【电力装备制造业智能化转型】【行业认知篇】【04】主数据混乱:同一物料 N 种 SKU 编码的代价
主数据混乱:同一物料 N 种 SKU 编码的代价
Master Data Chaos in Power Equipment Manufacturing
—— 电力装备制造业数据治理系列 · Vol.1 · 04
摘要 电力装备制造企业普遍面临「主数据混乱」问题——同一物料、同一客户、同一供应商在不同系统中有多套编码并存。一家中型企业(年产值 20-50 亿元)的客户主数据重复率典型 30%+、物料主数据编码不一致率超过 50%。这一问题直接导致跨系统报表无法直接联表、AI 应用幻觉率高、决策依赖人工映射。本文系统分析主数据混乱(5 重壁垒之 B2)的成因、量化损失、与解决思路。
1. 引言:被 ERP 厂商承诺过 30 年但未解决的问题
「主数据管理」(MDM, Master Data Management)是 ERP 厂商承诺了 30 年的概念,但在电力装备制造业,这一问题至今普遍存在。原因不是「主数据管理」概念不对,而是企业 IT 历史路径决定了「主数据混乱」是必然结果——多次系统建设、多次组织变革、多次业务变更,每一次都在主数据上留下「碎片」。
本文将主数据混乱具象化为 5 重壁垒之 B2,分析其成因、表现、与解决思路。
2. 痛点扫描:同一物料的 5 套编码
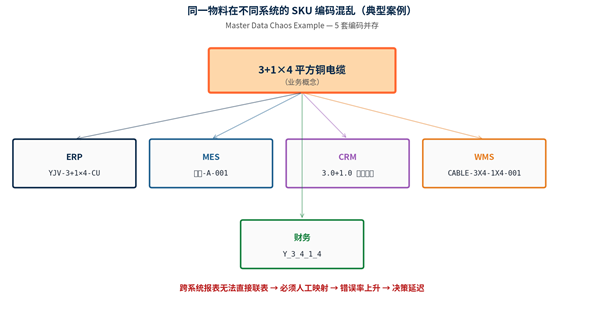
图 1:同一物料在不同系统的 SKU 编码混乱(典型案例)
2.1 典型案例
以「3+1×4 平方铜电缆」为例,这一物料在企业不同系统中可能有 5 套编码:
- **ERP**(订单/物料主数据):「YJV-3+1×4-CU」(按 IEC 标准命名);
- **MES**(生产工艺):「电缆-A-001」(按厂内序号命名);
- **CRM**(报价单):「3.0+1.0 平方铜缆」(按业务员口语化描述);
- **WMS**(库存):「CABLE-3X4-1X4-001」(按仓库系统的字段长度限制);
- **财务**(成本核算):「Y_3_4_1_4」(按财务系统的字段命名规范)。
这 5 套编码指向同一物料实体,但在数据库中是完全不同的字符串。结果:跨系统报表无法直接联表查询,所有跨系统分析都依赖「人工 Excel 映射表」。
2.2 客户主数据的混乱
客户主数据的混乱比物料主数据更严重。同一客户「广东电力建设有限公司」可能在不同系统中录为:
- CRM:「广东电力建设有限公司」(全称);
- ERP 应收账款:「广东电建」(简称);
- 质量管理系统:「广东电力建设」(中称);
- 项目管理系统:「广东电建(粤)」(简称 + 省份);
- 邮件系统:「GDDLJS」(首字母缩写)。
中型企业(年产值 20-50 亿元)的客户主数据重复率典型 30%+——同一客户在客户档案中可能有 2-3 条记录。这直接导致:
- 客户级毛利分析无法准确汇总;
- 客户应收账款分析有遗漏;
- 客诉关联到错误的客户档案。
2.3 量化损失
主数据混乱的可量化损失:
- **人工映射成本**:每个跨系统场景需 1-2 周做主数据对齐,企业内 20+ 场景合计 1-2 人年;
- **报表错误率**:跨系统报表的数据错误率典型 5-10%(主数据不一致是首要原因);
- **决策延迟**:「客户毛利分析」「物料成本分析」等关键决策报表需要人工修正,T+3 到 T+7 才能用;
- **审计风险**:上市公司或拟上市公司的财务审计中,主数据混乱可能触发审计预警;
- **AI 应用失败**:LLM 在主数据混乱的环境下幻觉率高,「查询某客户毛利」可能因客户名歧义而错答。
3. 共性壁垒 B2 的根因
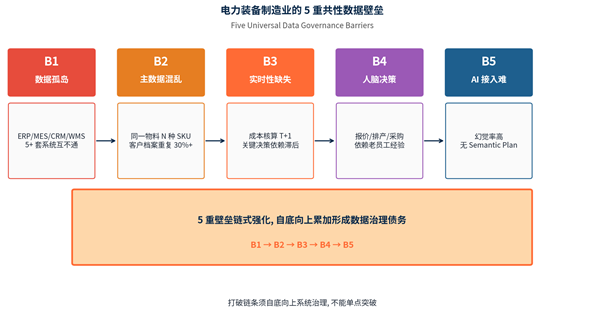
图 2:5 重共性壁垒中的 B2 位置
3.1 历史路径依赖
主数据混乱的根因与 B1 数据孤岛类似——历史路径依赖:
- **系统建设时期不同**:10 年前 ERP 的字段长度限制 30 字符,5 年前 MES 限制 50 字符,新 CRM 限制 100 字符,导致同一物料命名长度不同;
- **业务部门所有权不同**:ERP 物料主数据归采购部门,MES 物料归生产部门,命名习惯不同;
- **组织变更**:业务部门合并 / 拆分时,主数据的「所有者」频繁更换,命名规范跟随负责人变化;
- **业务规范变更**:IEC 标准更新、客户命名习惯变更、内部产品线重组,都引发主数据重命名。
3.2 「字段标准」的缺失
技术层面,最关键的缺失是「字段标准」(Field Standard)——一个企业级共识的「这个字段应该长什么样」的规范文档。多数电力装备企业不存在系统化的字段标准,每个系统的字段是「业务部门 + 系统供应商」临时定的,导致 N 套并存。
4. 解决方案:L2 元数据治理层
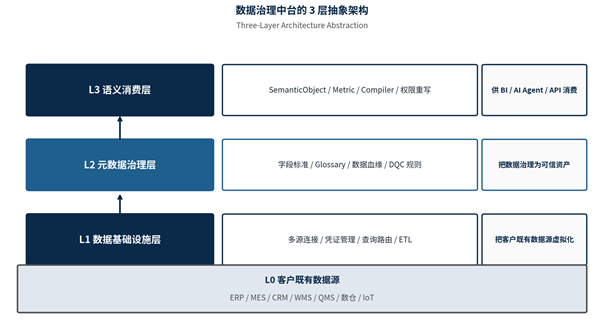
图 3:3 层架构中的「L2 元数据治理层」
4.1 字段标准化
L2 元数据治理层的核心抓手之一是「字段标准化」:
- **主数据字段标准**:定义企业级共识的物料 / 客户 / 供应商主数据字段格式(命名规则、长度、类型、枚举值);
- **字段对齐**:通过四阶段流水线(Recall / Rank / Verify / Confirm)对不同系统的字段做对齐——名称相似度 + 类型兼容性 + 样本分布 + 血缘关联 + 业务规则;
- **AI 辅助对齐**:在 10,000+ 字段规模下,纯人工对齐不可持续,需要 ML 模型(LightGBM / BERT)+ AI Agent 辅助。
4.2 Glossary 业务字典
字段标准之上是「业务字典」(Glossary)——把业务概念(如「客户毛利」「VIP 客户」「年订单量」)与具体字段绑定:
- 「客户毛利」= ((订单金额 - 物料成本 - 人工成本) / 订单金额) × 100%;
- 「VIP 客户」= 客户主数据中 vip_level ∈ {GOLD, PLATINUM};
- 「年订单量」= 客户主数据中过去 12 个月的订单数量 SUM。
Glossary 让业务概念可被机器执行(编译为 SQL),是 AI Agent 时代「LLM 查询数据」的核心基础设施。
4.3 数据血缘
字段标准 + Glossary 之上是「数据血缘」——记录字段在数据流中的传递关系:「订单表」的 customer_id 字段是从「客户主数据」的 id 字段引用过来的。血缘的工程价值:
- **变更影响分析**:客户主数据的 id 字段格式变更时,自动找出所有受影响下游字段;
- **数据问题追溯**:发现某报表数据错误时,自动追溯到上游哪个字段错;
- **主数据治理验证**:发现某字段的实际血缘与字段标准定义不一致时自动告警。
5. 实施路径
- **Phase 1(M1-M2)盘点**:盘点企业内全部主数据实体(物料 / 客户 / 供应商 / 员工 / 部门 / 项目 / 等),约 10-20 个核心实体;
- **Phase 2(M2-M4)字段标准定义**:为核心主数据实体定义企业级字段标准,约 100-200 个核心字段;
- **Phase 3(M3-M6)字段对齐**:用四阶段流水线 + AI Agent 对齐不同系统的字段到企业级标准;
- **Phase 4(M5-M8)Glossary 构建**:基于字段标准构建业务字典,约 500-1000 个业务概念;
- **Phase 5(M7-M12)血缘 + DQC**:基于 Glossary 做数据血缘解析与 DQC 规则引擎。
6. 价值数据
▎核心 KPI 字段对齐 Precision 从 32% 提升到 92%(基于 5 维特征 LightGBM + AI Agent) | 跨系统报表错误率从 5-10% 降低到 < 1% | 主数据治理人工成本降低 60-70% | Glossary 构建后 LLM 查询准确率提升 20-30 个百分点
▎数据说明 上述价值数据为基于行业典型场景与已知机器学习方法(LightGBM 字段对齐、BERT embedding 字段相似度等)的工程估算,具体效果因企业现状、实施颗粒度有差异。
7. 工程见解与边界
7.1 「自动 + 人工」的协作模式
字段对齐与 Glossary 构建必须是「AI 辅助 + 人工最终决定」的协作模式,不是「全自动」:
- AI 模型(LightGBM + AI Agent)输出 Top-3 候选 + 置信度;
- 高置信度(> 0.9)自动通过;
- 中置信度(0.5-0.9)触发人工审核(业务专家最终确定);
- 低置信度(< 0.5)标记为「无法对齐」。
这种「人机协同」可把人工工作量降低 80%+,同时保留对关键主数据的人工把关。
7.2 「持续治理」而非「一次性整改」
主数据治理不是「一次性整改完就完事」,而是需要「持续治理」机制——业务在变(新客户、新物料、新供应商),主数据必须跟进治理。需要建立:
- **字段标准的版本管理**(如 Git 化管理);
- **新字段加入时的对齐审批流程**;
- **字段标准的持续审计与告警**。
7.3 局限性
主数据治理的局限:
- **业务语义微差异**:「客户」与「买家」在概念上重叠但不完全等价(一个买家可能对应多个客户账号),机器只能给「相似」不能给「等价」;
- **冷启动**:新业务系统接入时缺少血缘信息,对齐准确率会显著下降;
- **数据稀疏字段**:只有几行样本的字段无法做统计验证。
▎工程见解 「主数据治理」的本质是「企业级数据语言的统一」——把跨系统、跨部门、跨时期的「数据方言」统一为「企业级 lingua franca」。这一变革对一家从「业务驱动」转向「数据驱动」的企业是不可回避的。但治理的成败不取决于工具,取决于组织对「数据所有权」的清晰定义与对「数据治理价值」的长期承诺。
参考资料
[1] Loshin D. Master Data Management. Morgan Kaufmann, 2008.
[2] Rahm E, Bernstein P A. A Survey of Approaches to Automatic Schema Matching. VLDB Journal 10(4), 2001.
[3] Reimers N, Gurevych I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019.
[4] Ke G, et al. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NeurIPS 2017.
[5] DAMA International. DAMA-DMBOK: Data Management Body of Knowledge. 2nd ed., 2017.
7. 关于我们
贵州数幄科技有限公司是一家专注于 人工智能与数据智能 领域的科技公司。
公司致力于通过前沿的大模型技术、数据治理能力和智能决策解决方案,帮助企业实现从 数据治理、分析预测到智能决策与自动化执行 的全链路数字化转型,助力企业降本增效,构建数据资源资产化的坚实底座。
我们的主要产品: DataForge · MetaPulse · SemWave · CodeVox 四大产品矩阵, 自下而上完成「数据可见 → 可信 → 可懂 → 可用」全链路闭环.


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)