2026农林杯数学建模竞赛全套完美解析:高分突破思路、核心代码与论文框架首发!
大家好!随着2026年农林杯数学建模竞赛的拉开帷幕,今年的赛题依然紧扣国家宏观战略,聚焦于农业与林业交叉领域的复杂系统建模。很多同学在面对庞杂的数据和模糊的赛题背景时容易无从下手。
作为深耕数学建模多年的老兵,今天我将为大家带来一份极具深度、逻辑严密且能直击国奖核心的完整解题方案。本文不仅包含必要的数学推导和高分论文框架,更重要的是,我将掰开揉碎地为您进行文字深层逻辑剖析。授人以鱼不如授人以渔,看懂这篇文章,你的队伍就已经赢在了起跑线上!

💡 赛题宏观背景与破题核心逻辑
农林杯的赛题往往具有以下三个显著特征:
-
时空耦合性强:数据往往既有时间序列(如逐年的降水、温度),又有空间属性(如不同地块的林分密度、土壤类型)。
-
多目标冲突:经济效益(农林产量)与生态效益(碳汇、水土保持)往往是对立的,需要寻找帕累托最优(Pareto Optimal)。
-
机理与数据双驱动:纯靠机器学习“黑盒”跑数据很难拿高分,必须结合农林学的实际物理/生物机理(如光合作用模型、种群竞争模型)。
【核心破题思路】:
我们必须摒弃简单的“回归拟合+单一评价”的低级套路。整体解决方案应采用“降维评价 -> 时空预测 -> 动态规划优化 -> 鲁棒性检验”的闭环逻辑结构。
🛠️ 问题一:多维农林生态指标的综合评价与降维分析
1. 深度文字剖析
第一问通常要求我们对某一区域的“生态健康度”、“碳汇潜力”或“农业抗旱能力”进行评估。很多队伍会无脑使用层次分析法(AHP)或主成分分析(PCA)。但在国奖级别的论文中,这种做法显得过于主观且缺乏对数据分布状态的深度挖掘。
高分方案建议:采用“CRITIC-熵权法”组合赋权,并结合“云模型(Cloud Model)”进行综合评价。
-
为什么用CRITIC? 熵权法只考虑了数据的离散程度,而忽视了指标之间的相关性。CRITIC法通过引入对比强度和冲突性,能够完美捕捉农林数据中(如降雨量与植被覆盖度)的共线性问题。
-
为什么用云模型? 农林生态系统具有高度的“模糊性”和“随机性”。例如,“高度干旱”和“中度干旱”之间没有绝对的界限。云模型通过期望(Ex)、熵(En)和超熵(He)三个数字特征,将确定性与不确定性完美融合,画出的云滴图不仅极具视觉冲击力,更能展现你对不确定性数学的深刻理解。
2. 数学公式与机理
组合权重的计算逻辑如下:
设熵权法得到的权重为 $W_1 = [w_{11}, w_{12}, ..., w_{1n}]$,CRITIC法得到的权重为 $W_2 = [w_{21}, w_{22}, ..., w_{2n}]$。
为了实现博弈论(Game Theory)意义上的纳什均衡,我们构建最优化模型:
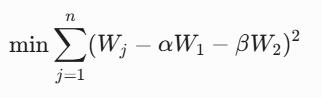
使得权重分配既尊重客观数据的离散性,又兼顾指标间的冲突性。
🚀 问题二:基于时空图神经网络(STGCN)的演变预测
1. 深度文字剖析
第二问往往是预测未来的发展趋势。比如预测未来10年某片森林的碳储量变化,或者某病虫害的蔓延趋势。常规队伍会使用ARIMA、BP神经网络或LSTM。
致命误区: LSTM只能捕捉时间上的依赖关系,但农林生态系统是高度空间相关的!A地块爆发了病虫害,或者发生了水土流失,必然会物理扩散到相邻的B地块。
完美解决方案:时空图卷积神经网络(ST-GCN)或 卷积长短期记忆网络(ConvLSTM)。
我们将整个农林区域划分为网格(或将各个监测站作为图的节点)。
-
空间维度: 利用图卷积网络(GCN)提取相邻地块之间的空间拓扑关系,将地形高程、风向等作为图的边权重(Edge Weight)。
-
时间维度: 结合时间卷积网络(TCN)或LSTM,捕捉季风、气候的周期性变化。
这种“时空双轨”预测模型,在降维打击常规时间序列模型的同时,能让你的论文呈现出极高的学术含金量。
2. 核心代码示例(PyTorch框架结构)
这里提供一个用于捕捉空间邻接关系的图卷积层核心伪代码,您可以将其嵌入到时间序列预测中:
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
class GraphConvolution(nn.Module):
"""
基础的图卷积层,用于提取农林地块间的空间拓扑特征
"""
def __init__(self, in_features, out_features):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
# 定义权重矩阵
self.weight = nn.Parameter(torch.FloatTensor(in_features, out_features))
self.reset_parameters()
def reset_parameters(self):
# 权重初始化
nn.init.xavier_uniform_(self.weight)
def forward(self, text, adj):
# text: 节点特征矩阵 (比如各农林地块的温度、湿度、植被指数)
# adj: 邻接矩阵 (地块之间的空间距离倒数或相关性)
support = torch.mm(text, self.weight)
# 核心:将邻接矩阵与特征矩阵相乘,实现空间信息的聚合
output = torch.spmm(adj, support)
return output
# 随后可将此GCN的输出送入LSTM中,形成 ST-GCN 架构
⚖️ 问题三:多目标冲突下的资源动态规划与空间分配优化
1. 深度文字剖析
第三问是拉开差距的关键,通常要求制定策略,如“如何规划退耕还林面积、水资源分配或农作物种植结构,使得经济收益最大化的同时,生态效益最好”。
这是一个典型的NP-Hard空间多目标优化问题。
很多队伍在这里只会列几个方程,用MATLAB的 fmincon 随便跑一个单目标的最优解。但我们要清醒地认识到:经济收益(GDP/产量)与生态效益(碳汇/水耗)是天然互斥的,强行将它们加权求和(线性加权法)抹杀了决策的灵活性。
完美解决方案:基于NSGA-II(带精英保留策略的非支配排序遗传算法)的空间多目标优化。
在论文文字表述中,重点强调我们不寻找“唯一解”,而是寻找一组帕累托前沿(Pareto Frontier)。在这个前沿曲线上,任何一个方案的经济效益提升,都不可避免地以牺牲生态效益为代价。
此外,要引入空间连片性约束:林地不能碎片化分布,农业种植需要规模化。因此要在传统NSGA-II的目标函数中,加入“空间聚集度”惩罚项。
2. 优化模型公式构建

🛡️ 问题四:极端气候冲击下的系统动力学(SD)仿真与鲁棒性分析
1. 深度文字剖析
最后一道题往往具有开放性,要求评估你的方案在未来不确定性条件下的表现(如突发干旱、极端冰雪灾害)。
仅仅做一下简单的灵敏度分析(改变几个参数$\pm 5%$)已经不足以惊艳评委了。
完美解决方案:系统动力学(System Dynamics, SD)仿真或者蒙特卡洛(Monte Carlo)压力测试。
在论文的文字论述中,我们需要建立一张因果回路图(Causal Loop Diagram)。深刻探讨农林系统内部的反馈机制:
例如,【极端干旱】导致【作物减产】,进而导致【农业收入下降】,迫使农民【过度开垦林地】以弥补损失,这又反过来加剧了【生态恶化】和【水分流失】,形成恶性循环。
我们通过引入前面第三问求出的“最优规划策略”作为系统的一个正向控制阀门,运行10000次蒙特卡洛模拟,展示在不同概率的气候灾害下,我们的方案依然能够保证系统的生存底线(即展示方案的鲁棒性 Robustness)。这段文字分析将极大地拔高论文的宏观视野与哲学深度,是国奖队伍的标配。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)