第004期精读:7 种噪声 × 54 种场景,Mega-ASR 专治“实验室好用、现实崩溃“的 ASR
Speech AI · FRONTIER — 第 004 期精读
Mega-ASR:用 2.4M 复合噪声数据 + 双粒度强化学习,把 SOTA 的崩溃场景打下来
📄 原文:Mega-ASR: Towards In-the-wild² Speech Recognition via Scaling up Real-world Acoustic Simulation
👥 作者:Zhifei Xie, Kaiyu Pang, Haobin Zhang, Deheng Ye, Xiaobin Hu, Shuicheng Yan, Chunyan Miao
📅 日期:2026-05-19 | 🏷️ 来源:arXiv 2605.19833 | 💻 代码:github.com/xzf-thu/Mega-ASR
📌 一句话总结
构建覆盖 7 类原子声学效应 × 54 种复合场景的大规模仿真数据集,配合两阶段专属训练策略(课程式 SFT + 双粒度 WER 门控强化学习),让 1.7B 规模的 ASR 模型在真实极端噪声场景下相对错误率降低 30%+。
🤔 这篇论文要解决什么问题?
痛点一:真实环境的声学崩溃问题。 现有 SOTA ASR 模型(Whisper、Qwen3-ASR、Gemini)在标准 benchmark 上表现亮眼,但一旦遭遇真实世界的极端噪声——同时叠加远场 + 回声 + 传输丢包——WER 会急剧劣化,甚至产生大量幻觉、空输出或关键词丢失。这类"in-the-wild"场景在实际部署中无处不在,却几乎没有系统性的解决方案。
痛点二:训练数据的覆盖盲区。 现有的鲁棒 ASR 数据集(CHiME、NOIZEUS、VOiCES)往往只覆盖单一噪声类型或单一场景,规模有限(千级别)。而现实中的声学退化是多种效应的复合叠加,单一数据集无法驱动模型学到泛化的鲁棒能力。
痛点三:高 WER 场景下的训练耦合瓶颈。 对于严重退化的语音(WER > 50%),声学提取和语义恢复是两个相互耦合的难题——直接端到端训练时,模型难以同时学好两者,往往顾此失彼。传统 SFT 的随机混合训练无法解决这一课程式学习需求。
论文的切入点是:系统性地从数据、训练策略、推理路由三个维度同时攻克上述问题,而非修补某一个环节。
🏗️ 核心方法
整体架构

▲ Voices-in-the-Wild-2M 数据集架构详解:
图中展示了数据集的生成逻辑:从左侧 7 种原子声学效应(Noise 噪声、Far-field 远场、Obstruction 阻挡、Echo & Reverb 回声混响、Recording Artifact 录制失真、Electronic Distortion 电子失真、Transmission Dropout 传输丢包)出发,通过"anchor–modifier composition"的组合机制,扩展为 54 种物理合理的复合场景。每种复合场景的严重程度采用线性分布采样,同时设置 WER > 70% 的样本丢弃阈值以保证训练稳定性。最终生成 2.4M 条合成样本,基础模型(Qwen3-ASR-1.7B)在该数据上的平均 WER 为 35%,覆盖了从轻度到重度的全谱退化分布。与已有数据集对比,Voices-in-the-Wild-2M 是目前唯一同时覆盖全部 7 类声学效应且达到百万规模的数据集。
关键技术点
技术点一:Acoustic-to-Semantic Progressive SFT(A2S-SFT)
是什么
三阶段渐进式监督微调策略,专门针对高 WER 场景的"声学提取与语义恢复解耦"问题设计。
| 阶段 | 训练对象 | 数据筛选 | 学习率 |
|---|---|---|---|
| 阶段一 | 编码器 + 适配器 | WER < 30% → < 50% → < 70%(课程递进) | 1×10⁻³ |
| 阶段二 | LLM 部分 | WER < 70% 全量 | 2×10⁻⁵ |
| 阶段三 | 编码器 + 适配器 + LLM 联合 | WER < 70% 全量 | 2×10⁻⁶ |
为什么有效
阶段一让编码器先在"相对干净"的数据上学会声学特征提取,逐步适应更高噪声;阶段二单独激活 LLM 的语义恢复能力(从不可靠的声学证据中推断语义);阶段三才做端到端对齐,避免梯度冲突。这种"分而治之"的思路与人类学习过程类似——先学发音,再学语义,最后整合。
与已有方法的区别
传统 SFT 将所有难度数据混合训练;此前鲁棒 ASR 工作通常只做数据增强而不调整训练课程。A2S-SFT 是首次将 WER 阈值显式作为课程控制信号应用于声学 LLM 训练。
技术点二:Dual-Granularity WER-Gated Policy Optimization(DG-WGPO)
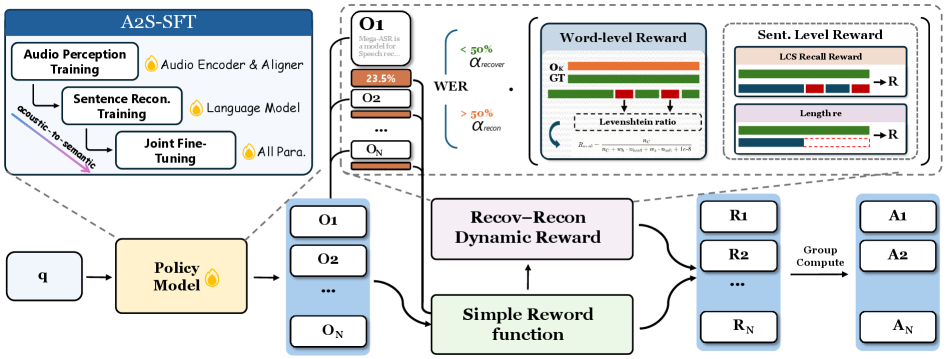
▲ DG-WGPO 框架详解:
图中展示了从 A2S-SFT 初始化出发,策略模型生成多条候选假设,由动态奖励函数打分并更新策略的完整 RL 流程。奖励设计分两个粒度:左侧 Token 级精化奖励(R_token) 基于编辑距离计算每个 token 的相似度,sim ≥ 0.5 为软错误(折扣较小),sim < 0.5 为硬错误(折扣较大),同时加入重复惩罚项;右侧 句子级重建奖励(R_sent) 基于最长公共子序列(LCS)衡量结构完整性,两部分等权融合。核心创新在于中间的 WER 门控融合机制:当假设的 WER < 0.3(相对容易,词级错误为主)时,75% 权重分配给 token 级奖励;当 WER ≥ 0.3(严重退化,语义崩溃为主)时,75% 权重转向句子级奖励。最终 R = (1 - α_dyn) × R_simple + α_dyn × R_dynamic,α_dyn = 0.6。论文验证了该规则奖励与 LLM judge 的结果高度一致,且计算成本降低 3.2×。
为什么有效
不同 WER 水平对应不同的错误模式——低 WER 时主要是词级替换,token 精细化更有效;高 WER 时出现幻觉/大段丢失,需要句子级结构约束。单一粒度奖励无法适配全谱错误分布,门控机制实现了自适应切换。
技术点三:Environment-Aware Routing(环境感知路由)
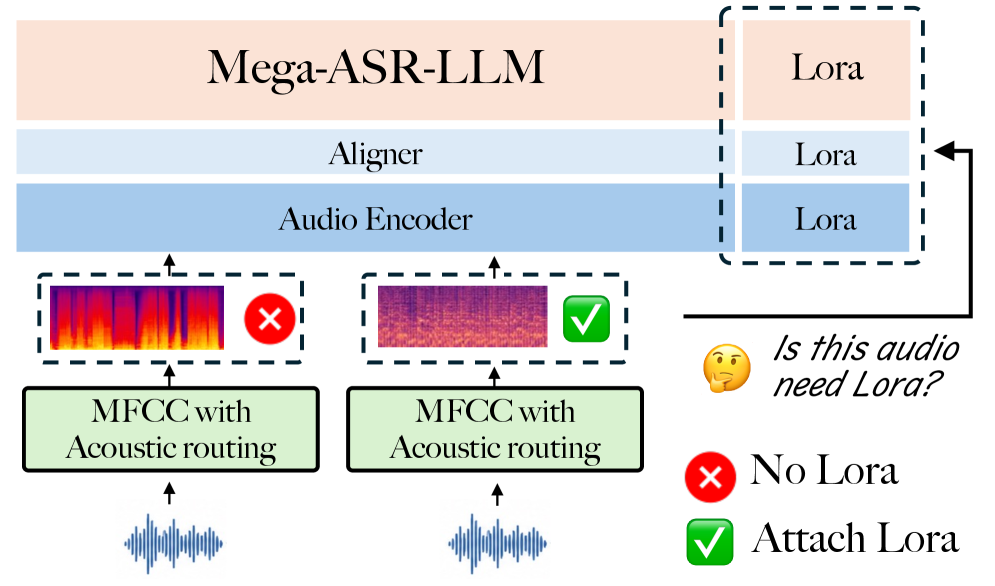
▲ 环境感知路由详解:
图中展示了一个轻量级二分类器(基于 LoRA 实现),在推理阶段对输入语音进行环境检测:若判断为干净语音,直接使用原始 Qwen3-ASR-1.7B backbone;若检测到噪声/退化环境,激活经过 Mega-ASR 训练的鲁棒权重分支。该路由器在干净语音和 Voices-in-the-Wild 样本的混合数据上训练,作为即插即用(plug-and-play)模块附加到主干模型上。这一设计的关键价值在于:鲁棒性训练往往以干净语音性能略有下降为代价,路由器通过条件激活避免了这一 trade-off。
📊 实验结果
Robust Benchmark 全面对比(CHiME-4 / VOiCES / NOIZEUS)
| 模型 | CHiME-4 Avg WER | VOiCES Avg WER | NOIZEUS Avg WER | Overall Avg |
|---|---|---|---|---|
| Whisper-Large-v3 | — | — | — | — |
| Qwen3-ASR-1.7B | 5.39 | 8.47 | 9.45 | 7.93 |
| Mega-ASR | 5.23 | 6.61 | 7.52 | 6.70 |
📌 整体平均 WER 从 7.93% 降至 6.70%,在 VOiCES 和 NOIZEUS 两个最难 benchmark 上提升最为显著。
极端噪声场景(VOiCES R4-B-F 和 NOIZEUS 0dB)
| 模型 | VOiCES R4-B-F WER | NOIZEUS 0dB WER |
|---|---|---|
| Gemini-3-Flash | — | ~56% |
| Qwen3-ASR-1.7B | 54.01% | 23.97% |
| Mega-ASR | 45.69% | 19.80% |
📌 在 NOIZEUS 0dB(极低信噪比)场景,Mega-ASR 比 Gemini-3-Flash 好 64.5%,比 Qwen3-ASR 基线相对降低约 17.4%。
Voices-in-the-Wild-Bench(论文自建 Benchmark)
| 模型 | Mixed Real WER | Mixed Sim WER |
|---|---|---|
| Whisper-Large-v3 | 8.91% | 14.79% |
| Qwen3-ASR-1.7B | — | — |
| Mega-ASR | 2.73% | 4.57% |
📌 相比 Whisper-Large-v3,Real 场景相对提升 69.4%,Sim 场景相对提升 69.1%。论文声称相对提升 65.8%。
标准 ASR 性能(干净语音,验证无退化)
| 模型 | LibriSpeech test-clean | LibriSpeech test-other | AISHELL-1 | WenetSpeech |
|---|---|---|---|---|
| Qwen3-ASR-1.7B | 1.62 | 3.40 | 3.19 | 5.80 |
| Mega-ASR w/ router | 1.63 | 3.37 | 3.17 | 5.89 |
📌 干净语音性能几乎无损失(±0.01~0.09%),路由器成功隔离了鲁棒性训练对干净场景的影响。
消融实验亮点
A2S-SFT 的贡献:相比直接全量 SFT,Voices WER 从 8.94% 降至 7.59%,Noizeus WER 从 9.45% 降至 8.12%,课程式渐进训练带来约 15% 的相对提升。
DG-WGPO 的增量贡献:在 A2S-SFT 基础上,Voices WER 进一步从 7.59% 降至 7.35%,Noizeus WER 从 8.12% 降至 7.64%,强化学习阶段提供稳定的额外收益。
规则奖励 vs LLM Judge:规则奖励与 LLM judge 结果高度一致,计算成本降低 3.2×,在大规模 RL 训练中具有显著的工程优势。
💡 个人点评
优势——系统性闭环,三个维度同时攻克。 这篇论文最大的价值在于系统性——数据、训练、推理三个环节全部重新设计,缺一不可,整体方案形成了完整的技术闭环。7×54 的场景矩阵思路非常值得借鉴,任何垂直领域的鲁棒 ASR 都可以用类似的"原子效应 × 复合场景"框架构建数据。
局限——单一基座,自建 benchmark 有泄露风险。 论文的实验全部基于 Qwen3-ASR-1.7B,未验证方法对其他架构(Whisper、Parakeet 等)的迁移性。另外 Voices-in-the-Wild-Bench 是作者自建 benchmark,独立评估时需注意数据泄露风险。DG-WGPO 的 τ=0.3 阈值是否需要对不同语种/领域重新调参,论文未讨论。
工程价值——数据框架和路由模块可直接迁移。 对于工业落地,最直接可用的是两点:一是 Voices-in-the-Wild-2M 的数据构建框架,可以低成本迁移到医疗、呼叫中心等垂直领域;二是环境感知路由的即插即用设计,能在不牺牲干净语音性能的前提下叠加鲁棒能力,对已有 ASR 系统升级友好。
未来方向——自适应门控与跨语种鲁棒性。 WER 门控的阈值 τ 目前是固定的,后续可以探索自适应阈值学习;7 种原子效应的覆盖面还可以扩展到语音压缩编解码(如 opus、aac 低码率失真)等数字传输场景;跨语种(中英混合、方言)的鲁棒性是下一个值得攻克的目标。
🔗 资源链接
- 📄 论文链接:https://arxiv.org/abs/2605.19833
- 💻 GitHub:https://github.com/xzf-thu/Mega-ASR
- 🌐 项目主页:https://xzf-thu.github.io/Mega-ASR/
- 相关论文推荐:
- Qwen3-ASR:https://arxiv.org/abs/2505.09627(本文基础模型)
- Robust ASR with WavLM:https://arxiv.org/abs/2110.13900
- CHiME-6 Challenge:https://arxiv.org/abs/2004.09249
Speech AI · FRONTIER · 论文精读系列
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文解读与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)