大模型入门-GRPO 组内相对策略优化
2.8 GRPO 组内相对策略优化 (Group Relative Policy Optimization)
论文地址: https://arxiv.org/abs/2402.03300
2.8.1 回顾:PPO 流程介绍
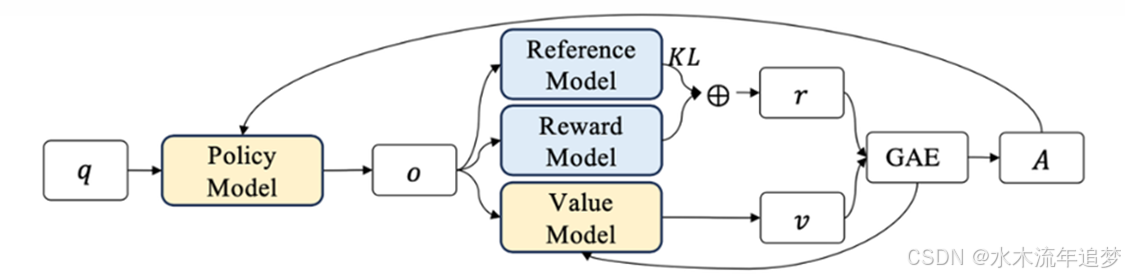
在深入 GRPO 之前,我们先简单回顾一下 PPO(近端策略优化)的流程。
对于输入问题 q q q,经过策略模型 (Policy Model) 生成回答 o o o 。接着这个输出会被输入到另外 3 个模型中:
参考模型 (Reference, 冻结): 计算输出与训练数据之间的 KL 散度,用于限制策略的更新幅度,防止模型“训歪” 。
奖励模型 (Reward, 冻结): 对生成的回答进行打分,生成实际的奖励分数 r r r 。
价值模型 (Value, 更新): 也被称为 Critic 模型,用于预测预期的分数 v v v 。
优势计算 (GAE): 优势 A A A = 实际分数 - 预期分数 。如果在输出时生成了某个 token,且这个 token 的优势大于 0,我们就应该增加生成该 token 的概率;反之,如果优势小于 0,就减少生成该 token 的概率 。最终,模型通过强化具有正优势的 token,使得生成结果更加符合预期目标 。
2.8.2 GRPO:奖励的优化方法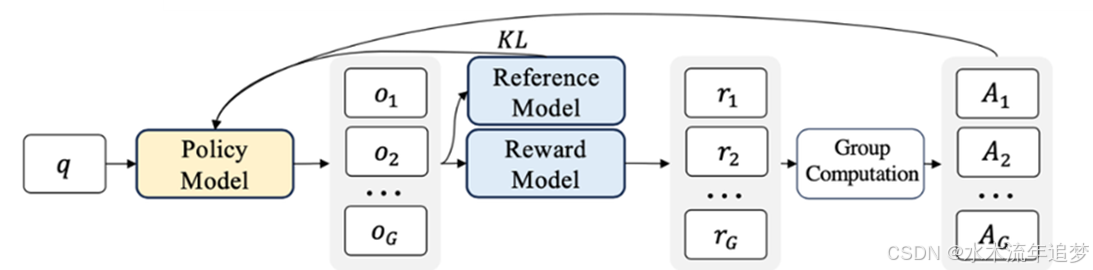
GRPO(组内相对策略优化)的核心正如其名,它的创新点在于使用组间关系去重塑优势的计算方法 :
-
组内生成: 输入 q q q,经过策略模型,针对同一个 q q q 一次性生成多个回答 o 1 , o 2 , . . . , o G o_{1}, o_{2}, ..., o_{G} o1,o2,...,oG 。
-
模型评估: 接着将这些输出输入到 2 个冻结的模型中 :
参考模型 (Reference): 计算输出与训练数据之间的 KL 散度 。
奖励模型 (Reward): 为每个回答生成对应的分数 r 1 , r 2 , . . . , r G r_{1}, r_{2}, ..., r_{G} r1,r2,...,rG 。
-
计算基准: 计算这组(共 G G G 个)回答分数的均值 μ G \mu_{G} μG 和标准差 σ G \sigma_{G} σG 。
-
计算相对优势: 计算每个样本的相对优势 :
A i G = r i − μ G σ G + ϵ A_{i}^{G}=\frac{r_{i}-\mu_{G}}{\sigma_{G}+\epsilon} AiG=σG+ϵri−μG
然后利用这个优势值进行强化,使生成结果更加符合预期目标 。
核心逻辑: 模型通过强化优势大于 0 的 token 生成,抑制优势小于 0 的 token 生成,从而整体提升生成质量
2.8.3 PPO VS GRPO 的核心区别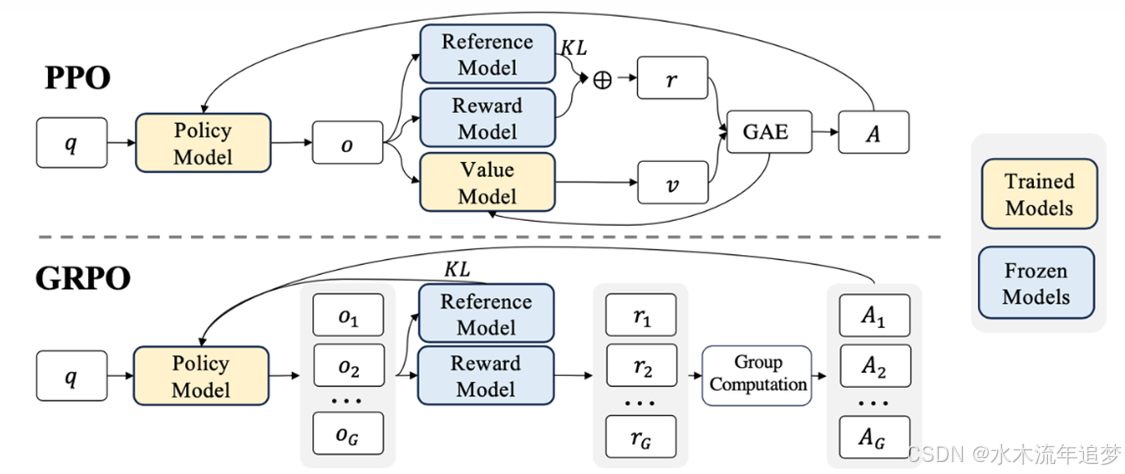
1. 损失函数对比
PPO 损失函数: 通过剪切函数 clip 限制策略更新幅度,确保数值稳定性 。
J P P O ( θ ) = E [ m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] J_{PPO}(\theta)=\mathbb{E}[min(r_{t}(\theta)A_{t},clip(r_{t}(\theta),1-\epsilon,1+\epsilon)A_{t})] JPPO(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
GRPO 损失函数: 通过标准化和 KL 散度共同控制策略变化 。
GRPO 优势值定义为组内标准化:
A i = r ( q i , O i ) − m e a n ( { r ( q j , O j ) } j = 1 G ) s t d ( { r ( q j , O j ) } j = 1 G ) A_{i}=\frac{r(q_{i},O_{i})-mean(\{r(q_{j},O_{j})\}_{j=1}^{G})}{std(\{r(q_{j},O_{j})\}_{j=1}^{G})} Ai=std({r(qj,Oj)}j=1G)r(qi,Oi)−mean({r(qj,Oj)}j=1G)
重要性采样权重定义为:
r i , t ( θ ) = π θ ( o i , t ∣ q i , o i : < t ) π o l d ( o i , t ∣ q i , o i : < t ) r_{i,t}(\theta)=\frac{\pi_{\theta}(o_{i,t}|q_{i},o_{i:<t})}{\pi_{old}(o_{i,t}|q_{i},o_{i:<t})} ri,t(θ)=πold(oi,t∣qi,oi:<t)πθ(oi,t∣qi,oi:<t)
KL 散度采用 K3 近似法计算:
K 3 = π r e f ( o i , t ∣ q i , o i : < t ) π θ ( o i , t ∣ q i , o i : < t ) − l o g π r e f ( o i , t ∣ q i , o i : < t ) π θ ( o i , t ∣ q i , o i : < t ) − 1 K3=\frac{\pi_{ref}(o_{i,t}|q_{i},o_{i:<t})}{\pi_{\theta}(o_{i,t}|q_{i},o_{i:<t})}-log\frac{\pi_{ref}(o_{i,t}|q_{i},o_{i:<t})}{\pi_{\theta}(o_{i,t}|q_{i},o_{i:<t})}-1 K3=πθ(oi,t∣qi,oi:<t)πref(oi,t∣qi,oi:<t)−logπθ(oi,t∣qi,oi:<t)πref(oi,t∣qi,oi:<t)−1
符号速查: * q i q_{i} qi: 提示词 (prompt) * O i O_{i} Oi: 生成的响应序列, ∣ O i ∣ |O_{i}| ∣Oi∣ 为长度 * o i , t o_{i,t} oi,t: 响应序列中的第 t t t 个 token * o i : < t o_{i:<t} oi:<t: 第 t t t 个 token 之前的前缀 * π θ , π o l d , π r e f \pi_{\theta}, \pi_{old}, \pi_{ref} πθ,πold,πref: 分别为当前策略、旧策略、参考策略 * r ( q i , O i ) r(q_{i},O_{i}) r(qi,Oi): 奖励值 * G G G: 批次中的提示词-响应对总数
损失函数的直觉理解: GRPO 存在一个特性,即响应序列 O i O_{i} Oi 中所有 token o i , t o_{i,t} oi,t 共享同一个优势值 A i A_{i} Ai 。这可以理解为“提升团队整体表现并控制生成的变动”。它激励每个团队成员努力超越团队的平均水平,并奖励那些贡献更高的人,同时让生成 token 的分布与训练数据分布保持一致性 。
2. 架构与资源优势
GRPO 更关注群体: PPO 更注重单个样本的表现,而 GRPO 利用群体统计量计算相对优势,能够一次性提升整个团队(更多数据量)的表现 。
GRPO 更省显存(杀手锏): 这是 GRPO 最大的工程优势。因为它只利用 Reward 模型生成的分数进行组内对比来计算损失,彻底抛弃了 PPO 训练过程中必须的 Value (Critic) 模型。这为大模型对齐训练节省了海量的 GPU 显存 。
2.8.4 GRPO Loss 核心代码解析
以下是 GRPO 训练过程中计算 Loss、Token 对数概率以及准备输入数据的核心代码实现,供研究者参考 。
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
"""
计算 GRPO 的损失值
参数:
model: 当前训练的策略模型
inputs: 包含输入数据的字典 (prompt, completion等)
"""
if return_outputs:
raise ValueError("GRPOTrainer不支持返回输出结果")
# 提取输入数据中的prompt和completion部分
prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"]
completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"]
# 拼接prompt和completion形成完整输入
input_ids = torch.cat([prompt_ids, completion_ids], dim=1)
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)
# 只需要计算completion部分的logits
logits_to_keep = completion_ids.size(1)
# 获取每个token的对数概率
per_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep)
# 计算模型与参考模型之间的KL散度 (用于约束策略更新)
ref_per_token_logps = inputs["ref_per_token_logps"]
# 使用KL散度的近似计算: f(x)=e^x - x - 1, 其中x = ref_logp - current_logp
per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
# 获取优势函数 (指导策略更新的信号)
advantages = inputs["advantages"] # 形状: (批次大小*生成数量, )
# 1. 计算策略比 (当前策略概率 / 参考策略概率) = exp(current_logp - ref_logp)
ratio = torch.exp(per_token_logps - ref_per_token_logps.detach())
# 2. 计算clip后的策略比 (限制在 [1-epsilon, 1+epsilon] 区间)
advantages_unsqueezed = advantages.unsqueeze(1)
epsilon = self.epsilon # 从类参数中获取clip系数 (如 0.2)
clipped_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon)
# 3. 计算原始策略比优势和clip后策略比优势,取两者最小值
surr1 = ratio * advantages_unsqueezed # 原始项
surr2 = clipped_ratio * advantages_unsqueezed # clip后的项
per_token_surrogate = torch.min(surr1, surr2) # 取最小值
# 结合KL惩罚项,取负值是因为要最小化损失 (对应最大化目标)
per_token_loss = -(per_token_surrogate - self.beta * per_token_kl)
# 应用掩码计算批次平均损失: 只计算completion部分的有效token
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
# 记录指标: 完成序列的平均长度、平均KL散度、clip比例等
completion_length = self.accelerator.gather_for_metrics(completion_mask.sum(1)).float().mean().item()
self._metrics["completion_length"].append(completion_length)
mean_kl = ((per_token_kl * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
self._metrics["kl"].append(self.accelerator.gather_for_metrics(mean_kl).mean().item())
clip_fraction = ((ratio < (1 - epsilon)).float().mean() + (ratio > (1 + epsilon)).float().mean())
self._metrics["clip_fraction"].append(self.accelerator.gather_for_metrics(clip_fraction).mean().item())
return loss
def _get_per_token_logps(self, model, input_ids, attention_mask, logits_to_keep):
"""
计算每个token的对数概率
"""
# 加1是因为最后一个logit会被排除 (不需要预测下一个token)
logits = model(
input_ids=input_ids,
attention_mask=attention_mask,
logits_to_keep=logits_to_keep + 1
).logits
# 排除最后一个logit (因为它对应下一个token的预测,我们不需要)
logits = logits[:, :-1, :] # 形状: (批次大小, 序列长度-1, 词汇表大小)
# 计算输入token的对数概率,使用循环减少内存峰值
per_token_logps = []
for logits_row, input_ids_row in zip(logits, input_ids[:, -logits_to_keep:]):
# 对logits进行softmax得到概率分布,再取对数
log_probs = logits_row.log_softmax(dim=-1)
# 提取每个token对应的对数概率
token_log_prob = torch.gather(log_probs, dim=1, index=input_ids_row.unsqueeze(1)).squeeze(1)
per_token_logps.append(token_log_prob)
return torch.stack(per_token_logps)
def _prepare_inputs(self, inputs: dict[str, Any]) -> dict[str, Any]:
"""
准备模型输入数据,处理prompt和生成的completion,计算奖励和优势函数
"""
device = self.accelerator.device
prompts = [x["prompt"] for x in inputs]
# 应用聊天模板处理prompt并tokenize
prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs]
prompt_inputs = self.processing_class(
prompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False
)
prompt_inputs = super()._prepare_inputs(prompt_inputs)
prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"]
# 截断过长的prompt
if self.max_prompt_length is not None:
prompt_ids = prompt_ids[:, -self.max_prompt_length:]
prompt_mask = prompt_mask[:, -self.max_prompt_length:]
# 生成completion (响应内容)
with unwrap_model_for_generation(self.model, self.accelerator) as unwrapped_model:
prompt_completion_ids = unwrapped_model.generate(
prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config
)
prompt_length = prompt_ids.size(1)
prompt_ids = prompt_completion_ids[:, :prompt_length]
completion_ids = prompt_completion_ids[:, prompt_length:]
# 为每个生成结果重复prompt_mask (一个prompt生成多个completion)
prompt_mask = prompt_mask.repeat_interleave(self.num_generations, dim=0)
# 生成completion的掩码: 在第一个EOS token后截断
is_eos = completion_ids == self.processing_class.eos_token_id
eos_idx = torch.full((is_eos.size(),), is_eos.size(1), dtype=torch.long, device=device)
eos_idx[is_eos.any(dim=1)] = is_eos.int().argmax(dim=1)[is_eos.any(dim=1)]
sequence_indices = torch.arange(is_eos.size(1), device=device).expand(is_eos.size(0), -1)
completion_mask = (sequence_indices <= eos_idx.unsqueeze(1)).int()
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)
logits_to_keep = completion_ids.size(1)
# 使用参考模型计算log概率 (不计算梯度)
with torch.inference_mode():
ref_per_token_logps = self._get_per_token_logps(
self.ref_model, prompt_completion_ids, attention_mask, logits_to_keep
)
# 解码生成的文本并准备奖励计算
completions = self.processing_class.batch_decode(completion_ids, skip_special_tokens=True)
if is_conversational(inputs[0]):
completions = [[{"role": "assistant", "content": completion}] for completion in completions]
prompts = [prompt for prompt in prompts for _ in range(self.num_generations)]
rewards_per_func = torch.zeros(len(prompts), len(self.reward_funcs), device=device)
# 计算奖励值
for i, (reward_func, reward_processing_class) in enumerate(zip(self.reward_funcs, self.reward_processing_classes)):
if isinstance(reward_func, nn.Module):
if is_conversational(inputs[0]):
messages = [{"messages": p + c} for p, c in zip(prompts, completions)]
texts = [apply_chat_template(x, reward_processing_class)["text"] for x in messages]
else:
texts = [p + c for p, c in zip(prompts, completions)]
reward_inputs = reward_processing_class(
texts, return_tensors="pt", padding=True, padding_side="right", add_special_tokens=False
)
reward_inputs = super()._prepare_inputs(reward_inputs)
with torch.inference_mode():
rewards_per_func[:, i] = reward_func(**reward_inputs).logits[:, 0]
else:
# 处理自定义奖励函数
reward_kwargs = {key: [] for key in inputs[0].keys() if key not in ["prompt", "completion"]}
for key in reward_kwargs:
for example in inputs:
reward_kwargs[key].extend([example[key]] * self.num_generations)
output_reward_func = reward_func(prompts=prompts, completions=completions, **reward_kwargs)
rewards_per_func[:, i] = torch.tensor(output_reward_func, dtype=torch.float32, device=device)
# 汇总所有奖励并计算组内均值和标准差 (核心优势计算部分)
rewards = rewards_per_func.sum(dim=1)
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
# 标准化奖励以计算优势函数
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4) # 加小epsilon避免除零
return {
"prompt_ids": prompt_ids,
"prompt_mask": prompt_mask,
"completion_ids": completion_ids,
"completion_mask": completion_mask,
"ref_per_token_logps": ref_per_token_logps,
"advantages": advantages,
}


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)