只做决策,执行的事情都由代码完成
# LLM 输出的【标准结构化格式】,不是自然语言!
llm_output = {
"role": "assistant",
"tool_calls": [
{
"id": "tool_001",
"type": "function",
"function": {
"name": "get_weather", # 调用哪个函数
"arguments": '{"city":"北京"}' # 参数
}
}
]
}那么我们在注册工具的时候需要做什么呢?
- 工具描述,用于告诉模型,这个工具的作用,这一步很重要,如果描述的不准确,llm可能无法有效的调用工具
- 参数列表,参数的数据类型,每一个参数是什么含义
# 工具描述(必须告诉 LLM 每个工具是干嘛的)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询城市天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,例如:北京"
}
},
"required": ["city"]
}
}
}
]LLM只负责决策调用哪个工具,工具真实去执行完全依赖于代码/框架解析LLM输出的Json格式Function Calling
三.Agent的推理范式
先说一下CoT和ToT这两个概念,都属于模型怎么思考层面的问题
CoT:思维链,线性单路径,一步步推的推理范式,让模型把隐式的推理显示的表现出来成为一条连贯的思维链
ToT:思维树,树状多路径,可分支的推理范式,把思考的过程建成树
Agent的推理范式说的就是Agent思考和行动的模式,比如说先思考完整体的步骤再去执行和一边思考一边执行
Agent有三种推理范式:
-
ReAct
把推理和行动交替进行,ReAct的每一轮循环由三个步骤组成,思考->行动->观察
思考:LLM先把当前情况分析一遍,把推理过程写出来
行动:根据思考阶段的结论,决定去调用哪个工具,传什么参数
观察:工具的返回结果,反馈给LLM,读取这个结果,进入下一轮思考
-
Plan-and-Execute
把规划和执行彻底分离,先让LLM做规划,输出一个完整的步骤列表,然后逐步执行
规划和执行解耦之后,好处就是复杂任务整体结构非常清晰
-
Reflection
反思则是用于给前两个范式做一个检验,检验LLM的输出是否符合预期,做法就是在Agent完成一步或者整个任务之后,再让一个LLM(也可以是同一个)来判断做的好不好,如果不通过就重试或换一种思路(记录失败原因,重试的时候将失败原因注入到query当中),带来的收益就是提升LLM输出的质量和准确性,但同时也增加了大量token的消耗
四.Agent的记忆机制
首先Agent的记忆分为短期记忆和长期记忆,短期记忆也是最基础的,本轮会话的信息集合,长期记忆是跨会话持久化,可检索,可复用的
短期记忆包含:用户query,历史上下文,工具调用Function Calling,工具调用结果
长期记忆包含:用户画像,用户习惯等
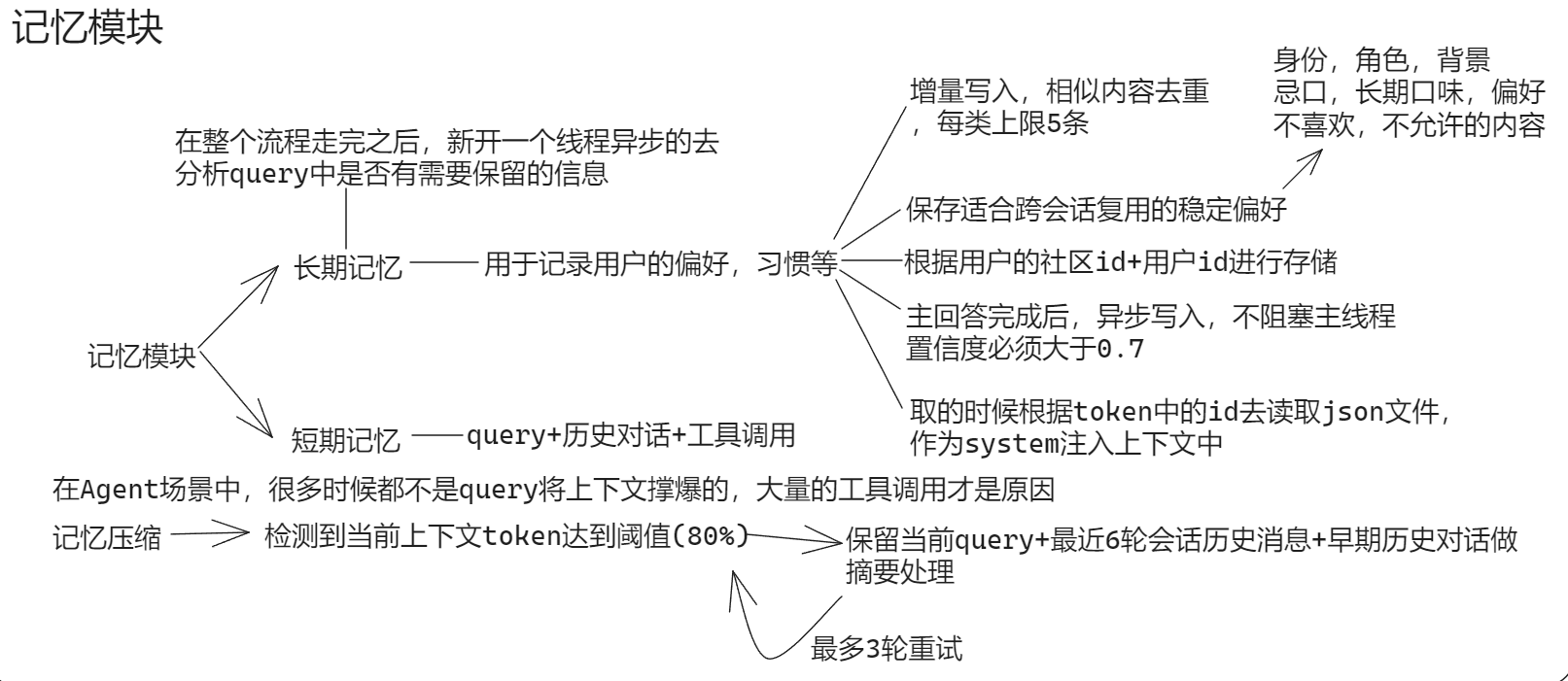
五.记忆压缩?
Agent在执行复杂任务的时候,随着工具调用越来越多,历史对话越来越长,上下文窗口可能就会被撑满,这时就需要做记忆压缩了
记忆压缩常见的有三种方式:
- 滑动窗口:只保留最近的N轮对话,超过N轮的历史对话不保留,好处是实现及其简单,不需要任何额外的LLM调用,也没有额外的开销,坏处是硬截断,按对话内容一刀切
- 摘要压缩:不直接丢弃之前超出窗口的历史对话,而是先让LLM把这段对话历史总结生成成一段摘要精华,用摘要去替换原始对话,但是摘要会丢失细节,LLM在总结时,会按照自己判断的重要性来决定保留什么,省略什么
- 重要性过滤:按价值筛选,不按时间维度筛选,像滑动窗口和摘要压缩都是按时间维度去筛选,重要性过滤则是按照消息的价值去筛选,给每条记录打分,低于阈值的直接淘汰,高分的保留
六.什么是幻觉?如何预防幻觉?
大模型幻觉:模式生成了听起来很合理但实际是错的内容,模型生成了与训练事实,用户输入,或已知世界不一致的内容,但语言上看起来很流畅合理,这是LLM的固有缺陷
模型产生幻觉有三个原因:
- 训练数据层面:互联网语料本身就有错误,矛盾,过时的信息,模型把这些都学进去当作事实记忆
- 生成机制层面:LLM本质是按概率去续写下一个token,不是查询知识库,模型对自己知不知道某件事没有显示信号,碰到不熟悉的问题,会按训练时见过的相似上下文编一个看起来合理的答案
- 对齐目标层面:在训练时,自信地回答往往比我不知道得分要高,模型无形中被训练成不会拒答
幻觉分为三类:
- 事实幻觉:编造不存在的事实,这是训练数据层面导致的原因
- 推理性幻觉:推理链路错乱,前后矛盾
- 上下文不一致:违背用户给出的明确条件。运行时上下文导致的原因
缓解方案:
- 训练层:对齐数据里加入不知道就说不知道的样例,做校验训练,让模型学会拒答
- 推理层:让模型先做必要的分布分析再答(CoT),温度降低减少随机偏差
- 系统层:RAG接入外部知识库,让模型看着相关资料回答
环节不可能完全消除,因为它是LLM概率生成机制的固有产物,工程上是降低发生率+让用户能感知到

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)