0 门槛克隆 0.1B 纯 CPU 实时运行、1 核飙出 48kHz,AI 语音告别显卡依赖
在音频生成(TTS)赛道,过去想要获得高质量、能流式克隆声音的模型,动辄也需要搭上一张昂贵的显卡,甚至还要忍受几秒钟的“首字延迟”。
但就在最近,开源社区投下了一枚震撼弹。由 MOSI.AI 与 OpenMOSS 团队 联合开源的 MOSS-TTS-Nano 彻底打破了这一僵局: 仅凭 0.1B(1亿)参数,不依赖任何显卡(GPU),直接在纯 CPU 环境下就能流畅运行实时多语言语音克隆! 在苹果今年最新的 MacBook Air M4 上,它甚至只占用 1 个 CPU 核心,就能像流水一样源源不断地吐出 48kHz 超高保真、双声道的克隆音频。

这不禁让人大呼:TTS 领域的“轻量化工业奇迹”来了。
一、 为什么说 MOSS-TTS-Nano 是“打工人的福音”?
在很多人的印象里,“微型模型”往往意味着“低质量”和“阉割版”。但 MOSS-TTS-Nano 的“Nano”绝非敷衍,它把刀法用在了极致的架构优化上,直接切中了开发者和本地部署爱好者的三大痛点:

1. 极致小身材,极低部署门槛
它的参数量仅有 0.1B。这意味着什么?它不需要十几G的显存,也不用复杂的 CUDA 环境配置。普通的笔记本电脑、甚至是轻量级的云服务器,都能轻松把它跑起来。
2. 48 kHz 立体声:身材缩水,画质(音质)不缩水
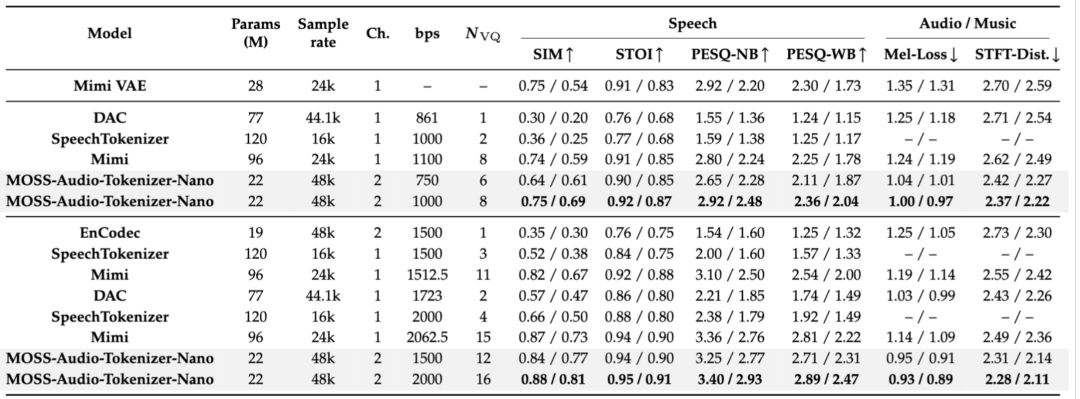
市面上很多轻量级 TTS 为了省算力,输出的音频大多是 16kHz 或 24kHz 的单声道,听起来总有一种挥之不去的“电话音”或“塑料感”。而 MOSS-TTS-Nano 竟然在 0.1B 的体量下,原生支持 48 kHz、双声道(立体声) 输出!拿它克隆出来的声音,饱满、真实,连呼吸声和语气细节都得到了完美保留。
3. 恐怖的 CPU 推理效率:速度直接“翻倍”
尤其是团队最新推出的 ONNX CPU 版本,在推理阶段彻底脱离了对 PyTorch 的依赖。经过实际测试,ONNX 版本的处理效率较原版接近翻倍。对于想把 TTS 集成到日常软件、浏览器插件或小工具里的开发者来说,这简直就是降维打击。

二、 核心技术揭秘:它是如何做到“以小博大”的?
要实现如此恐怖的性能,离不开 OpenMOSS 家族深厚的技术底蕴。MOSS-TTS-Nano 能够以小博大,核心在于其精妙的 “纯自回归 Audio Tokenizer + LLM” 管道架构。
这里不得不提它背后的“无名英雄”——MOSS-Audio-Tokenizer-Nano。
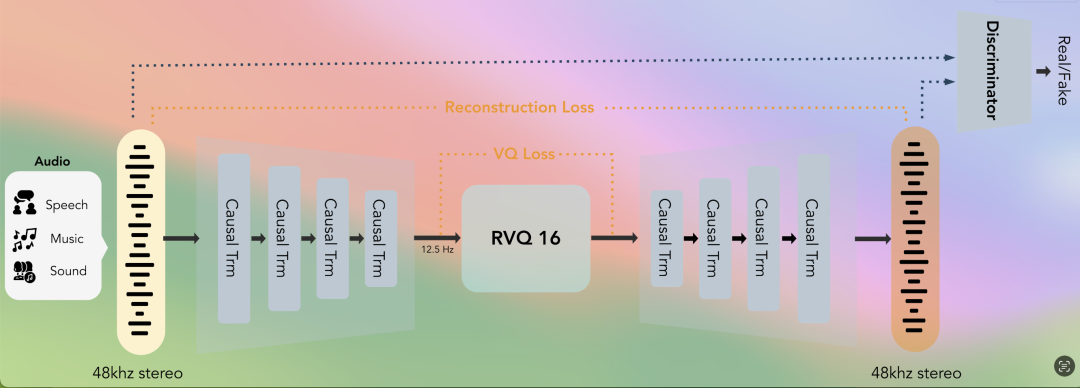
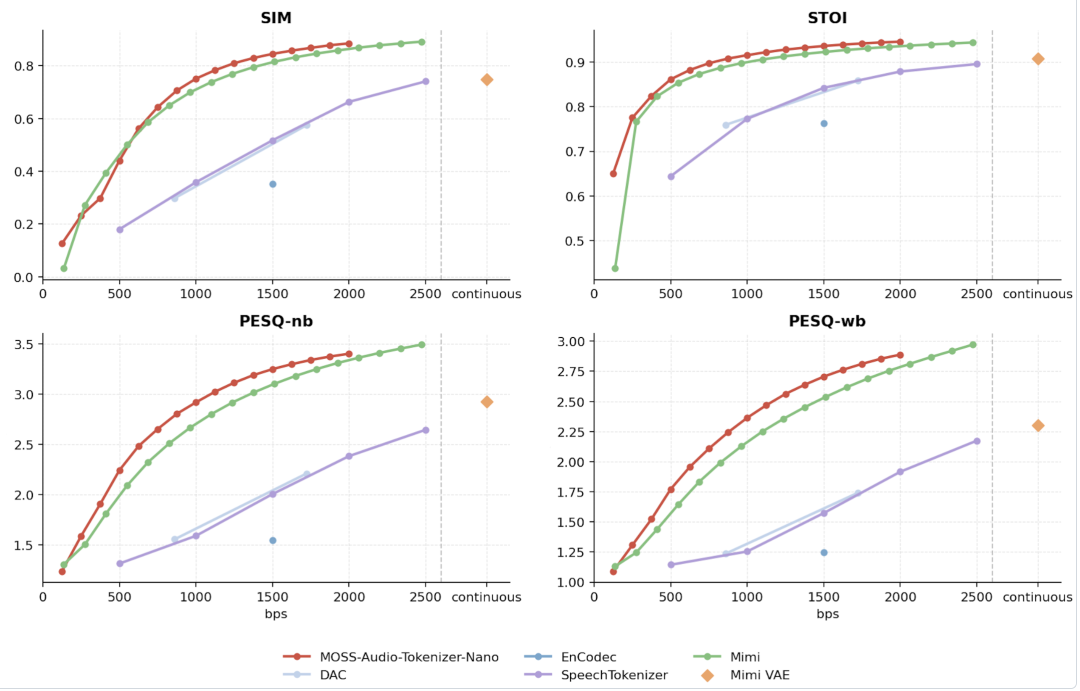
在传统的音频大模型中,音频的“分词器”(Tokenizer)通常依赖繁重的 CNN 架构,计算量巨大。而 OpenMOSS 团队创新性地提出了 Cat(Causal Audio Tokenizer with Transformer)架构——一个完全由因果 Transformer 块组成的无 CNN 音频分词器。
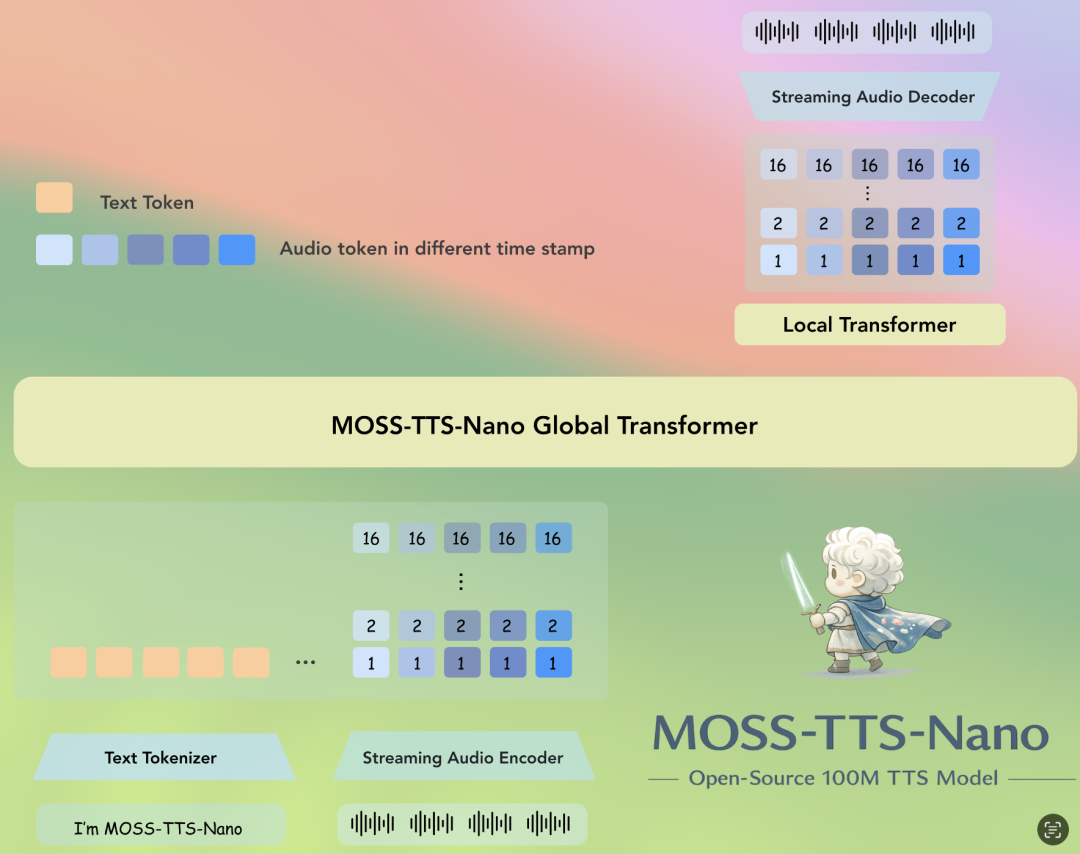
- 20M 参数的轻量化奇迹
:这个专门训练的 Tokenizer 只有约 20M 参数,却能将 48 kHz 的立体声音频压缩成 12.5 Hz 的 Token 流。
- 高保真重建
:利用 16 个码本的 RVQ(残差矢量量化),在 0.125 kbps 到 2 kbps 的超低可变码率下,它在 LibriSpeech、AISHELL-2 等权威基准评测中,整体重建质量超越了大量规模在其数倍之上的开源 Tokenizer。
正是凭借这个强大的音频分词器,0.1B 参数的 LLM 核心才能毫无负担地处理极其精简的音频 Token,从而在极低的实时延迟下,实现流式音频的快速首字节输出。
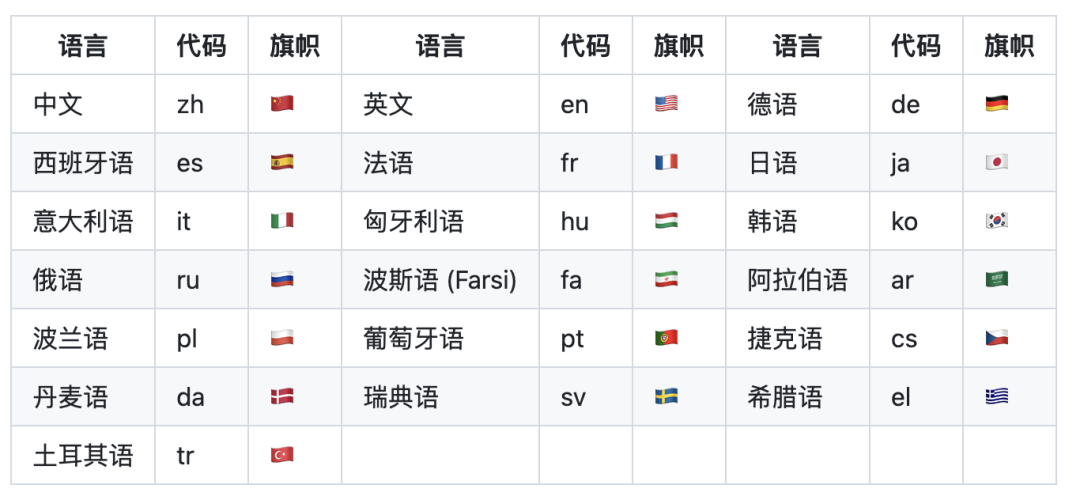
三、 支持 20 种语言,真正的“跨国语言大师”
别看它体积小,它还是个不折不扣的“语言天才”。MOSS-TTS-Nano 原生支持包括中文(zh)、英文(en)、日语(ja)、韩语(ko)、德语(de)、法语(fr)、西班牙语(es)、俄语(ru)在内的 20 种语言。
无论是做跨国跨境电商的配音、多语言小语种的客服播报,还是追番时的实时同传翻译,它都能无缝切换,且对中英混合等复杂场景的合成也有着极高的稳定性。
四、 快速上手:几行代码,解锁你的“本地声音克隆机”
光说不练假把式。MOSS-TTS-Nano 维持了极简的部署栈,非常适合折腾。
1. 环境配置(推荐使用 Conda)
首先,创建一个干净的环境并克隆仓库:
conda create -n moss-tts-nano python=3.12 -y
conda activate moss-tts-nano
git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
cd MOSS-TTS-Nano
接着,针对一些文本预处理依赖(如 pynini 和 WeTextProcessing),推荐通过 conda 顺畅安装
conda install -c conda-forge pynini=2.1.6.post1 -y
pip install git+https://github.com/WhizZest/WeTextProcessing.git
pip install -r requirements.txt
pip install -e .2. 一句话快速克隆项目彻底打包了 CLI 工具,装好之后连 Python 脚本都不用写,直接在终端里敲下一行命令,就能用指定的参考音频(zh_1.wav)克隆出你想要的任何长文本
moss-tts-nano generate \
--backend onnx \
--prompt-speech assets/audio/zh_1.wav \
--text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。体验纯CPU下的飞速克隆!"
(注:如果没有提前下载模型,首次运行会自动从 Hugging Face 官方仓库拉取对应的 ONNX 权重。)3. 启动属于你的本地 Web 界面
如果你更喜欢可视化操作,官方提供了一键启动本地网页端演示的命令:
moss-tts-nano serve --backend onnx在浏览器中打开 http://127.0.0.1:18083,你就能直接上传你或者朋友的录音,在线体验如同丝滑流水的实时语音生成了!
五、 想象空间:MOSS-TTS-Nano 能用来做什么?
MOSS-TTS-Nano 的出现,把原本属于云端、显卡集群的超能力,平权给了每一个边缘设备。它的想象空间极其广阔:
- 浏览器超轻量插件(MOSS-TTS-Nano-Reader)
:官方目前已经基于该技术更新了浏览器插件,用户可以直接在浏览器内部、完全不依赖任何后端服务器的情况下,让小说、新闻用你熟悉的声音读出来。
- 播客与自媒体高产工具
:文案写完,直接用自己的音色模型在纯本地批量生成 48kHz 的高清音频配音,不仅零成本,还完全不用担心音色数据泄露给第三方云平台。
- NPC 实时对话与智能硬件
:因为对 CPU 极度友好、单核即可流畅运行,它可以被轻松集成进各种掌机游戏、智能音箱、甚至是树莓派等嵌入式设备中,让设备真正学会“用特定音色流式思考与表达”。
结语
从大参数量的旗舰模型 MOSS-TTS(8B)、面向有声对话场景的 MOSS-TTSD,再到如今惊艳全场的 MOSS-TTS-Nano(0.1B),OpenMOSS 团队不仅在顶尖性能上不断向上探顶,更在落地实用性上向下扎根。
据悉,MOSS-TTS 2.0 已经在紧锣密鼓地筹备中,官方也放出了需求收集表,欢迎各路开发者前去“许愿”。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)