使用llama.cpp运行模型unsloth/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf 速度大约5.5 token/s
下载llama.cpp
repo:github.com
到这个页面,下载适合的程序,比如windows10下,使用了这个:
下载模型
寻找模型
到modelscopy下载模型,首先我们要确定模型,是这款Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
但是直接查这个名字未必能查到,所以先要查Qwen3.6-35B-A3B,在modelscopy官网查:搜索 · 魔搭社区
查到这里: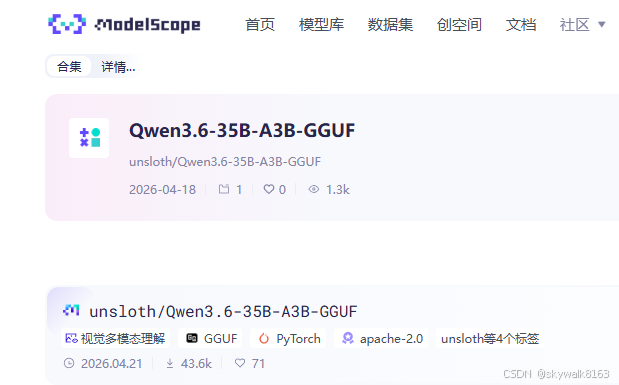
进入unsloth子页面,发现gguf有好多模型,我们今天用这一款:Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
安装modelscopy
pip install modelscope下载模型
modelscope download --model unsloth/Qwen3.6-35B-A3B-GGUF Qwen3.6-35B-A3B-UD-Q4_K_M.gguf --local_dir ./下载完毕
G:\ai\models>dir
Volume in drive G is AI
Volume Serial Number is 0619-E3AB
Directory of G:\ai\models
05/25/2026 09:36 AM <DIR> .
05/25/2026 09:36 AM <DIR> ..
05/25/2026 09:36 AM 113 .msc
05/25/2026 09:04 AM <DIR> ._____temp
05/25/2026 09:36 AM 22,134,528,992 Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
2 File(s) 22,134,529,105 bytes
3 Dir(s) 123,231,006,720 bytes free
启动llama服务
启动命令
普通的启动命令
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf当前速度5 token/s
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 99 --n-cpu-moe 32 --flash-attn on -c 65536 --cache-type-k q4_0 -np 1
内存少了5G,速度略有增加

llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 99 --n-cpu-moe 32 --flash-attn on -c 65536 --cache-type-k q4_0 -np 1 --cache-ram 0
最后用的4并发
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 99 --n-cpu-moe 32 --flash-attn on -c 65536 --cache-type-k q4_0 -np 4 --cache-ram 0
在2个任务同时进行的情况下,可以达到7.3 token/s
参数含义
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 99 --n-cpu-moe 32 --flash-attn on -c 65536 --cache-type-k q4_0 -np 4 --cache-ram 0 --tools all
以下是针对 llama-server.exe 命令中各参数的详细解读,结合 Qwen3.6-35B-A3B 模型和推理优化需求进行说明:
1. 基础模型加载
-
-m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf- 作用:指定模型文件路径。
- 细节:
- 文件格式为
.gguf(GGML 量化格式),支持高效推理。 Qwen3.6-35B-A3B是阿里云的 350亿参数混合专家(MoE)模型,A3B可能表示架构优化版本。UD-Q4_K_M表明模型经过 4-bit 量化(Q4),键(Key)和值(Value)使用q4_0量化类型,显著减少内存占用。
- 文件格式为
2. 模型架构与并行配置
-
-ngl 99- 作用:设置 GPU 层数(Number of GPU Layers)。
- 细节:
99表示将模型的前 99 层加载到 GPU(若模型总层数 ≥99)。- 剩余层(如注意力层、输出层)可能在 CPU 上运行(需结合
--n-cpu-moe配置)。 - 适用场景:多 GPU 或 GPU 内存不足时,通过分层卸载平衡负载。
-
--n-cpu-moe 32- 作用:分配 32 个 CPU 线程处理 MoE(混合专家)路由。
- 细节:
- MoE 模型需动态选择专家(Expert)处理输入,此参数控制路由计算的并行度。
- 数值需 ≤ 物理 CPU 核心数(如 64 核 CPU 可设为 32-64)。
- 性能影响:线程数过高可能导致上下文切换开销,需实测调优。
3. 推理加速优化
-
--flash-attn on- 作用:启用 Flash Attention 优化。
- 细节:
- 通过算法优化减少注意力计算的内存访问次数,显著提升速度(尤其长序列)。
- 硬件要求:需支持 Tensor Cores 的 GPU(如 NVIDIA A100/H100)。
- 兼容性:若 GPU 不支持,可能自动回退到标准注意力机制。
-
-c 65536- 作用:设置 上下文窗口大小(Context Length) 为 65,536 tokens。
- 细节:
- 决定模型能处理的最大输入/输出序列长度(如长文档摘要、多轮对话)。
- 内存影响:窗口越大,KV 缓存占用越高(需配合
--cache-type-k和--cache-ram调整)。 - 限制:实际可用窗口可能受模型架构和硬件限制(如 35B 模型可能支持 ≤32K tokens)。
4. 缓存与量化配置
-
--cache-type-k q4_0- 作用:指定键(Key)的缓存量化类型为 4-bit 量化的
q4_0格式。 - 细节:
q4_0是 GGML 量化的一种,牺牲少量精度换取内存节省(通常压缩率 75%)。- 仅量化 Key(不量化 Value),平衡速度与质量(部分实现可能同时量化 Value)。
- 适用场景:内存受限但需处理长序列时。
- 作用:指定键(Key)的缓存量化类型为 4-bit 量化的
-
--cache-ram 0- 作用:不限制 系统内存(RAM)用于缓存的大小。
- 细节:
- 缓存主要用于存储 KV 缓存和中间结果,
0表示自动分配(可能占用全部可用内存)。 - 风险:若系统内存不足,可能导致 OOM(需监控内存使用)。
- 替代方案:可设为固定值(如
--cache-ram 16000000000限制为 16GB)。
- 缓存主要用于存储 KV 缓存和中间结果,
5. 多进程与工具集成
-
-np 4- 作用:启动 4 个推理进程(Number of Processes)。
- 细节:
- 多进程可并行处理多个请求,提升吞吐量(尤其高并发场景)。
- 每个进程独立加载模型,需确保总内存足够(35B 模型 ×4 进程可能需 >100GB 内存)。
- 适用场景:服务化部署(如 API 服务)。
-
--tools- 作用:启用 工具调用能力(如函数调用、外部 API 交互)。
- 细节:
- 允许模型通过工具扩展功能(如查询数据库、调用计算器)。
- 需配合工具定义文件(如
tools.json)使用,具体实现依赖框架版本。 - 典型场景:智能体(Agent)应用(如 AutoGPT、BabyAGI)。
参数组合建议
-
内存优化配置(低显存 GPU):
bash
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 64 --n-cpu-moe 16 --flash-attn on -c 32768 --cache-type-k q4_0 -np 2 --cache-ram 8000000000- 减少 GPU 层数(
-ngl 64)、缩小上下文窗口(-c 32768)、限制缓存内存(8GB)。
- 减少 GPU 层数(
-
高性能配置(多 GPU + 高显存):
bash
llama-server.exe -m g:\ai\models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf -ngl 120 --n-cpu-moe 32 --flash-attn on -c 65536 --cache-type-k q4_0 -np 4 --cache-ram 0- 最大化 GPU 利用率(
-ngl 120)、启用 Flash Attention、不限制缓存内存。
- 最大化 GPU 利用率(
注意事项
- 硬件匹配:确保 GPU 支持 Flash Attention(如 NVIDIA Ampere 架构及以上)。
- 监控资源:使用
nvidia-smi(GPU)和htop(CPU)监控负载,避免瓶颈。 - 框架版本:部分参数(如
--tools)可能需特定版本的llama-server支持。
通过调整这些参数,可在 推理速度、内存占用、模型质量 之间找到最佳平衡点。
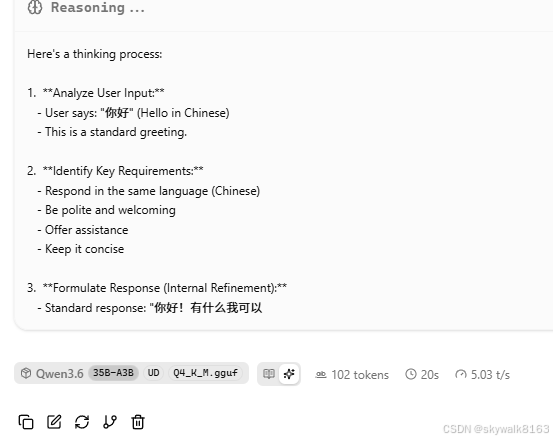
测试一下,问它个问题:你擅长什么?
Reasoning
Toggle content
我擅长多个方向的能力,主要集中在以下几个方面:
- 复杂推理与逻辑分析:能拆解数学、科学、商业及日常场景中的复杂问题,提供严谨、可验证的分析路径。
- 全栈代码与开发支持:支持多语言代码生成、理解、调试与重构,可协助完成从脚本到完整项目架构的开发任务。
- 超长上下文处理:支持 256K 上下文窗口,能一次性阅读并精准定位长篇文档、报表或日志中的关键信息。
- 多语言与跨文化交互:原生支持全球 100 多种语言,满足国际化沟通、翻译与本地化需求。
- 智能体与自动化工作流:可自主规划多步任务,结合搜索、代码执行与工具调用,独立完成复杂流程。
- 专业领域知识增强:在医疗、法律、金融、教育等垂直领域具备深度知识对齐,可提供合规、实用且结构清晰的建议。
如果你有具体的任务、想测试某项能力,或需要我协助完成某类工作,直接告诉我即可,我会按需为你高效处理。
Qwen3.635B-A3BUDQ4_K_M.gguf
ReadingGeneration
938 tokens2min 50s5.50 t/s
可以看到答案还是可以的。
耗时
总共耗时约3分钟,可以一用。主要是cpu和显卡都较差,
CPU
Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
Base speed: 3.50 GHz
Sockets: 2
Cores: 12
Logical processors: 24
Virtualization: Enabled
L1 cache: 768 KB
L2 cache: 3.0 MB
L3 cache: 50.0 MB
Utilization 32%
Speed 3.58 GHz
Up time 2:21:49:31
Processes 451
Threads 8502
Handles 251410
GPU 0
NVIDIA Quadro K4200
Driver version: 30.0.14.7514
Driver date: 6/10/2024
DirectX version: 12 (FL 11.0)
Physical location: PCI bus 5, device 0, function 0
Utilization 6%
Dedicated GPU memory 0.8/4.0 GB
Shared GPU memory 0.2/32.0 GB
GPU Memory 1.0/36.0 GB
总体llama.cpp配这款模型,32G的主机配老显卡,都可以一战!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)