大模型是怎么“听懂“你说话、再去调工具的?——以客服 Agent 为例
大模型是怎么"听懂"你说话、再去调工具的?——以客服 Agent 为例
本文面向对 AI Agent 感兴趣的开发者,用最通俗的语言讲清楚:大模型如何识别用户意图、如何决定调用哪个工具、调用流程是怎样的,以及怎么让这个过程更准确。全文无公式,有代码,有流程图,看完就能上手。
一、从一个生活场景说起
你有没有打过快递公司客服电话?
你说:“我的快递怎么还没到?”
电话那头的客服小姐姐,脑子里瞬间做了三件事:
- 判断你要干嘛——查物流,不是投诉,不是退款
- 提取关键信息——你的订单号、手机号
- 去系统里查一下,然后把结果告诉你
大模型客服 Agent 做的,就是完全一样的三件事。 只不过"去系统查"这一步,变成了"调用工具"。
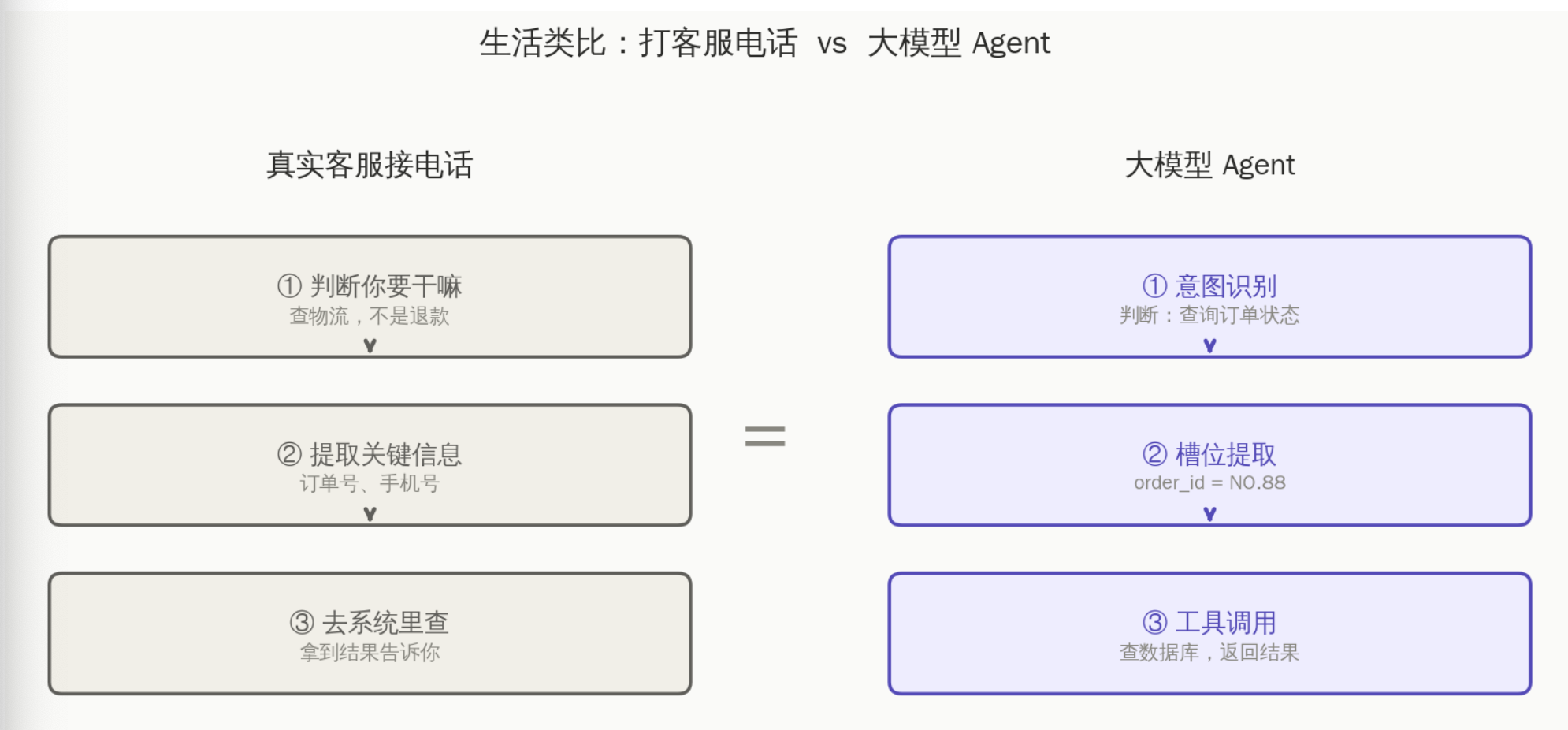
图1:生活类比——打客服电话的三步,和大模型 Agent 的三步完全一一对应
整篇文章,就围绕这三件事展开。
二、第一件事:识别意图
什么叫"意图识别"
用户发来一句话,模型要先判断:这句话是想做什么?
比如下面这几句,虽然说法不同,但意图一样:
- “我的包裹还没到”
- “快递在哪啊”
- “帮我查一下订单 NO.88”
它们都是查询物流,不是退款,不是投诉。
意图识别,说白了就是一个分类任务:把用户的话归到某一类操作上。
同时还要做"槽位提取"
光知道用户想查物流还不够,还得知道查哪个订单——这就是槽位提取,从用户的话里把关键参数抠出来。
用户说:"帮我查一下订单 NO.88"
↓ 意图识别
意图 = 查询订单状态
↓ 槽位提取
order_id = "NO.88"
user_id = 从登录态获取(用户没说,系统补全)
在 Function Calling(工具调用)里,这两件事是同时完成的——模型看到工具定义,自己决定调哪个、填什么参数,一步搞定。
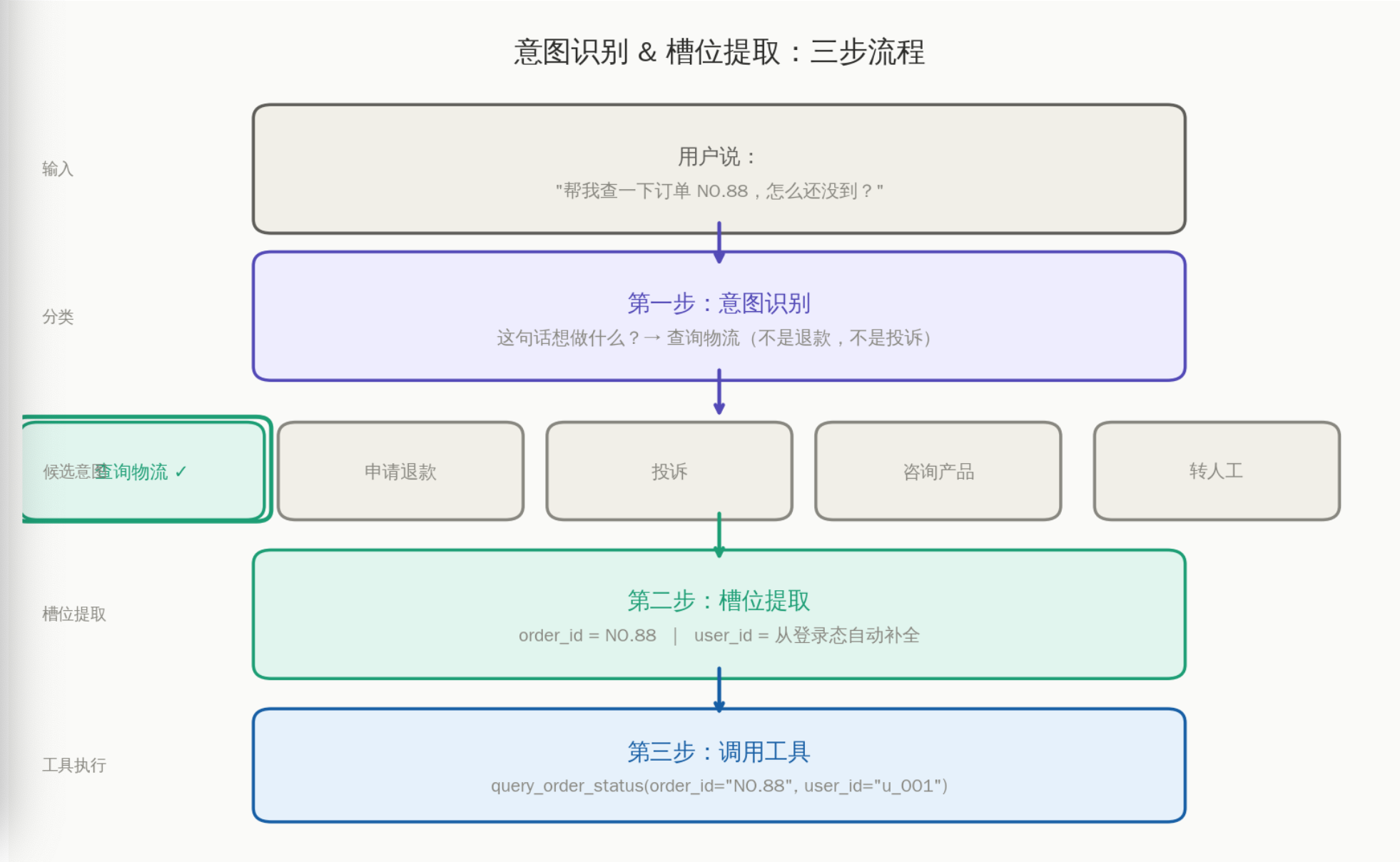
图2:从用户一句话到工具调用的三步流程——意图识别、槽位提取、工具执行
三、第二件事:调用工具
工具是什么
工具就是一个个可以被调用的函数,比如:
query_order_status:查询订单状态apply_refund:申请退款transfer_to_human:转人工客服search_knowledge_base:搜索知识库
你把这些工具的"说明书"告诉模型,模型就知道什么情况该用哪个。
工具说明书长什么样
这是 Function Calling 里工具定义的真实格式:
{
"name": "query_order_status",
"description": "查询指定订单的物流和配送状态。当用户询问订单是否发货、快递在哪、预计几天到时使用。不适用于退款或投诉场景。",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单号,从用户的话里提取,通常是数字或字母+数字的组合"
},
"user_id": {
"type": "string",
"description": "用户 ID,从当前登录态获取"
}
},
"required": ["order_id", "user_id"]
}
}
划重点:
description字段是核心。 模型靠这段文字来判断"这个工具适不适合用在当前情况"。写得模糊,意图识别就会出错。
完整的调用流程
整个过程是一个两轮对话,下图展示了用户、大模型、工具系统三方之间的消息流转:

图3:工具调用完整时序图——两轮对话,七个步骤
用代码表示:
// 第一轮:发用户消息 + 工具定义
const response = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
messages: [
{ role: "user", content: "帮我查一下订单 NO.88,怎么还没到?" }
],
tools: [queryOrderTool, applyRefundTool, transferHumanTool],
system: "你是XX电商的智能客服,只使用提供的工具来回答问题..."
});
// 模型返回工具调用指令
// response.content[0] = {
// type: "tool_use",
// name: "query_order_status",
// input: { order_id: "NO.88", user_id: "u_001" }
// }
// 执行工具,拿到真实数据
const result = await queryOrderStatus({
order_id: "NO.88",
user_id: "u_001"
});
// result = { status: "运输中", eta: "明天下午", location: "上海转运中心" }
// 第二轮:把结果塞回对话,让模型生成回复
const finalResponse = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
messages: [
{ role: "user", content: "帮我查一下订单 NO.88,怎么还没到?" },
{ role: "assistant", content: response.content }, // 模型的工具调用
{ role: "user", content: [{ // 工具执行结果
type: "tool_result",
tool_use_id: response.content[0].id,
content: JSON.stringify(result)
}]}
],
tools: [queryOrderTool, applyRefundTool, transferHumanTool]
});
// 模型最终回复:"您好,您的订单正在运输中,目前在上海转运中心,预计明天下午送达~"
整个模型扮演的角色,本质上是一个翻译官:把用户的大白话翻译成系统能执行的指令,再把系统返回的数据翻译成人话告诉用户。
四、第三件事:让它更准确
这是最重要的部分。实际落地时,意图识别出错是最常见的问题。以下是六个经过验证的提升方向:
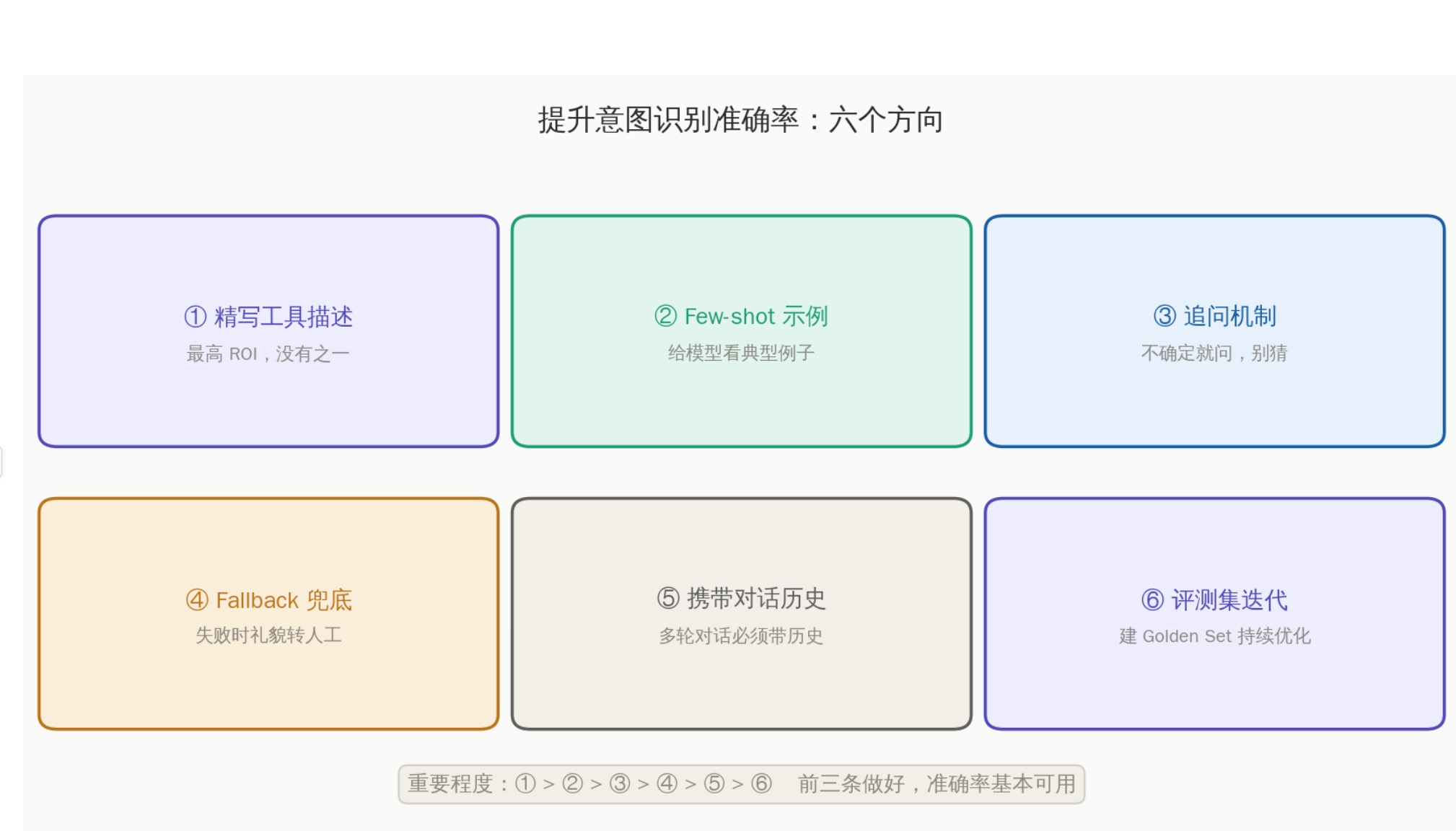
图4:提升意图识别准确率的六个方向,按重要程度排序
方向一:把工具描述写清楚(最高性价比)
这一步做好,准确率可以提升 60%~80%。
很多人写工具描述就三个字:“处理退款”。这完全没用,模型不知道什么情况该用、什么情况不该用。
正确做法:写清楚三件事——适用场景、不适用场景、需要哪些参数。

图5:工具描述好坏对比——左侧模糊写法 vs 右侧清晰写法,准确率差距达 60%+
如果有两个工具很容易混淆,专门加一条对比说明:
注意区分:
- 用户说"还没到" → 查询物流(query_order)
- 用户说"不想要了" → 退款(apply_refund)
- 用户说"东西坏了" → 先查订单,再退款(需要两步)
方向二:给几个典型例子(Few-shot)
有例子比有解释管用。在 System Prompt 里直接写:
【意图示例】
用户:我的包裹 NO.66 怎么还没到?
→ 调用:query_order_status,order_id = "NO.66"
用户:我要退款,订单 NO.22,东西质量太差了
→ 调用:apply_refund,order_id = "NO.22",reason = "质量问题"
用户:你们服务太差了!我要投诉!
→ 不调用工具,先同理心回应,询问具体遇到了什么问题
方向三:碰到不确定的,先追问
这是很多人容易忽略的地方——不要猜,猜错了比什么都不做更糟。
在 System Prompt 里明确告诉模型:
【决策规则】
- 意图明确且参数齐全 → 直接调用工具
- 意图明确但缺少必要参数 → 追问缺失的参数
- 意图模糊(无法判断用户想做什么)→ 追问意图
- 每次只问一个最关键的问题,不要一口气列出五条
实际效果对比:
用户说:"有点问题"
❌ 模型猜测并直接调用退款工具 → 方向完全错误
✅ 模型追问:"您好,请问是遇到了物流问题,还是商品问题呢?" → 用户体验好
方向四、五、六:Fallback + 对话历史 + 评测迭代
看下面这张完整决策树,涵盖了意图识别后所有可能的情况:

图6:完整决策树——意图识别后的三条分支,以及 Fallback 兜底机制
Fallback(兜底):任何时候都要有保底路径,一旦识别失败,礼貌说明并转人工,绝不静默失败让用户傻等。
携带对话历史:每一轮发给模型的消息,都要带上完整的对话历史,否则模型不知道上下文:
// 每轮都带完整历史
const messages = [
{ role: "user", content: "我要退款" },
{ role: "assistant", content: "请问是哪个订单呢?" },
{ role: "user", content: "NO.88" },
{ role: "assistant", content: "请问退款原因是什么?" },
{ role: "user", content: "东西坏了" } // 当前这轮
];
评测迭代:建议收集真实用户输入(脱敏),人工标注正确意图建立 Golden Set(200 条以上),持续评测和优化。参考指标:
| 指标 | 说明 | 参考目标 |
|---|---|---|
| 意图准确率 | 识别正确的比例 | ≥ 92% |
| 槽位填充率 | 必要参数提取成功率 | ≥ 95% |
| 误触发率 | 不该调工具却调了 | ≤ 3% |
| 兜底触发率 | Fallback 被触发的比例 | 越低越好 |
五、总结
用一句话概括整个流程:
用户说一句话 → 模型识别意图、提取参数 → 调用对应工具拿到数据 → 把数据翻译成人话回复用户
影响准确率的核心因素,按重要程度排序:
- 工具描述写得好不好(最重要,没有之一)
- 有没有给典型的 Few-shot 示例
- 不确定时有没有追问机制
- 有没有 Fallback 兜底
- 有没有持续的评测迭代
前三条做好,一个客服 Agent 的意图识别准确率基本就能达到可用水平。剩下的就是在真实数据上不断打磨。
六、附:客服 Agent 工程实现参考
完整 System Prompt 模板
你是 [公司名] 的智能客服助手。
【基本原则】
- 只使用提供的工具来处理用户请求,不要凭空给出答案
- 意图不明确时,先追问,每次只问一个最关键的问题
- 工具调用前,确认所有必要参数都已获取
- 遇到无法处理的情况,礼貌说明并转接人工
【意图示例】
用户:我的快递还没到 → 调用 query_order_status
用户:我要退款 → 先确认订单号和原因,再调用 apply_refund
用户:投诉 / 情绪激动 → 先安抚,再调用 transfer_to_human
【工具边界说明】
- 查询物流 vs 申请退款:用户说"在哪/没到"→ 查物流;说"不要了/退钱"→ 退款
- 复杂问题(涉及多个诉求)→ 拆分处理,一步一步来
工具配置完整示例
const tools = [
{
name: "query_order_status",
description: "查询订单物流状态。用于:用户询问包裹位置、发货情况、预计到达时间。不用于:退款、投诉。",
input_schema: {
type: "object",
properties: {
order_id: { type: "string", description: "订单号,从用户话语中提取" },
user_id: { type: "string", description: "用户ID,从登录态获取" }
},
required: ["order_id", "user_id"]
}
},
{
name: "apply_refund",
description: "申请退款。用于:用户明确说要退款、退钱、不想要了。必须先获取退款原因再调用。",
input_schema: {
type: "object",
properties: {
order_id: { type: "string", description: "订单号" },
refund_reason: { type: "string", description: "退款原因,如:质量问题、不想要了、发错货等" }
},
required: ["order_id", "refund_reason"]
}
},
{
name: "transfer_to_human",
description: "转接人工客服。用于:用户情绪激动、问题复杂无法自动处理、用户主动要求人工。",
input_schema: {
type: "object",
properties: {
reason: { type: "string", description: "转接原因" }
},
required: ["reason"]
}
}
];

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)