MQ 常见问题梳理:消息不丢、顺序消费、幂等处理与积压治理
在分布式系统中,MQ 是非常核心的基础组件。它常用于系统解耦、异步削峰、流量缓冲、事件驱动等场景。
但只要引入 MQ,就绕不开几个经典问题:
- MQ 如何保证消息不丢失?
- MQ 如何保证消息的顺序性?
- MQ 如何保证消息消费的幂等性?
- MQ 如何快速处理积压的消息?
这几个问题看似独立,实际上都围绕一个核心目标:让消息系统在高并发、异常、重试、扩容、故障恢复等复杂场景下仍然稳定可靠。
下面我们逐个展开。
一、MQ 如何保证消息不丢失
消息丢失一般可能发生在三个阶段:
- 生产者发送消息到 MQ 的过程
- MQ Broker 存储消息的过程
- 消费者消费消息的过程
1. 生产者端防丢失
生产者发送消息时,不能只管调用发送接口后就认为消息一定成功了。
正确做法是:必须确认 MQ 已经成功接收消息。
常见手段包括:
- 开启发送确认机制 (同步)
- 判断发送结果
- 失败时进行重试
- 必要时落库记录消息发送状态
以 RocketMQ 为例,生产者发送消息后会得到发送结果,只有返回成功状态,才说明消息已经被 Broker 接收。
典型流程如下:

2. Broker 端防丢失
Broker 收到消息后,也存在丢失风险。
比如消息刚写入内存,还没刷盘,Broker 就宕机了,这时消息就可能丢失。
因此 Broker 端需要关注两个点:
- 消息是否持久化
- 副本是否同步完成
常见做法包括:
- 开启消息持久化
- 使用同步刷盘
- 使用主从复制
- 对关键业务开启同步复制
- 部署高可用集群
以 RocketMQ 为例,可以配置:

同步刷盘可以保证消息写入磁盘后才返回成功。
同步复制可以保证消息同步到从节点后才返回成功。
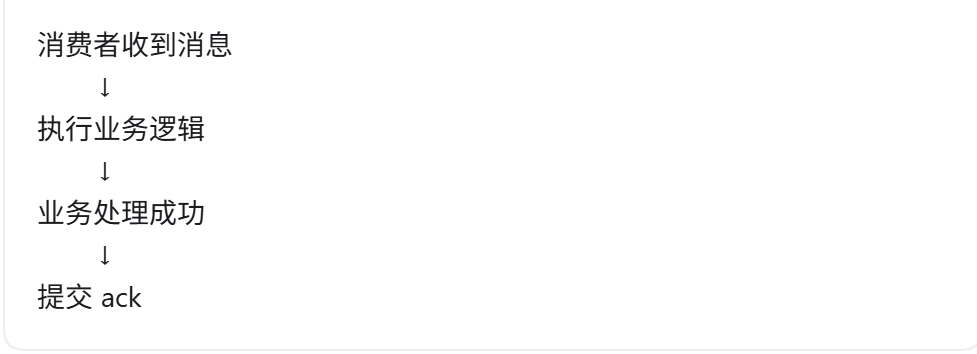
3. 消费者端防丢失
消费者端最容易出现的问题是:消息还没真正处理成功,就提前提交了消费确认
正确做法是:业务逻辑处理成功之后,再提交消费确认。
MQ 保证消息不丢失,本质上是保证三件事:
生产者确认发送成功
Broker 确认可靠存储
消费者确认处理成功后再 ack
二、MQ 如何保证消息的顺序性
消息顺序性分为两类:
- 全局顺序
- 局部顺序
全局顺序是指所有消息严格按照发送顺序消费。
局部顺序是指同一个业务维度下的消息有序,比如同一个订单的消息有序、同一个用户的消息有序。
在实际项目中,大多数场景只需要局部顺序。
例如订单状态流转:
创建订单 → 支付成功 → 商家发货 → 确认收货
对于同一个订单,这些事件必须按顺序处理。
但不同订单之间并不要求有序。
1. 为什么 MQ 会乱序
MQ 乱序通常来自以下几个原因:
- 多个生产者并发发送
- 消息进入了不同队列
- 多个消费者并发消费
- 消费失败后重试
- 消费者处理时间不同
比如同一个订单的三条消息进入了三个不同队列:
Queue 1:订单创建
Queue 2:支付成功
Queue 3:订单取消
如果三个消费者并发消费,就无法保证处理顺序。
2. 保证顺序的核心思路
要保证顺序,核心思路是:
同一业务 key 的消息发送到同一个队列,并由同一个消费者串行消费。
比如以 orderId 作为路由 key:
queueIndex = hash(orderId) % queueCount
这样同一个 orderId 的消息一定进入同一个队列。
然后消费者对这个队列进行顺序消费。
3. 顺序消息的注意点
使用顺序消息时,需要注意:
- 选择稳定的业务 key,比如 orderId、userId
- 同一业务 key 必须进入同一个队列
- 消费端避免并发处理同一队列
- 消费失败时不要跳过当前消息
- 谨慎扩容队列数量,因为 hash 结果可能变化
三、MQ 如何保证消息幂等性
只要使用 MQ,就必须默认一件事:
消息可能会被重复消费,重复消费并不是 MQ 的 bug,而是分布式系统中的正常现象。
例如:
- 消费者处理成功,但提交 ack 失败
- Broker 没收到 ack,重新投递消息
- 消费者处理超时,触发重试
- 网络抖动导致状态不一致
- 生产者重试导致重复发送
所以 MQ 很难做到“绝对只消费一次”。
实际工程中通常采用:
MQ 保证至少投递一次,业务侧保证幂等
也就是说,消息可以重复到达,但业务结果只能生效一次。
1. 什么是幂等
幂等是指同一个操作执行一次和执行多次,最终结果一致。
例如:
update order set status = 'PAID' where order_id = 1001;
这类操作天然比较接近幂等,因为多次把订单状态更新为 PAID,结果是一样的。
但下面这种操作就不是幂等:
update account set balance = balance - 100 where user_id = 1;
如果重复执行,就会重复扣款。
2. 常见幂等方案
唯一业务流水号
给每条消息分配一个全局唯一的 messageId 或业务流水号。
消费时先判断是否处理过。

可以设计一张消费记录表:
create table mq_consume_log (
id bigint primary key auto_increment,
message_id varchar(128) not null,
consumer_group varchar(128) not null,
status tinyint not null,
create_time datetime not null,
unique key uk_msg_consumer (message_id, consumer_group)
);消费时先插入消费记录,利用唯一索引防重复。
如果插入成功,说明第一次消费,可以继续处理业务。
如果插入失败,说明消息已经处理过,直接返回成功。
四、MQ 如何快速处理积压的消息
消息积压是生产环境中非常常见的问题。
一般表现为:
- 消费延迟越来越大
- 队列堆积数量持续增加
- 用户侧感知到状态更新变慢
- 下游系统压力异常
- 消费者频繁超时或重试
1. 消息为什么会积压
常见原因包括:
- 消费者处理能力不足
- 消费者实例数量太少
- 单条消息处理耗时过长
- 下游数据库或接口变慢
- 消费者异常导致大量重试
- 某类异常消息阻塞队列
- 生产流量突增
- 顺序消息被某一条慢消息卡住
解决积压前,首先要判断瓶颈在哪里。
2. 快速处理积压的思路
处理积压的核心公式是:
消费速度 > 生产速度
要做到这一点,要么提高消费能力,要么降低生产速度,或者两者同时做。
3. 临时扩容消费者
最直接的方式是增加消费者实例。
例如原来只有 4 个消费者,可以临时扩容到 16 个。
但扩容是否有效,取决于 MQ 的队列数量。
如果只有 4 个队列,即使启动 16 个消费者,真正并行消费的通常也只有 4 个。
所以消费者并发能力受两个因素限制:
最大并发度 ≈ 队列数量 × 单消费者线程数
如果队列数太少,需要考虑增加队列数量。
不过如果是顺序消息,不能盲目扩容,否则可能破坏顺序性。
4. 提高单个消费者处理速度
如果消费者内部处理慢,可以从以下方面优化:
- 批量拉取消息
- 批量写数据库
- 减少远程调用
- 使用连接池
- 优化 SQL 和索引
- 将串行逻辑改成并行处理
- 对非核心操作异步化
- 减少锁竞争
- 调整消费线程池
例如原来每条消息都单独写库:
1 条消息 = 1 次 insert
可以优化为:
100 条消息 = 1 次 batch insert

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)