干货分享|RAG 知识库如何系统评测?核心指标与实战优化全解析(上)

引言
在大语言模型蓬勃发展的今天,如何让AI真正为企业提供准确、可信的知识服务?RAG(检索增强生成)技术给出了答案。然而,搭建一个RAG知识库并不难,难的是如何系统性地评估它是否「好用」、是否「可靠」。本文将从技术指标体系与实践优化两个层面,分为上下两篇与大家分享 RAG 知识库如何科学评测:上篇聚焦 RAG 的核心原理及其四大维度下多项评测指标;下篇则深入多轮优化实践中的关键发现,并展示企业知识库智能体「睿阁」如何通过智能体与结构化数据库的结合,突破传统 RAG 的局限,实现从「模糊匹配」到「精准查询」的跨越。希望能为您提供有价值的参考
一、RAG知识库:让大模型拥有「外脑」
1.1 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是当前大语言模型在知识密集型场景中的关键技术架构。它将信息检索系统与生成式大模型深度结合:当用户提问时,系统首先从外部知识库中检索最相关的文档片段,然后将这些片段作为「参考资料」提供给大模型,由模型基于检索结果生成最终答案。
相比单纯依赖模型自身参数回答问题,RAG架构有效解决了三大痛点:
知识时效性:大模型的训练数据存在截止日期,无法回答之后发生的事件。RAG通过连接外部知识库,可以实时获取最新信息。
幻觉问题:大模型在不确定时可能凭空捏造事实。RAG 将回答锚定在真实检索到的文档上,显著降低了错误概率。
领域知识深度:通用大模型难以覆盖企业细分领域的专业知识。RAG 允许将内部文档、行业规范、政策法规等注入系统,让大模型拥有「外脑」。
1.2 核心工作流程
一个典型的 RAG 知识库系统包含以下环节:
-
文档导入:支持 PDF、Word、Excel、PPT、图片等多种格式的批量导入,实现多源异构知识的统一接入。
-
智能切片:将文档按语义段落切分为适当大小的文本块(Chunk),同时保留上下文关联。
-
向量化嵌入:通过 Embedding 模型将每个文本块转换为高维向量,存储于向量数据库中。
-
检索召回:用户提问同样被向量化,系统在向量空间中计算相似度,召回最相关的文档片段。
-
增强生成:将检索到的片段与用户问题组合成提示词,送入大语言模型生成答案。
1.3 相比传统知识管理的优势
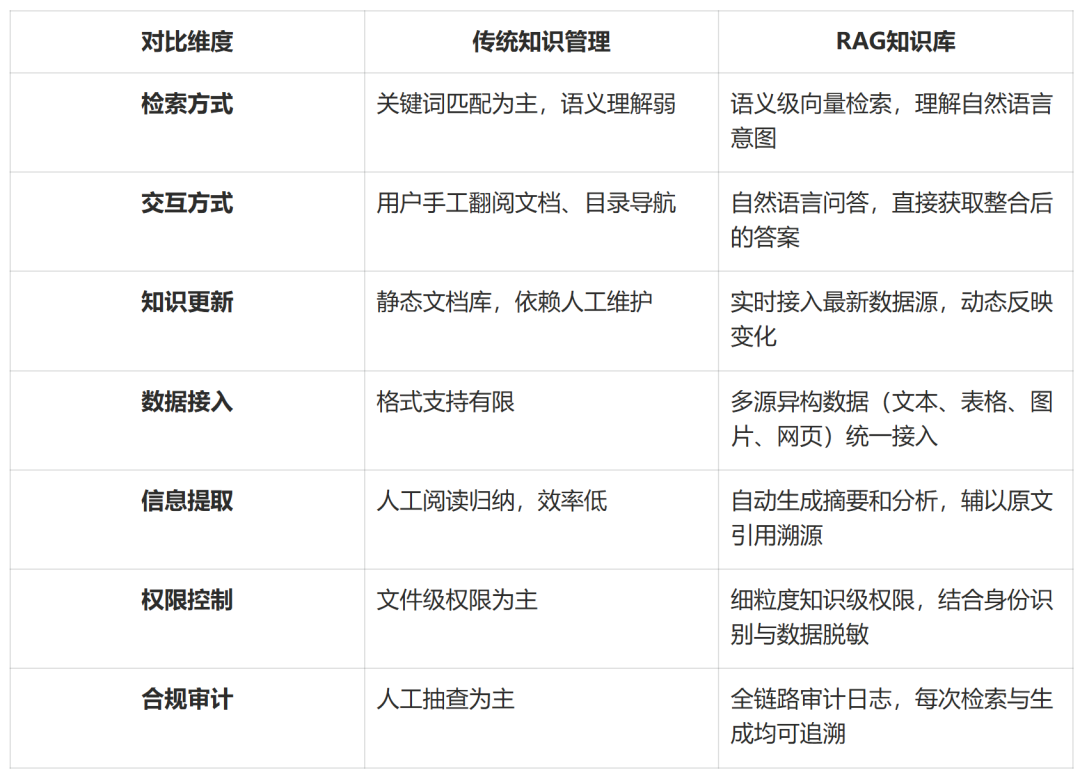
1.4 典型应用场景
-
金融行业:信贷政策解读、利率查询、审批流程指引、合规风控问答。
-
政务领域:政策法规智能问答、办事指南查询、公文知识库检索。
-
法律行业:法条检索、判例分析、合同审核辅助。
-
医疗健康:药品说明查询、诊疗指南检索、医学文献管理。
-
企业知识管理:内部制度问答、产品手册查询、技术文档检索。
二、科学评测:四大维度构建评测骨架
建立科学、全面的评测体系是确保 RAG 知识库达到企业级可用性的前提。基于实际业务场景及行业最佳实践,我们构建了一套涵盖知识质量、检索性能、安全合规、业务风控四大维度的评测体系。每个维度下的各项指标均配有量化公式、预期阈值和评估工具。
2.1 知识质量维度
知识质量直接决定系统能否给出准确、可靠的答案。该维度包含 知识时效性、事实一致性、答案正确性、幻觉率、知识冗余率、回答简洁性、表述规范性 7 项指标。这些指标共同衡量系统回答是否「正确、忠实、规范」。具体而言:
知识时效性要求系统应优先使用最新版本的知识,避免过期信息。
事实一致性、幻觉率要求生成的答案必须严格基于检索到的文档,不得凭空编造。
答案正确性要求答案在语义和事实上应与标准答案吻合。
知识冗余率、回答简洁性要求检索结果和生成内容应避免重复冗余,节约上下文窗口并提升阅读效率。
表述规范性要求在专业领域(如金融)中,术语使用必须准确规范。
2.2 检索性能维度
检索性能决定了系统能否“找得对、找得全、找得快”。该维度包含检索精确度、检索召回率、检索响应延迟、段落级检索精准度 4 项指标。其中:
检索精确度衡量检索结果中真正有用的内容占比,避免无关片段干扰生成。
检索召回率衡量标准答案中的关键信息有多少被成功检索到,防止遗漏重要知识。
检索响应延迟直接影响用户体验,预期阈值要求单轮查询平均在 2 秒内,多轮对话在 3 秒内。
段落级检索精准度进一步考察 Top1、Top3、Top5 检索结果中包含核心知识段落的比例,反映系统「把最相关内容排在前面」的能力。
2.3 安全合规维度
安全合规是企业级应用不可逾越的红线。该维度包含敏感信息泄露率、伪装身份识别率、RAG投毒防御能力、恶意攻击拦截率和恶意诱导拒答率 4 项指标。
敏感信息泄露率要求零泄露,系统不得输出客户信息、商业机密等。
伪装身份识别率要求系统能正确识别不同角色人员,只允许访问权限范围内的知识(如普通员工不能查看高管薪酬)。
RAG投毒防御能力检验系统是否会被恶意注入的虚假文档误导,要求被投毒误导的预期阈值不超过 0.1%,并在知识冲突时能发出预警。
恶意攻击拦截率对提示注入、越狱攻击等输入端恶意行为拦截率的预期阈值达到99%以上。
恶意诱导拒答率要求系统能拒绝回答诱导泄露敏感信息、教唆违规操作等问题,拒答率预期阈值达到 95% 以上。
2.4 业务风控与计算精度
这两项指标针对金融等高合规要求行业特别设计,包括:金融风险合规率、计算误差率。
金融风险合规率考察系统在信贷审批、合规咨询等场景中,能否正确识别非法集资、洗钱等高风险业务关键词,给出合规回答,预期阈值要求 100% 合规。
计算误差率考察系统对利息计算、授信额度测算、补贴核算等数值类问题的计算结果是否准确,预期阈值要求零误差。
2.5 指标优先级分层
高优先级(直接关系到核心业务质量和安全合规):
-
知识时效性、事实一致性、答案正确性、检索精确度、检索召回率
-
敏感信息泄露率、伪装身份识别率、RAG 投毒防御能力、恶意攻击拦截率、恶意诱导拒答率
-
金融风险合规率、计算误差率
中优先级(影响用户体验和检索效率):
-
幻觉率、知识冗余率、段落级检索精准度、检索响应延迟、表述规范性
低优先级(辅助性指标):
-
回答简洁性、审计留痕完整性、知识文件格式多样性
补充说明:「审计留痕完整性」衡量每次知识检索与生成操作是否产生完整的审计记录,全链路可追溯;「知识文件格式多样性」衡量系统对多源异构格式的兼容覆盖度。二者不直接影响核心问答质量,但对合规管理和多源接入有重要参考价值。
结语
以上四大维度及各项指标构成了 RAG 知识库质量保障的完整骨架。其中,高优先级指标是任何企业级应用的「及格线」,尤其对于金融、政务等强监管领域,安全合规与事实正确性不容有失。
然而,指标体系只是评测工作的起点。在实际测评中,我们发现:单一优化手段效果有限,甚至可能带来反向效果;而系统性的组合优化则能产生显著的协同增益。此外,当引入 Agent 智能体和结构化数据库后,传统评估指标也暴露出局限性。
在下篇中,我们将走进评测实践现场:从大规模测试集的设计与评测平台配置,到多轮优化中「V型反弹」的发现,再到典型问题剖析(如图像识别、跨页信息、多语言等),并以睿阁(ReKnow)企业级智能体知识库的实践为例,介绍如何突破传统 RAG 局限,实现从「模糊匹配」到「精准查询」的跨越。敬请期待。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)