OpenClaw 如何调用模型、工具和浏览器:从“聊天 AI”到“会干活的 Agent”
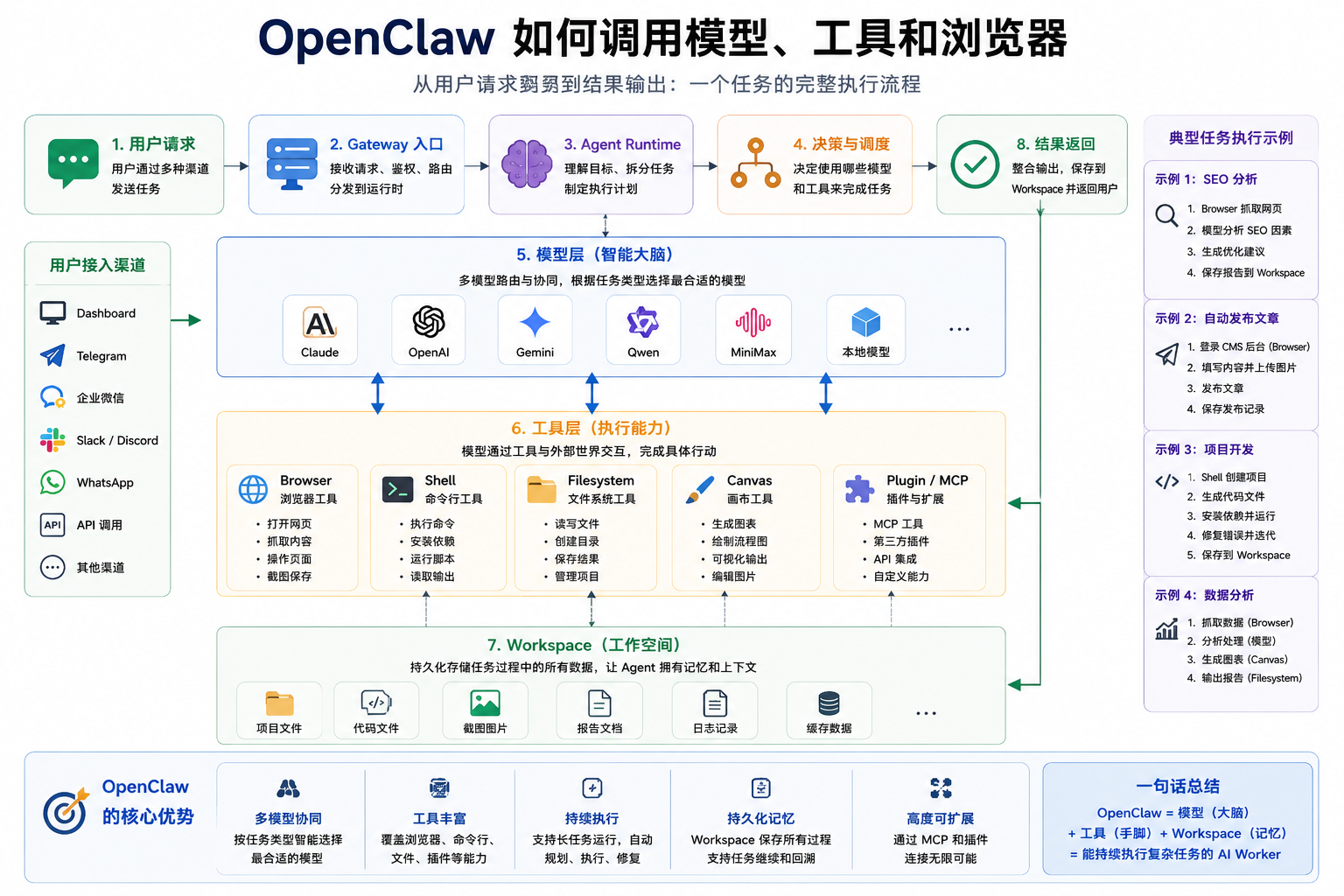
很多人第一次部署 OpenClaw 后,都会做同一件事:
打开 Dashboard。
输入一句:
帮我写一篇文章
然后看到模型返回内容。
接着得出结论:
“OpenClaw 不就是套了一层 UI 的 Claude 吗?”
这是一个非常典型的误解。
因为你看到的只是最后一步:
模型输出。
真正复杂的部分,其实发生在前面。
OpenClaw 并不是:
用户 → 模型 → 返回结果
而是:
用户
↓
Gateway
↓
Agent Runtime
↓
任务规划
↓
工具调用
↓
Browser / Shell / Filesystem
↓
模型推理
↓
结果生成
↓
Workspace 保存
↓
返回用户
模型只是其中一个环节。
真正让 OpenClaw 与普通 AI 区别开的,是:
它会先决定“干什么”,再决定“问谁”,最后决定“怎么执行”。
这篇文章,我们就把整个执行流程彻底拆开。
一、普通 AI 的调用方式:只有模型,没有执行
先看传统聊天 AI。
例如:
用户输入:
写一篇关于 AI 创业的文章
系统流程:
Prompt
↓
LLM
↓
文章输出
结束。
整个过程只有一次模型调用。
不会:
-
打开网页
-
保存文件
-
调用命令
-
检查结果
-
二次修复
所以它属于:
推理型系统。
重点在:
怎么回答
而 OpenClaw 不一样。
它属于:
执行型系统。
重点变成:
怎么完成任务
这是两个完全不同的设计方向。
二、OpenClaw 收到任务后,第一步不是调用模型
很多人以为:
用户输入以后。
OpenClaw 立即请求 Claude。
实际上并不是。
例如:
用户发送:
帮我分析 skills.lc 首页 SEO,并生成优化报告
OpenClaw 第一件事不是:
Claude:
请分析 SEO
而是先做任务理解。
内部流程类似:
收到请求
↓
识别目标
↓
拆分任务
↓
判断工具
↓
决定模型
↓
执行
系统可能拆成:
- 任务1:打开网站。
- 任务2:抓取 HTML。
- 任务3:读取标题。
- 任务4:分析 Meta。
- 任务5:检查图片 ALT。
- 任务6:生成报告。
- 任务7:保存 Workspace。
这时候模型甚至还没开始工作。
因为 Agent 正在规划。
这一步决定:
后面调用哪些能力。
三、模型层:OpenClaw 不一定只调用一个模型
传统 AI:
用户
↓
GPT
↓
结果
OpenClaw:
用户
↓
Agent Runtime
↓
模型路由
├─ Claude
├─ OpenAI
├─ Gemini
├─ Qwen
├─ MiniMax
└─ Local Model
它更像一个模型调度器。
例如:
复杂规划:
Claude
代码生成:
Qwen
图片理解:
Gemini
长文本总结:
OpenAI
失败降级:
MiniMax
流程可能变成:
任务开始
↓
Claude 规划
↓
Browser 获取内容
↓
Gemini 分析图片
↓
Qwen 生成代码
↓
OpenAI 总结
用户看到的是一个结果。
内部可能已经调用了四个模型。
这也是为什么 OpenClaw 更接近:
AI Runtime
而不是:
聊天机器人。
四、工具层:模型负责思考,工具负责行动
模型再聪明。
也不会自己打开浏览器。
不会执行命令。
不会保存文件。
这些事情由 Tool Layer 完成。
OpenClaw 常见工具包括:
Browser
Shell
Filesystem
Canvas
Plugin
MCP
每个工具都有不同职责。
- Browser:负责网页。
- Shell:负责命令。
- Filesystem:负责文件。
- Canvas:负责可视化。
- Plugin:负责扩展能力。
- MCP:负责连接外部系统。
这时候流程变成:
模型
↓
决定动作
↓
调用工具
↓
工具执行
↓
返回结果
↓
模型继续推理
所以模型像:大脑。
工具像:手脚。
没有工具。
模型只能聊天。
有了工具。
模型开始工作。
五、Browser:OpenClaw 如何操作网页
Browser 是最容易被低估的能力。
很多人认为:
浏览器工具就是:“打开网页。”
实际上远不止如此。
例如任务:
检查网站 SEO
Browser 可以执行:
打开页面
↓
等待加载
↓
读取 DOM
↓
提取标题
↓
分析 Meta
↓
检查图片
↓
抓取链接
↓
返回内容
如果是自动运营场景:
例如:
登录后台发布文章
流程甚至可能是:
打开后台
↓
输入账号
↓
点击登录
↓
进入编辑器
↓
粘贴内容
↓
上传图片
↓
发布
这已经不是问答。
而是:网页自动化。
六、Shell:让 Agent 真正开始执行
Browser 管网页。
Shell 管系统。
例如:
用户输入:
创建一个 Next.js 项目并启动
模型不会直接返回教程。
OpenClaw 可以规划:
第一步:创建项目。
npx create-next-app
第二步:安装依赖。
npm install
第三步:启动服务。
npm run dev
第四步:检查输出。
第五步:修复错误。
整个过程类似:
模型规划
↓
Shell 执行命令
↓
读取输出
↓
模型分析错误
↓
再次执行
你会发现。
模型开始形成:
观察 → 判断 → 执行 → 修复
闭环。
这是 Agent 的核心。
七、Filesystem:让任务拥有记忆
普通聊天 AI 最大问题:
结束即遗忘。
OpenClaw 用 Workspace + Filesystem 解决。
例如:
执行 SEO 检查:
系统可能保存:
workspace/
└── seo-report/
├── html/
├── screenshots/
├── report.md
├── keywords.csv
└── logs.txt
- 第一次运行:生成报告。
- 第二次运行:比较变化。
- 第三次运行:继续优化。
这意味着:
任务不是一次性的。
而是连续演进。
Filesystem 提供的不是存储。
而是:长期上下文能力。
八、完整流程:一次任务到底发生了什么
现在把所有组件放一起。
假设用户输入:
检查网站 SEO,并生成报告
OpenClaw 内部可能执行:
用户输入
↓
Gateway 接收任务
↓
Runtime 分析目标
↓
Claude 规划步骤
↓
Browser 抓取网站
↓
Filesystem 保存页面
↓
Gemini 分析图片
↓
OpenAI 总结内容
↓
生成 report.md
↓
保存 Workspace
↓
返回结果
注意。
模型不是入口。
也不是全部。
它只是整个链路里的:
推理节点。
真正完成工作的,是:
-
Runtime
-
Tool Layer
-
Browser
-
Shell
-
Filesystem
-
Workspace
模型负责:思考。
工具负责:行动。
Workspace 负责:记忆。
三者结合。OpenClaw 才能从:
聊天 AI
进化成:
持续执行任务的 Agent
九、总结:OpenClaw 为什么能“干活”
普通 AI:
用户
↓
模型
↓
答案
OpenClaw:
用户
↓
Gateway
↓
Runtime
↓
任务规划
↓
模型选择
↓
工具调用
↓
Browser / Shell
↓
Filesystem
↓
Workspace
↓
结果
普通 AI 解决:怎么回答。
OpenClaw 解决:怎么完成。
这也是它最大的不同。
它不是:
AI Chat
而是:
AI Execution System
下一篇我们继续讲:
OpenClaw vs OpenHands vs Claude Code:三个 Agent 系统到底有什么区别?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)