YOLO26最新创新改进系列:DRoRAE深度路由表征融合,让多层视觉语义在检测中真正协同,高阶魔改写作创新!
YOLO26最新创新改进系列:DRoRAE深度路由表征融合,让多层视觉语义在检测中真正协同,高阶魔改写作创新!
购买相关资料后畅享一对一答疑!
微信公众号:Ai计算机视觉
畅享超多免费持续更新且可大幅度提升文章档次的纯干货工具!
YOLO26改进创新 | DRoRAE深度路由表征融合,让多层视觉语义在检测中真正协同
本文将围绕 DRoRAE 的原始论文思想与 YOLO26 检测适配策略展开:

一、原文链接
- 论文标题:Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenization
论文地址:https://arxiv.org/abs/2605.10780
二、为什么这篇工作值得拿来做 YOLO26 改进
原文关注的是视觉 tokenizer 只使用最后一层特征导致层级信息浪费的问题,提出 DRoRAE 用深度路由和渐进校正把中间层与末层信息重新融合。
对目标检测研究者来说,真正值得借鉴的从来不只是“原论文在原任务上做得强不强”,更关键的是:它解决的到底是不是一个我们在检测里也会频繁碰到的核心矛盾。
DRoRAE 在这一点上很典型,因为它瞄准的是 只读最后一层编码特征会丢掉大量中间层结构信息。低层视觉细节在深层语义抽象过程中会变成衰减残差。 和 视觉标记器的表示丰富度被严重低估。。这些问题在原论文里出现于 Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenization 对应的任务域,但一旦转到 YOLO26,我们会发现它们几乎都能在检测特征流中找到对应影子。

三、原文摘要翻译
原文摘要首先指出,当前很多表征自编码器虽然复用了强大的预训练视觉编码器,但在做视觉 标记时几乎都默认只取最后一层输出,这使得中间层丰富的层次化信息被整体丢弃。
作者进一步证明,低层视觉细节并不是彻底消失,而是在多层语义抽象后以衰减残差的形式埋在最后一层中。基于这一观察,论文提出 DRoRAE,也就是 Depth-Routed Representation AutoEncoder。它通过能量约束路由与渐进校正机制,自适应聚合各层编码特征,构造出更丰富的潜表示。在 ImageNet-256 等任务中,DRoRAE 显著改善了重建和生成指标,并揭示了融合容量与表征质量之间的可预测扩展规律。
四、原文引言翻译整理
引言部分最值得检测研究者借鉴的地方在于:作者并不是简单地说“多层特征更好”,而是从表示丢失机制出发,解释为什么最后一层并不天然是最佳答案。视觉模型的浅层更擅长表达边缘、纹理、局部结构,中间层兼顾模式组合,高层则更偏抽象语义。如果只保留最后一层,那么许多对精细定位很关键的结构信息会被过度压缩。对目标检测来说,这个逻辑更加成立,因为定位和分类本来就需要不同层次的信息协作。因此,把 DRoRAE 的深度路由思想蒸馏进 YOLO26,本质上是在强化“多层语义-细节协同”的检测表达。

五、原理解析:把论文的核心抓手翻成检测语言
只看论文不深度精读,不知道它真正改变了哪条信息流,那改进文章通常会写得很虚。DRoRAE 的价值并不在“换了个更复杂的块”,而在于它重新定义了特征在网络内部应当如何流动。
首先,从原文角度看,作者强调的关键抓手包括:设计深度路由模块,自适应聚合各编码层信息。;引入 incremental correction,避免简单堆叠造成冗余扰动。;把多层信息融合能力和重建质量联系起来,提出丰富的视角。这些抓手如果直接照抄到检测网络里,要么接口不兼容,要么成本过高。因此,真正高质量的 YOLO26 融合写法不是整网照搬,而是抓住最能转化成 2D feature block 的那部分思想。
其次,从检测角度看,YOLO26 的优势是高效、多尺度、训练稳定,但它并不是面面俱到的通用最优器。当我们把检测任务放到复杂背景、长距离依赖、统计漂移、上采样细节损失或恶劣天气退化这些问题上时,传统 Conv + C3k2 + Neck 融合流程会暴露出比较明显的短板。DRoRAE 恰好提供了一个足够清晰的研究方向:在不破坏 YOLO26 主流程的前提下,用一个相对克制的独立模块,把最脆弱的那条特征链路补强。
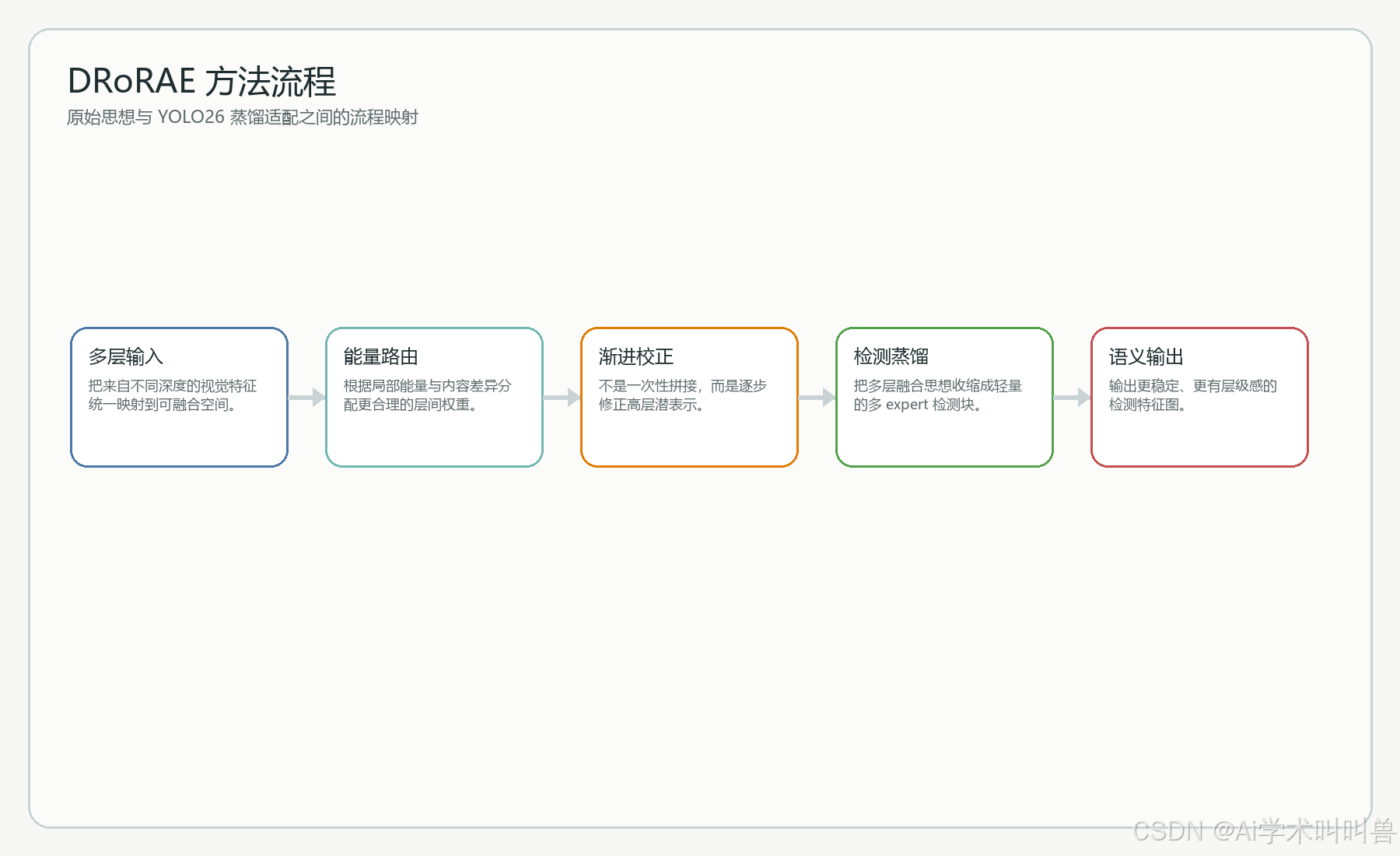
六、关键公式与数学直觉
下面只保留最值得写进专栏、也最容易帮助读者建立直觉的核心公式,而不是把原文所有符号照搬一遍。
路由权重
\alpha_l(x)=Softmax(g(E_l(x)))
每一层特征先被估计能量或显著性,再由路由器给出层间聚合权重。
融合表达
z=\sum_l \alpha_l \odot \phi_l(f_l)+\Delta z
最终融合表达不是简单拼接,而是加权投影后叠加一个渐进校正项。
检测适配
y=x+\sum_k w_k \cdot Expert_k(x)
在 YOLO26 里,我们把跨层融合思想转化成多 expert 与路由加权的局部可插拔块。
从写作上讲,这样处理有两个好处。第一,读者能迅速抓住论文到底控制了哪个变量。第二,后面讲 YOLO26 融合时,可以自然把这些公式映射到“模块插在什么位置、改变了什么信息流、为什么这会帮助检测”这三个问题上。

七、原文方法图表解读
如果我们把原文的方法图拆开来看,它本质上都在处理同一件事:不是简单把特征算得更大,而是把特征算得更对。所谓“更对”,对应的是三层含义。
第一层,是输入表征是否足够保留对任务有用的结构信息。
第二层,是中间处理过程是否在不必要的地方丢掉了边缘、层级或统计多样性。
第三层,是输出特征是否真正适合下游任务,而不是只在原论文自己的评价协议里好看。
从这个角度出发,改进的重点就不该停留在“模块名字是什么”,而应放在“作者到底在哪个环节发现了信息损失,又用什么机制把它救回来”。这也是把论文读懂,最终迁移到 YOLO26 的关键一步。
八、YOLO26 融合改进创新点
-
把视觉 tokenizer 的多层 richness 观念改造成检测中的多专业语义修正块。
-
融合重点不是堆更深,而是让不同内容区域自动挑选更合适的感受野和修正路径。
-
这类模块尤其适合纹理复杂、边缘易丢失、尺度跨度大的检测场景。
更进一步地说,这种融合写法的价值并不只是“我给 YOLO26 又加了一个新块”。真正的创新点在于,你把原论文最有信息含量的机制抽出来,重新安排到目标检测最需要它的位置上。这样形成的文章,不会流于“换模块”的流水账,而会更像一篇有研究判断力的结构创新笔记。
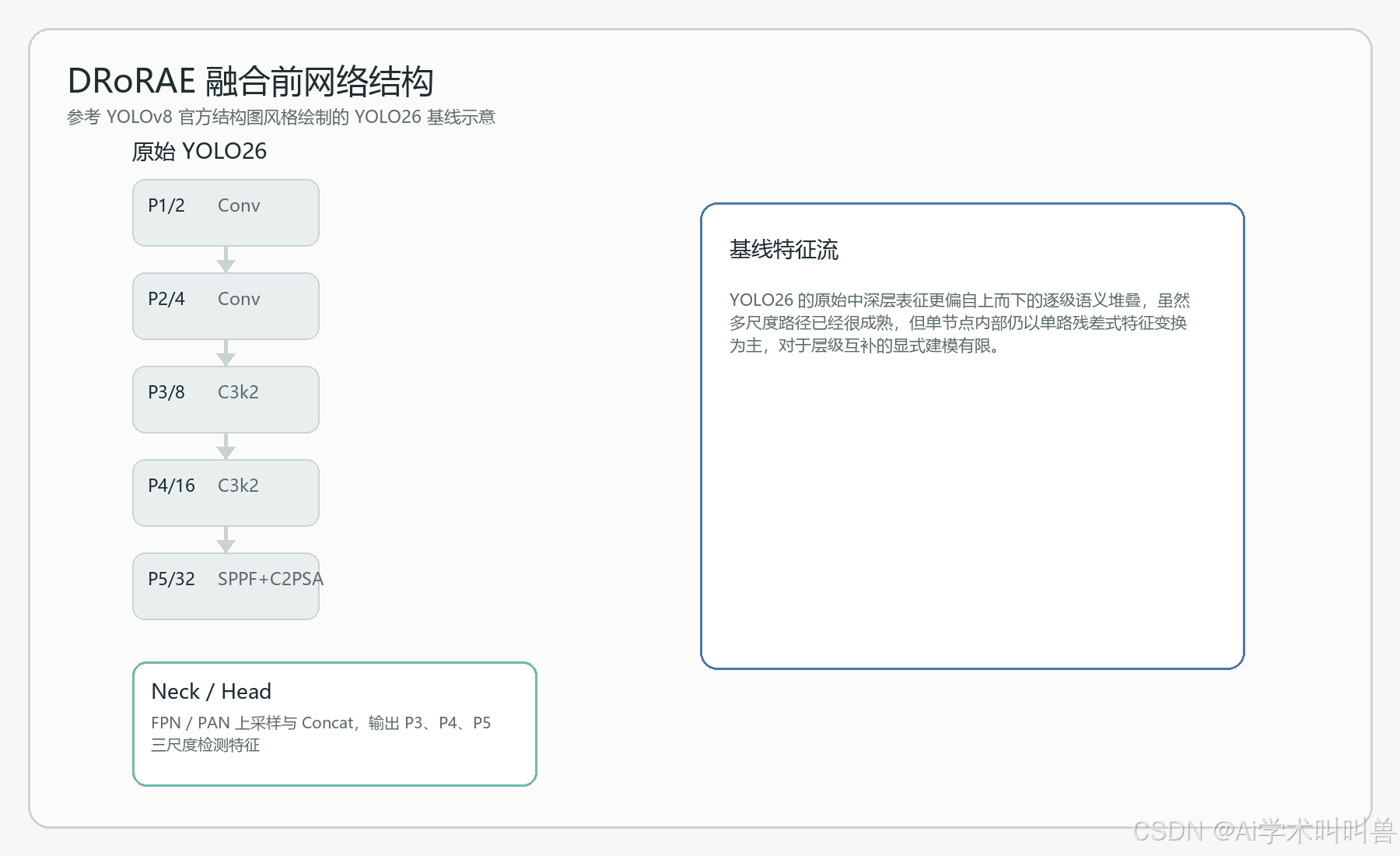
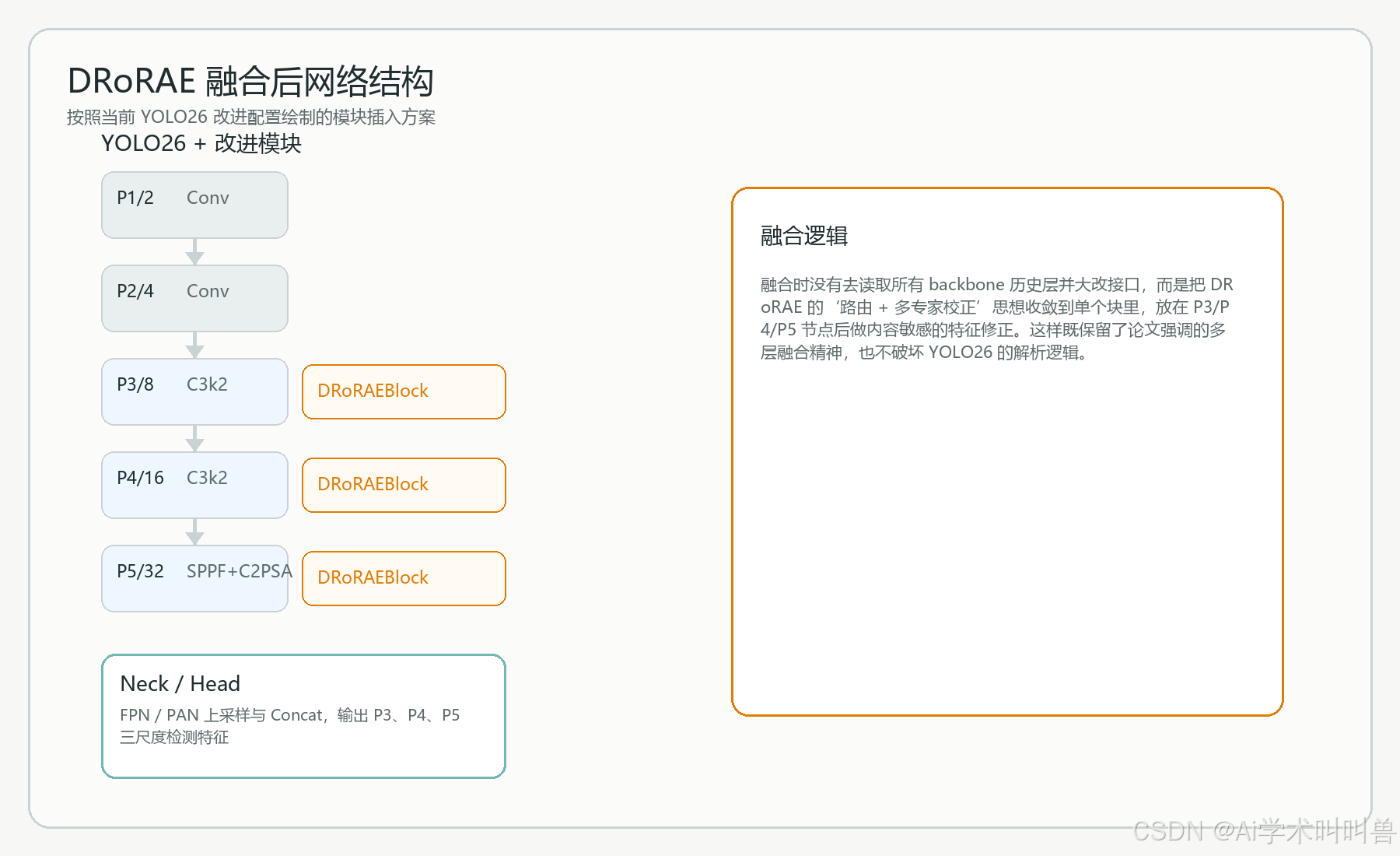
九、融合前后网络结构对比
在原始 YOLO26 中,主干和 Neck 的分工已经非常清晰:Backbone 负责逐级提炼语义,Neck 负责多尺度对齐,Head 负责检测输出。这套框架的优点是稳、快、成熟,但它默认所有节点的特征更新都遵循统一逻辑。问题恰恰出在这里:不同研究问题需要被修复的链路并不相同。
YOLO26 的原始中深层表征更偏自上而下的逐级语义堆叠,虽然多尺度路径已经很成熟,但单节点内部仍以单路残差式特征变换为主,对于层级互补的显式建模有限。
融合时没有去读取所有 backbone 历史层并大改接口,而是把 DRoRAE 的‘路由 + 多专家校正’思想收敛到单个块里,放在 P3/P4/P5 节点后做内容敏感的特征修正。这样既保留了论文强调的多层融合精神,也不破坏 YOLO26 的解析逻辑。
十、模块改进前后对比
从检测视角总结,融合前后的变化至少可以从以下四个层面理解:
-
语义与细节协同:融合前 更多依赖自然层级传递;融合后 通过路由显式调节不同感受野特征贡献
-
纹理异质性处理:融合前 单路径残差较稳但偏固定;融合后 不同特征可针对不同区域做差异化修正
-
对小目标边界:融合前 需要依赖 Neck 二次补偿;融合后 在 Backbone 末端就开始修复细节衰减
-
融合思想来源:融合前 检测内部多尺度;融合后 借鉴 标记器的多层丰富融合逻辑
 ## 十一、核心思想代码片段 这里不把完整源码展开,而是仅保留最能体现思想的核心写法,帮助各位建立实现直觉。 ```python class DRoRAEBlock(nn.Module):def forward(self, x):
expert_feats = torch.stack([expert(x) for expert in self.experts], 1)
weights = torch.tanh(self.router(x))
weights = weights / (weights.abs().sum(1, keepdim=True) + 1e-6)
fused = (expert_feats * weights.unsqueeze(2)).sum(1)
return self.act(x + self.scale * self.mix(fused))
```
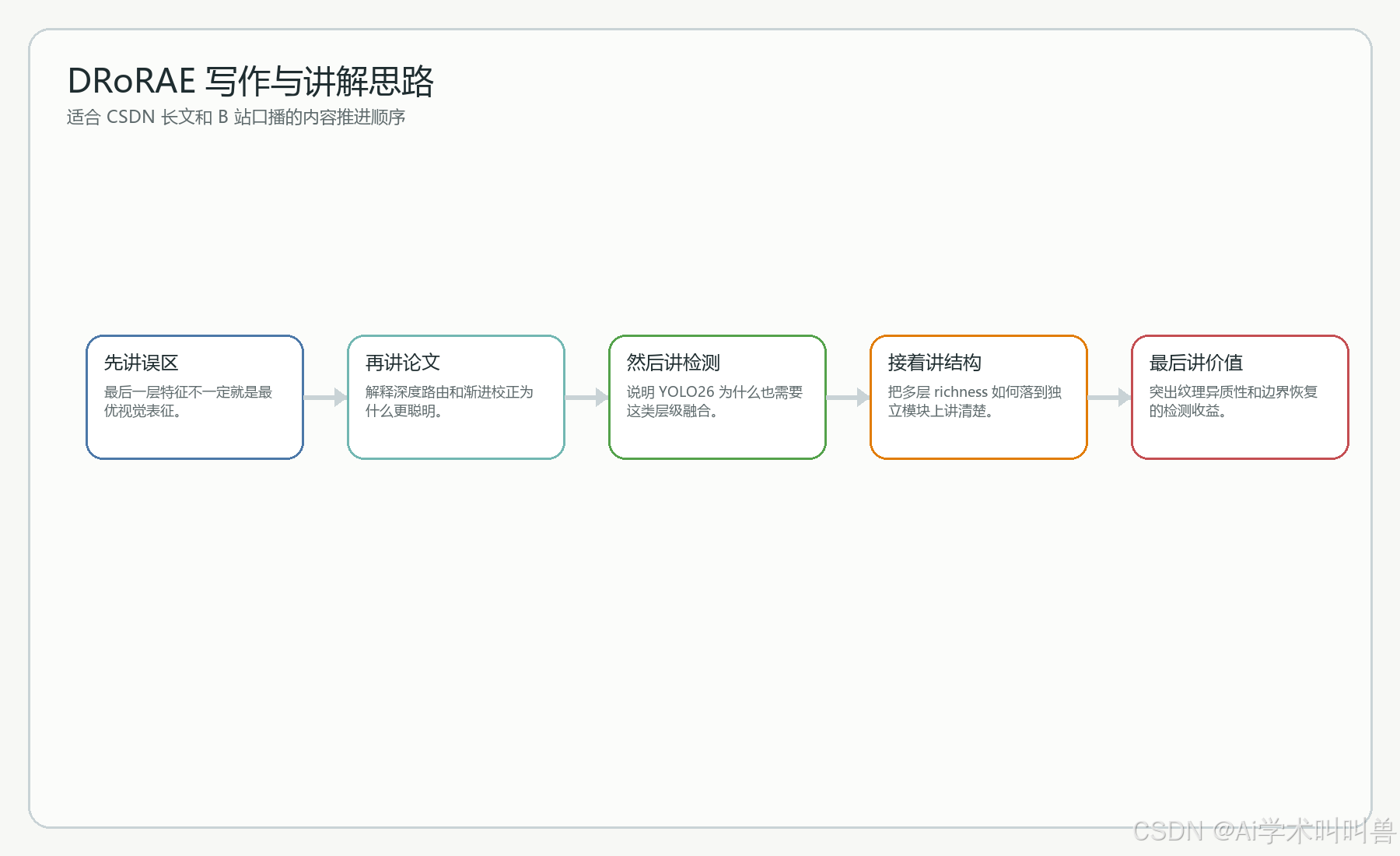
十二、原理、创新点与写作思路如何展开
DRoRAE 这类模块尤其适合做“原理型改进文章”,因为它既有论文层面的新意,又有结构迁移上的可解释性。只要你把“为什么插这里、为什么这样做、为什么这样比直接照搬更稳”讲清楚,整篇文章的质量就会上一个台阶。
十三、总结
总体来看,DRoRAE 融合到 YOLO26 的意义,不在于制造一个花哨的新名词,而在于为检测网络补上一条原本相对薄弱的信息链路。它可以补的是全局语义,可以补的是多层 richness,可以补的是残差统计纪律,也可以补的是上采样边缘细节或复杂天气下的结构净化。但无论具体形式如何变化,真正高阶的创新写法始终遵循同一条逻辑:先识别 YOLO26 的真实短板,再从原文中提炼最适合检测的那部分机制,最后用结构、公式、图表和对比把这件事讲透。
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,关注UP:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。
因为经历过所以更懂小白的痛苦!
因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!
微信公众号:Ai计算机视觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)