【论文解读】Ensembling LLM-Induced Decision Trees for Explainable and Robust Error Detection(二)
数学解释
对,这几个公式如果只看符号会很抽象。我们用一个小表格 + 手算式例子来讲。
先说结论:
边特征 h_e = φ(D[i,j])
作用是:把“单元格的具体值”变成向量,放到图的边上。
GNN 消息传播时,不只看“谁和谁相连”,还看“这条边上的单元格值是什么”。
论文里把表格构造成二部图:行是 tuple node,列是 attribute node,每个单元格是一条边;并且每条边都有特征 h_e = φ(D[i,j]),其中 φ 是把 cell value 编成数值向量的 hash-based embedding。GNN 的消息传播会把邻居节点表示和边表示拼接起来,所以边特征会直接参与信息聚合。
1. 为什么需要边特征?
假设有一个表:
| 行 | CustomerID | Age | |
|---|---|---|---|
| t1 | C100 | a@email.com | 20 |
| t2 | C100 | b@email.com | 21 |
| t3 | C200 | c@email.com | 30 |
构成二部图后:
行节点:t1, t2, t3
列节点:CustomerID, Email, Age
边:
t1 -- CustomerID,边值是 C100
t1 -- Email,边值是 a@email.com
t1 -- Age,边值是 20
t2 -- CustomerID,边值是 C100
t2 -- Email,边值是 b@email.com
t2 -- Age,边值是 21
...
如果没有边特征,GNN 只知道:
t1 连着 CustomerID、Email、Age
t2 也连着 CustomerID、Email、Age
t3 也连着 CustomerID、Email、Age
那所有行结构都差不多,它不知道:
t1 的 CustomerID 是 C100
t2 的 CustomerID 也是 C100
但 t1.Email 和 t2.Email 不一样
这样它就很难发现:
同一个 CustomerID = C100
对应了两个不同 Email
可能违反 CustomerID -> Email
所以边特征 h_e = φ(D[i,j]) 的作用就是把单元格值塞进图里。
你可以把它理解成:
边特征 = 这条连接线上携带的单元格内容
没有边特征,图只有“表格结构”;有边特征,图才有“表格内容”。
2. φ(D[i,j]) 是什么?
公式:
h_e = φ(D[i,j])
意思是:
把单元格值 D[i,j] 转成一个向量
比如:
φ("C100") = [0.8, 0.1, 0.3]
φ("a@email.com") = [0.2, 0.7, 0.4]
φ("20") = [0.1, 0.9, 0.5]
论文里说它用的是 hash-based embedding,也就是用哈希方法把值编码成数值向量。你不用纠结具体数值,只要理解:
原始值:C100、a@email.com、20
↓
向量化后:机器能计算的 h_e
3. GNN 消息传播公式到底在说什么?
论文里的消息聚合公式大致是:
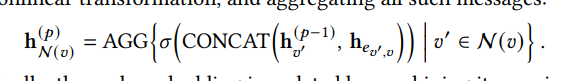
h_N(v)^(p)
=
AGG {
σ( CONCAT( h_v'^(p-1), h_e(v',v) ) )
| v' ∈ N(v)
}
这个公式可以拆成一句话:
对节点
v来说,把每个邻居v'的表示,和连接它们那条边的单元格值表示拼起来,形成消息;然后把所有邻居消息聚合起来。
逐个符号看:
v:当前节点
v':v 的某个邻居节点
N(v):v 的所有邻居
h_v'^(p-1):邻居节点上一层的表示
h_e(v',v):连接 v' 和 v 的边特征,也就是单元格值 embedding
CONCAT:拼接
σ:激活函数,可以先理解成“做一次非线性变换”
AGG:聚合函数,论文里是 mean,也就是求平均
h_N(v)^(p):当前节点 v 从邻居那里收到的综合信息
4. 用一个列节点 Email 举例
我们看列节点 Email。
它的邻居是所有行节点:
N(Email) = {t1, t2, t3}
因为每一行都有一个 Email 单元格。
对应边特征是:
t1 -- Email:φ("a@email.com")
t2 -- Email:φ("b@email.com")
t3 -- Email:φ("c@email.com")
那么 Email 节点聚合邻居信息时,会收到三条消息:
来自 t1 的消息:
CONCAT( h_t1, φ("a@email.com") )
来自 t2 的消息:
CONCAT( h_t2, φ("b@email.com") )
来自 t3 的消息:
CONCAT( h_t3, φ("c@email.com") )
然后做平均聚合:
h_N(Email)
=
mean(
message(t1 -> Email),
message(t2 -> Email),
message(t3 -> Email)
)
这是什么意思?
就是让 Email 这个列节点学到:
Email 这一列整体上出现了哪些值、分布是什么、有没有异常模式
比如如果大部分 Email 都像:
xxx@email.com
但有一个是:
bob@emaix.com
那么这个异常值的信息会通过边特征参与聚合。
5. 再用行节点 t2 举例
现在看行节点 t2。
它的邻居是所有列节点:
N(t2) = {CustomerID, Email, Age}
对应边特征:
t2 -- CustomerID:φ("C100")
t2 -- Email:φ("b@email.com")
t2 -- Age:φ("21")
所以 t2 收到的消息是:
来自 CustomerID 列节点的消息:
CONCAT( h_CustomerID, φ("C100") )
来自 Email 列节点的消息:
CONCAT( h_Email, φ("b@email.com") )
来自 Age 列节点的消息:
CONCAT( h_Age, φ("21") )
聚合后:
h_N(t2)
=
mean(
message(CustomerID -> t2),
message(Email -> t2),
message(Age -> t2)
)
这是什么意思?
就是让 t2 这个行节点学到:
这一整行的上下文是什么
也就是:
这个人/客户的 CustomerID 是 C100,
Email 是 b@email.com,
Age 是 21。
6. 节点更新公式是什么意思?
论文的节点更新公式是:

h_v^(p)
=
σ( W^(p) · CONCAT( h_v^(p-1), h_N(v)^(p) ) )
这句话翻译成人话:
节点的新表示 = 把“自己原来的表示”和“邻居传来的综合信息”拼起来,再经过一层神经网络变换。
逐个符号看:
h_v^(p-1):节点 v 原来的表示
h_N(v)^(p):邻居聚合后的信息
CONCAT:拼接
W^(p):可训练参数矩阵
σ:激活函数
h_v^(p):更新后的节点表示
7. 用 t2 节点完整走一遍
假设现在更新行节点 t2。
第一步:t2 原来的表示
一开始:
h_t2^(0) = [1, 1, 1]
论文里说 tuple node 初始化为常量向量。也就是说,所有行节点一开始可能都差不多。
第二步:t2 收集邻居消息
t2 连着三个列节点:
CustomerID, Email, Age
每条消息都包含:
邻居列节点表示 + 单元格值边特征
例如:
message(CustomerID -> t2)
=
CONCAT( h_CustomerID^(0), φ("C100") )
message(Email -> t2)
=
CONCAT( h_Email^(0), φ("b@email.com") )
message(Age -> t2)
=
CONCAT( h_Age^(0), φ("21") )
第三步:聚合邻居消息
假设聚合函数是平均:
h_N(t2)^(1)
=
mean(
message(CustomerID -> t2),
message(Email -> t2),
message(Age -> t2)
)
这个 h_N(t2)^(1) 就表示:
t2 这行从所有列和单元格值里汇总来的上下文信息
第四步:更新 t2 的表示
然后用节点更新公式:
h_t2^(1)
=
σ( W^(1) · CONCAT( h_t2^(0), h_N(t2)^(1) ) )
意思是:
t2 新表示
=
神经网络(
t2 原来的表示
+
t2 从邻居那里汇总来的信息
)
更新完以后,h_t2^(1) 就不再只是一个普通行节点,而是带有这一行内容的信息了。
8. 两层传播为什么有用?
一层传播后:
行节点知道自己这一行的值
列节点知道自己这一列的值
两层传播后,信息可以走得更远。
比如要检查:
CustomerID -> Email
我们关心的是:
t1.CustomerID = C100
t2.CustomerID = C100
但 t1.Email ≠ t2.Email
这个关系涉及:
t1 行
t2 行
CustomerID 列
Email 列
信息传播路径可以理解成:
t1 的 CustomerID 信息
→ CustomerID 列节点
→ t2 行节点
t1 的 Email 信息
→ Email 列节点
→ t2 行节点
这样 t2 的表示里就有机会感知:
和自己共享 CustomerID 模式的其他行,
它们的 Email 分布是什么样
当然,论文里的二部图结构本身比较粗,具体能学到多少取决于 edge embedding、训练标签和 GNN 参数。但设计意图就是:通过行节点和列节点之间的信息传播,让模型捕捉跨行、跨列的关系模式。论文也说,二部图允许信息在 tuple 和 attribute 两个维度上传播,适合捕捉 functional dependencies、cross-column constraints 等局部规则难以表达的错误模式。
9. 一个更直观的“聊天”比喻
你可以把二部图看成一个班级群:
行节点 = 每个学生
列节点 = 每门课程
边特征 = 学生在这门课的成绩
比如:
学生 t2 -- 数学课,边特征是 95
学生 t2 -- 英语课,边特征是 60
如果数学课节点想知道“这门课整体情况”,它要听所有学生发来的消息:
学生是谁 + 他数学多少分
如果学生 t2 想知道“自己的整体画像”,他要听所有课程发来的消息:
课程是什么 + 自己这门课多少分
所以消息传播公式就是:
每个节点听邻居说话;
邻居说话时,不仅说“我是哪个节点”,还要说“我们之间这条边上的值是什么”。
边特征就是“说话内容里最重要的那个值”。
10. 最后这些节点表示怎么用于判断单元格?
经过两层 GNN 后,要判断单元格 D[i,j],比如:
D[2, Email]
它对应图中的边:
t2 -- Email
模型取:
h_t2^(2):第 2 行节点最终表示
h_Email^(2):Email 列节点最终表示
拼接后送入 MLP:
q̂_i,j,k = MLP( h_t2^(2) || h_Email^(2) )
输出:
这个单元格在第 k 个 GNN 节点上走 true_child 的概率
论文也是这样:经过两层传播后,拼接 tuple node 和 attribute node 的 embedding,再输入两层 MLP 输出分支概率,并用二元交叉熵训练。
11. 用一句话把三个公式串起来
h_e = φ(D[i,j])
表示:
先把每个单元格值变成边上的向量。
h_N(v) = AGG{ σ(CONCAT(h_neighbor, h_edge)) }
表示:
节点从所有邻居那里收消息,每条消息由“邻居是谁 + 单元格值是什么”组成。
h_v = σ(W · CONCAT(h_v_old, h_N(v)))
表示:
节点把自己的旧信息和邻居汇总信息合并,得到新的节点表示。
最终:
MLP(h_row || h_column)
表示:
用更新后的行表示和列表示,判断这个单元格在 GNN 节点该走 true 还是 false。
所以你可以这样记:
边特征负责提供“单元格的值”;
消息传播负责让“值的信息”在行和列之间流动;
节点更新负责把这些信息变成新的行/列表示;
MLP 负责用行/列表示判断某个单元格的分支。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)