yolov10卷积层改进:动态卷积:DynamicConv(替换softmax),在C2fCIB和P4层Bottleneck结构中嵌入动态卷积
一、简介
传统卷积始终使用固定的特征提取模板,不管图像里目标大小、形态和场景怎么变化,都用同一套规则提取特征,适配能力很差;动态卷积应运而生,它提前准备多套不同的卷积模板,能根据每张图像的自身特点自动调配、组合出专属的特征提取模板,不再机械套用固定参数,小幅度增加推理参数,几乎不影响推理速度,性价比高,让网络可以灵活适配各种复杂场景、大小不一以及有遮挡的目标
二、实现原理
- 预先初始化多个独立专家卷积核;
- 对单张输入特征,通过路由 / 注意力分支生成样本专属归一化权重;
- 用权重加权融合所有专家核,生成当前输入专属的动态卷积核;
- 用自适应后的专属卷积核完成卷积计算,做到一样本一内核。
三、复现代码
地址:https://github.com/kaijieshi7/Dynamic-convolution-Pytorch/blob/master/dynamic_conv.py
为了即插即用,源代码中Softmax 函数需要配合退火机制,这里将Softmax 函数改为Sigmoid
1. Softmax 路由与温度参数
给定输入特征图,注意力网络输出一个![]() 维原始分数向量
维原始分数向量![]() ,每个元素对应一个专家卷积核。Softmax 路由将其转化为专家混合权重:
,每个元素对应一个专家卷积核。Softmax 路由将其转化为专家混合权重:
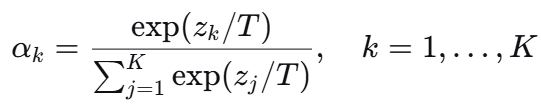
其中![]() 称为温度。
称为温度。
-
当
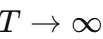 时,
时,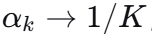 ,权重趋于均匀分布,所有专家平等参与。
,权重趋于均匀分布,所有专家平等参与。 -
当
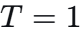 时,为标准 Softmax,分布由
时,为标准 Softmax,分布由  决定,可能极度尖锐(某个
决定,可能极度尖锐(某个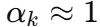 ,其余接近 0)。
,其余接近 0)。 -
当
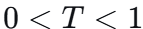 时,Softmax 变得更“硬”,分布更加集中。
时,Softmax 变得更“硬”,分布更加集中。
最终卷积核为各专家的加权组合:
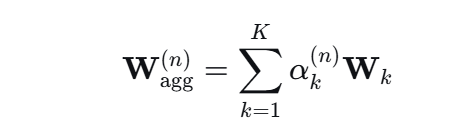
并用这个样本专属核进行卷积。
2. 温度退火的作用
训练初期,若直接使用 T=1,Softmax 的互斥性(![]() )容易使模型快速偏向某一个专家,其余专家接收到的梯度极小,导致专家退化——多个专家未能充分学习,动态卷积退化为近乎静态卷积。
)容易使模型快速偏向某一个专家,其余专家接收到的梯度极小,导致专家退化——多个专家未能充分学习,动态卷积退化为近乎静态卷积。
温度退火策略令 T 随训练进程从高逐步降低(例如初始 T=34,每若干步减小一个常数直至 T=1)。
-
高温阶段(T 大):
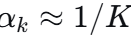 ,所有专家几乎均匀地被更新,保证了充分的“探索”,每个专家都能学习到有意义的特征。
,所有专家几乎均匀地被更新,保证了充分的“探索”,每个专家都能学习到有意义的特征。 -
降温阶段:随着 T 下降,分布逐渐锐化,模型开始“利用”更适合当前样本的专家,注意力集中到少数相关核上,提升判别力。
-
最终低温(T=1):模型在充分训练的基础上进行精细的专家选择,达到最优性能。
从优化角度看,退火相当于在损失面上先进行平滑(高温使梯度信号均匀分散),再逐渐恢复锐利度,稳定训练并避免过早收敛到局部极值。
3.函数替换为逐元素 Sigmoid:
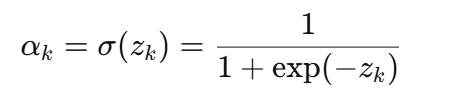
性质发生了根本变化:
-
非互斥性:不同
 之间相互独立,可以同时接近 1 或同时接近 0,不再强制总和为 1。
之间相互独立,可以同时接近 1 或同时接近 0,不再强制总和为 1。 -
天然软激活:Sigmoid 的输出始终是平滑的、软饱和的,即使某个专家激活值很高,其他专家依然可以同时保持中等或较高激活。这避免了 Softmax 那种“赢者通吃”导致的梯度稀疏问题。
因此,Sigmoid 路由器天然具备持续多专家协同学习的能力,无需通过外部温度调节来平衡探索与利用。训练全程只需使用标准 Sigmoid,简单且鲁棒。
class attention2d(nn.Module):
def __init__(self, in_planes, ratios, K, init_weight=True):
super(attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
if in_planes != 3:
hidden_planes = int(in_planes * ratios) + 1
else:
hidden_planes = K
self.fc1 = nn.Conv2d(in_planes, hidden_planes, 1, bias=False)
self.fc2 = nn.Conv2d(hidden_planes, K, 1, bias=True)
if init_weight:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return torch.sigmoid(x) # 替换为 Sigmoid,每个专家独立激活,无需温度/退火
class Dynamic_conv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size=1, ratio=0.25, stride=1, padding=None,
dilation=1, groups=1, bias=True, K=4, init_weight=True):
super(Dynamic_conv2d, self).__init__()
assert in_planes % groups == 0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
# 自动计算 padding,保持输出尺寸不变
self.padding = autopad(kernel_size, padding) if padding is None else padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = attention2d(in_planes, ratio, K) # 不再需要 temperature 参数
self.weight = nn.Parameter(
torch.randn(K, out_planes, in_planes // groups, kernel_size, kernel_size),
requires_grad=True
)
if bias:
self.bias = nn.Parameter(torch.zeros(K, out_planes))
else:
self.bias = None
if init_weight:
self._initialize_weights()
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
# 移除 update_temperature 方法,不再需要
def forward(self, x):
routing_weights = self.attention(x) # [B, K],sigmoid 输出
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width) # 合并 batch 和通道
weight = self.weight.view(self.K, -1) # [K, out*in_per_group*kernel*kernel]
# 为每个样本聚合出专属卷积核
aggregate_weight = torch.mm(routing_weights, weight).view(
batch_size * self.out_planes,
self.in_planes // self.groups,
self.kernel_size, self.kernel_size
)
if self.bias is not None:
aggregate_bias = torch.mm(routing_weights, self.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggregate_bias,
stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None,
stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
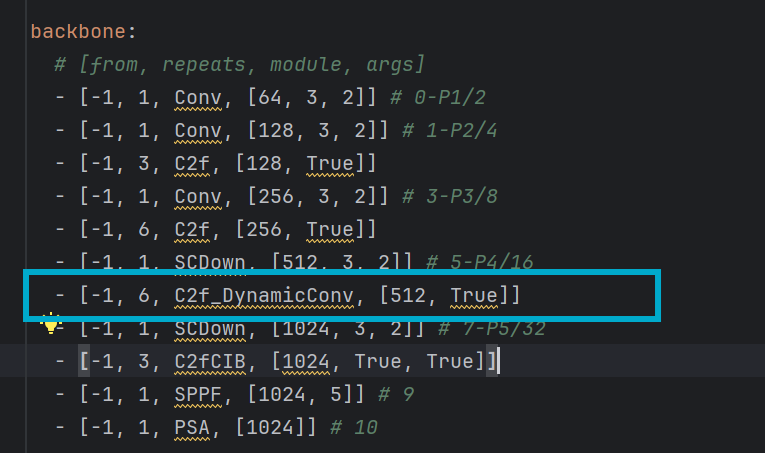
return output三、改进
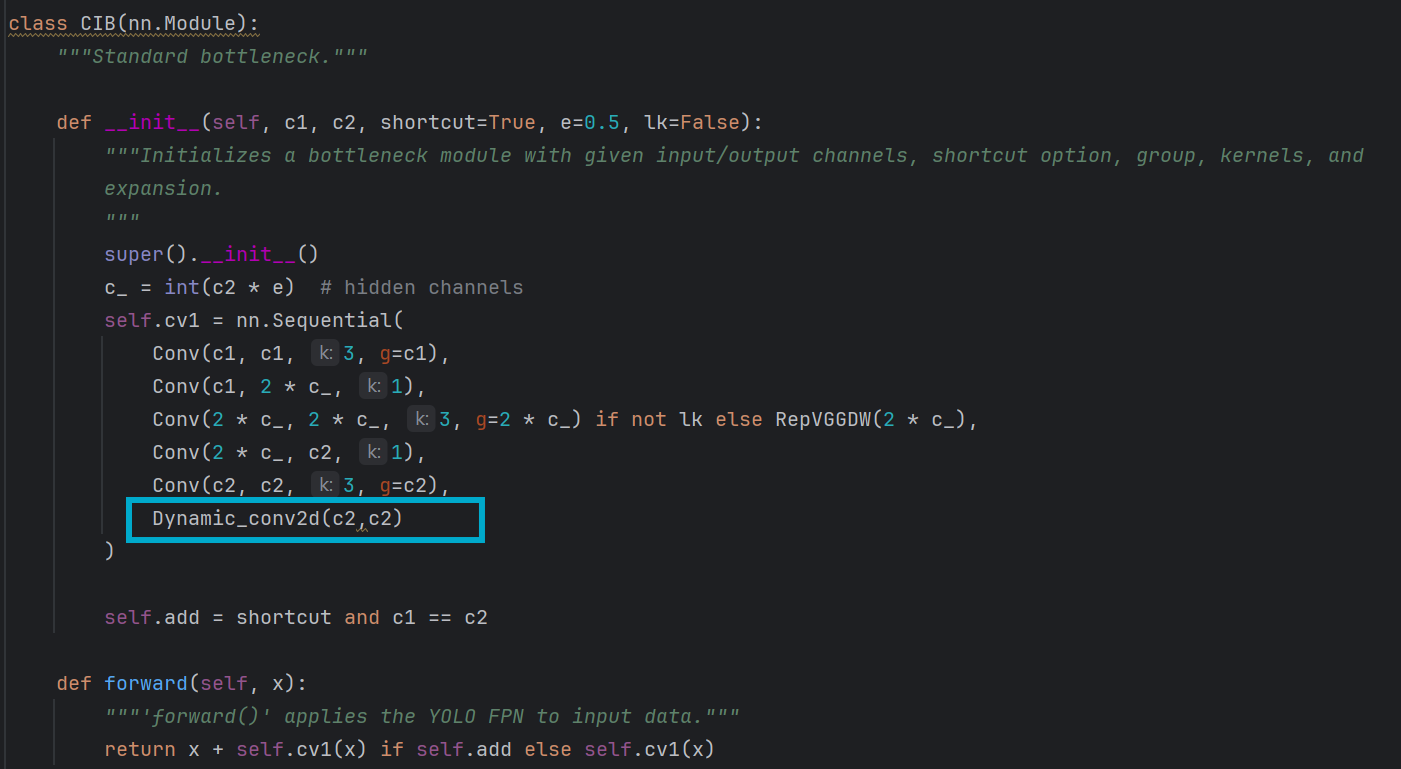
一、在C2fCIB函数的CIB 末尾插入插入动态卷积
经过前面这一系列处理后,特征已经高度凝练、语义丰富,在 CIB 末尾插入动态卷积,是为了在语义最丰富的特征上,用样本专属的通道混合器进行即插即用的微调,同时不破坏残差连接的优化基础,从而提升网络对复杂场景的适应性。
四、网络模型
替换原有的C2fCIB函数
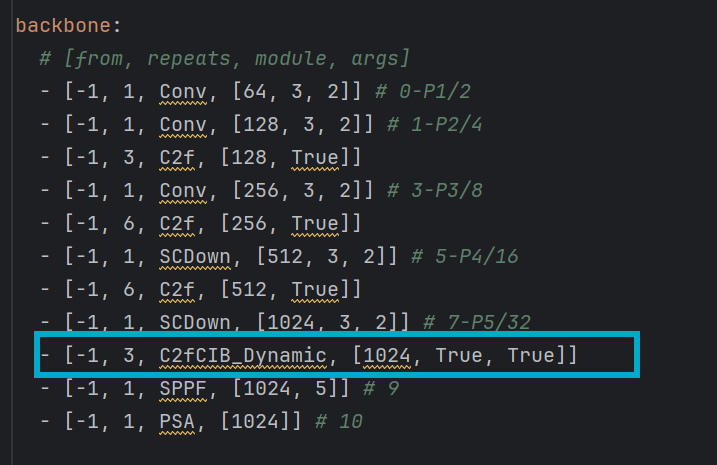
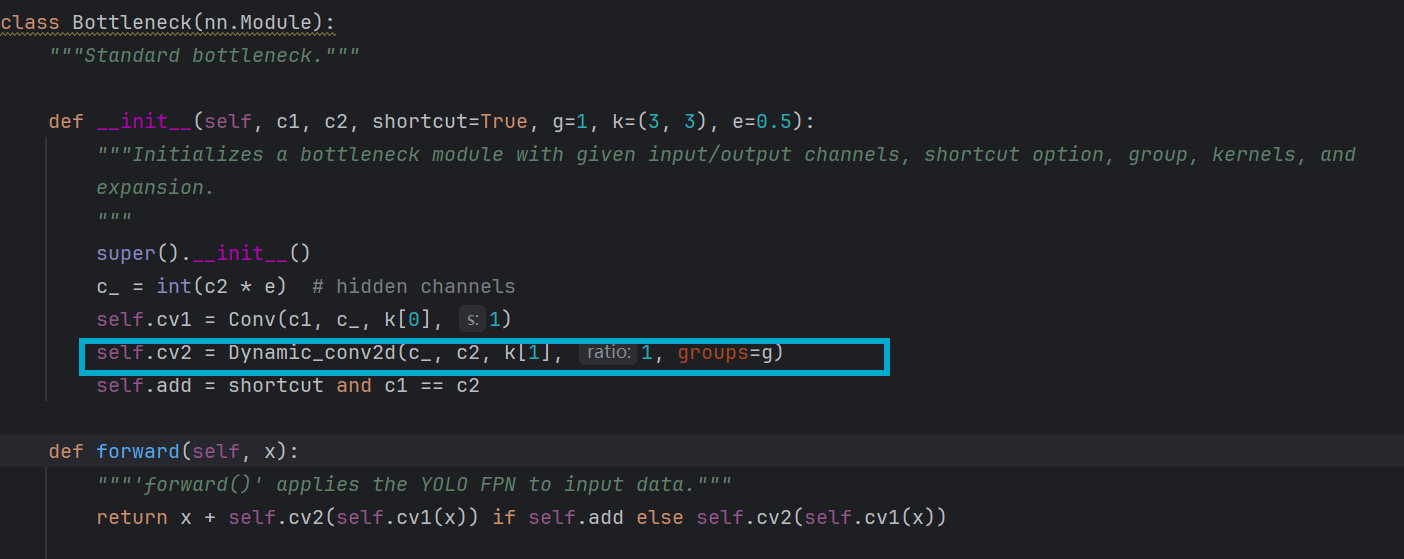
二、修改P4层的C2f中Bottleneck结构
在P4层的C2f进行修改,将动态卷积嵌入其中,这里选择对Bottleneck进行修改
C2f架构(AI生成):
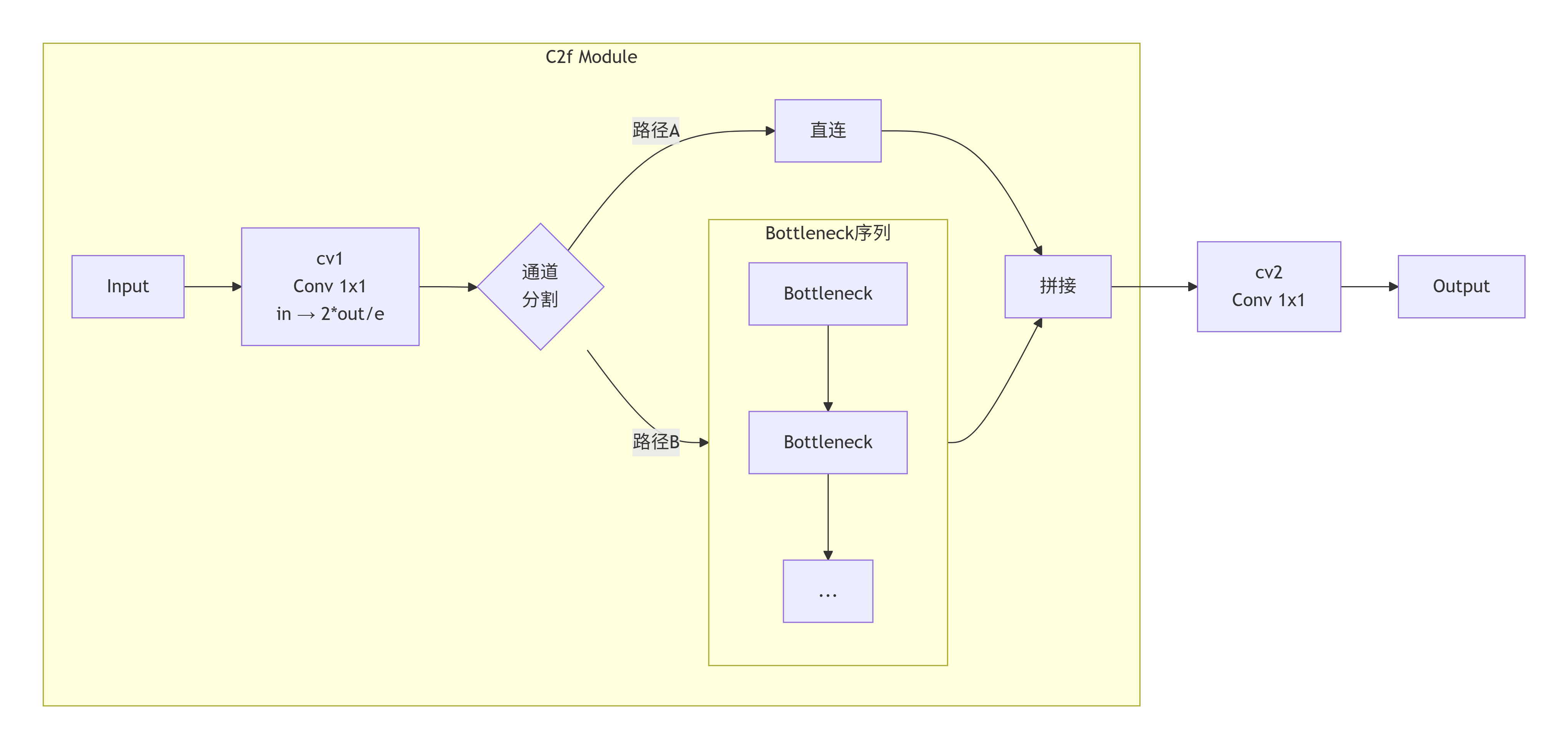
替换Bottleneck结构中的卷积
修改yaml网络配置文件

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)