NLP —— Transformers库使用
目录
一、概念
Transformers库 是由 2017年谷歌大脑团队论文提出的,在python中的Transformers库 是由Huggingface公式 提出、开发、维护。
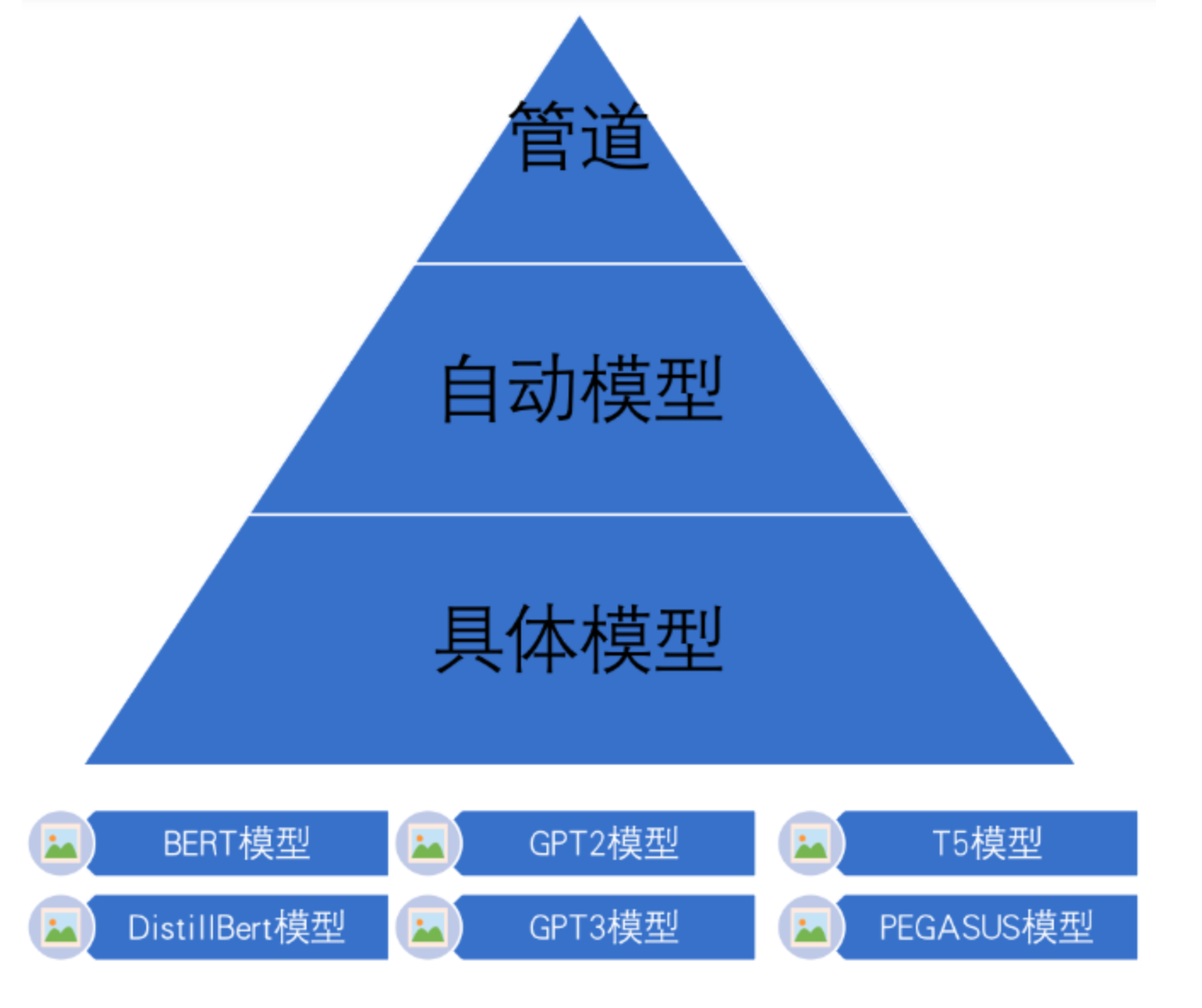
主要分为三层应用结构
1.管道(Pipline)方式:高度集成的极简使用,开箱即用。
2.自动模型(AutoMode)方式:可载入并使用BertTology系列模型
3.具体模型(SpecificModel)方式:在使用时,需要明确指定具体的模型,并安装对应模型中的特定参数进行微调调用,该方式相对复杂,但具有较高的灵活度。
二、管道方式(Pipline)
使用(例:文本分类)
model = pipeline(task="text-classification",model=r"本地模型路径")
# - 预测
pred_result = model("这家餐馆的卫生太差了,吃了拉稀,非常不推荐")
print(pred_result) # [{'label': 'star 5', 'score': 0.6314295530319214}]
API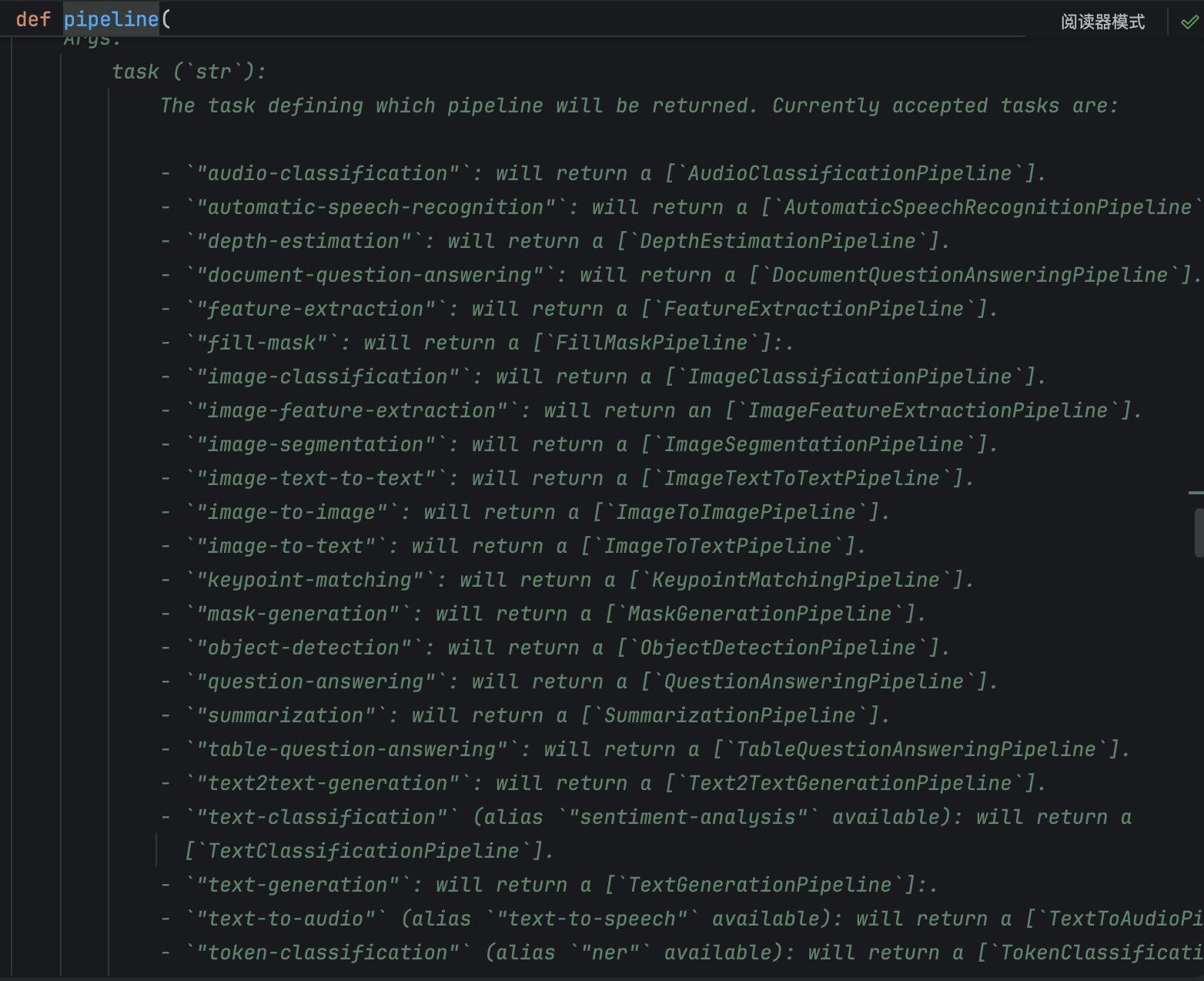
文本分类:text-classification 或者sentiment-analysis
特征抽取:feature-extraction
完形填空:fill-mask
阅读理解:question-answering
文本摘要:summarization
命名实体识别:ner
三、自动模型(AutoModel)
import torch
# 自动加载模型的配置文件
from transformers import AutoConfig
# 自动加载对应的模型
from transformers import AutoModel
# 自动加载模型词汇表,分词器
from transformers import AutoTokenizer
# 文本分类
from transformers import AutoModelForSequenceClassification
# 完型填空
from transformers import AutoModelForMaskedLM
# 阅读理解
from transformers import AutoModelForQuestionAnswering
# 文本摘要
from transformers import AutoModelForSeq2SeqLM
# NER命名实体识别
from transformers import AutoModelForTokenClassification例:文本分类
① 创建分词器,从预训练模型中创建得到分词器
my_tokenizer = AutoTokenizer.from_pretrained(“预训练模型路径”)② 创建模型对象:根据具体的业务需求,选择对应的类
my_model = AutoModelForSequenceClassification.from_pretrained(“预训练模型路径”)③ 准备数据
message = “xxxxxxx”
④ 文本分词并转为模型需要的数据类型,也就是张量
data_tensor = my_tokenizer.encode(text=message, return_tensors="pt", padding="max_length", truncation=True,max_length=10)
print(f"分词器处理后的结果:{data_tensor}, {type(data_tensor)}")⑤ 将处理后的数据输入到模型中得到结果
my_model.eval()
result = my_model(data_tensor)
print(f"运行结果:{result}, {type(result)}")
# 获得预测分类概率值最高的分类ID
print(result[0].argmax(dim=-1))例:特征抽取
model = AutoModel.from_pretrained("预训练模型路径")分词器用. encode_plus 比 encode 会返回更加丰富的信息
data_tensor = tokenizer.encode_plus(
text=sens,
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=30
)
"""
返回值解释:
1- input_ids:句子对应的词索引
2- token_type_ids:词索引来源于的句子索引。句子索引从0开始
3- attention_mask:注意力掩码。0表示不看input_ids对应位置的词索引;1反之
{
'input_ids': tensor([[ 101, 872, 3221, 6443, 102, 782, 4495, 6421, 1963, 862, 6629, 1928,
102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]])}调用模型
model.eval()
result = model(**data_tensor) # 对字典进行解包操作
print(result)
print("最后一个隐藏状态信息", result.last_hidden_state.shape)
print("池化层信息", result.pooler_output.shape)例:完形填空
model = AutoModelForMaskedLM.from_pretrained(“预训练模型路径”)准备数据
content = "我想明天去[MASK]家吃饭."数据处理
# 推荐:完型填空类的任务,不要设置padding、truncation此类的参数
data_tensor = tokenizer.encode_plus(
text=content,
return_tensors="pt"
)模型调用
model.eval()
result = model(**data_tensor)
print(f"result-->类型:{type(result)}")
print(f"result-->内容:{result}")
"""
结果形状是[1, 12, 21128],解释如下:
1- 1:上面传递给大模型的有1条句子
2- 12:上面传递给大模型的句子中,含句子开头、句子结尾、标点符号、[MASK]在内,总共有12个词
3- 21128:chinese-bert-wwm大模型的词汇表中有这么多个词
这里写[0][6]原因是,[MASK]所在的索引是6
"""
print(f"result中logits-->形状:{result.logits.shape}")
print(f"result中logits某个词-->形状:{result.logits[0][6].shape}")
print(f"result中logits某个词-->结果数据:{result.logits[0][6]}")
# 获得概率最高词的索引信息
pred_word_index = torch.argmax(result.logits[0][6]).item()
# 将概率最高词的索引转成能够识别的内容
pred_word_content = tokenizer.convert_ids_to_tokens(pred_word_index)
print(f"填充词的索引:{pred_word_index},对应的内容:{pred_word_content}") # 填充词的索引:1961,对应的内容:她例:阅读理解
question-answer,根据文本以及问题,从文本里面解答问题的答案
model = AutoModelForQuestionAnswering.from_pretrained(model_path)准备数据
context = '我叫张三 我是一个程序员 我的喜好是打篮球'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']模型调用
# 3- 对问题列表进行循环。每次让大模型回答一个问题。这是与pipeline的主要区别
for question in questions:
# 3.1- 数据处理
data_tensor = tokenizer.encode_plus(question,context,return_tensors="pt")
print(data_tensor)
# 3.2- 调用模型
model.eval()
result = model(**data_tensor)
# print(result)
# 3.3- 处理结果
# 获得答案中预测概率最高start开始索引
start_index = torch.argmax(result.start_logits).item()
# 获得答案中预测概率最高end结束索引
end_index = torch.argmax(result.end_logits).item() + 1
# 通过start和end,对context(因为问题的答案肯定存在于上下文中)上下文进行切片,得到答案
answer = tokenizer.convert_ids_to_tokens(data_tensor.input_ids[0][start_index:end_index])
print(f"问题是:{question},对应的答案:{answer}")例:文本摘要
model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
准备数据 文章 text = 一段话
# 3- 处理数据
data_tensor = tokenizer.encode_plus(text,return_tensors="pt")
# 4- 得到文本摘要:生成文本内容
model.eval()
result = model.generate(**data_tensor)
print(result) # 就是一个普通张量
# 5- 结果解析
# 5.1- 使用decode进行解码
decode_result_1 = [tokenizer.decode(word_index,skip_special_tokens=True,clean_up_tokenization_spaces=False) for word_index in result[0]]
print(f"decode处理后的结果:{' '.join(decode_result_1)}")
decode_result_2 = [tokenizer.decode(word_index,skip_special_tokens=False,clean_up_tokenization_spaces=False) for word_index in result[0]]
print(f"decode处理后的结果:{' '.join(decode_result_2)}")
# 5.2- 直接使用convert_ids_to_tokens
print("convert_ids_to_tokens处理后的结果:"," ".join(tokenizer.convert_ids_to_tokens(result[0],skip_special_tokens=True)))例:命名实体识别
多了一个config
model = AutoModelForTokenClassification.from_pretrained(model_path)
config = AutoConfig.from_pretrained(model_path) # 2- 准备数据
content = "鲁迅原名周树人,代表作有《朝花夕拾》,在外交部上班,今天他去故宫游览"
# 3- 数据处理
data_tensor = tokenizer.encode_plus(text=content,return_tensors="pt")
# 4- 调用
model.eval()
result = model(**data_tensor)
print(result)
"""
[1, 34, 32]形状解释
1- 1:上面有1条句子
2- 34:上面句子中,含开头、结尾、标点符号在内有34个词
3- 32:该模型支持的命名实体的种类有32。每种大模型支持的命名实体的种类不同
"""
# print(result.logits.shape) # 形状[1, 34, 32]
# 5- 结果解析
words = tokenizer.convert_ids_to_tokens(data_tensor.input_ids[0])
for word,prob_list in zip(words, result.logits[0]):
# 过滤掉特殊符号:例如句子的开始、结束
if word in tokenizer.all_special_tokens:
continue
# 1- 获得每个词对应的命名实体类别索引
ner_index = torch.argmax(prob_list).item()
# 2- 根据索引,获得命名实体的名称
ner_type_name = config.id2label.get(ner_index)
print(f"词:{word},命名实体类别索引:{ner_index},命名实体的名称:{ner_type_name}")四、具体模型方式
举例:以Bert模型为例,处理二分类问题
① 设置变量
<1> 设备
<2>加载字典和分词工具
<3>加载Bert模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device = torch.device("cpu") # 👈 就改这里,别用 mps
# 加载字典和分词工具
tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path='./model/bert-base-chinese')
# 这里导入模型要使用BearModel,而不是BertModelForSequenceClassification
# 因为,这里使用预训练模型进行特征提取,下游自己指定多分类输出层(线性层)
# 加载预训练模型 Bert模型
bert_model = BertModel.from_pretrained("./model/bert-base-chinese")
bert_model = bert_model.to(device) # 必须把 bert 也放到 device 上!②加载原始数据
def load_data():
# slpit 只能是train
data1 = load_dataset("csv", data_files='./data/train.csv')
#data1 -> DatasetDict({
# train: Dataset({
# features: ['label', 'text'],
# num_rows: 9600
# })
# })
data2 = load_dataset("csv", data_files='./data/train.csv', split='train')
# data2 -> Dataset({
# features: ['label', 'text'],
# num_rows: 9600
# })
print('data2 -> ',data2)
print('data2类型 -> ',type(data2))
return data2③ 数据二次处理
def collate_fn1(dataset):
"""
迭代器
对数据进行二次处理的函数,就是这一批次的数据,需要接受一个函数地址
# batch_size = 4. 一次处理4数据
:param dataset:
:return:
"""
sents = [i['text'] for i in dataset]
labels = [i['label'] for i in dataset]
print(sents,type(sents))
print(labels)
"""
batch_encode_plus 对一次batch的数据一次编码
要对文本数值化,文本张量化,对标签进行张量化
"""
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
padding='max_length',
max_length=300,
return_tensors='pt'
)
"""
data= {'input_ids':tensor(), 数据数值化,文本张量化后的结果
'token_type_ids':tensor(), 文本(句子)类型,0代表一个句子
'attention_mask':tensor()} 掩码 (1代表掩码(需要掩码) , 0代表填充的)
labels 标签张量化
"""
intput_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return (intput_ids,
attention_mask,
token_type_ids,
labels)④创建数据加载器
def load_dataLoader(dataset_train):
mydataloader = torch.utils.data.DataLoader(
dataset=dataset_train,
batch_size=4,
collate_fn=collate_fn1,
shuffle=True,
drop_last=True
)
# for intput_ids, attention_mask, token_type_ids, labels in mydataloader:
# print('intput_ids -> ',intput_ids)
# print('attention_mask -> ',attention_mask)
# print('token_type_ids -> ',token_type_ids)
# print('labels -> ',labels)
# break
return mydataloader⑤自己定义模型类
class MyModule(nn.Module):
def __init__(self):
super().__init__()
"""
因为用的是bert模型,维度768维度,输入是 768
处理的是二分类问题,所以输出维度是2
定义线性层。
"""
self.linear = nn.Linear(in_features=768, out_features=2)
def forward(self, input_ids, token_type_ids, attention_mask):
"""
先试用Bert模型进行特征提取
【可选】 冻结或者不冻结 torch.no_grad
如果效果不好,就不冻结
1- 推荐使用torch.no_grad(),冻结Bert的参数训练。可以不加,那么回对Bert的110M个参数都会进行训练,比较耗时
2- bert_model()里面的参数要使用关键字传参
"""
# with torch.no_grad():
out = bert_model(
input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask
)
"""
做分类任务 → 推荐用 pooler_output
做特征提取 → 用 last_hidden_state[:,0]
: = 取所有句子
0 = 取第 0 个位置(也就是 <[BOS_never_used_51bce0c785ca2f68081bfa7d91973934]>token)
out.last_hidden_state[:, 0] 最后一个时间步的隐藏状态 词向量
out.pooler_output 句向量
"""
#print('last_hidden_state -->>> ',out.last_hidden_state.shape) 【4, 300, 768】
#print('pooler_output -->>> ',out.pooler_output.shape) 【4, 768】
#output = self.linear(out.last_hidden_state[:, 0])
output = self.linear(out.pooler_output)
# print('output -->',output.shape)
# 然后把特征送给下游的自定义输出层线性层,实现二分类任务
return output⑥ 模型训练
<1>创建自定义模型
<2>可选冻结预训练模型梯度更新(不冻结 效果更好,耗时)
<3>创建优化器
<4>创建损失函数
<5>获取加载数据
<6>数据加载器处理数据
<7>训练
《1》 前向传播
《2》损失计算
《3》梯度清零
《4》反向传播
《5》梯度更新
《6》模型保存
def train_model():
# 5.1 创建模型
my_model = MyModule().to(device=device)
# #bert模型 预训练冻结梯度更新
# for param in bert_model.parameters():
# param.requires_grad_(False)
my_model.train()
# 5.2 创建优化器
my_optimizer = torch.optim.AdamW(my_model.parameters(), lr=5e-4)
# 5.3 创建损失函数
my_cross = nn.CrossEntropyLoss()
# 5.4 加载数据
my_data = load_data()
# 5.5 数据加载器
my_dataloader = load_dataLoader(my_data)
# 5.6 训练
#轮次
epochs = 1
for epoch in range(epochs):
"""
进度条 pip install tqdm
enumerate 序列化
"""
for i, (input_ids, token_type_ids, attention_mask, labels) in enumerate(tqdm(my_dataloader), start=1):
# <1> 模型前向传播
output = my_model(
input_ids=input_ids.to(device),
token_type_ids=token_type_ids.to(device),
attention_mask=attention_mask.to(device)
)
labels = labels.to(device)
# <2> 损失计算
# 预测值 与 真实值 计算损失
loss = my_cross(output, labels)
# <3> 梯度清零
my_optimizer.zero_grad()
# <4> 反向传播
loss.backward()
# <5> 梯度更新
my_optimizer.step()
# <6> 打印日志
if i % 5 == 0:
pred = torch.argmax(output, dim=-1)
accuracy = (pred == labels).sum().item() / len(labels)
print(f'训练轮次:{epoch+1}')
print(f'本轮损失值:{loss.item()}')
print(f'准确率:{accuracy}')
#模型保存
torch.save(my_model.state_dict(), f'./save_model/my_model_{epoch + 31}.pth')⑦模型评估
注意:with torch.no_grad(): # 测试必须加 no_grad
def test_model():
my_data = load_data()
my_dataloader = load_dataLoader(my_data)
my_model = MyModule()
my_model.load_state_dict(torch.load('./save_model/my_model_31.pth'))
my_model = my_model.to(device=device)
my_model.eval()
# 准备参数:total,accuracy
num = 0
total = 0
with torch.no_grad(): # 测试必须加 no_grad
for i, (input_ids, token_type_ids, attention_mask, labels) in enumerate(tqdm(my_dataloader), start=1):
# 预测值
output = my_model(
input_ids=input_ids.to(device),
token_type_ids=token_type_ids.to(device),
attention_mask=attention_mask.to(device)
)
labels = labels.to(device)
#真实值
y_pre = torch.argmax(output, dim=-1)
num += (y_pre == labels).sum().item()
total += len(labels)
print("准确率:accuracy-->", num/total*100)五、预训练模型使用总结:
1- pipeline管道:
优点:代码开发非常简单
缺点:底层高度封装,可调整的超参数少
使用:一般用来快速验证预训练模型/大模型是否满足业务需求
2- AutoModel自动模型:
优点:代码相对比较简单,有一定可以可调整的超参数
缺点:相对具体模型来说,可调整的超参数相对较少
3- 指定模型:
优点:可调整的超参数很多,能够针对具体的大模型进行指定参数的微调。每种大模型的可调整的参数都是不一样
缺点:比较灵活,不同的大模型可调整的参数有区别
使用:针对业务场景需要比较高的情况,推荐使用
后续:LoRA、QLoRA

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)