项目实训个人工作博客(六):智能体相关models的补充
最近这段时间,我主要在继续完善项目后端的model层。前面基础的增删改查相关模型已经基本完成了,这一阶段的重点就放在了智能体相关模型的整理、补充和统一上。
这篇博客主要记录一下我这一阶段具体做了什么,补了哪些模型,为什么要这样拆,以及目前这一部分做到什么程度了。
一、阶段任务
后端中智能体相关的模型系统性补齐,统一放到Code_public/backend/app/models这个目录下面。
前面做 CRUD 的时候,像用户、项目、文件、知识库、服务这些基础模型已经有了,但智能体这部分还不完整。所以这一阶段的工作,就是两件事:
- 把智能体相关的数据结构全部梳理清楚
- 把应该放在models层的内容补到 app/models 下面
二、主要补充模型
这次补的内容可以分成两类。
1. Pydantic模型
这类模型主要用于请求响应、数据约束、结构化对象表达。
2. TypedDict状态模型
这类模型主要用于智能体运行过程中的状态描述,比如:
- 当前任务状态
- 阅读计划
- 分析计划
- Graph 执行状态
- User Proxy 动作参数和动作结果
最后新增出来的模型文件主要有这些:
- knowledge_search.py
- agent_graph.py
- agent_knowledge.py
- agent_orchestrator.py
- agent_plan.py
- agent_read.py
- agent_file_analysis.py
- agent_h5ad.py
- agent_user_proxy.py
三、知识检索模型补充
这一块我单独拆成了 knowledge_search.py。主要补了下面几个模型:
- KnowledgeSearchRequest
- KnowledgeDocument
- KnowledgeSearchResult
- KnowledgeSearchResponse
检索文献/知识这一条链路本身也需要有独立模型。
from __future__ import annotations
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, ConfigDict, Field
class KnowledgeSearchRequest(BaseModel):
query: str = Field(..., min_length=1)
project_id: str = Field(..., alias="projectId")
top_k: int = Field(20, ge=1, le=100, alias="topK")
rewrite: bool = Field(True)
sources: Optional[List[str]] = Field(None)
trace: bool = Field(False)
model_config = ConfigDict(populate_by_name=True, extra="ignore")知识检索模型关系图如下:

四、Graph 状态模型整理
智能体这部分有一个很重要的问题,就是运行中会有很多状态对象,如果这些状态对象没有统一定义,后面代码会越来越乱。所以我把这类通用状态结构拆到了agent_graph.py里,主要包括:
- MessageDict
- ContextFile
- PlannerTask
- PlannerTodo
- KnowledgeQuery
- KnowledgeDocument
- KnowledgeResult
- GraphState
- InitialStateContext
- InitialStatePayload
- StateUpdate
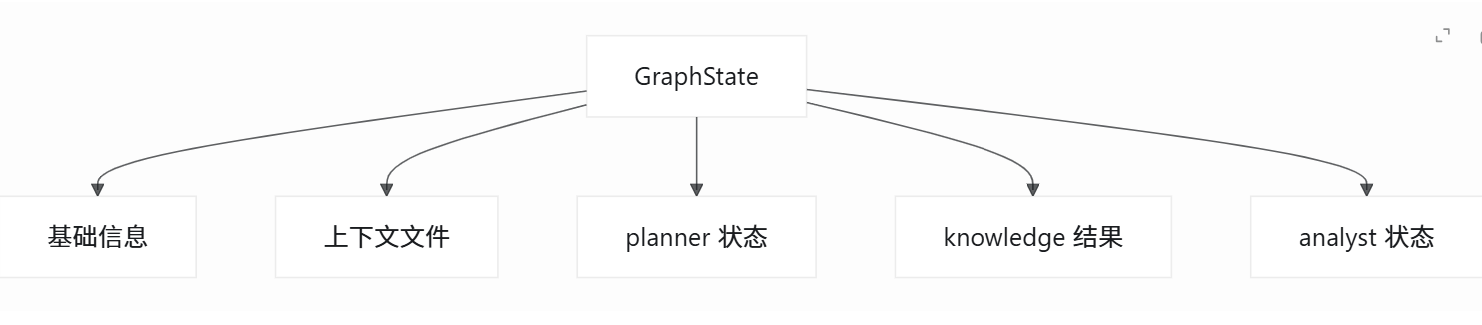
class GraphState(TypedDict, total=False):
job_id: str
user_id: str
project_id: str
user_message: str
conversation_history: list[MessageDict]
selected_file_id: NotRequired[str]
context_files: list[ContextFile]
planner_todos: NotRequired[list[PlannerTodo]]
final_answer: NotRequired[str]
next_task_type: NotRequired[Literal["knowledge", "analyst", "done"]]
knowledge_results: list[KnowledgeResult]这个部分整理完以后,后面如果继续写 Graph 工作流相关逻辑,就不需要再临时拼字典了,直接围绕统一状态定义来做就行。
GraphState 字段结构示意图
五、专项 Agent 模型拆分
除了通用 Graph 状态,我这次还把几个专项 Agent 的结构定义分别拆出来了。
1. agent_knowledge.py
这一部分主要放和知识解释、知识检索相关的状态:
- ReadingPlan
- KnowledgeAgentState
- KnowledgeInterpretationState
其中 KnowledgeInterpretationState 也顺便从原来 agent 子目录里的 state.py 挪到了 models 层里。
class KnowledgeInterpretationState(TypedDict, total=False):
project_id: str
user_id: str
user_query: str
project_knowledge: List[Dict[str, Any]]
project_documents: List[Dict[str, Any]]
public_documents: List[Dict[str, Any]]
evidence_lines: List[str]
final_answer: str这块做完以后,knowledge_interpretation_agent 的状态定义就和模型层统一了,不再继续散在 service 子目录中。
2. agent_plan.py
这一部分主要是计划相关模型:
- MessageDict
- Plan
- PlanAgentState
PlanAgentState 里面包括:
- 用户问题
- 项目 ID
- 上下文文件
- 执行历史
- 下一步计划
- 循环控制字段
这个文件整理完后,Plan Agent 这条链的结构已经比较清楚了。
3. agent_read.py
这个文件相对内容多一点,因为阅读相关状态比较细。主要包括:
- FileInfo
- PlanHistory
- ReadAgentState
- FileTreeNodeBase
- FileTreeNode
- GeneratedFileEntry
- ReadPlan
- AnalysisPlan
- FilesDeepReadPlanHistory
- FilesDeepReadAgentState
这里我没有强行把普通 read agent和deep read agent的结构合并成一个,因为它们虽然都和读文件这个功能有关,但语义并不完全一样。
class FileTreeNode(FileTreeNodeBase, total=False):
file_name: str
file_path: str
description: str
preview: str
from_agent: str
children: list["FileTreeNode"]class FilesDeepReadAgentState(TypedDict, total=False):
user_query: str
file_tree_list: list[FileTreeNode]
language: NotRequired[str]
analysis_plans: list[AnalysisPlan]
history_plans: list[FilesDeepReadPlanHistory]
read_plan: ReadPlan
generated_files_info: list[GeneratedFileEntry]
work_dir_path: str
final_answer: NotRequired[str | None]阅读 Agent 状态流转图
4. agent_file_analysis.py
这里主要补的是文件分析 Agent 的状态模型:
- GeneratedFileInfo
- SubAgentInfo
- FileAnalysisAgentState
这块的重点是要把子Agent的输入输出结构写清楚,而不是只用dict。
class SubAgentInfo(TypedDict, total=False):
name: str
prompt: str
expected_output: str
expected_files: list[GeneratedFileInfo]这类定义做完以后,后面看文件分析这块代码时就会清楚很多。
5. agent_h5ad.py
这个文件主要补了 H5ADAgentState。字段包括:
- 用户查询
- h5ad 文件路径
- 文件预览
- 解析后的 intent / params
- 生成代码
- 执行结果
- 结构化结果
- 最终回答
- 是否需要重试
- 错误信息
这一块虽然现在看起来只是一个状态模型,但它实际上把H5AD Agent的完整执行过程给描述出来了。
6. agent_user_proxy.py
这个文件主要整理了用户代理式交互中的动作参数和动作结果:
- ExecuteServiceParameter
- ReadFilesParameter
- QueryKnowledgeParameter
- ExecuteServiceResponse
- ReadFilesResponse
- QueryKnowledgeResponse
- AnswerQuestionResponse
- ActionResponse
- UserProxyState
这部分补完之后,用户代理式决策链条里面“动作长什么样、返回什么结构”就清楚了。
User Proxy 动作结构图

六、models层目前状态
做到这里,后端models层与智能体相关的内容已经基本收口了。现在模型层里已经覆盖了:
- 智能体会话与任务
- 知识检索请求响应
- Graph 通用状态
- Knowledge Agent 状态
- Plan Agent 状态
- Read Agent 状态
- File Analysis Agent 状态
- H5AD Agent 状态
- User Proxy 状态
七、阶段总结与完成情况
智能体相关代码和普通业务代码不太一样,它在运行过程中会产生很多中间状态。如果这些状态一直是散的、临时的、靠约定传递的,那么后面越写越容易乱。所以这个阶段的工作耗时比较长,完成得比较慢。
这一阶段我完成的内容可以简单总结成下面这几条:
- 梳理了当前后端已有模型结构
- 补齐了知识检索相关 Pydantic 模型
- 补齐了智能体相关 TypedDict 状态模型
- 按板块拆成多个独立模型文件
目前来看,后端 model 层里智能体相关部分已经基本完成收尾。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)