无限资源消耗 - 大语言模型 OWASP TOP 10系列
无限资源消耗
- 资料来源:
genai.owasp.org - 资料整理:韦胖
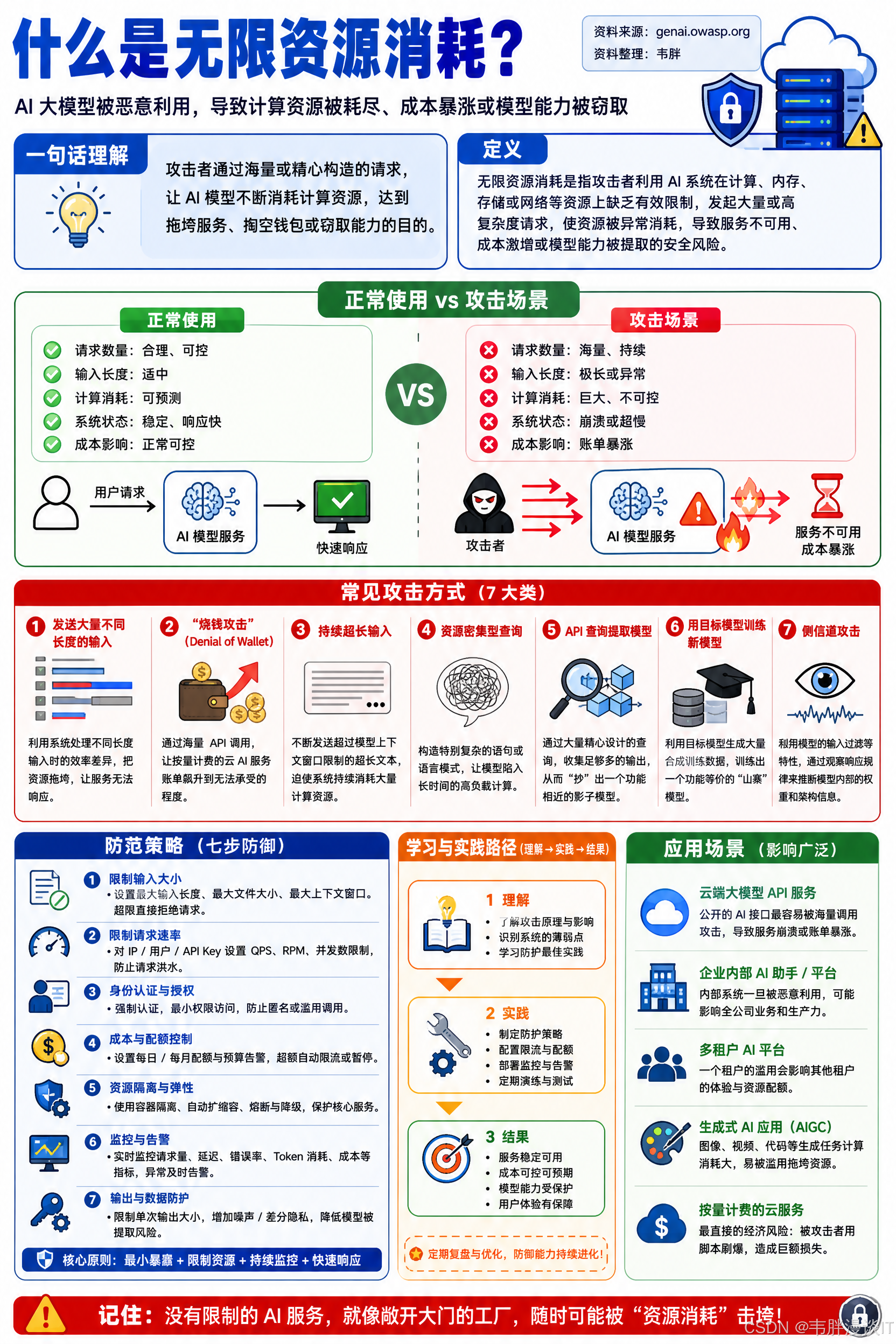
是什么意思?
AI 大模型每次生成回答都需要消耗计算资源。如果不加限制,攻击者就可以大量发送请求,耗尽服务器资源,让正常用户无法使用;或者通过"烧钱攻击"让按量计费的云服务账单暴涨;还能通过反复查询来"抄走"你的模型能力。
这类攻击会导致:
- 拒绝服务(DoS):服务崩溃或响应超慢,真实用户无法使用
- 经济损失:云端按量计费被大量请求刷爆
- 模型被盗:攻击者通过海量查询复现模型行为,克隆出"山寨版"
常见攻击方式
-
发送大量不同长度的输入:利用系统处理不同长度输入时的效率差异,把资源拖垮,让服务无法响应。
-
“烧钱攻击”(Denial of Wallet):通过海量 API 调用,让按量计费的云 AI 服务账单飙升到无法承受的程度。
-
持续超长输入:不断发送超过模型上下文窗口限制的超长文本,迫使系统持续消耗大量计算资源。
-
资源密集型查询:构造特别复杂的语句或语言模式,让模型陷入长时间的高负载计算。
-
API 查询提取模型:通过大量精心设计的查询,收集足够多的输出,从而"抄"出一个功能相近的影子模型,窃取知识产权。
-
用目标模型训练新模型:利用目标模型生成大量合成训练数据,训练出一个功能等价的"山寨"模型,绕过传统的模型保护手段。
-
侧信道攻击:利用模型的输入过滤等特性,通过观察响应规律来推断模型内部的权重和架构信息。
如何防范
-
限制输入大小:设置合理的输入长度上限,拒绝超长请求。
-
减少模型概率信息的暴露:限制 API 返回
logit_bias和logprobs等敏感信息,防止攻击者利用这些数据逆向模型。 -
速率限制:对每个用户或来源设置单位时间内的最大请求数,超过限制就拒绝或排队。
-
动态资源管理:实时监控资源使用,防止单个用户或请求占用过多资源。
-
超时与限流:为耗时操作设置最大执行时间,超时自动中断,防止资源被长时间占用。
-
沙箱隔离:限制 AI 应用能访问的网络资源、内部服务和 API,控制攻击影响范围,也有助于防止侧信道攻击。
-
日志与异常监控:持续监控资源使用情况,发现异常消耗及时告警并介入。
-
水印技术:在模型输出中嵌入水印,方便检测和追踪未经授权的使用。
-
优雅降级:系统负载过高时,降低服务质量而不是直接崩溃,保留基本功能。
-
限制队列并弹性扩容:限制排队任务数量,同时配合动态扩容和负载均衡,保证基本可用性。
-
对抗性训练:训练模型识别并抵抗专门用于提取模型信息的对抗性查询。
-
过滤已知问题输入:维护已知会引发异常行为的"故障令牌"列表,在处理前过滤掉。
-
访问控制:用 RBAC(基于角色的访问控制)和最小权限原则保护模型和训练环境,防止未授权访问。
-
中央化模型注册表:统一管理生产环境中使用的模型,确保每个模型都经过审批和版本控制。
-
自动化 MLOps 流程:通过自动化部署流程,加上审批和追踪机制,避免未授权的模型或配置被推上生产。
真实攻击场景
场景 1:输入过大
攻击者向 AI 应用提交超大文本,导致服务器内存和 CPU 暴涨,系统崩溃或严重变慢。
场景 2:请求洪水
攻击者向 API 发送海量请求,把计算资源全部占满,让真正的用户都无法正常访问服务。
场景 3:资源密集型查询
攻击者精心设计特定的输入格式,让每次查询都触发模型最耗资源的计算路径,导致 CPU 长时间满载。
场景 4:“烧钱攻击”
攻击者用脚本自动发送大量 API 请求,把按量计费的云服务账单刷到天文数字,服务方无法承受。
场景 5:复制模型
攻击者用目标模型生成海量合成数据,拿去微调另一个开源模型,得到一个功能相近的"山寨版",绕过了传统的模型保护。
场景 6:绕过过滤提取模型信息
攻击者绕过前置的输入过滤机制,通过侧信道攻击,将模型的内部信息偷偷传输到远程服务器。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)