Agent时代的存储(上):有了“Memory”还要“Harness”?Agent的痛点到底在哪?
作者:FTS、HJ from AISYS-Group@Shanghai AI Lab
如今,越来越多的Agent开始“干活”,Token消耗呈指数级增长,算力贵、稳定性差等问题也日益突出;在控制Agent成本和稳定性两个方面,大家做了很多尝试,却没有达成共识。本文会分享笔者对于Agent成本和稳定的思考。具体而言,我们将从存储这一点切入,分上下两篇展开,上篇中我们将:①描述Agent的成本和稳定问题,挖掘这个问题的根因,讲讲为什么我们会选择存储作为答案。②介绍业界火热的答案,展开分析方案中的核心贡献和关键矛盾。③复盘借鉴推荐系统中的工程共识与和优化思路,聊一聊数据格式、搜索方案、优化假设等工作如何嵌入到大模型时代的存储方案中。在下篇中我们会用一个简单的假设关联现有的尝试,选取业界共识的技术,在Agent典型工作场景中做一些新的局部性优化实验,敬请期待!
一、背景介绍:如何理解Agent时代的存储
2026年伊始,Agent市场上最火热的就是OpenClaw了。历经半年的发展,社区里出现了越来越多的用户吐槽:“499安装OpenClaw之后再花299卸载”,“我的Claw怎么越养越笨了?”,这些问题反映出了Agent 时代的影响用户体验的两个核心问题——Agent使用的成本和稳定性。而从技术层面看,它们与推理过程的组织方式息息相关,尤其是推理时对上下文与外部信息的使用方式。
从模型定义上看,推理是 next-token prediction,即预测接下来最可能出现的词元。但在真实应用里,推理通常不是单次生成,而是一系列的生成与引用的决策。在最常用的Agent Search 中,提示模板、会话历史、长期记忆、检索结果、工具返回、缓存产物与数据库记录,都会在不同阶段被模型引用。若主要由“生成”来推进任务,会带来两类后果:一是 token 与工具调用次数增加,导致成本上升;二是长程任务的误差累积更明显,出现偏航、重复、循环调用等稳定性问题。
为优化上述问题,从传统的RAG 到 新兴的Memory,从最初的Function Calling 到 近期备受关注的Harness ,业界都在尝试:在正确的时机提供给Agent可用信息,并约束推理的执行边界,从而降低无效生成与不可控行为。我们将这种工程共识总结为:在推理过程中需要引入更多“引用”,并将其系统化。
我们提出”引用“这个概念不仅是为了消除歧义,还为了说明这些业界实践背后都高度依赖于存储方案的支持。我们认为Agent时代的存储不再只是“把东西放起来”,而是一套围绕“可引用性” 建立的机制:让信息在合适的时刻、以合适的形态、用可控的成本被再次使用。
二、从Memory和Harness讲起:大模型场景中的存储新需求与关键矛盾
如果说 2025 年大家都在谈 Agentic,那么到 2026 年,越来越多的讨论开始转向 Memory 与 Harness。这种转变说明市场已经不满足于“大模型能完成一次性任务”,而是希望它在长程任务里能够保持状态、继承进度、验证结果,并持续推进。
在存储视角下,长程任务会改变系统访问数据的方式:Agent 不再随机触碰全量知识库,而是围绕当前目标反复引用一小片状态、证据和工具结果。沿着这条线索,本节将分别介绍 Memory、Harness,并归纳我们认为的关键矛盾与存储新需求。
Memory:大模型面对长程任务的基础
关于Memory,我们在先前的文章《Agent Memory(上):记忆的形态、功能与代表性路径》及《Agent Memory(下):工作记忆折叠、会话档案化与记忆演化》中有过非常详细的介绍,欢迎感兴趣的朋友前往查看!
Memory实际上就是大模型对于存储的需求。事实记忆回答“智能体知道什么”,经验记忆回答“智能体如何改进自身”,工作记忆回答“智能体现在正在处理什么”。这些信息最终都要被组织成当前步骤可消费的状态。在长程任务中这些记忆通常会有三个过程: 记忆形成,记忆演化和记忆检索。其中,记忆检索最直接也最显著地影响着任务的成果:它决定了何时检索,怎么构造 query,用什么策略检索,取回后怎么用。这些环节可以让模型维持“认知连续性”,让长程任务的状态清晰,执行可靠,成本可控。
但是纯靠Memory的约束,大模型只能解决“状态如何留下来”,而执行长程任务更重要的是“状态如何被使用”,于是另一个关键词闪亮登场——“Harness”。
Harness:大模型执行长程任务的标准
在Anthropic的文章中,把长程 agent 的核心挑战定义为:每个新 session 都“no memory of what came before”,Harness 的目的就是“bridge the gap between coding sessions”。他们对Harness的定义是:让 agent 能稳定完成长程任务的一套外部工作环境与流程脚手架:用一组可读、可执行、可持续迭代的工件,把多轮/多窗口会话串起来,避免每次新 session “从零开始”。
Harness 通常由一组标准化工件组成,在不改变模型参数的前提下,赋予了模型额外的能力——当“完成定义”和“验证证据”都被外置成可读工件后,运行时的策略自然会趋向:优先引用这些工件与测试证据来推进任务;只有在证据不足或代价过高时,才回到纯生成补全。这就像是提前为模型立好了一套行为规范与执行边界。
这种能力解决了几种很具体的失败模式:agent 容易一次性做太多,做到一半耗尽上下文;下一轮接班时只能猜上一轮发生了什么;项目后期看到已有进展后,又可能过早宣布“已经完成”。面对Multi-agent system,Harness 会扩展为:Planner 负责规格,Generator 负责实现,Evaluator 负责验证。这里的关键不只是“多几个 agent”,而是把生成者和评价者拆开,让评价者更怀疑、更具体、更贴近验收标准。另外值得注意,这种能力是不绑定某种特定模型的。
但是Harness 复杂度不能无条件增加。每一个 planner、evaluator、context reset、subagent 或 review loop,都是在假设“当前模型单独做不好某件事”。当模型能力变化、任务类型变化、工具接口变化时,这些组件是否仍然必要,都需要重新验证。好的 Harness 不是越复杂越好,而是把模型当前不稳定的能力外置为可引用、可检查、可替换的系统能力。随着模型变强,一些原本必要的结构可能会变成冗余。这看起来会变成一个很复杂的工程优化,但它背后的关键矛盾其实很朴素:模型什么时候应该继续生成,什么时候应该停下来引用已有状态、规则、证据或工具结果。Memory 和Harness最终都会落到同一个运行时的选择:生成 token,还是引用 data。
原子决策:生成token还是引用data
正如开篇提到的:真实应用里Agent的行为是一系列的“生成 / 引用”的序列决策。也就是说长程任务和Multi-agent system的关键矛盾都是生成token还是引用data,一旦这样假设,我们遇到的问题就会落到同一张图上:上下文工程、长期记忆、RAG、搜索、工具调用、缓存、日志回放,都是外部可引用数据源;压缩、重排、裁剪、权限、TTL、命中率、延迟与 token 成本,都是围绕引用路径展开的系统优化。这些其实都是大模型对于存储的需求。
我们以最常用的Agent Search场景举例。在传统视角下,Agent Search是一个纯引用data的过程,但是在大模型推理输出中却由“生成+引用”组成——系统先判断哪些信息值得引用,再缩小候选、读回证据、压缩注入上下文,最后由模型继续生成:
Memory / Harness / 领域数据
-> 判断是否需要引用
-> 找到相关候选
-> 读回证据正文
-> 重排 / 压缩 / 注入上下文
-> 模型继续生成这样抽象后优化逻辑就会变得更简单:我们不必把系统当成一个黑盒的搜索服务,而是把每次引用拆成几个可独立调参的环节——哪些信息值得引用(Memory/Harness)、怎么缩小候选(embedding + metadata filter)、候选怎么找(ANN)、证据怎么读回(payload fetch)、读回后怎么变成可消费上下文(rerank/compress/inject)。每一步对应的指标也更直接:命中率、延迟、IO 次数、payload 字节、token 占用、以及“引用是否真的提升了结果”。
更重要的是,引用视角天然支持任务拆分与并行协作。因为协作的对象不再是“共享一段复杂对话”,而是“共享一组可引用的外部工件”:检索到的证据、工具返回、评测结果、进度状态、缓存条目。这样一来,多智能体并行不一定需要复杂协议:只要写入格式稳定、可追溯、可回放,不同角色就能围绕同一批引用对象各做各的事——有人负责找证据,有人负责验证,有人负责压缩与注入,有人负责产出最终生成。同样地,长程任务也不一定必然失控。真正让任务漂移的往往不是“跑得久”,而是“目标与状态不可引用”。当目标清晰、完成标准可引用、进度与证据可引用,Agent 即使跨多个上下文窗口运行,也能像工程流水线一样稳定推进:每一轮都在同一条引用路径上做增量改进,而不是在越来越长的对话里续写。
从这个视角继续往下推,“引用”就不再是一个独立的新问题,而是存储问题的一个切面:凡是能被引用的东西,首先必须能被保存、被组织、被定位、被回查;引用只是在运行时把这条路径走一遍,并决定走到什么深度、付出多少成本。换句话说,我们今天讨论的“引用优化”,本质是在讨论“哪些数据值得被放进推理链路、以及如何以可控代价把它们读出来”。
这方面的工作可以借鉴互联网时代的经验。引用对应的就是一次搜索链路(召回、过滤、重排、压缩、注入),而被引用的内容最终一定要落到某种数据形态上:schema 怎么定义、payload 怎么切分、元数据怎么过滤、版本与权限怎么追溯、物理布局怎么决定回查成本。下一节我们将具体介绍一下比较有代表性的几项工作。
三、从行业经验中获得启发: 互联网共识里的“新”方案
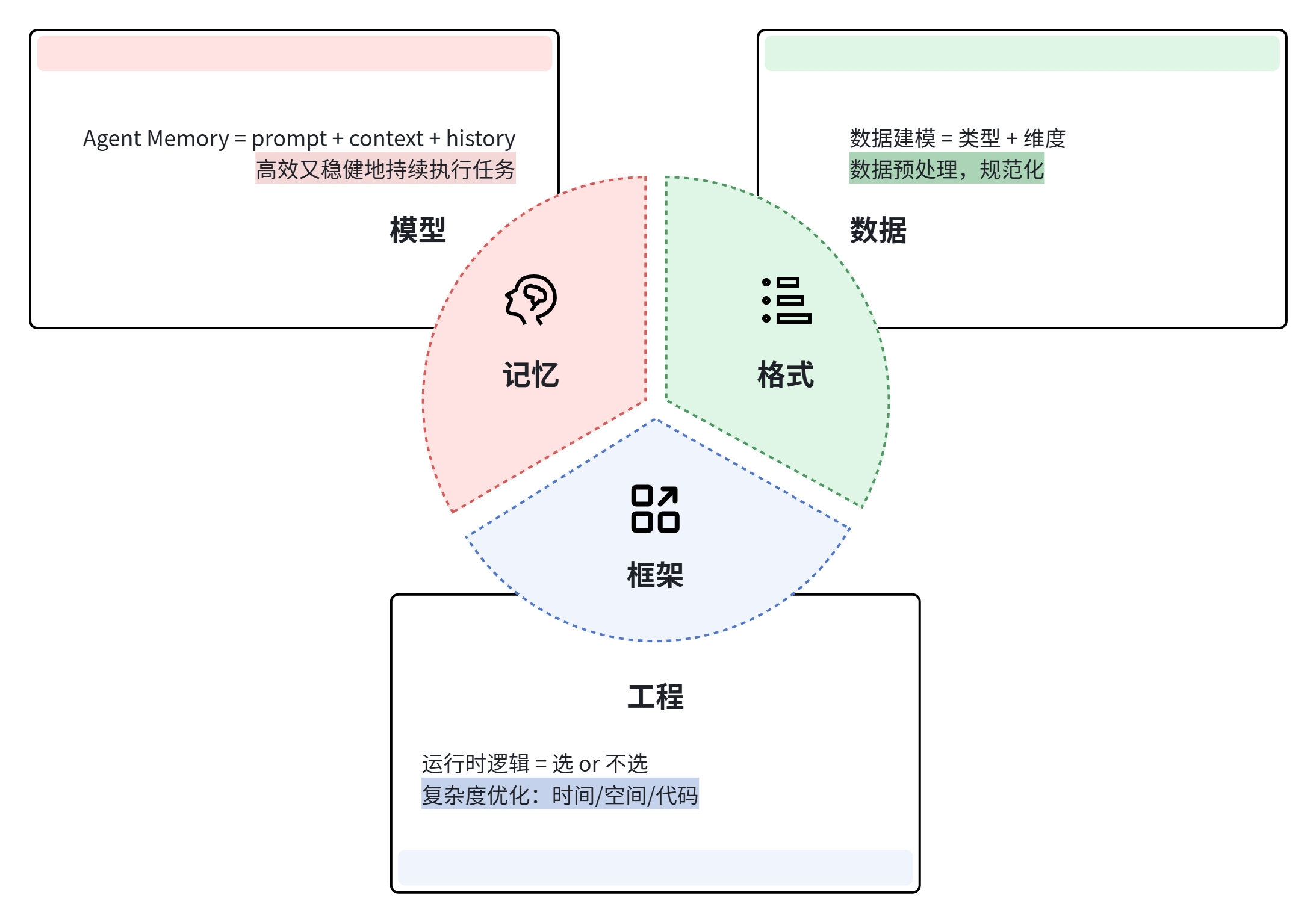
为避免讨论发散,下面我们先统一一下在大模型场景下谈“存储”时不同角色的关注点:
-
模型方(记忆):关注“推理如何被历史影响”。目标不是把信息堆进上下文,而是在有限窗口与预算下,把
prompt + context + history组织成当前步骤可消费的先验——为“选引用”提供高价值候选,并降低“盲生成”的不确定性。 -
数据方(格式):关注“信息以何种形态才能被引用”。目标是把原始内容建模为可检索、可组合、可评估的表示(schema/元数据/粒度/版本/权限),决定“能引用什么、怎么引用、能否稳定复用”。
-
工程方(框架):关注“系统如何在运行时做取舍”。目标是把引用链路封装成可配置、可观测、可迭代的策略与组件(DB/Search/RAG/Cache),在延迟、成本与复杂度之间做出可解释的“引用/生成”决策。
在这一节里,我们将选取数据格式、搜索方案、优化假设这三类的代表性工作,并解释它们如何嵌入到大模型时代的存储方案中。
Lance格式:从列式到引用集合
数据方的存储最关注信息的存在形态。我们注意到在初期,大模型往往选择Markdown、YAML、JSON 与 Jinja 这些数据格式。但随着数据规模增长,越来越多的项目选择Parquet 这类列式格式。从 Markdown 到 Parquet,格式演进的终点不是“更复杂的文件”,而是让数据更容易被调用。轻量阶段需要规则、样本和 prompt 模板;规模上来以后,列投影、条件过滤、压缩和高吞吐扫描会变成底座能力。这和互联网时代数据演进的路线是一致。
但 Parquet 格式也有边界,当Agent任务不只是扫描结构化表,而是要在 embedding、metadata、长文本 payload、工具轨迹和多模态 blob 之间做随机访问、过滤和回查。需要一类数据格式牺牲一部分压缩,来换取检索能力的增强。
Lance 这类面向 AI 工作负载的格式,原先为了数据湖场景设计,它把“检索、随机访问、多模态存储”下沉为底座能力,在Agent场景下这样的设计会有很大的优势:
-
存储格式中包含Agent所需的所有信息。在 Agent Search 里,一条样本通常不是单纯的文本。它至少包含三类信息:用于语义召回的 embedding,用于过滤、权限和路由的 metadata,以及最终要交给 reranker 或模型阅读的 payload。
-
优化了随机访问和向量工作负载。它通过 manifest 记录数据集版本和 fragment 组成;每个 fragment 内部按列组织数据,列数据再被拆成适合读取和跳过的物理单元。这样做的好处是:metadata filter 可以只读相关列,embedding 可以参与向量索引,payload 又可以在候选确定后被按 row id 回查。
-
版本控制和轨迹追踪。这和传统“对象存储放原文、数据库放路径、向量库放 embedding”的三套系统相比,有一个重要区别embedding、metadata 与 payload 不再只是松散拼接,而是能在同一个数据集抽象下被索引、过滤、回查和版本化。这意味着“找到候选”和“读回证据”可以被放到一条更统一的引用路径里优化。
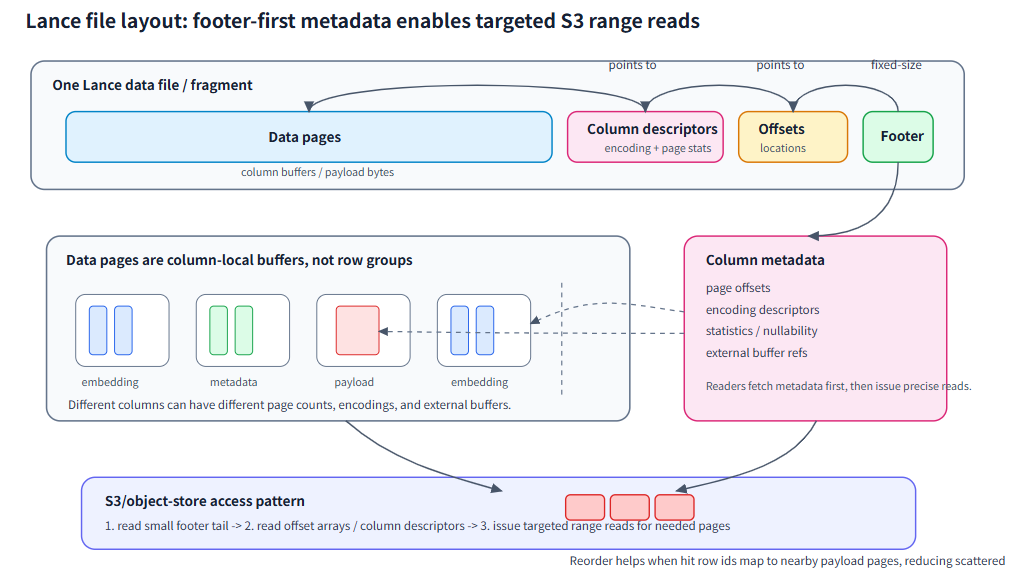
Lance 把向量、结构化字段和证据正文放到同一份数据抽象中,让“找到候选”和“读回证据”可以一起优化
基于Lance存储格式,我们可以进一步优化访问布局,它承担的角色可以拆成两层:
-
逻辑层:
embedding / metadata / payload共同描述一条“可引用样本”; -
物理层:
fragment / column / page / row id决定这条样本“如何被读出”。
逻辑层解决的是“能不能被检索、能不能被过滤、能不能被模型引用”;物理层解决的是“引用一次要读多少次、读多少无关字节、相邻回查能不能合并”。前者决定可调用性,后者决定调用成本。我们存储优化的着力点更倾向于“相似数据在物理上是否挨在一起”,比如在下一篇中会重点介绍的我们做的reorder实验。在实验原型里,我们把向量索引里已经形成的语义分组,投影到存储层的物理布局上:语义上相近的样本,尽量在文件里也更接近。后文把这件事称为紧凑布局;对应的实验命令只是原型实现细节,不是上游 Lance 默认能力。
向量索引:从候选到证据回查
互联网时代的推荐系统,本质是在做两件事:召回与排序。召回负责从海量内容里快速找到一小撮“可能相关”的候选(高 recall、低成本),排序负责在候选上做更精细的打分(高 precision、可解释)。早期召回主要依赖协同过滤、图关系与倒排索引等信号;随着 embedding 成熟,语义相似性成为新的召回通道,但并没有替代全文检索,而是催生了业界共识的 hybrid retrieval:全文检索 + 向量检索。
在大模型时代,以向量检索为基底的RAG技术一度成为引入外部数据的首选方案。不仅因为以embedding 表征语义相似性,做近邻召回的做法与 Transformer 在表示空间里用向量进行匹配、选择和组合的思想是同构的,还在于RAG 在结构上与推荐系统高度同构:它同样是“召回 → 重排/压缩 → 注入 → 生成”的流水线,只是最终的“排序输出”变成了“把证据放进上下文,让模型完成生成”。它把推荐系统的检索与排序经验,迁移到了大模型的引用链路上,并额外解决了上下文窗口、token 成本与证据组织的问题。
但随着模型能力的增强,越来越多的项目更倾向绕过RAG系统,通过索引的方式来直接进行查询。这样的方式通常不会把所有向量完整扫一遍,而是先把语义空间切成很多粗粒度区域,再只在少量相关区域里找候选。具体实现可以是 IVF、PQ 等索引结构,它们共同带来的访问模式:先找到候选,再读回候选背后的证据。向量索引只解决了“候选在哪里”,但 Agent 真正需要引用的是候选背后的文本、工具结果、日志片段或文档上下文。对于少量候选查询,这个回查成本可能不显眼;但当系统需要读回较大候选集做重排、聚合或证据拼接时,读回证据正文就会成为引用路径里的主要成本之一。候选如果在物理上高度离散,就会产生大量随机读;如果它们在文件里相邻,读取器就有机会把多个小读合并成更少的连续读取。
到这里,语义检索问题已经变成了存储布局问题,这也是我们做动态控制实验的初衷。
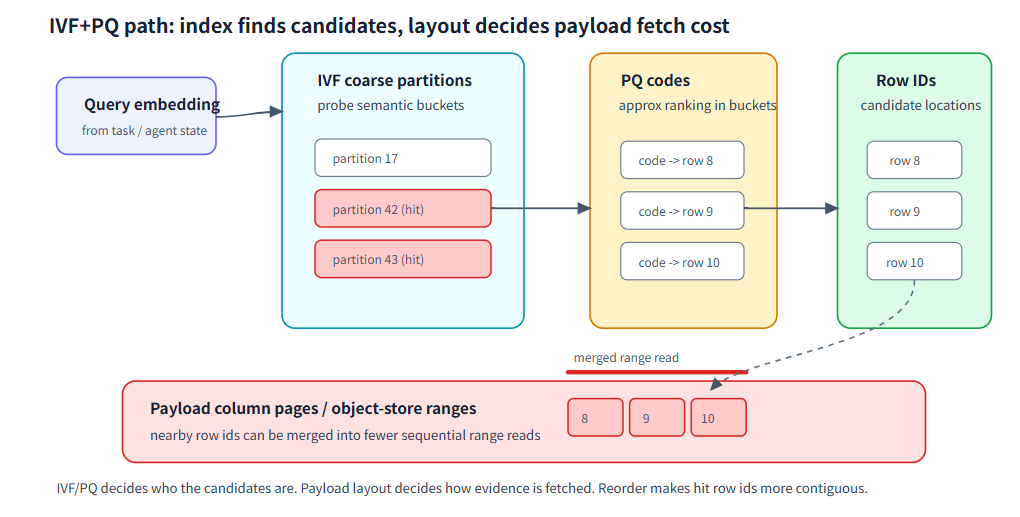
向量索引只决定候选在哪里;候选之后的证据回查,才把语义检索问题重新带回存储布局
局部特性:从通用到特殊场景
“让存储尽可能贴近计算”一直是存储优化的思路。但在大模型时代,随着存储规模的扩大也许这个思路会变成“让部分存储尽可能贴近计算,所有存储保持一致”。这个变化也会改变我们之前的ANN策略。通用向量检索基准测试往往假设 query 分布近似均匀,但 Agent Search 的真实访问负载通常不是这样。同一个会话、同一个租户、同一批验证证据,会反复触达相近的语义区域;重排、评估和多轮验证也常常需要读回一批相关候选,而不是只取一个点。
如果 ANN partition 与 payload 的物理布局能对齐这种局部性,系统就有机会把语义上的相近访问转化为存储层的顺序访问。
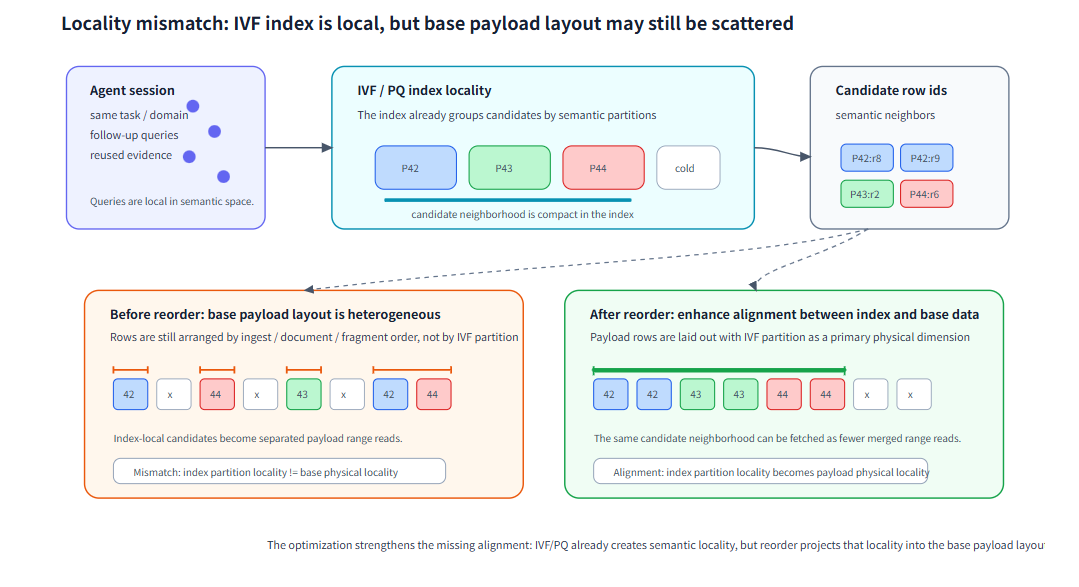
当语义上的相近访问能映射到物理上的相邻读取时,布局优化才有机会减少随机 IO
这里的关键变量可以称为连续性。在打散的数据中,向量索引虽然在语义空间里找到了相邻候选,但这些候选可能散落在不同文件块或对象存储区间上;一次 top-k 回查会退化成很多次小读取。紧凑布局之后,同一语义区域里的样本在物理上更接近,证据正文更容易被合并读取。连续性变好,并不一定意味着读字节必然更少,因为合并读取可能会顺手读入一些无关字节;但它通常会减少请求次数和随机 IO,这是对象存储路径上最有价值的收益来源。换句话说,逻辑上的语义相邻越强,把它们在物理上放近的收益就越大。
如果你喜欢我们的内容,欢迎点赞👍、收藏⭐️、关注➕我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!
参考资料:
https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
https://www.anthropic.com/engineering/harness-design-long-running-apps

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)