32GB显存老显卡横评多款30B参数级别本地大模型之运行速度篇
上篇文章初步整理了V100显卡加载运行Qwen3.6-27B的较全面体验过程(加载运行模型、生成速度、智力、agentic等),详细内容请看:
32GB显存老显卡V100跑最新小型开源大模型Qwen3.6-27B体验全过程
接下来,我准备从运行速度、能力评分、实战项目三个方面进行全面的评测对比这些30B参数级别开源大模型,然后跟各位同步分享其中的过程,如有不当更优之处还请不吝赐教!
先从大模型的运行速度开始。
本文内容关注目前开源领域最热门的几款30B级别大模型的运行速度方面,观察指标主要有不同上下文时的预填充prefill、生成速度decoding。这些速度指标可直观辅助选择满足我们自己场景要求的大模型,具体参与的大模型有:
- Qwen3.6-27B(Q4_K_M/Q6_K)
- Qwen3.6-35B-A3B(Q4_K_M)
- gemma-4-31B-it(Q4_K_M/IQ4_XS)
- gemma-4-26B-A4B(Q4_K_M/IQ4_XS)
- GLM-4.7-Flash(Q4_K_M)
其中,Qwen3.6-27B和Qwen3.6-35B-A3B这两个主角是近期最热门的个人本地部署的国产大模型,分别是dense和moe架构模型。
gemma-4-31B和gemma-4-26B-A4B这两个谷歌出品的开源模型热度也很高,另外IQ4_XS量化版本是应上篇文章的网友反馈加入测试的。
最后还选择了GLM-4.7-Flash,是因为最近GLM-5/GLM-5.1这代大模型相对来说太顶了,所以就把前一代30B激活3B参数的MOE架构模型也加入评测。
测试说明
测试时,每个量化的大模型,都会请求6个完全一致的中文prompt(文本分别长度分别为1000,5000,10000,20000,40000,80000),用来模拟不同长度的上下文。
相同文本经过不同厂商的tokenizer处理后获得的tokens也不尽相同,国产的两个模型token效率即压缩比会略高于国外谷歌gemma模型。
这样发送给大模型后,就可以统计各个模型的预填充prefill速度和token生成速度decoding(t/s),即tokens/s
不同厂商大模型在不同长度的输入文本字符数下token量和效率如下:
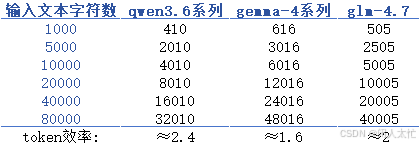
因为这里测试的为中文prompt,所以国产大模型token效率都会高一些,可以用更少量的token去表达同样长度的中文内容,对于中文占绝大多数的日常交流来说是有一定优势的。
测试环境
运行框架:llama.cpp n9113
显卡设备:V100 32GB
注:Lm studio和llama.cpp本质都差不多,因为习惯命令行操作,这里就用llama.cpp来进行测试
llama.cpp的主要参数:
--ctx-size:50000+ # 上下文长度,dense模型要低一些
--gpu-layers:99 # 所有层都加载到gpu
--no-mmap # 模型就不映射到系统内存了
结果分析
经过全面测试,数据较多,先看看主要指标,再细分对比。
先看大致结果,下面统计了各模型各量化精度的预填充和生成速度平均值:
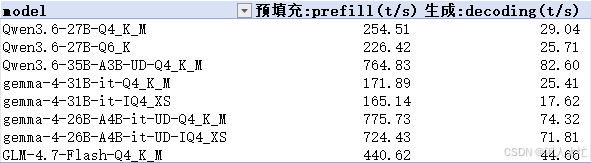
可以从上图看出dense稠密模型的速度确实要低很多,预填充速度一般都是10倍于生成速度。
下面进行较为详细的对比分析。
同等量化精度下(Q4_K_M),各个模型的预填充速度prefill
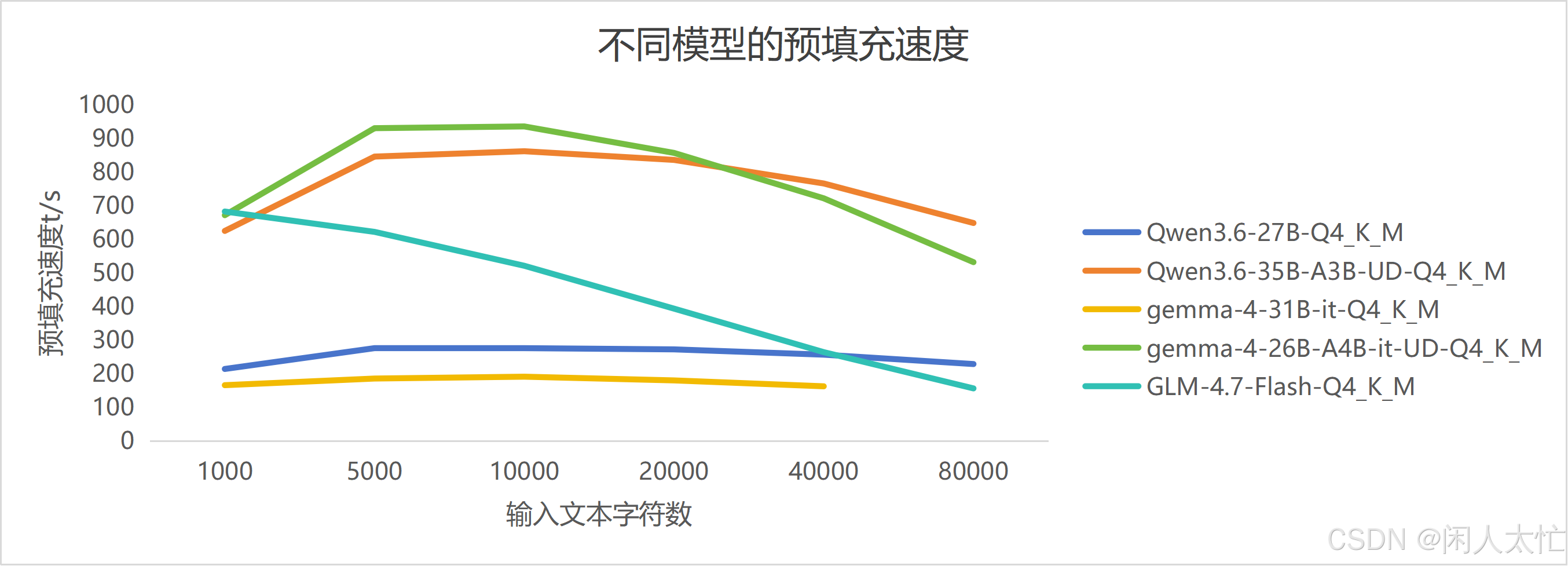
两个稠密模型毫无疑问速度被Moe架构模型拉开,gemma-4-31B在很少的输入文本数下暂时领先了Qwen3.6-27B,但毕竟因为多了4B左右的参数,在输入文本增加后预填充速度落后近10%左右。多数模型会在几千不到1万个文本字符时,预填充速度达到峰值,glm-4.7-falsh除外。
同等量化精度下(Q4_K_M),各个模型的token生成速度decoding
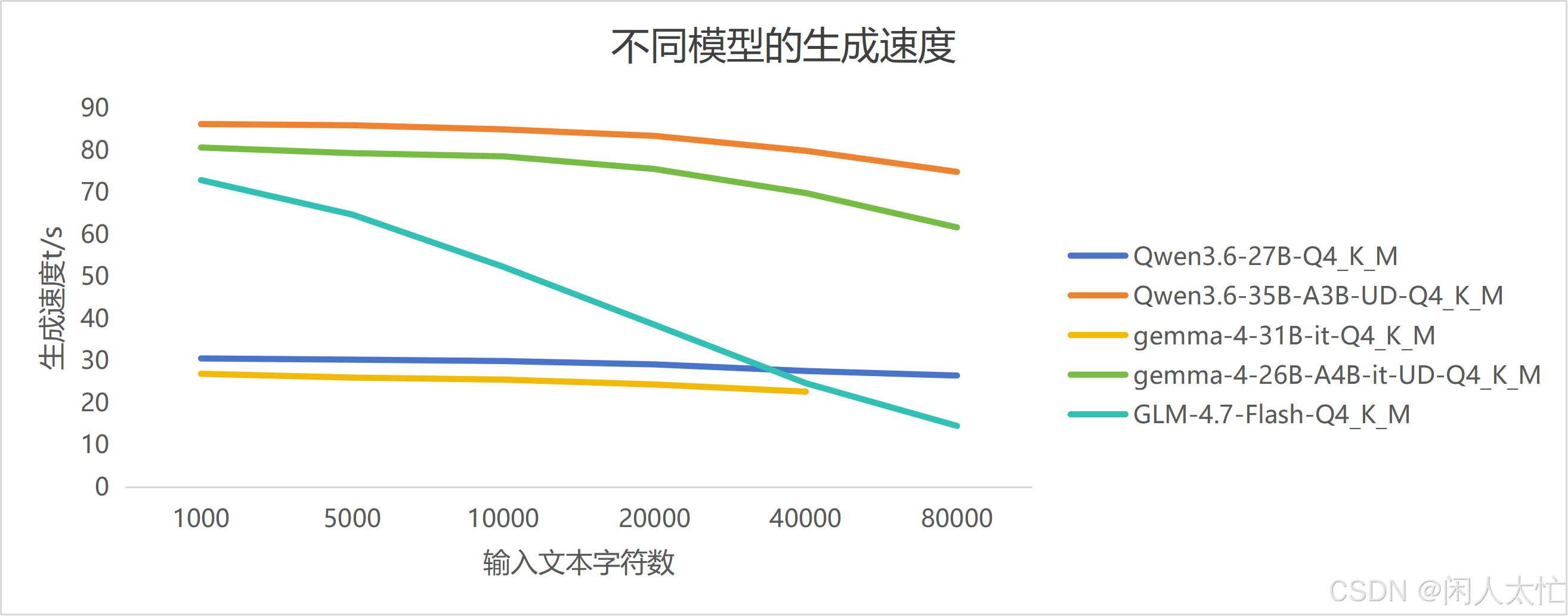
生成速度方面,还是稠密模型明显会慢很多,而且整体上都是随着上文的增加,生成速度逐步变慢。
GLM-4.7-FLASH特色
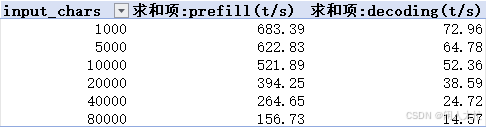
结合此图和上面的几张图可以看出,GLM-4.7-FLASH这个模型随着上文的增加,速度下降很快几乎呈线性衰减了。这种特性应该是使用了大模型比较原始的注意力机制,没上更强更高效的注意力优化方法,如有其他具体原因可以在评论区留言讨论下。
同等量化位数的不同量化方法对比(Q4_K_M VS IQ4_XS)

整体上智能模式的IQ4_XS量化方法都会比传统Q4_K_M慢一些,只不过gemma-4-31B-it-IQ4_XS也下降的太明显了。
这些都是我个人测试的,如有出入或错误之处还请告知。
但是理论上,IQ4_XS量化的模型在能力上会稍优于Q4_K_M量化的,后面总结下测试这方面的对比。
不同量化精度对比
Qwen3.6-27B的不同量化版本Q4_K_M vs Q6_K,Q6_K的预填充和生成速度都下降11%左右。
总结一下
稠密模型的prefill和decoding速度慢于Moe架构模型3-4倍,预填充速度大约是生成速度的10倍左右,量化强度精度低整体上也是要快些的,此外IQ4_XS这种智能量化方法会比Q4_K_M稍慢点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)