中科院等团队5月最新论文 SegCompass!让多模态大模型“看得见”推理过程
想象一下,你对 AI 说:“帮我把桌上那个和盘子颜色一样、且离水槽最近的马克杯抠出来。”
以往的推理分割(Reasoning Segmentation)算法(比如经典的 LISA)虽然能听懂、能抠图,但它们就像一个黑盒:大模型一通脑补,直接吐出一个神秘的向量交给分割解码器,至于它到底有没有找对“盘子”、是不是卡在了“水槽”的判断上,人类完全无法追溯 。
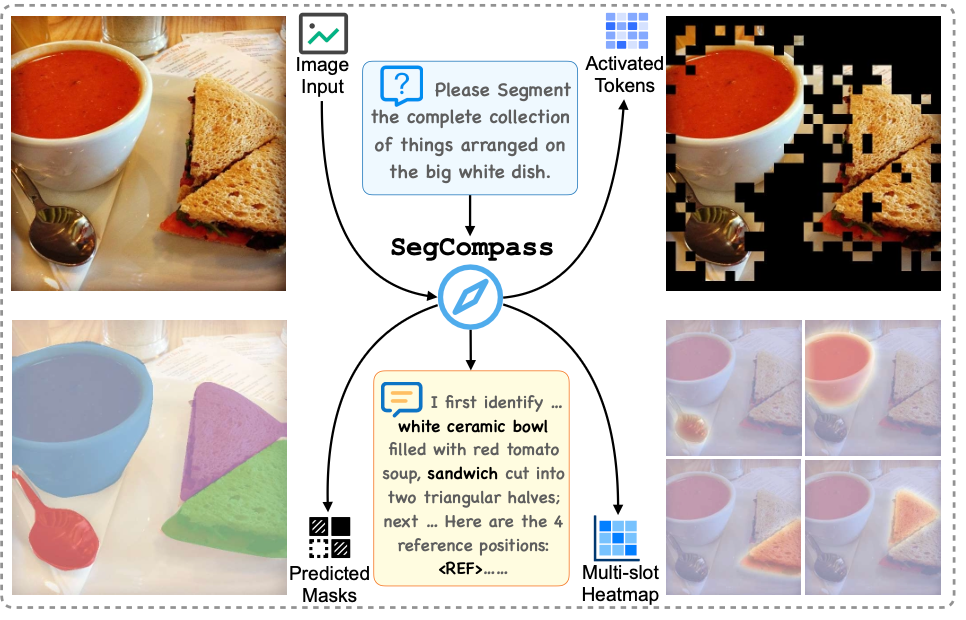
5月21日,来自中科院深圳先进院、鹏城实验室、哈工大(深圳)以及美团等机构的研究团队发表了全新成果:SegCompass(语义指南针) 。他们首次将大模型可解释性利器——稀疏自编码器(SAE, Sparse Autoencoder)引入了推理分割任务,不仅拿下了 5 大主流榜单的 SOTA(最高水平),更彻底终结了多模态大模型的“黑盒”时代,实现了解码过程的“全白盒级”可解释性 !
今天我们就用最通俗的语言,拆解这项硬核科技。
一、 传统流派的尴尬:“全盲”或“生硬的缝合”
在理清 SegCompass 之前,我们要先看明白之前社区里存在的两大“门派”:
隐式查询对齐派(Latent Query Alignment): 大模型理解完句子后,生成一个特殊的隐藏标记(比如 <SEG>),以此作为特征查询去对齐图片 。
痛点: 妥妥的“黑盒”。中间发生了什么?模型到底有没有真正理解“和盘子颜色一样的马克杯”?不知道。 debug 全靠猜 。
文本坐标读取派(Textual Localization Readout): 让大模型先做思维链(CoT)推理,直接在文本里输出边界框坐标(Box)或者区域索引,再把坐标喂给 SAM(Segment Anything)去抠图 。
痛点: 这是“伪可解释”。大模型嘴里说出的坐标和最终视觉分割经常对不上,文本里丰富的语义信息在变成干瘪的数字坐标时丢失殆尽,属于“生硬的后期缝合” 。
如何既保留端到端训练的强大性能,又能让人类一眼看清大模型的思维轨迹和视觉焦点的对齐过程?
二、 核心破局点:SAE 搭建的“高维白盒桥梁”
SegCompass 的解法极其惊艳。它请出了一位近两年在 LLM 机制可解释性(Mechanistic Interpretability)领域红透半边天的技术——稀疏自编码器(SAE) 。
SAE 的核心作用,是把大模型内部难以捉摸、混杂在一起的密集稠密向量,解耦(Disentangle)成人类看得懂的、成千上万个独立的“稀疏概念(Sparse Concepts)” 。
在 SegCompass 的世界里,整个流程被优雅地重构了 :
1. 脑补与聚焦(Reasoning)
当收到图像和指令时,多模态大模型(如 Qwen2.5-VL 或 LLaVA)首先在内部启动类似 DeepSeek-R1 的多模态思维链(MCoT),在 <think> 标签内进行深度推理,并生成多个“专注标记”(Concentration Tokens, e k e_k ek) 。
2. 概念解耦(Interpretable Alignment)
模型训练了一个巨大的 SAE(例如将 4096 维的大模型隐藏层,映射到 65536 维 的超完备稀疏空间) 。
在这个空间里,思维链里的文字和图像块(Tokens)全部被翻译成了清爽的“指数-激活值”对 。每一个维度都对应一个极其具体的概念(比如“第 543 维代表‘白色陶瓷碗’”,“第 1209 维代表‘番茄浓汤’”) 。因为是稀疏的,单次推理中只有极少数的概念原子会被触发 !
3. 查询密码本与槽映射(Query Codebook & Slot Mapper)
光有散落的概念还不够。SegCompass 设计了一个查询密码本(Query Codebook)和 Transformer 编码块,把被激发的稀疏概念聚合成 K s K_s Ks 个具体的概念表征(Concept Representations, r k r_k rk) 。
接着,这些概念表征与大模型的专注标记( e k e_k ek)融合,化身为一队“侦察兵”(Queries),去和图像特征做多头交叉注意力(Cross-Attention) 。
最性感的地方来了: 这一步会直接输出一个可观测的多槽热力图(Multi-slot Heatmap, H k \mathcal{H}_k Hk) !
比如,如果大模型想找“白色陶瓷碗里的番茄汤”,热力图里的第 1 个槽(Slot)就会在图像中白色碗的区域亮起;第 2 个槽就会在红色的汤上亮起 。每一个槽对应什么语义、定位在图像哪里,人类看得一清二楚 !
4. 白盒解码(Mask Decoder)
最后,这个高度清晰、带语义指向的热力图被喂给一个轻量级的掩码解码器(采用类似 SAM 的双向 Transformer 架构),从而生成极其精准的最终分割掩码 M ^ \hat{M} M^ 。
三、 极致的训练艺术:GRPO 强化学习 + 视觉监督
为了让这个复杂的通路完美运转,SegCompass 的训练采用了一种双轨并行的统一优化策略 :
语言路径(强化学习): 引入了 DeepSeek 同款的 GRPO(群体相对策略优化)算法 。大模型生成一组推理回答,通过正则匹配检查其思维链(CoT)的格式(给格式分),再根据分割出来的 Mask 质量给分割分,从而用强化学习不断压榨大模型的逻辑推理能力,逼它吐出最干净、逻辑最严密的隐藏特征 。
视觉路径(有监督学习): 图像掩码和热力图直接使用 Ground Truth(真实标签)进行 Dice Loss 和交叉熵损失监督,强行让热力图的“槽”聚焦到正确的像素区域 。
四、 战绩斐然:不仅能打,还死死拿捏了“证据”
光说不练假把式,论文在 RefCOCO、RefCOCO+、RefCOCOg、gRefCOCO(多目标挑战)以及 ReasonSeg(复杂推理分割)这 5 大硬核榜单上进行了疯狂横扫 。
在各种主流大模型底座下(Qwen2.5-VL-7B, LLaVA-1.5-7B/13B),SegCompass 几乎在所有指标上都把前人的黑盒模型按在地上摩擦 。例如在推理分割神榜 ReasonSeg 的零测试中,展现出了惊人的泛化性能 。更重要的是,它顶住了 Seg-Zero、SAM-R1 等同样基于 GRPO 训练的强劲对手的攻势,有力地证明了“因为理解得更通透、概念对齐得更准,所以分割得更好” 。
更震撼的,是它的“白盒自证”:
论文做了一项非常硬核的定量分析:稀疏自编码器(SAE)的重构质量,与最终的抠图准确率(cIoU)之间呈现出极其强烈的正相关性。 这就好比我们去考微积分,SegCompass 不仅拿了满分,还能向老师出示他密密麻麻、严丝合缝的草稿纸 。草稿纸上的推导(SAE 概念激发的质量)越漂亮,最后的得分(抠图精度)就越高 。它用铁一样的数据证明:我的高分不是蒙出来的,我是真的懂了 !
总结
SegCompass 的诞生,给当前一味追求“端到端黑盒更大、更强”的大模型社区敲响了一个优雅的警钟。
它告诉我们:利用稀疏自编码器(SAE),我们完全可以在不牺牲性能、甚至提升性能的前提下,把大模型隐秘的“潜意识向量”拆解成人类可读的“显式概念指南针” 。未来的具身智能机器人、自动驾驶视觉系统如果搭载了这样的“语义指南针”,当它做出一项决定或者抠出一个物体时,背后的每一步视觉逻辑都将被人类深度信任。
这样有含金量、兼具工程美感与科学可解释性的作品,开源社区已经迫不及待了!
论文传送门: arXiv:2605.22658
开源代码(已Star): https://github.com/ZhenyuLU-Heliodore/SegCompass
配合EasyReader“导读+思维导图”功能阅读,效率提升80%。立即体验EasyReader论文阅读

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)