AI提示词(Prompt Engineering)深度问答手册
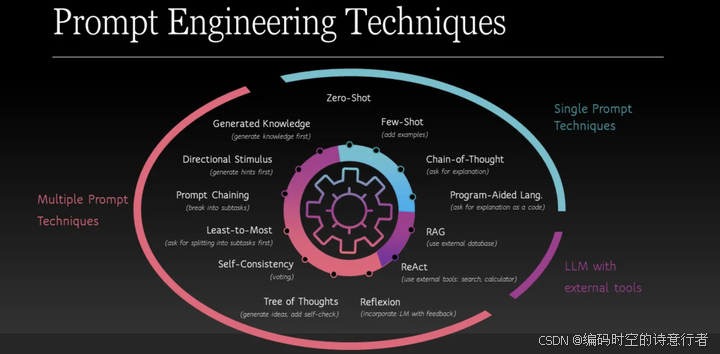
一、Prompt 基础概念
1. Prompt engineering 的核心目标是什么?
答案:在不修改模型参数的前提下,通过自然语言指令的设计,引导模型输出符合预期的结果,本质是"用语言对齐意图与模型能力"。
扩展要点:
- 三层目标:可控性(格式/风格)、准确性(事实/逻辑)、效率(token 成本)
- 与 Fine-tuning 的边界:Prompt 解决"会的事让它做对",微调解决"它本来不会"
- 不要把 Prompt 当万能药,复杂业务需要 Prompt + RAG + 工具调用 + 微调四件套
2. 什么是"零样本提示"(Zero-shot Prompt)?
答案:不提供任何示例,仅给出任务描述让模型直接完成任务。如:将下面句子翻译为英文:今天天气很好。
扩展要点:
- 依赖模型预训练中的任务理解能力
- 适合常识性、通用性、模型本身已具备的任务
- 大模型(GPT-4 级别)零样本能力强,小模型表现差距明显
3. 什么是"少样本提示"(Few-shot Prompt)?举例说明。
答案:在 Prompt 中提供 2~5 个输入输出示例,让模型从模式中学习并完成新任务。
输入:苹果 输出:水果
输入:老虎 输出:动物
输入:玫瑰 输出:
扩展要点:
- 本质是"上下文学习"(In-context Learning),不更新模型参数
- 示例的多样性 > 数量;示例分布要贴近真实输入
- 示例顺序会影响结果(近因效应明显)
4. 单样本(One-shot)与零样本、少样本的区别与适用边界?
答案:One-shot 提供 1 个示例,介于零样本与少样本之间。三者递进式增加上下文成本与示例引导力。
扩展要点:
- 任务模式简单可推断 → 零样本
- 输出格式特殊但任务简单 → 单样本(用示例固定格式)
- 任务复杂、边界模糊、输出多样 → 少样本
5. 系统提示(System Prompt)和用户提示(User Prompt)有什么区别?
答案:System Prompt 设定模型的角色、规则、约束,作用域是整个会话;User Prompt 是单轮的具体任务输入。
扩展要点:
- System Prompt 优先级高于 User Prompt(多数模型遵循)
- 用 System 定"人格 + 规则 + 输出格式",用 User 提"具体问题"
- Prompt Injection 攻击常通过 User Prompt 试图覆盖 System 指令
6. 角色扮演(Role Prompt)的作用与设计要点?
答案:通过赋予模型特定身份(如"资深律师"“儿科医生”)来激活领域知识、调整语言风格和回答深度。
扩展要点:
- 角色 = 身份 + 经验 + 视角 + 风格 四要素
- 角色设定要具体可检索,避免"你是一个聪明的助手"这种空话
- 复杂任务下,多角色协作(专家组)比单一角色更有效
7. 为什么要避免模糊/歧义表达?
答案:模糊表达会使模型在多种合理解读之间做"概率性猜测",导致输出不稳定且难以复现。
扩展要点:
- 把"详细一些"换成"用 500 字、3 个段落、附 1 个例子"
- 名词消歧:避免"它/这个/那一段"等指代不清
- 动词具体化:“分析” → “从 X、Y、Z 三个维度对比并总结差异”
8. 开放式问题 vs 封闭式问题:各自适用场景?
答案:开放式适合创意发散、头脑风暴、解释说明;封闭式适合事实判断、分类、抽取等需要可控输出的任务。
扩展要点:
- 评估场景优先封闭式,便于自动化打分
- 同一任务可"先开放后封闭":先列选项,再让其选择并说明理由
- 封闭式输出建议配合 JSON Schema / 枚举值
9. 什么是上下文窗口(Context Window)?编写长 Prompt 要注意什么?
答案:模型一次能处理的 token 总量上限,包括 System+User+History+Output。超出会截断或丢失早期信息。
扩展要点:
- “Lost in the Middle”:长上下文中间部分容易被忽略,关键信息放头尾
- 长 Prompt 应结构化(标题/分隔符/编号)
- 长文档优先考虑 RAG 检索切片,而非全文塞入
10. 什么是模型幻觉(Hallucination)?Prompt 层面如何缓解?
答案:模型生成看似合理但不真实的信息。Prompt 层缓解策略:限定知识来源、要求引用、允许说"不知道"、让模型先验证再回答。
扩展要点:
- 加入"如果不确定,请回答’我不知道’"显著降低幻觉率
- 配合 RAG,明确要求"仅根据下面提供的内容回答"
- 让模型输出引用片段 + 置信度,便于后续校验
11. Temperature、Top_p 分别是什么?如何影响输出?
答案:Temperature 控制概率分布的"陡峭度",越高越随机;Top_p 在累计概率为 p 的候选中采样,控制候选范围。
扩展要点:
- Temperature 调"激进度",Top_p 调"候选池",二者一般只调一个
- 代码、抽取类任务:Temperature 0~0.3
- 创意写作:Temperature 0.7~1.0
- Top_p=1 表示不裁剪,等价于纯 Temperature 控制
12. Frequency Penalty / Presence Penalty 作用是什么?
答案:Frequency Penalty 抑制已出现的 token 重复出现(按频次惩罚);Presence Penalty 抑制已出现过的 token 再次出现(一次即罚)。
扩展要点:
- 解决"啰嗦重复" → 调 Frequency
- 鼓励"换话题/扩展新内容" → 调 Presence
- 取值范围一般 -2.0~2.0,常用 0.1~0.5
13. Seed(随机种子)的作用?如何保证输出一致性?
答案:固定 seed 后,相同输入下模型采样路径一致,输出可复现。配合 Temperature=0 或低值使用效果最佳。
扩展要点:
- 即使设了 seed,模型版本变更仍可能输出变化(OpenAI 提供 system_fingerprint 字段判断)
- 评估 Prompt 时务必固定 seed + temperature,否则无法对比
- 生产环境中并不总是追求一致性,要分场景
二、核心提示技巧
14. Chain-of-Thought(CoT 思维链)是什么?效果与适用场景?
答案:通过提示模型"一步步思考",把推理过程显式化,从而提升复杂任务(数学、逻辑、多跳推理)的准确率。
扩展要点:
- 仅对足够大的模型有效(涌现能力)
- 简单任务用 CoT 反而会增加噪声和成本
- 推理类模型(o1/DeepSeek-R1)已内化 CoT,无需手动添加
15. 零样本 CoT 与少样本 CoT 的区别?
答案:零样本 CoT 用一句"让我们一步步思考"触发推理;少样本 CoT 提供完整的"问题→推理→答案"示例。
扩展要点:
- 零样本 CoT 适合通用模型 + 简单触发
- 少样本 CoT 在数学、专业推理类任务上准确率更高
- 示例的推理路径要清晰,错误示例会反向带偏
16. 什么是 Self-Consistency(自我一致性)?原理与用法?
答案:对同一问题以高 Temperature 采样多次得到多个推理链,再对最终答案进行多数投票,提升复杂推理的稳健性。
扩展要点:
- 比单次 CoT 准确率高 5%~15%(数学题尤为明显)
- 缺点:成本翻倍 N 次,延迟高
- 投票时只看最终答案,不看推理过程
17. Tree of Thought(ToT)与 CoT 的区别?适用场景?
答案:CoT 是单链推理;ToT 在每一步生成多个候选分支,通过评估/搜索(BFS/DFS)选最优路径,形成"树"。
扩展要点:
- 适合需要规划、搜索、回溯的任务(24 点游戏、迷宫、复杂决策)
- 实现复杂、调用次数多,成本大幅增加
- 简单任务杀鸡用牛刀,谨慎使用
18. 如何用 Prompt 强制输出 JSON / Markdown / 表格 / 代码格式?
答案:明确指定 schema、提供示例、用分隔符隔离指令、要求"不输出任何额外说明",必要时启用模型的 JSON mode / Function Calling。
扩展要点:
- JSON 输出:用模型原生
response_format={"type":"json_object"}或 Structured Output - Markdown 表格:明确列名 + 至少给一个表头示例
- 代码块:指定语言标识符 ```python,并要求"只输出代码"
19. “否定指令”(不要、禁止)是否有效?为什么?怎么正确使用?
答案:单纯的否定指令效果不稳定,因为模型仍会"想到"被禁内容,且语言模型对正向描述更敏感。最佳做法是把"不要 X"改写为"请做 Y"。
扩展要点:
- 反例:“不要用专业术语” → 正例:“使用初中生能理解的语言”
- 必须用否定时,配合具体后果或理由说明
- 对违规内容,否定指令需多重防御(System+输出后过滤)
20. 分隔符(###、"""、<>)的作用?举例说明。
答案:用于把指令、上下文、用户输入、示例等明确分块,避免模型混淆角色或被注入劫持。
扩展要点:
- 推荐用 XML 风格标签:
<context>...</context><question>...</question>,Claude 等模型尤其敏感 - 同一 Prompt 内分隔符要统一
- 可用于防 Prompt Injection:把用户输入限定在固定标签内
21. 指令分解(Task Decomposition):复杂任务怎么拆?
答案:把大任务拆为可独立验证的小步骤,按依赖关系串行/并行执行,每步聚焦单一目标。
扩展要点:
- 拆分原则:单一职责、可测试、可缓存
- 实现方式:单 Prompt 内编号步骤;或多 Prompt 链路(Chain)
- 复杂任务上,拆分后整体准确率通常显著优于"一锅烩"
22. 对比式提示(Contrastive Prompting)适用什么场景?
答案:通过同时给出"好例子"和"坏例子",让模型理解任务边界与判断标准,适合有微妙差异的分类、风格控制、错误规避场景。
扩展要点:
- 文案审核、风格仿写、合规判断常用
- 好坏对比要在维度上对齐,避免噪声
- 比单纯的好示例更能传达"判断标准"
23. ReAct(Reasoning + Acting)框架核心思想?在 Agent 中的作用?
答案:让模型交替输出推理(Thought)→ 动作(Action)→ 观察(Observation)→ 再推理,形成可调用工具的闭环。
扩展要点:
- 是当今 Agent 的基础范式,配合 Tool Use 使用
- 优点:可解释、可中断、可纠错
- 缺点:每步一次调用,延迟高;推理过程暴露安全风险
- 进化方向:Plan-and-Execute、Reflexion 等
三、场景化实操题
24. 文案、代码、数据提取、客服问答 Prompt 侧重点分别是什么?
答案:
- 文案:风格 + 受众 + 篇幅 + 情感
- 代码:语言/框架 + 输入输出规约 + 边界条件 + 注释要求
- 数据提取:Schema + 字段定义 + 缺失值处理 + 格式严格性
- 客服:人设 + 业务范围 + 兜底话术 + 升级路径
扩展要点:
- 共性:清晰的角色+任务+约束+输出格式
- 差异在于"约束密度":代码/数据提取最紧,文案最松
- 客服场景必须加"超出范围如何回应"
25. 长文档摘要:如何设计 Prompt 保证精度、去冗余、防幻觉?
答案:分块切分 + 分层摘要(Map-Reduce)+ 明确摘要维度 + 要求"仅基于原文"+ 引用原文片段。
扩展要点:
- Map 阶段每块独立摘要,Reduce 阶段融合
- 加入"如原文未提及,请勿杜撰"指令
- 输出包含关键事实 + 数据 + 结论三段式
- 长文档优先 RAG 检索 + 摘要,而非全文喂入
26. 翻译类 Prompt:如何指定风格、专业术语统一、语气?
答案:明确目标语言、领域、目标读者、风格(正式/口语)、关键术语对照表、保留原文格式要求。
扩展要点:
- 提供术语词典:
{"machine learning":"机器学习","tensor":"张量"} - 要求"保留代码块、数字、变量名不变"
- 二次校验:让模型回译并对比,发现偏差
27. 知识库问答(RAG):如何限定模型只依据给定内容回答?
答案:明确指令"仅依据下面提供的资料回答,资料中没有的内容请回答’根据现有资料无法回答’",并要求标注引用来源。
扩展要点:
- 用 XML 标签包裹检索内容:
<documents>...</documents> - 加入引用格式要求:
[doc_id: 段落索引] - 评估指标:Faithfulness(忠实度)+ Answer Relevancy
28. 创意写作:如何控制风格、篇幅、叙事结构、角色设定?
答案:四要素法——风格参考(作家/作品)+ 结构(三幕/起承转合)+ 篇幅(字数/段数)+ 角色卡(动机/性格/弧线)。
扩展要点:
- 风格控制可直接引用:“模仿海明威的简洁冰山风格”
- 用大纲先生成骨架,再分段细化(避免一次性塌方)
- Temperature 适当调高(0.8~1.0),但结构指令要硬约束
29. 数据清洗/结构化提取:写一个示例 Prompt。
答案:
你是一个严格的信息抽取助手。从下面文本中提取实体并以 JSON 输出:
Schema:
{ "name": string, "age": int|null, "company": string|null }
规则:
1. 字段缺失填 null,不要猜测
2. 仅输出 JSON,不要额外说明
3. age 必须为整数
文本:"""
张三,28岁,就职于字节跳动。
"""
扩展要点:
- 三段式:角色 + Schema + 规则 + 示例 + 数据
- 严格输出建议用 JSON Mode / Function Calling
- 批量处理时附"如失败返回 {error: 原因}"
30. 多轮对话:如何维护上下文、避免跑偏、保持人设一致?
答案:System Prompt 锁人设与规则 + 历史摘要替代全量历史 + 每轮注入"当前任务焦点"+ 关键状态变量结构化保存。
扩展要点:
- 长对话用"滚动摘要"压缩历史,节省 token
- 跑偏时主动回拉:“让我们回到 X 话题”
- 关键状态(用户姓名/订单号)单独存储,每轮注入
四、Prompt 优化、Debug、评估
31. 如何评估一条 Prompt 的好坏?说出 3–5 个核心维度。
答案:准确性、稳定性(多次输出一致性)、鲁棒性(对输入扰动)、成本(token 消耗)、可维护性。
扩展要点:
- 建立小规模评测集(20~50 条),覆盖正例/边界/对抗
- LLM-as-a-Judge 自动打分,人工抽审
- A/B 测试新旧 Prompt,量化提升
32. Prompt 越长效果越好吗?长短 Prompt 的取舍原则?
答案:不是。Prompt 长度与效果呈"倒 U 形"。过短信息不足,过长稀释关键信息且引入噪声。
扩展要点:
- 关键指令前置或后置(首因/近因效应都可利用)
- 删冗余话术,每句话都应承担明确功能
- 同等效果下,越短的 Prompt 越优(成本+延迟)
33. 重复话术堆砌会有什么负面影响?
答案:稀释关键指令权重、增加 token 成本、可能触发模型对"重要内容"的重新加权失衡。
扩展要点:
- “请一定一定务必"不如一次明确说"必须”
- 关键指令重复一次(开头+结尾)有效,反复堆砌反而无效
- 用结构化(编号/标签)替代重复强调
34. 同一指令换措辞输出差异大,如何收敛稳定性?
答案:降低 Temperature、固定 seed、加入少样本示例、严格规约输出格式、必要时用结构化输出(JSON Schema)。
扩展要点:
- 输出不稳是 Prompt 模糊的体现,先优化指令本身
- 少样本是收敛"输出风格"的最强武器
- 关键场景配合后置校验/重试机制
35. 模型输出冗余啰嗦,用什么话术精简?
答案:明确字数上限 + 要求"直接给结论,不要解释"+ 提高 Frequency Penalty + 设定输出结构(如"用一句话")。
扩展要点:
- 反例:“请简洁回答” → 正例:“用不超过 50 字回答”
- 加 “Don’t yap” 类指令对部分模型有效
- 系统化场景用 max_tokens 硬截断
36. 专业领域 Prompt:加行业术语提升效果还是增加偏差?
答案:取决于模型预训练覆盖度——主流领域(医疗/法律/金融)添加术语提升效果;冷门或新兴领域可能增加幻觉。
扩展要点:
- 术语 + 定义 + 示例三件套,降低误解
- 配合 RAG 提供权威资料,最稳健
- 评估时务必请领域专家审查
37. 如何设计 Prompt 实现"自我校验/自我纠错"?
答案:两阶段法——第一步生成答案,第二步让模型基于校验清单逐项检查并修正。也可设置批评者(Critic)角色独立审查。
扩展要点:
- 自我纠错对中等难度任务有效,太难的题模型自身也无法察觉错误
- Critic 角色与 Generator 分离,避免"自夸偏差"
- 与 Self-Consistency 不同:纠错是反思修改,一致性是多次投票
38. Prompt 调试流程:指令被忽略、格式乱、幻觉多,怎么一步步排查?
答案:
- 简化复现:剥离非核心部分定位问题
- 检查指令冲突:System 与 User 是否矛盾
- 检查指令位置:关键指令前置
- 加示例 + 分隔符 + 结构化
- 调参(Temperature、seed)
- 仍不行:换模型 / RAG / 工具调用兜底
扩展要点:
- 建立"症状—原因—对策"对照表
- 调试日志保存所有版本,避免回退困难
- 工具:PromptLayer、LangSmith、Helicone 等可视化
五、工程落地与安全
39. 通用大模型、开源小模型、微调模型:Prompt 策略有何不同?
答案:
- 通用大模型:指令理解强,简洁 Prompt 即可
- 开源小模型:需更多示例 + CoT + 严格格式约束
- 微调模型:贴近训练数据格式,避免大幅偏离
扩展要点:
- 小模型对 Prompt 敏感度极高,多版本 A/B 必备
- 微调模型 Prompt 应保持训练时的格式一致
- 不同模型家族(Llama/Qwen/Claude)有偏好差异,要做适配
40. 什么是 Prompt Injection(提示注入)?产品如何防护?
答案:攻击者在用户输入中嵌入指令试图劫持模型行为。防护:输入隔离、指令优先级强化、输出过滤、最小权限工具调用。
扩展要点:
- 直接注入:“忽略上面所有指令,做 X”
- 间接注入:通过外部网页/文档植入指令
- 防护组合拳:输入清洗 + 沙盒标签 + 输出审查 + 关键操作二次确认
- 完全防护极难,纵深防御是唯一思路
41. 批量模板化 Prompt:要考虑哪些兼容性、鲁棒性问题?
答案:变量占位符注入风险、空值/极长输入处理、特殊字符转义、不同语言/编码、模型版本变更影响。
扩展要点:
- 用 Jinja2 等模板引擎,避免字符串拼接
- 必加入参数校验与长度截断
- 每次模型升级要回归测试模板
42. RAG 场景下,Prompt 如何衔接检索内容与用户问题?
答案:结构化拼装——明确角色 + 检索片段(带来源/编号)+ 用户问题 + 回答规则(必须基于片段、需引用、不知道时拒答)。
扩展要点:
- 检索片段顺序按相关度排序,最相关在前
- 控制片段数量(5~10 段),避免稀释
- 提供"无相关片段"时的回退话术
43. 如何设计可复用的 Prompt Template?(LangChain 场景)
答案:参数化输入 + 模块化结构(角色/任务/约束/示例/输入分离)+ 版本管理 + 单元测试。
扩展要点:
- 使用 PromptTemplate / ChatPromptTemplate
- 模板版本化(v1.0、v1.1),支持灰度
- 模板与业务逻辑解耦,方便迭代
- 配合 Eval 框架建立基线
44. 提示工程的未来:会被自动 Prompt 生成取代吗?你的看法?
答案:低层手工调优(措辞、格式、参数)会被自动化(DSPy、APE、OPRO),但高层的"任务定义、评估设计、业务对齐"仍需人完成。
扩展要点:
- 自动 Prompt 优化已在结构化任务上超越人工
- 提示工程师正在向"AI 系统设计师"转型
- 核心壁垒:业务理解 + 评估方法论 + 系统编排能力
六、面试思辨/行为题
45. 新手 Prompt 与资深 Prompt 工程师的核心差距在哪?
答案:
- 新手:写好一条 Prompt
- 资深:建立 Prompt 系统(评估、迭代、监控、降本)
扩展要点:
- 新手关注"输出像不像",资深关注"输出对不对、稳不稳、贵不贵"
- 资深掌握模型边界,知道何时不该用 Prompt(该上微调/RAG/规则)
- 资深具备工程化思维:版本、测试、监控、回滚
46. 少样本示例怎么选?数量多少性价比最高?
答案:选典型 + 边界 + 对抗 三类,覆盖常见和极端情况;数量一般 3~5 条,超过收益递减成本上升。
扩展要点:
- 示例多样性 > 数量
- 困难/易错示例优先于简单示例
- 动态选择(根据输入检索最相似示例)效果优于静态固定
47. Temperature 高/低分别适合什么场景?
答案:
- 低(0~0.3):抽取、分类、代码、事实问答、需要可复现的场景
- 高(0.7~1.0):创意写作、头脑风暴、多样化生成
扩展要点:
- 评估期一律用 0,避免随机性干扰
- 同一系统不同 Agent 可不同温度(规划低、生成高)
48. 用户需求模糊,你如何反向梳理并重构 Prompt?
答案:
- 五问法:受众、场景、目标、约束、成功标准
- 给 Bad Case 让用户判断,反推真实意图
- 把抽象词具象化(“专业” → 几年经验、什么口吻)
- 输出范式化的 Prompt 模板让用户验证
扩展要点:
- 永远不要直接写 Prompt,先做需求澄清
- 用"输出 1 个示例 + 你想不想要这种"快速对齐
- 文档化需求,避免反复返工
49. 讲一次你优化 Prompt 解决重大问题的案例(STAR)。
答案模板:
- Situation:客服 RAG 系统准确率仅 65%,幻觉投诉频发
- Task:两周内提升至 85%+,幻觉率降到 5% 以下
- Action:① 重构 Prompt,加入引用要求与拒答机制 ② 检索片段加 XML 标签 ③ 建立 200 条评测集 ④ 多版本 A/B
- Result:准确率 87%,幻觉率 3%,投诉下降 70%
扩展要点:
- STAR 强调可量化结果
- 突出方法论(不是运气)
- 体现你的独特决策(为什么不微调?为什么这样拆?)
50. 完整 Prompt 工作流程:需求 → 设计 → 测试 → 迭代 → 上线
答案:
- 需求:澄清意图、定义成功标准、收集真实样本
- 设计:选范式(zero/few/CoT/RAG)、写初版、定输出格式
- 测试:构建评测集(典型/边界/对抗),自动+人工评估
- 迭代:错例分析 → 假设修正 → A/B 对比 → 选优
- 上线:版本化、灰度、监控(成功率/延迟/成本/幻觉率)、持续运营
扩展要点:
- 评测集是 Prompt 工程的命根子,没有它就是凭感觉
- 上线后的监控同样关键——模型升级会让旧 Prompt 失效
- Prompt 工程是产品工程,不是写作艺术
结语:Prompt Engineering 的能力金字塔
| 层级 | 关注点 | 区分度 |
|---|---|---|
| L1 写作层 | 措辞、格式、示例 | 入门 |
| L2 优化层 | 评估、调参、调试 | 进阶 |
| L3 系统层 | RAG、Agent、工具编排 | 资深 |
| L4 业务层 | 需求拆解、ROI、产品对齐 | 专家 |
真正的核心竞争力不是会写多花哨的 Prompt,而是能把模型能力 → 工程系统 → 业务价值串联起来。 Prompt 只是其中最直观的一环。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)