收藏 2026 版|一文吃透 Transformer 原理:从分词 Token 到逐字预测全过程
本篇以诗句春眠不觉推演补全晓为例,带你完整跑通 Transformer 输入到输出全流程,零基础小白、入门程序员都能轻松看懂。全文沿用uer/gpt2-chinese-cluecorpussmall中文 GPT2 模型演示,结合实战代码、流程拆解,同步补充 2026 大模型应用侧实用知识点。
Transformer 整体框架
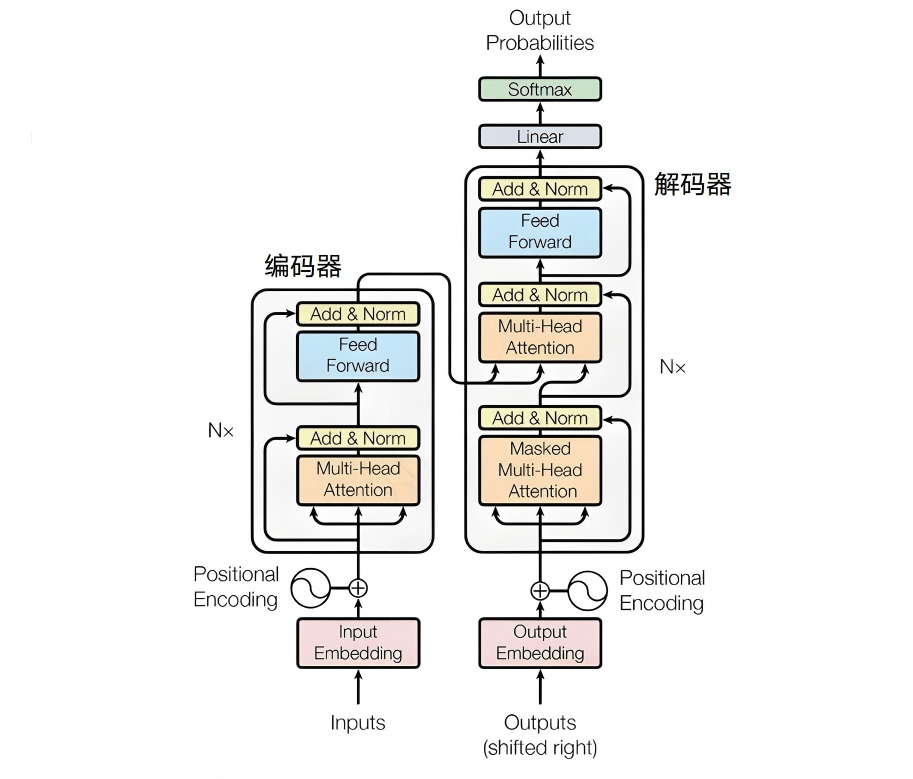
下面用 「春眠不觉」→ 补全「晓」 串起全流程(层数、维度随具体模型而变):
输入:"春眠不觉"
│
▼
┌─────────────────────────────────────────┐
│ 1. Tokenize(分词) │
│ ["春", "眠", "不", "觉"] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 2. 编码(Token → ID) │
│ [102, 235, 301, 189] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 3. Embedding(如 768 维) │
│ 查表得 [v1, v2, v3, v4] │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 4. 位置编码(Position Embedding) │
│ 与 vi 相加:输入i = vi + pi │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 5. Decoder × N 层(如 12 层,视模型而定) │
│ • Masked Self-Attention │
│ • Feed-Forward Network │
│ • 残差连接 + LayerNorm │
│ (Encoder-Decoder 架构才有 │
│ Cross-Attention,纯 GPT 无此项) │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 6. Linear(输出层 / LM Head) │
│ 隐状态 → 词表大小(如 21128)→ logits │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 7. Softmax │
│ logits → 词表上的概率分布 │
└─────────────────────────────────────────┘
│
▼
概率示意(词表维度,非句中第几位):
[0, 0, …, 0.92, …, 0] → 「晓」对应下标概率最高
│
▼
输出 Token:"晓"
最终句子:"春眠不觉晓"
后文各节按 1 → 7 的顺序展开说明。
文本转换为Token
把一段文字变成一组 Token,这一过程叫 词元化(Tokenization)。
Transformer 处理自然语言的第一步:模型只能对数字做矩阵运算,不能直接处理汉字或英文,因此须先把文本切成离散单元,再映射为整数编号。
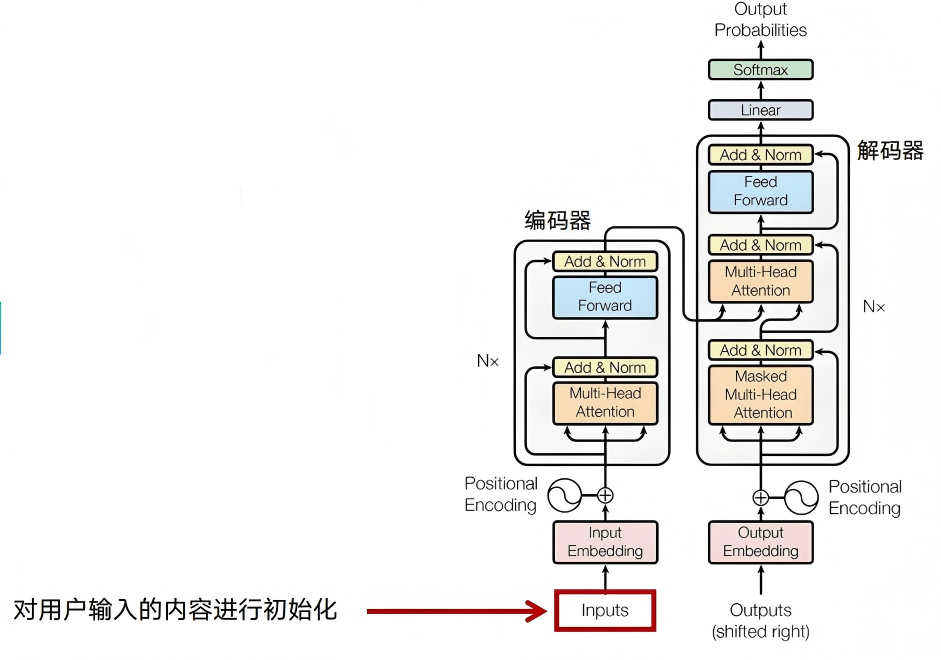
分词器做什么?
对应上文流程图的 第 1、2 步(Tokenize → 编码),由 Tokenizer(分词器) 完成:
| 人类 | 模型 | |
|---|---|---|
| 输入 | 「春眠不觉晓」 | 同一句经词元化后 |
| 实际使用 | 直接理解语义 | [101, 2345, 6789, …] 这样的 Token ID 序列 |
送进模型的是 ID 序列,不是原始字符串。分词器主要做两件事:
- 切分:把字符串拆成 Token 列表;
- 编码:把每个 Token 换成词表(Vocabulary)里的整数 ID。
训练与推理须用同一套词元化规则;换模型通常也要换对应的分词器,否则 ID 与词义会对不上。
三种词元化粒度:字、词与子词
模型里的 Token 是词元化后交给大模型的最小单元,按切分方式,常见有三类:
| 粒度 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 字/字符级 | 每个汉字、字母单独成 Token | 词表小,罕见词也能表示 | 序列很长,语义片段被拆碎 |
| 词级 | 按词典切分为完整词语 | 符合直觉 | 词表巨大,未登录词(OOV)难处理 |
| 子词级(Subword) | BPE、WordPiece、SentencePiece 等 | 词表可控,能兼顾常见词与生僻词 | 规则稍复杂,需专门学习 |
当前主流大模型(GPT、BERT、LLaMA 等)几乎都采用子词分词:常见词整段保留,生僻词拆成更小的片段。
从句子到 ID 序列
以句子 「春眠不觉晓」 为例(实际切分结果因模型而异):
原文: 春眠不觉晓
Token: [春, 眠, 不, 觉, 晓] ← 词元化后的字符串片段
Token ID: [2345, 1890, 45, 67, 891] ← 词表中的整数编号
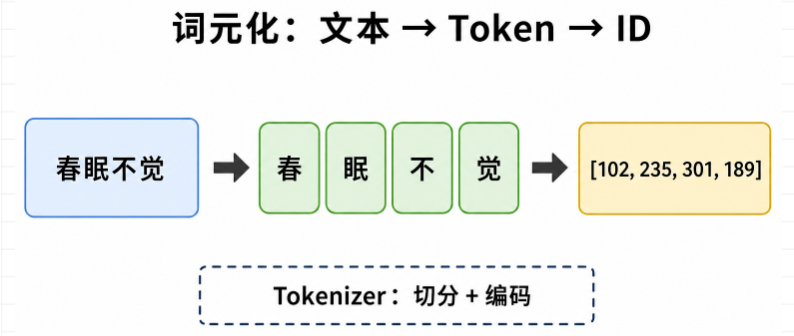
模型后续接收的是 Token ID 序列,而不是原始字符串。解码时再用分词器的 decode 把 ID 还原成文字。
特殊 Token
词表里除了普通字词,还预留了一些控制用的符号,例如:
| 符号(示例) | 常见含义 |
|---|---|
[CLS] |
BERT 等用于分类/句首聚合(GPT 生成模型通常不用) |
[SEP] |
句子分隔(多用于 BERT 双句输入) |
| `` | 补齐到同一长度(批处理时) |
[MASK] |
掩码语言模型训练时遮盖的位置 |
| <|endoftext|> | endoftext |
用 Hugging Face 亲手试一次
用 AutoTokenizer 加载与模型配套的分词器:
from transformers import AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "春眠不觉晓"
# 编码:文本 → Token ID
encoded = tokenizer(text)
print("Token ID:", encoded["input_ids"])
# 看每个 ID 对应什么片段(便于理解子词切分)
tokens = tokenizer.tokenize(text)
print("Token 片段:", tokens)
# 解码:Token ID → 文本
decoded = tokenizer.decode(encoded["input_ids"])
print("还原文本:", decoded)
典型输出形态(具体数字以本机为准;GPT-2 中文多为按字切分,一般不含 BERT 的 [CLS]/[SEP]):
Token 片段: ['春', '眠', '不', '觉', '晓']
Token ID: [2345, 1890, 45, 67, 891]
要点小结:
- Tokenizer 与模型成对使用:
from_pretrained同一模型名,会下载vocab.txt、tokenizer_config.json等(见下一篇文章模型目录说明)。 - 词表大小(如 21128)决定 Embedding 矩阵行数,即模型最多认识多少个不同 Token。
Token转换为向量
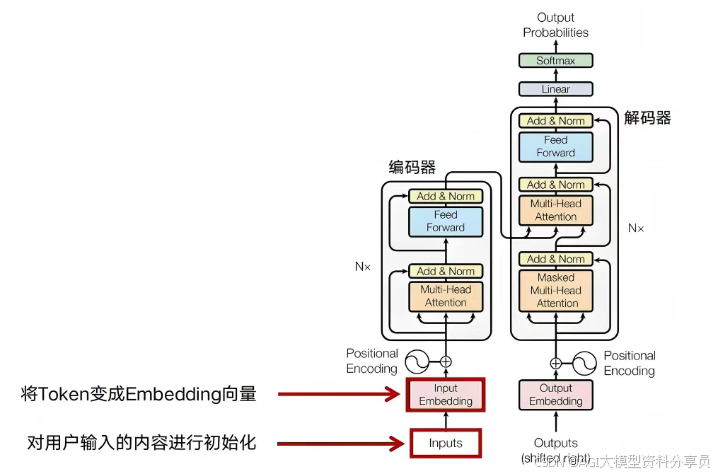
Embedding(嵌入) 把每个 Token ID 映射为一条 hidden_size 维向量(如 768 维)。实现上是查表:矩阵 [词表大小, hidden_size],每个 ID 取一行;n 个 Token 得到 [n, hidden_size]。
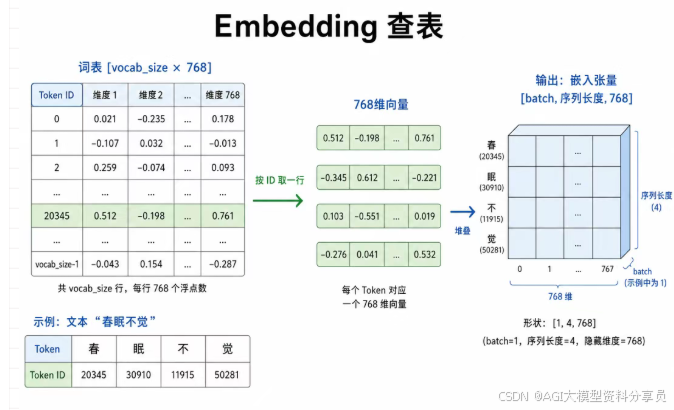
用代码看形状
import torch
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
text = "春眠不觉晓"
inputs = tokenizer(text, return_tensors="pt")
input_ids = inputs["input_ids"]
print("Token ID 张量:", input_ids.shape)
# 取出模型的词嵌入层
embed_layer = model.get_input_embeddings()
token_vectors = embed_layer(input_ids)
print("Token 向量张量:", token_vectors.shape)
print("hidden_size:", model.config.hidden_size)
若 hidden_size 为 768、分词后序列长度为 5,则 token_vectors.shape 多为 torch.Size([1, 5, 768]):
| 维度 | 含义 |
|---|---|
第 1 维 1 |
batch,一次 1 条句子 |
第 2 维 5 |
序列中 5 个 Token |
第 3 维 768 |
每个 Token 一条 768 维向量 |
要点小结:
- Embedding 把离散 ID 变成连续向量,是第一个可学习的语义表示层。
- 走完整 Transformer 后,同一词在不同上下文里向量还会被后续层改写;本节是刚查表时的初始向量。
向量中加入位置信息
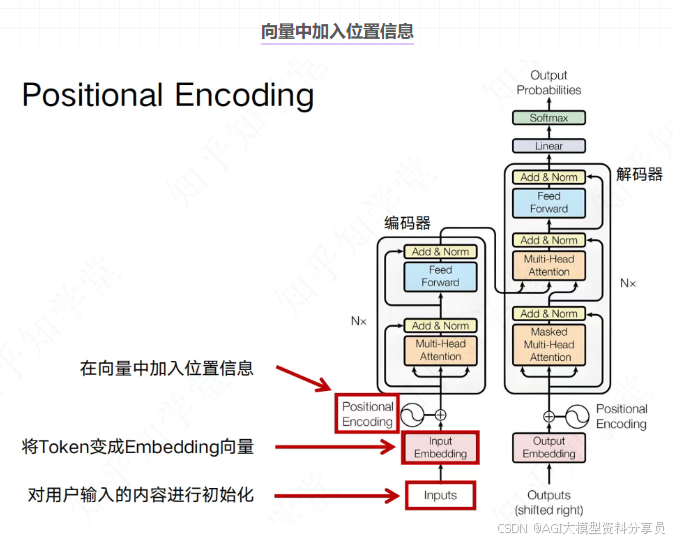
Embedding 只按 Token ID 查表,同一字在不同位置查到的向量相同——还须知道顺序。例如「狗咬人」与「人咬狗」,词一样,顺序不同,意思相反。
怎么做:位置向量与 Token 向量相加
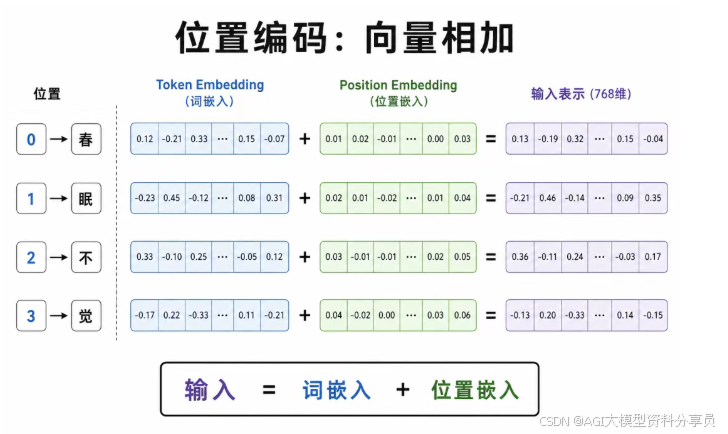
输入表示 = Token Embedding + Position Embedding
| 方式 | 说明 |
|---|---|
| 正弦位置编码 | 原始论文用 sin/cos 生成,不增加可训练参数 |
| 可学习位置编码 | GPT-2、BERT:每个位置一行可训练向量 |
相加后,同一 Token 在不同位置上的输入向量不同,后续自注意力才能区分先后。
用代码看一眼(GPT-2)
GPT-2 使用可学习位置编码,内部大致是「词嵌入 + 位置嵌入」:
from transformers import AutoModel, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
inputs = tokenizer("春眠不觉晓", return_tensors="pt")
# 模型 forward 时会自动把 wte(词嵌入)与 wpe(位置嵌入)相加
outputs = model(**inputs)
print(outputs.last_hidden_state.shape) # [1, 序列长度, hidden_size]
要点小结:
- Embedding 管「是什么词」,位置编码管「在第几位」。
- 没有位置信息,模型无法稳定区分语序。
深度理解语义
「春」在「春眠不觉晓」和「春色满园」里含义不同——须结合整句其它词更新每个位置的表示。核心是 自注意力(Self-Attention):每个 Token 按相关程度汇总句中信息。
Decoder 生成时还用 掩码自注意力(Masked Self-Attention):当前位置不能看见后面的词,避免「偷看答案」。
自注意力:以 「春」 为例(见下图),按 Q / K / V 三步融合全句——
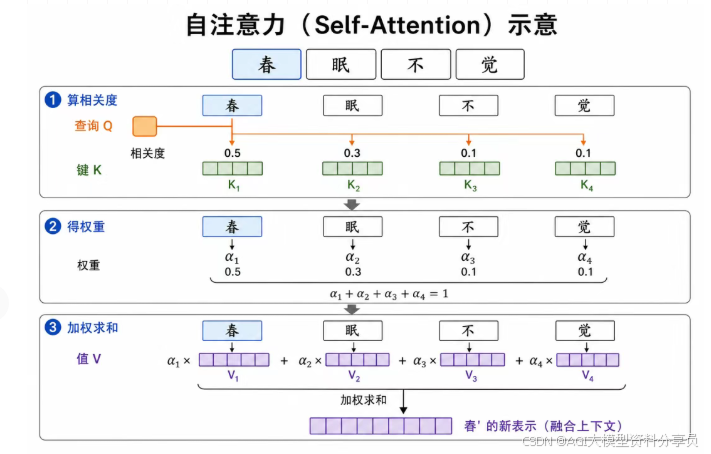
- 算相关度:「春」的 Q 与每个词的 K 比对;
- 得权重:Softmax 归一,权重和为 1;
- 加权求和:对 V 加权,得到 春’。
| 符号 | 含义(通俗理解) |
|---|---|
| Q | 当前词「想找什么」 |
| K | 每个词「能提供什么匹配信息」 |
| V | 每个词「实际贡献的语义内容」 |
句中每个词都会走一遍(也会看自己),因此叫「自」注意力。
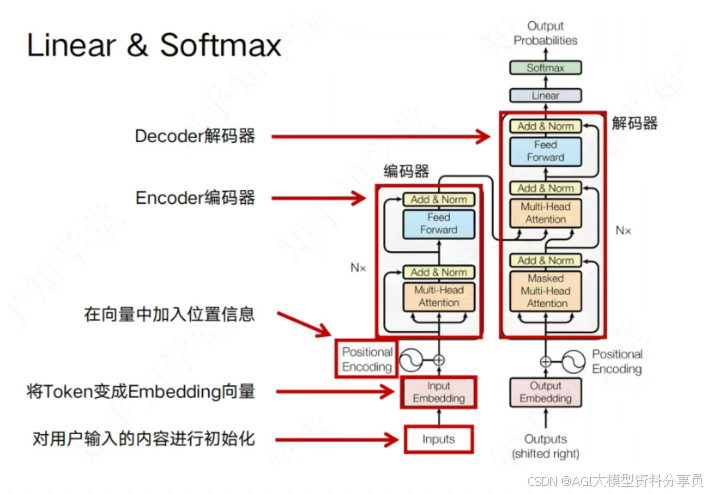
一层 Block 与多层堆叠:把 多头注意力(MHA) 与 前馈网络(FFN) 组成一层 Transformer Block(各带一次 Add & Norm),再 叠 N 层——对应文首第 5 步与整体架构图(1-1.png)里 Decoder 的 Nx。
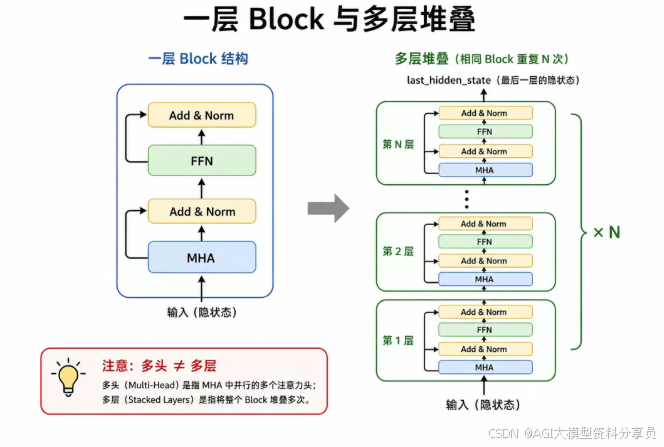
多头是同一层内多路并行,多层是同一种 Block 重复很多遍(二者含义不同)。叠完后得到 last_hidden_state,供下文映射到词表。本文为 仅 Decoder 的 GPT;理解类常用 Encoder(如 BERT),翻译等用 Encoder-Decoder。
outputs = model(**inputs)
hidden = outputs.last_hidden_state # [1, 序列长度, hidden_size]
生成“下一个字”的权重分布
对应文首流程图 第 6 步。最后一层每个位置是一条 hidden_size 维向量,经 Linear(LM Head) 映射到整个词表,得到每个候选 Token 的 logits(未归一化的得分)。
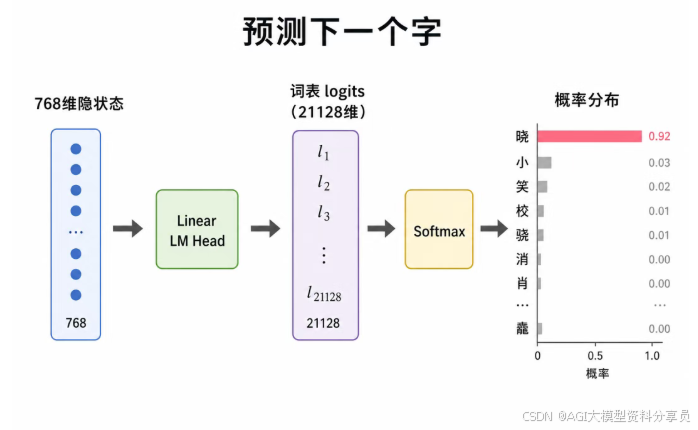
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
inputs = tokenizer("春眠不觉", return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # [1, 序列长度, vocab_size]
print("logits 形状:", logits.shape)
print("词表大小:", model.config.vocab_size)
# 通常取最后一个位置的 logits,用于预测「下一个字」
next_logits = logits[0, -1, :]
将权重分布转换成概率分布
对应文首 第 7 步。对 logits 做 Softmax,得到和为 1 的概率;再 取概率最大(贪心)或按概率采样,得到下一个 Token。
以补全 「晓」 为例:词表中「晓」对应位置概率最高,即输出该 Token;再拼回输入,继续预测,直到遇到结束符——这叫 自回归生成。
import torch
probs = torch.softmax(next_logits, dim=-1)
pred_id = torch.argmax(probs).item()
print("预测 Token ID:", pred_id)
print("预测片段:", tokenizer.decode([pred_id]))
也可用 model.generate 自动完成多轮预测(见 下一篇文章)。
要点回顾
| 步骤 | 做什么 | 本文对应 |
|---|---|---|
| 1–2 | 词元化 → Token ID | Tokenizer |
| 3 | ID → 向量 | Embedding |
| 4 | 加位置信息 | Position Embedding |
| 5 | N 层 Decoder 理解上下文 | 自注意力 + Block × N |
| 6 | 映射到词表得分 | LM Head → logits |
| 7 | 得分 → 概率 → 下一个字 | Softmax + 采样/贪心 |
「春眠不觉」 经上述链路,模型在词表上给 「晓」 较高概率,补全为 「春眠不觉晓」。
最后
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!
很多程序员、职场新人纷纷入局大模型领域,绝非盲目跟风,而是实实在在看到了不可替代的价值优势,这也是2026年最值得抓住的职业风口:
1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标(掌握基础AI应用+具备简单项目经验),年龄、学历均非硬性要求,小白可快速入门,转行程序员也能无缝衔接;
2、技术可复用,上手速度翻倍:如果你有前后端开发、测试、数据分析等基础,在大模型落地、系统部署、Prompt工程等环节会更具优势,无需从零开始,复用原有技术能力就能快速进阶;
3、懂业务更吃香,竞争力翻倍:单纯懂技术已不够,2026年大厂更看重“技术+业务”的复合型人才,有垂直领域(金融、医疗、工业等)经验者,能精准定位模型落地痛点,薪资比纯技术岗高出30%以上;
更重要的是,即便没有转型需求,用AI大模型工具为工作赋能、提升效率,也已经成为80%企业的硬性要求——不会用大模型提效,未来很可能被行业淘汰!
那么2026年,小白/程序员该如何高效学习大模型?
很多人想入门大模型,却陷入两大困境:要么到处搜集零散资料,不成体系,越学越懵;要么被收费高昂的课程割韭菜,花了钱却学不到实战技能,白白浪费时间走弯路。
今天就给大家精心整理了一份2026年最新、免费、系统化的AI大模型学习资源包,覆盖从零基础入门到商业实战、从理论沉淀到面试通关的全流程,所有资料均已整理归档,无需拼凑,直接领取就能上手学习,小白可照做,程序员可进阶!

👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
这份学习路线结合2026年行业趋势和新手学习规律,由行业专家精心设计,从零基础到精通,每一步都有明确指引,帮你节省80%的无效学习时间,少走弯路、高效进阶,避免踩坑。
2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、大模型学习书籍&电子文档
涵盖2026年最新技术要点,包括基础入门、Transformer核心原理、Prompt工程、RAG实战、模型微调与部署等内容

4、AI大模型最新行业报告
报告包含腾讯、阿里、甲子光年等权威机构发布的核心内容,还有2026年中文大模型基准测评报告、AI Agent行业研究报告等,帮你站在行业前沿,把握技术风口。

5、大模型项目实战&配套源码
项目包含Deepseek R1、GPT项目、MCP项目、RAG实战等热门方向,还有视频配套代码,手把手教你从0到1完成项目开发,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

6、2026大模型大厂面试真题
2026年大模型面试已全面升级,不再单纯考察基础原理,而是转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
7、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献267条内容
已为社区贡献267条内容

所有评论(0)