YOLO26最新创新改进系列:别再把深度学习当黑盒:一张图看懂 CNN 如何“看见”图像
YOLO26最新创新改进系列:别再把深度学习当黑盒:一张图看懂 CNN 如何“看见”图像
购买相关资料后畅享一对一答疑!
微信公众号:Ai计算机视觉
畅享超多免费持续更新且可大幅度提升文章档次的纯干货工具!
别再把深度学习当黑盒:一张图看懂 CNN 如何“看见”图像
从卷积的乘加运算,到 YOLO 的检测框输出,科研小白也能按步骤跑起来
整理说明:本文基于 B 站视频《一文读懂深度学习:超强可视化,深度学习再也不“黑盒”卷积神经网络的计算可视化!》的公开信息,并结合 CNN、YOLO、Grad-CAM 等基础知识进行原创化梳理。

很多同学第一次学深度学习,最容易卡在一句话上:
模型到底是怎么从一张图片里“看见”目标的?
如果只看公式,卷积神经网络像一团黑盒;如果只看代码,又容易变成“调包跑通但完全不懂”。正确的打开方式是:把图像在网络中的流动过程画出来。
这篇文章用最小必要知识讲清楚 3 件事:
- 图片进入 CNN 之后,到底发生了什么。
- 卷积层为什么能提取边缘、纹理、形状等特征。
- YOLO 这类目标检测网络,如何把特征变成检测框。
建议先收藏。后面配了学习路线、实操命令、代码片段和踩坑清单,适合科研新手照着做。
01 先把一句话记住:图片在模型里不是图片,而是数字
我们肉眼看到的是一张图,计算机看到的是一个三维数组:
| 维度 | 含义 | 例子 |
|---|---|---|
| H | 高度 | 640 |
| W | 宽度 | 640 |
| C | 通道数 | RGB 三通道 |
一张 640 x 640 的彩色图,进入模型前通常会变成 640 x 640 x 3 的数字张量。每个像素点的值表示颜色强度,模型并不知道“猫”“车”“细胞”“病灶”这些概念,它只能从数字模式里逐层学习。
所以深度学习不是魔法,它更像一个层层加工的流水线:
像素值 -> 边缘纹理 -> 局部形状 -> 目标部件 -> 类别或检测框

初学者只要理解这条线,后面的 CNN、YOLO、Grad-CAM 都会顺很多。
02 卷积到底在算什么?核心只有“乘加”
卷积层看起来复杂,本质是一个小窗口在图像上滑动。
每滑到一个位置,它会做 3 步:
- 取出窗口覆盖的一小块数字。
- 和卷积核里的权重逐项相乘。
- 把乘积全部加起来,得到输出特征图里的一个格子。
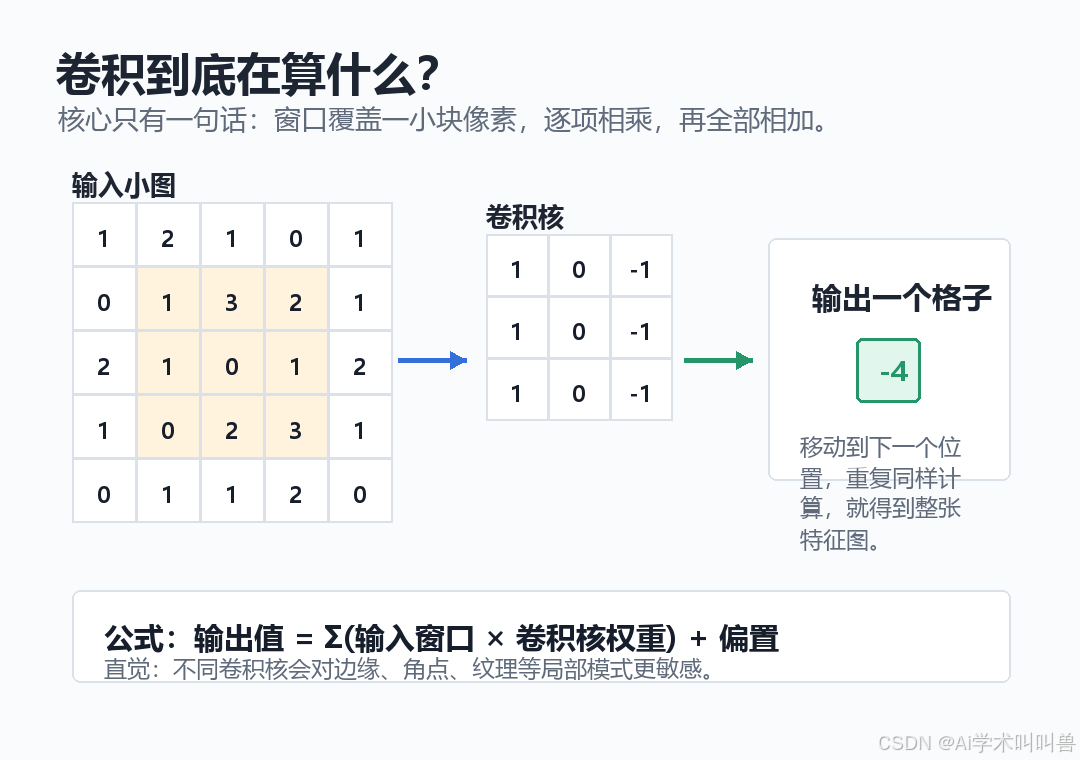
可以把卷积核理解成一个“特征探测器”:
| 卷积核偏好 | 更容易响应的内容 |
|---|---|
| 水平边缘核 | 横向边界、明暗变化 |
| 垂直边缘核 | 竖向边界、轮廓 |
| 纹理核 | 重复花纹、细密结构 |
| 深层组合特征 | 物体局部、目标部件 |
这里最重要的不是背公式,而是理解一个直觉:
卷积核不是一次看完整张图,而是反复观察局部区域。浅层先学边缘,后面再把边缘组合成纹理、形状和语义。
03 CNN 为什么越往后越“抽象”?
CNN 的每一层都在把上一层的输出重新加工。
浅层离原始像素近,所以更容易看到边缘、颜色、纹理;深层经过多次组合后,空间分辨率通常变小,但语义更强。
| 层级 | 常见变化 | 你应该怎么观察 |
|---|---|---|
| 输入层 | 原始像素 | 看图像尺寸、通道数、是否归一化 |
| 浅层卷积 | 边缘和方向 | 看 feature map 是否对轮廓有响应 |
| 中层结构 | 纹理和局部形状 | 看不同通道是否关注不同区域 |
| 深层语义 | 目标部件和类别线索 | 看热力图是否落在目标主体上 |
| 输出层 | 分类、检测、分割结果 | 看预测是否和任务目标一致 |
这就是“黑盒”可以被拆开的地方。
你不需要一开始就完全理解每个参数,只要先做到:
- 能打印每层输出尺寸。
- 能画出几层 feature map。
- 能看懂 Grad-CAM 热力图大概在关注哪里。
学深度学习,先让模型“可见”,再谈优化。
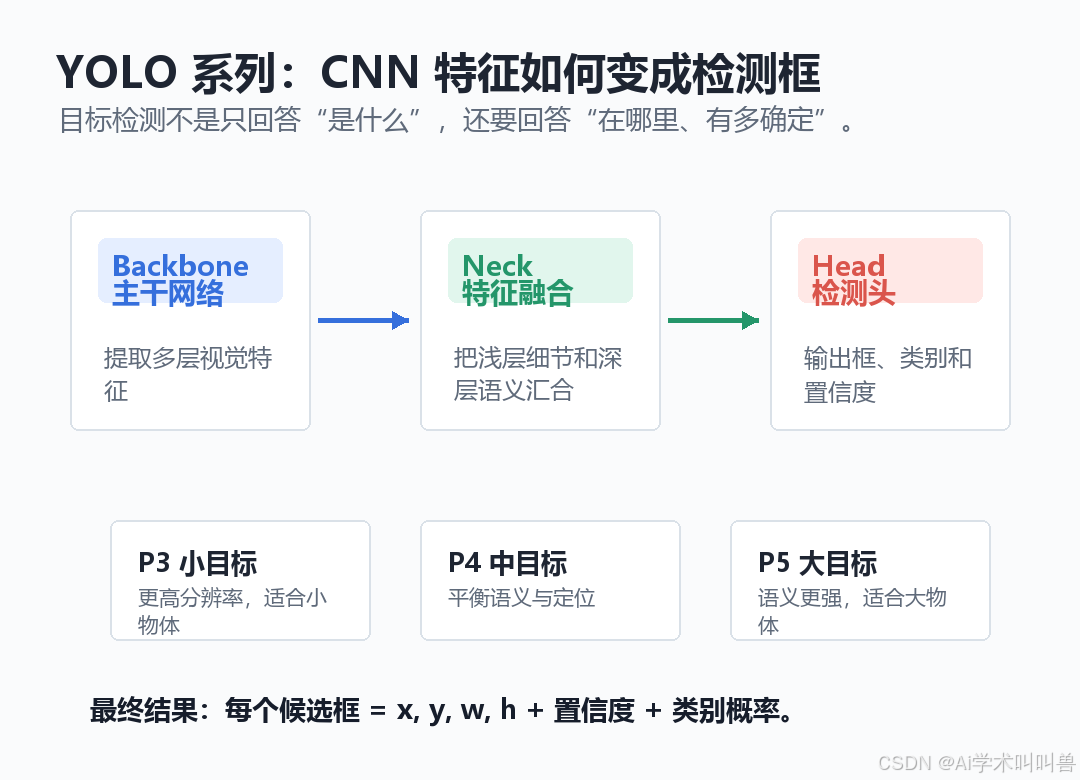
04 YOLO 做目标检测时,多做了哪一步?
普通分类模型回答的是:“这张图里是什么?”
YOLO 目标检测模型回答的是:“图里有哪些目标?它们在哪里?我有多确定?”
所以 YOLO 的输出通常包含:
| 输出项 | 含义 |
|---|---|
| x, y | 目标框中心点 |
| w, h | 目标框宽高 |
| confidence | 模型对目标存在的置信度 |
| class probability | 属于每个类别的概率 |

理解 YOLO,可以先抓住三个模块:
| 模块 | 作用 | 小白理解 |
|---|---|---|
| Backbone | 提取图像特征 | 先把图看懂 |
| Neck | 融合不同尺度特征 | 小目标、大目标信息汇合 |
| Head | 输出检测结果 | 给出框、类别、置信度 |
如果你正在看 YOLO 的 YAML 结构,常见格式是:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 3, C2f, [128, True]]
- [[-1, 2], 1, Concat, [1]]
- [[8], 1, Detect, [nc]]
这 4 个字段可以这样读:
| 字段 | 解释 |
|---|---|
| from | 输入来自哪一层,-1 代表上一层 |
| repeats | 模块重复几次 |
| module | 使用什么模块,比如 Conv、C2f、Concat、Detect |
| args | 模块参数,比如通道数、卷积核大小、步长 |
读 YOLO 网络结构时,不要一行一行硬背。先画数据流:上一层输出到哪里,哪些层被拼接,最后哪些尺度进入 Detect。
05 7 天学习路线:科研小白照着走
| 时间 | 学什么 | 交付物 |
|---|---|---|
| Day 1 | 图像张量、归一化、通道 | 能说清一张图进入模型后的形状 |
| Day 2 | 手算 3x3 卷积 | 算出一个输出格子 |
| Day 3 | feature map 可视化 | 截图保存浅层、中层、深层特征 |
| Day 4 | 训练一个小 CNN | 跑出 loss 曲线 |
| Day 5 | 分析错误样本 | 找出模型看错的典型情况 |
| Day 6 | 跑一次 YOLO 检测 | 得到带检测框的图片 |
| Day 7 | 做 Grad-CAM 热力图 | 判断模型是否关注目标主体 |
建议每天只做一件事。不要一开始就追求论文级创新,先让自己能独立复现实验流程。
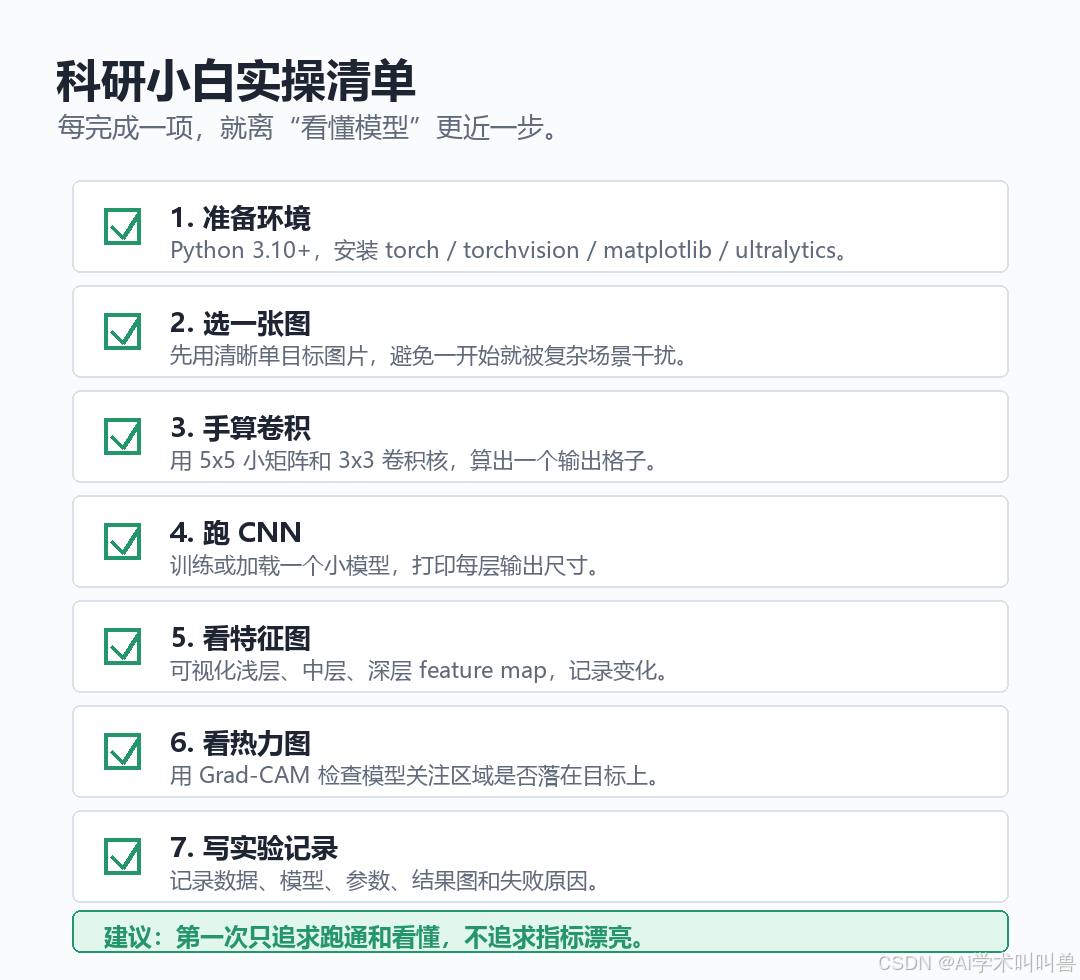
06 实操教程:从 0 跑通一个最小实验
下面的步骤适合 Windows、macOS、Linux。Windows 用户建议使用 Anaconda Prompt 或 PowerShell。
第一步:创建环境
conda create -n cnn-viz python=3.10 -y
conda activate cnn-viz
pip install torch torchvision matplotlib opencv-python ultralytics
如果下载慢,可以换国内镜像,或者先只安装 torch torchvision matplotlib,把 CNN 部分跑通。
第二步:手算一次卷积
新建文件 01_convolution_hand_calc.py,运行:
import numpy as np
image = np.array([
[1, 2, 1, 0, 1],
[0, 1, 3, 2, 1],
[2, 1, 0, 1, 2],
[1, 0, 2, 3, 1],
[0, 1, 1, 2, 0],
], dtype=float)
kernel = np.array([
[1, 0, -1],
[1, 0, -1],
[1, 0, -1],
], dtype=float)
patch = image[1:4, 1:4]
value = np.sum(patch * kernel)
print("输入窗口:")
print(patch)
print("卷积核:")
print(kernel)
print("逐项相乘:")
print(patch * kernel)
print("输出格子的值:", value)
你要观察的不是结果有多大,而是这条链路:
输入窗口 -> 权重相乘 -> 求和 -> 输出一个格子
这就是卷积层最基础的计算过程。
第三步:打印 CNN 每层输出尺寸
新建文件 02_print_cnn_feature_shapes.py:
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
x = torch.randn(1, 3, 224, 224)
for i, layer in enumerate(model):
x = layer(x)
print(i, layer.__class__.__name__, tuple(x.shape))
你会看到类似:
0 Conv2d (1, 16, 224, 224)
1 ReLU (1, 16, 224, 224)
2 MaxPool2d (1, 16, 112, 112)
3 Conv2d (1, 32, 112, 112)
4 ReLU (1, 32, 112, 112)
5 MaxPool2d (1, 32, 56, 56)
读法很简单:
通道数从 3 变 16,再变 32,说明模型提取的特征类型变多;空间尺寸从 224 变 112,再变 56,说明模型逐渐压缩空间信息,保留更抽象的模式。
第四步:跑一次 YOLO 检测
准备一张测试图片,比如 test.jpg。
新建文件 03_yolo_predict_quickstart.py:
from ultralytics import YOLO
# 如果你有视频配套或本地训练得到的权重,改成对应 .pt 路径。
model = YOLO("yolo26n.pt")
results = model("test.jpg", save=True, conf=0.25)
for r in results:
print("检测框数量:", len(r.boxes))
print("结果保存目录:", r.save_dir)
如果 yolo26n.pt 当前环境不可用,就把它替换成你本机已有的 Ultralytics 权重文件,例如 best.pt、last.pt,或官方可下载的轻量模型权重。
第一次跑通时,重点看 3 件事:
- 能不能正常加载权重。
- 输出图里有没有检测框。
- 置信度阈值
conf调高或调低后,检测结果如何变化。
07 看可视化结果时,重点看什么?
很多同学会把可视化图当“好看的配图”,但科研训练里更重要的是分析。
建议按下面的表格记录:
| 观察对象 | 正常现象 | 异常信号 |
|---|---|---|
| 浅层 feature map | 边缘、纹理有响应 | 全黑、全白、噪声极强 |
| 深层 feature map | 目标主体附近更明显 | 背景比目标更亮 |
| Grad-CAM | 热区落在目标区域 | 热区落在水印、边框、背景 |
| 检测框 | 框住主要目标 | 漏检、小目标偏移、重复框 |
| 训练曲线 | loss 逐渐下降 | loss 不动、剧烈震荡、验证集变差 |
如果热力图总是关注背景,不要急着换模型。先检查:
- 数据集是否有偏差,比如所有目标都出现在固定背景。
- 标注是否准确,框有没有偏移。
- 图片预处理是否一致,训练和推理尺寸是否匹配。
- 类别是否不平衡,某些类别样本太少。
这就是可视化的价值:不是为了证明模型很厉害,而是帮助你发现模型到底在哪里偷懒。
08 常见问题
1. 为什么卷积后图片变小了?
通常和 kernel_size、stride、padding 有关。步长越大,输出越小;padding 可以在边缘补零,让输出尺寸不至于缩太快。
2. 为什么通道数越来越多?
每个通道可以理解为一种特征响应。越往后,模型需要表达的模式越复杂,所以通道数通常会增加。
3. YOLO 的 Backbone、Neck、Head 必须死记吗?
不需要。先记功能:Backbone 提特征,Neck 融合多尺度,Head 输出框和类别。等你能看懂数据流,再去研究具体模块。
4. 可视化热力图亮的地方一定正确吗?
不一定。热力图只是解释工具,不能替代定量评估。要结合原图、预测结果、错误样本和指标一起看。
5. 科研新手应该先学 CNN 还是 Transformer?
如果你的方向涉及图像检测、分割、医学影像、遥感、工业缺陷,建议先把 CNN 和 YOLO 的基本流程学通。CNN 是理解视觉模型的重要地基。
09 一句话总结
深度学习并不是完全不可解释的黑盒。
把一张图片放进 CNN 后,它会经历:
像素输入 -> 卷积乘加 -> 特征图 -> 多层抽象 -> 任务输出
而可视化的意义,就是把这条路径重新摊开,让我们看见模型每一步在处理什么。
如果你是科研小白,别急着追新模型。先做到这 3 件事:
- 手算一次卷积。
- 打印每层特征尺寸。
- 用 YOLO 跑通一次检测,并用热力图分析结果。
能做到这一步,你已经从“调包使用者”迈向“能诊断模型的人”。
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,关注UP:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。
因为经历过所以更懂小白的痛苦!
因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!
微信公众号:Ai计算机视觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)