Transformer架构详解:从原理到代码,一文吃透大模型基石
从 ChatGPT 到 LLaMA,从 BERT 到 Stable Diffusion,所有你听过的前沿 AI 模型,背后都站着同一个 “功臣”——Transformer。2017 年 Google 发表的《Attention Is All You Need》提出的这个架构,彻底颠覆了序列建模的范式,成为了整个大模型时代的基石。
本文将用最通俗的语言,从原理到代码,带你彻底搞懂 Transformer 的每一个细节,看完你就能明白,为什么这个架构能有这么大的能量。
一、为什么是 Transformer?告别 RNN 的困境
在 Transformer 出现之前,处理序列数据(比如文本、语音)的主流方案是循环神经网络(RNN),以及它的变体 LSTM、GRU。
RNN 的工作方式很像我们人类阅读:从左到右,一个字一个字地处理,每处理一个字,都会把之前的信息记在"隐藏状态" 里,传给下一个字。
但这种 “顺序处理” 的模式,有两个致命的缺点:
-
无法并行计算:我必须读完第一个字,才能处理第二个字。这在现代拥有成千上万个核心的 GPU 上,简直是巨大的浪费,训练一个大模型要等几个月。
-
长程依赖衰减:想象一个长句子:" 那只住在山脚下、被老爷爷养了十几年、每天清晨都会准时打鸣的公鸡,声音特别洪亮。"
作为人类,我们读到 “公鸡” 时,能立刻联系到句首的 “那只”。但 RNN 就像个记性不好的人,信息在一步步传递中被稀释,隔了几十个字之后,早就忘了开头说的是什么了。
那有没有一种方法,能让模型在处理 “公鸡” 这个词时,直接去 “看” 一眼句首的 “那只”?
这就是 Transformer 的核心灵感:自注意力机制。它允许模型在处理序列的任何一个位置时,都能直接访问序列中所有其他位置的信息,不管它们离得有多远。
更重要的是,整个计算过程可以完全并行,GPU 的所有核心都能跑满,训练速度直接提升了几十倍!
二、Transformer 整体架构:先看一眼全貌
Transformer 的整体架构其实非常对称,左边是编码器(Encoder),右边是解码器(Decoder)。
论文里默认的配置是:编码器堆叠 6 层,解码器也堆叠 6 层,就像搭积木一样,一层一层把特征抽得越来越深。
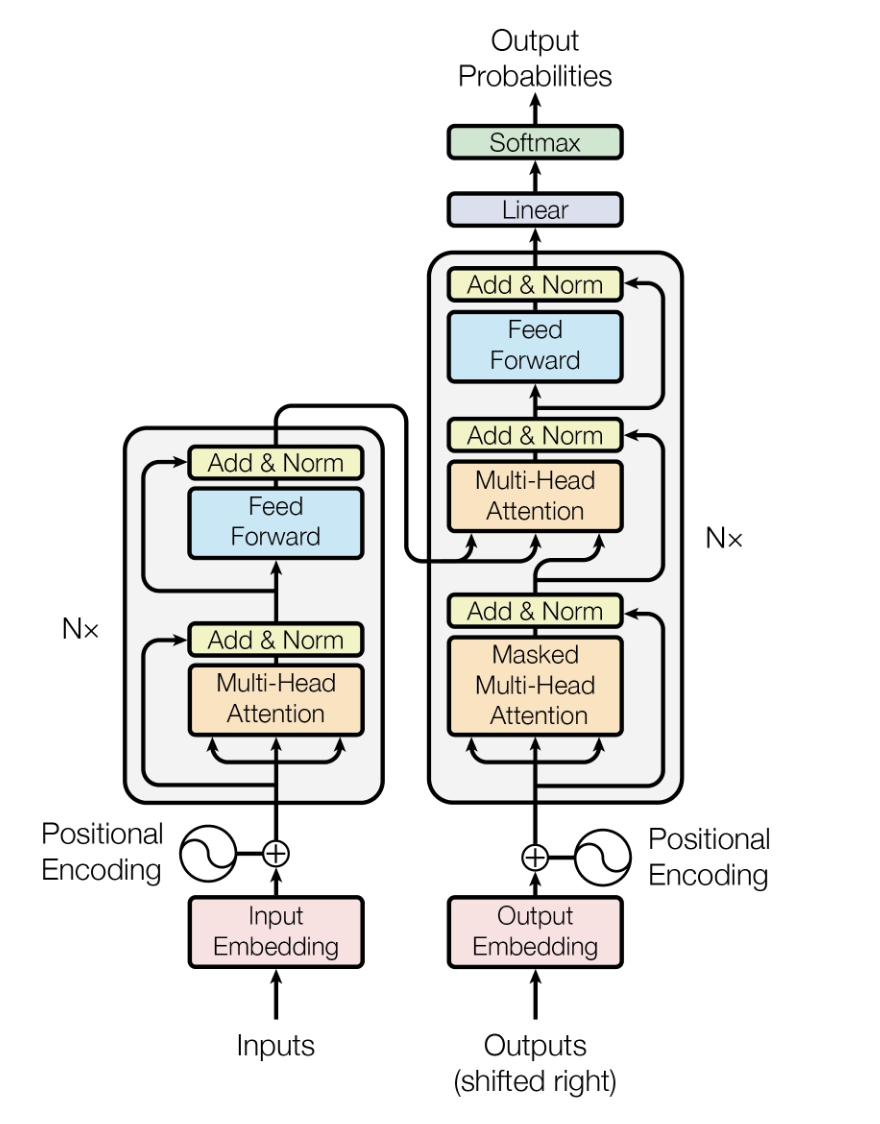
我们先从宏观上走一遍整个流程,以机器翻译任务为例:
-
输入处理:把源语言(比如德语)的句子,转成词向量,再加上位置编码,告诉模型每个词的顺序。
-
编码器编码:输入经过 6 层编码器,每一层都用自注意力机制,把整个句子的上下文信息融合进去,最终输出一个包含了整个源语言语义的 “记忆向量”。
-
解码器解码:解码器一边接收已经生成的目标语言(比如英语)的前缀,一边通过交叉注意力机制,去读取编码器的 “记忆向量”,然后一个字一个字地生成翻译结果。
-
输出预测:最后把解码器的输出,通过线性层和 Softmax,预测下一个字是什么。
是不是很清晰?接下来我们把每个部分拆开,一个一个讲。
三、输入层:词嵌入 \+ 位置编码,把文字变成向量
3.1 词嵌入:把文字转成数字
模型看不懂文字,所以我们首先要把每个词(或者子词)转成一个高维向量,这就是词嵌入(Word Embedding)。
比如我们有一个词表,里面有 3 万个词,每个词都会被映射成一个 512 维的向量(论文里的默认值)。语义相似的词,它们的向量距离也会很近,比如 “国王” 和 “女王” 的向量,就会比 “国王” 和 “苹果” 的向量近得多。
3.2 位置编码:告诉模型谁在前谁在后
这里有个问题:自注意力机制是 “置换不变” 的 —— 也就是说,如果你把句子里的词顺序打乱,它的计算结果不会变。但我们都知道,“我吃苹果” 和 “苹果吃我”,意思完全不一样!
所以我们必须想办法,把 “位置信息” 告诉模型。这就是 ** 位置编码(Positional Encoding)** 的作用。
Transformer 用了一种非常巧妙的正弦余弦编码,不需要训练,直接用公式就能生成:
这里:
-
pos是词在句子里的位置,比如第一个词 pos=0,第二个 pos=1 -
i是向量的维度索引,偶数维度用 sin,奇数维度用 cos -
d_model是词向量的维度,论文里是 512
这种编码的好处是:
-
唯一性:每个位置的编码都是唯一的,模型能分清哪个词在哪个位置
-
相对位置:对于任意两个位置 pos 和 pos+k,它们的编码之间有固定的三角函数关系,模型能很容易学到它们的相对距离
-
长度外推:哪怕训练的时候只见过长度为 512 的句子,推理的时候也能处理长度为 1024 的句子,因为公式能直接生成任意位置的编码
最后,我们把位置编码和词嵌入直接相加,就得到了最终的输入向量 —— 它既包含了词的语义,也包含了词的位置。
四、自注意力机制:Transformer 的灵魂,QKV 三剑客
现在到了最核心的部分:自注意力机制。很多人被 QKV 这三个词吓到了,其实特别好理解,我们用一个图书馆借书的比喻就能讲清楚:
-
Query(查询向量):我现在要找什么?比如我拿着一张书单,上面写着 “我想要 Python 相关的书”。
-
Key(键向量):图书馆里每本书的标签,比如每本书的封面都写着 “Python 入门”、“Java 编程”、“深度学习”。
-
Value(值向量):书本身的内容,就是你借到之后能读到的信息。
当你去借书的时候,你会做什么?
-
拿你的书单(Query),和每本书的标签(Key)比对,看看哪些书和你的需求最匹配
-
匹配度越高,你就越关注那本书
-
最后,你把这些书的内容(Value),按照匹配度加权加起来,就得到了你想要的信息!
是不是一下子就懂了?自注意力的计算过程,就是这么回事!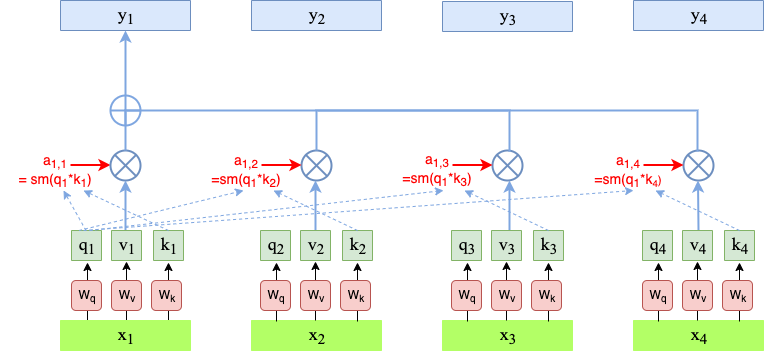
4.1 四步搞定自注意力计算
整个计算过程只需要四步,我们一步一步来看:
第一步:生成 Q、K、V 三个向量
对于输入的每个词向量,我们用三个可学习的权重矩阵,把它分别映射成 Query、Key、Value 三个向量。
这三个矩阵是模型在训练过程中学出来的,就像图书馆里的 “书单生成器”、“标签生成器”、“内容提取器”。
第二步:计算注意力分数,用点积匹配相似度
接下来,我们拿每个词的 Query,和所有词的 Key 做点积,得到的结果就是注意力分数 —— 这个分数代表了 “当前词和其他词的匹配度有多高”。
比如句子里的 “it”,它的 Query 和 “animal” 的 Key 点积结果就会很高,和 “street” 的点积结果就会很低,因为 “it” 指代的是动物。
第三步:缩放,防止分数太大
然后我们把分数除以dk\sqrt{d_k}dk(dkd_kdk是 Key 向量的维度,论文里是 64),这一步叫 “缩放”。
为什么要缩放?因为当维度很高的时候,点积的结果会变得特别大,导致 Softmax 函数进入饱和区,梯度就没了。除以根号 d_k 之后,就能把分数拉回到合理的范围,保证训练稳定。
第四步:Softmax 归一化,加权求和
最后,我们把分数过一遍 Softmax,把它们变成 0 到 1 之间的权重,而且所有加起来等于 1。
然后用这些权重,对所有词的 Value 向量做加权求和,就得到了当前词的最终输出!
这个输出向量,已经融合了整个句子里所有词的信息 —— 比如 “it” 的输出,就把 “animal” 的信息加进来了,模型一下子就知道,哦,原来这个 it 指的是动物!
整个过程的公式就是:
是不是很简单?就这一个公式,就把自注意力的所有计算都概括了!
五、多头注意力:一个头不够,我们来八个
单一的自注意力头,一次只能关注一种类型的关联。但句子里的关联是多种多样的:
-
有的是语法关联,比如主谓宾
-
有的是语义关联,比如指代关系
-
有的是逻辑关联,比如因果关系
一个头怎么可能同时关注这么多东西?所以 Transformer 搞了个 “多头注意力”;(Multi-Head Attention)。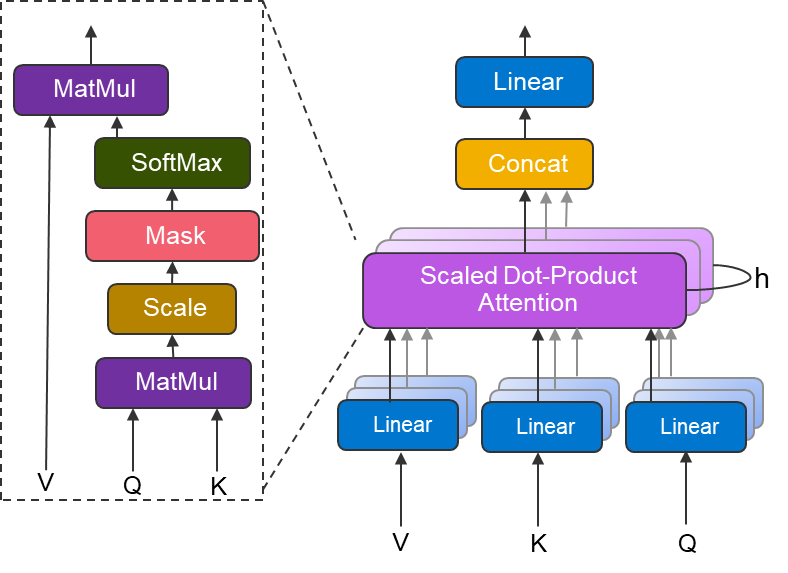
做法很简单:
-
我们把 Q、K、V,分头拆成 8 份(论文里默认 8 个头)
-
每个头自己做一套自注意力计算,就像 8 个独立的小组,各自关注不同的关联
-
比如第一个头关注指代关系,第二个头关注主谓关系,第三个头关注局部的相邻词...
-
最后,把 8 个头的输出拼起来,再过一个线性层,就得到了最终的结果!
这样一来,模型就能同时捕捉不同维度的关联信息,表达能力直接翻了好几倍!
六、编码器与解码器:搭积木一样的深层网络
现在我们有了注意力机制,就可以搭编码器和解码器了。
6.1 编码器层:提取上下文特征
每一层编码器,都包含两个子层:
-
多头自注意力层:让输入的每个词,都能看到整个句子的所有词,融合上下文信息
-
前馈神经网络:对每个词的向量,单独做一个特征变换,把注意力层的输出再加工一下
而且,为了让深层网络能稳定训练,每个子层外面都加了残差连接和层归一化:
-
残差连接:把输入直接加到输出上,防止梯度消失
-
层归一化:把向量的数值归一化到稳定的范围,让训练更稳
就像这样:
x = x + dropout(attn(x))
x = norm(x)
x = x + dropout(ffn(x))
x = norm(x)
然后把 6 个这样的编码器层堆起来,就得到了整个编码器!
6.2 解码器层:逐字生成输出
解码器比编码器多了一个子层,因为它要做自回归生成 —— 也就是一个字一个字地输出,不能提前看到后面的字。
比如我们要翻译 “ich mochte ein bier”,生成英语的时候,先生成 “I”,然后生成 “want”,然后生成 “a”,最后生成 “beer”。
在生成 “want” 的时候,模型只能看到已经生成的 “I”,不能看到还没生成的 “a” 和 “beer”,不然就作弊了!
所以解码器的第一个子层,就是掩码多头自注意力(Masked Multi-Head Attention):
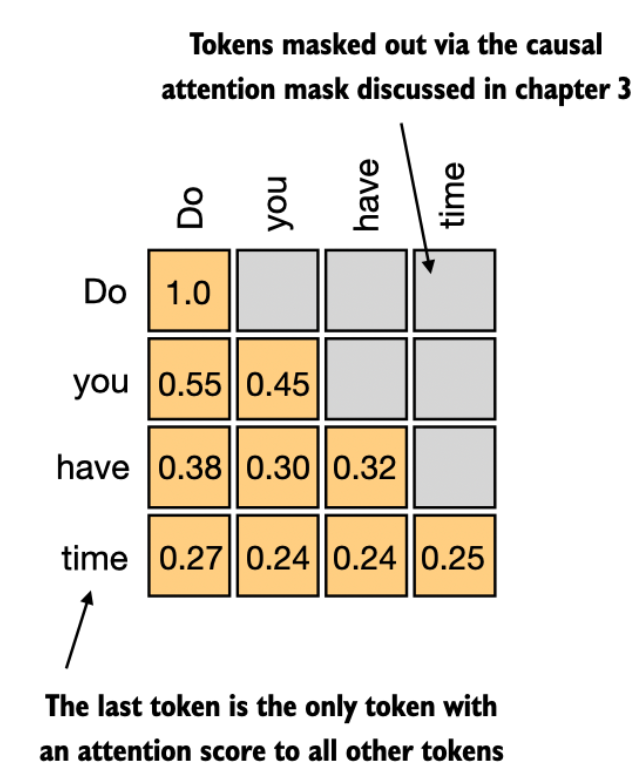
它会在计算注意力的时候,把未来位置的信息全部 mask 掉,也就是把那些位置的分数设成负无穷,这样 Softmax 之后权重就变成 0 了,模型就看不到未来的字了。
然后第二个子层,是交叉注意力(Cross Attention):
-
这里的 Query 来自解码器的输出,也就是我们已经生成的部分
-
Key 和 Value 来自编码器的输出,也就是源语言的整个句子的记忆
-
这样,解码器在生成每个字的时候,就能去编码器的记忆里,找最相关的源语言信息,比如生成 “beer” 的时候,就会重点关注源语言里的 “bier”。
最后,同样是前馈神经网络,加上残差和归一化。
然后把 6 个解码器层堆起来,就得到了整个解码器!
七、PyTorch 从零实现:把理论变成代码
讲了这么多理论,我们来动手写代码,把整个 Transformer 实现出来!代码非常模块化,每一部分都对应我们刚才讲的原理,注释非常详细,你可以直接复制运行。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# -------------------------- 1. 位置编码 --------------------------
class PositionalEncoding(nn.Module):
"""经典的正弦位置编码,不需要训练,直接生成"""
def __init__(self, d_model: int, max_len: int = 5000, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# 计算每个位置的编码
position = torch.arange(max_len).unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度用sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度用cos
# 注册为buffer,不参与梯度计算,但会随模型保存
self.register_buffer('pe', pe.unsqueeze(0)) # [1, max_len, d_model]
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: [batch_size, seq_len, d_model]
x = x + self.pe[:, :x.size(1), :] # 位置编码和词嵌入相加
return self.dropout(x)
# -------------------------- 2. 多头注意力机制 --------------------------
class MultiHeadAttention(nn.Module):
"""
多头注意力,支持三种用法:
1. 编码器自注意力:Q=K=V=输入
2. 解码器掩码自注意力:Q=K=V=目标输入,加mask
3. 交叉注意力:Q=解码器输出,K=V=编码器输出
"""
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# QKV的投影矩阵 + 输出投影矩阵
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.scale = math.sqrt(self.d_k)
def forward(self, query, key, value, attn_mask=None):
batch_size = query.size(0)
# 1. 线性投影 + 分头
Q = self.W_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 现在Q/K/V的形状是: [batch, heads, seq_len, d_k]
# 2. 缩放点积注意力
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale # [b, h, q_len, k_len]
# 如果有mask,就把mask的位置设成负无穷
if attn_mask is not None:
if attn_mask.dim() == 3:
attn_mask = attn_mask.unsqueeze(1)
scores = scores.masked_fill(attn_mask == 0, -1e9)
attn = F.softmax(scores, dim=-1)
attn = self.dropout(attn)
# 3. 加权求和
context = torch.matmul(attn, V) # [b, h, q_len, d_k]
# 4. 合并多头 + 输出投影
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.W_o(context)
return output, attn
# -------------------------- 3. 前馈神经网络 --------------------------
class PositionWiseFeedForward(nn.Module):
"""逐位置前馈网络,每个位置独立计算"""
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 两层线性,中间加ReLU
return self.linear2(self.dropout(F.relu(self.linear1(x))))
# -------------------------- 4. 编码器层 --------------------------
class EncoderLayer(nn.Module):
"""单层编码器"""
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)