【论文阅读】VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
快速了解部分
基础信息(英文):
- 题目: VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
- 时间: 2026.02
- 机构: Stanford University
- 3个英文关键词: VLA, World Model, Diffusion
1句话通俗总结
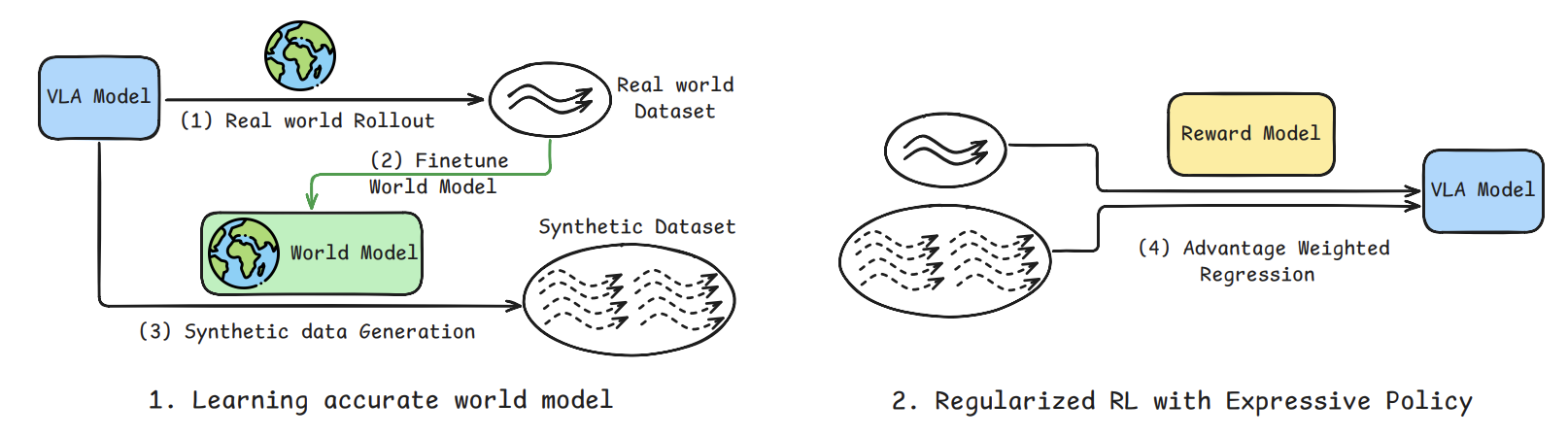
通过用真实机器人跑坏掉的数据“校准”世界模型(World Model),让这个模拟器不再“画饼”(过于乐观),然后用校准后的模拟器生成海量假数据来训练机器人策略,实现了在接触丰富、软体物体任务上的大幅提效。
研究痛点
现有的世界模型(模拟器)物理精度不够,因为它们只在演示数据(全是成功的数据)上训练,导致模型过于乐观,模拟不出失败的物理交互(比如推不动东西、抓滑了),没法用来训练复杂的机器人策略。
核心方法
先用少量真实机器人跑出来的数据(包含成功和失败)去微调预训练的世界模型,让它“认清现实”;然后用这个校准后的模型生成大量带奖励标签的合成数据,通过监督微调来提升VLA策略。
深入了解部分
作者核心主张
世界模型要想能用来做强化学习训练,必须先用在线采集的真实Rollout数据(特别是失败案例)进行“物理接地”,否则生成的数据全是幻觉,越练越差。
创新本质
相比SOTA,真正新在“迭代共提升”的闭环流程设计,即策略和世界模型在真实数据和合成数据之间交替微调,而不是单向的“模拟器生成数据喂给策略”。
方法直觉解释
输入:预训练的VLA策略 + 预训练的世界模型 + 少量真实机器人交互数据(含失败)。
处理:先用真实数据微调世界模型,让它学会物理规律(不再盲目乐观);再用这个模型在“脑内”生成大量想象出的轨迹,并用一个视觉语言奖励模型(VLM)自动打标签筛选出成功的轨迹。
输出:用筛选出的高质量合成数据+真实数据微调VLA策略,使其性能大幅提升。
关键实现细节
- 世界模型微调:在真实Rollout数据上继续微调预训练的Ctrl-World(Diffusion模型),并混合原始大规模数据集防止过拟合。
- 奖励模型:微调Qwen3-VL作为奖励函数,通过设定“yes” token的概率阈值(>0.8)来严格判断任务是否成功,过滤掉模棱两可的假成功。
技术传承
继承自Ctrl-World (2025) 的世界模型架构和 π0.5\pi_0.5π0.5 (2025) 的 VLA 策略基座;改进了单纯依赖演示数据的训练范式,引入了在线交互数据来修正模型偏差。
实验验证(只列最关键的2-3个)
exp1: 世界模型物理精度测试
- 设置: 对比预训练模型 vs 加入真实Rollout微调后的模型,在接触丰富任务上的视频预测质量(PSNR/SSIM)和事件成功率混淆矩阵。
- 数据: DROID 真实机器人数据集。
- 结论: 加入真实数据微调后,模型预测的物理交互准确率大幅提升,显著减少了“假阳性”(预测成功实际失败)的情况。
exp2: 策略下游任务提效 - 设置: 在堆叠、翻书、擦除等5个复杂任务上,对比基线(Filtered BC, DSRL)与本方法(VLAW)的最终成功率。
- 数据: 真实机器人平台 DROID。
- 结论: 相比基线,本方法平均成功率大幅提升,在部分任务上实现了绝对成功率的显著增长(例如在某些任务上比基线提升10%以上)。
同类工作对比
- Ctrl-World <2025>: 同一团队的前作,是一个强大的预训练世界模型,但本文指出它在没有真实Rollout数据微调前,物理精度不足,无法直接用于复杂策略提升。
- DSRL <2025>: 一种不依赖世界模型的在线强化学习方法,本文对比显示DSRL在多任务设置下提升有限,而本文利用合成数据能获得更大收益。
- DayDreamer <2023>: 早期的视觉模型强化学习工作,受限于模型容量和数据规模,通常是任务特定的,而本文利用大规模扩散模型实现了多任务通用的世界模型。
强相关文献(3篇)
- Ctrl-World: A Controllable Generative World Model for Robot Manipulation <2025>
- π0.5\pi_0.5π0.5: A Vision-Language-Action Model with Open-World Generalization <2025>
- RoboReward: General-purpose Vision-Language Reward Models for Robotics <2026>
局限与适用边界
作者承认目前仅在5类特定任务上验证了效果,扩展到更广泛任务集还需要更多在线数据;该方法适用于需要大量交互但真实采样昂贵的场景,不适用于物理规律极其复杂且预训练模型完全未见过的全新领域。
我的
想法还是比较合理常见的。就是先真机采集,采完训wm,再用wm合成数据训Policy。然后可以一直循环。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)