基于深度学习+AI的红外人体行为目标检测与预警系统(Python源码+数据集+UI可视化界面+YOLOv11训练结果)
基于深度学习+AI的红外人体行为目标检测与预警系统(Python源码+数据集+UI可视化界面+YOLOv11训练结果)
1、背景介绍
针对公共安全防控、特殊区域值守、应急救援处置、夜间安防管控需求,面向夜间道路监测、养老院监护、工业厂区巡检、草原牧区安防、应急搜救现场、涉密区域管控等场景,研发基于深度学习+AI的红外人体行为目标检测与预警系统具有重要现实意义。随着公共安全体系完善、智能化安防水平提升与特殊场景管控要求升级,人体作为安防监测的核心对象,其躺卧(Lying)、坐姿(Sitting)、站立(Standing)、弯腰(bend)、跌倒(fall)、行走(walking)、奔跑(running)、静坐(static sitting)、微动(micro-movement)、徘徊(wandering)等多类行为的实时精准监测,是保障人员安全、防范安全隐患、提升管控效能、规范安防管理的核心环节,而红外监测场景中人员分布分散、环境复杂(夜间光线缺失、烟雾粉尘遮挡、雨雪恶劣天气、远距离监测、复杂背景干扰)、行为姿态多变、相似行为易混淆、静态与微动行为难区分等问题带来的检测精度低、行为识别滞后、异常管控不及时等管理痛点日益凸显,年均因人体行为检测不及时、识别不准确引发的人员意外跌倒、夜间安全事故、非法闯入、应急救援延误、涉密区域违规逗留等问题频发,严重影响公共安全防控成效、人员生命安全与各类场景规范化管控水平。
传统人体行为监测依赖人工值守、可见光视频判读、简单红外传感器采集与特征匹配,受人力成本高、值守效率低、主观判断偏差大、复杂场景适配性差、夜间及恶劣天气监测盲区多、静态人员无法有效识别等因素制约,难以实现对监测区域内人体多目标、多行为的全天时、全天候、全范围精准检测与实时预警,而AI智能分析技术可依靠深度学习算法自动挖掘人体各类行为的红外热辐射特征、姿态规律与场景关联信息,精准捕捉跌倒、微动、徘徊等不同行为的细微差异,有效区分相似行为(如坐姿与静坐、行走与奔跑、弯腰与跌倒),实现夜间、烟雾、雨雪、远距离、复杂背景等特殊场景下的人体多目标行为精准识别,突破传统监测技术难以适配红外场景、捕捉静态与微动行为、实现全域化管控的瓶颈,同时兼顾隐私保护,避免可见光监测带来的隐私泄露问题,契合各类敏感场景的监测需求。
将深度学习目标检测算法(如改进型Faster R-CNN、YOLO系列)与AI智能分析、红外视频采集设备(红外摄像头、移动巡检红外设备、无人机红外巡检模块)、安防管控终端、应急预警平台结合,能够精准识别监测区域内人体个体及躺卧(Lying)、坐姿(Sitting)、站立(Standing)、弯腰(bend)、跌倒(fall)、行走(walking)、奔跑(running)、静坐(static sitting)、微动(micro-movement)、徘徊(wandering)等各类行为,有效区分人体与监测环境中的杂物、红外热源干扰、不同行为的动作差异,借助AI智能分析的实时性、自动化、规模化优势,以及红外采集设备的全天候适配能力(不受光照、烟雾、粉尘影响),实现对监测区域全域的人体个体定位、多行为自动识别、行为类型分类、异常行为预警(如意外跌倒、长时间静坐不动、非法闯入徘徊、异常奔跑、夜间违规逗留等),同步推送预警信息至安防管控终端、应急处置中心与值守负责人,提升公共安全防控、特殊区域值守、应急救援处置、夜间安防管控等工作的智能化、全域化与精准处置能力,尤其适用于老龄化社会背景下的老人安全监护、夜间道路交通安全监测等重点场景,弥补传统监测技术的短板。
该系统对强化各类场景精细化安防管控、提升公共安全防控效能、减少人员安全事故、降低人工值守成本、保障人员生命安全具有重要应用价值,为公共安全、应急救援、工业安防、养老监护、草原牧区管控等领域的规范化管理、智能化防控提供高效、可靠的技术支撑,助力破解红外场景下人体多目标行为检测难、相似行为识别准度低、静态与微动行为难捕捉、异常预警滞后、全域化管控效率低的技术难题,保障人员安全、提升安防管控水平、规范各类场景管理秩序,同时依托红外感知的隐私保护优势,实现安全监测与隐私保护的双向兼顾,推动智能化安防技术在各类复杂场景的深度落地与应用升级。
2、算法结构
目标检测是一种基于目标集合和统计特征的图像分割,主要包括分类问题和检测定位问题。目标检测算法以深度学习为基准的主要有两大类:基于回归分析的单阶段目标检测和基于候选区域的两阶段目标检测。
基于回归分析的单阶段目标检测算法在检测目标时采用一个网络进行端到端的目标检测,直接对图像进行计算生成检测结果,检测速度快,但检测精度低。主要代表是YOLO系列和SSD系列。2015年,Joseph等人提出了一种新的目标算法YOLO,其思想是将一张图片分成多个网格,让每个网格负责预测中心点落在当前网格中的物体。该方法目标检测速度快、可以避免背景错误并能学到物体的泛化特征,但存在定位不准、精度低和对小物体检测效果不好的问题。Joseph在接下来的几年从骨干网络和跨尺度特征融合等方面对YOLO进行优化改进,相继提出了YOLOv2和YOLOv3。2016年,Liu等人提出了结合YOLO检测速度快和Faster R-CNN的锚框思想的SSD算法,并使用多尺度特征图进行检测,在满足检测速度要求的同时还大幅提高了模型的检测精度,但由于小尺寸的目标多用较低层级的锚框来训练,较低层级的特征非线性程度不够,无法训练到足够的精确度,所以仍存在小目标的检测效果差的问题。
基于候选区域的两阶段目标检测是先对图像提取候选框,然后对候选框进行分类回归操作得到检测结果,检测精度较高,但检测速度较慢,训练时间长且误报高。主要代表算法有R-CNN系列、SPP-Net和FPN。Girshick等人在2014年提出了两阶段目标检测算法R-CNN,通过选择性搜索的方法提取出候选区域,然后将候选区域变换为标准的方形尺寸并使用改进的AlexNet筛选出有效的候选区域,最后通过支持向量机进行分类并对有效的候选区域进行线性回归获得边界框,该算法有着较高的准确性并提高了特征对样本的表示能力,但由于图像尺寸限制造成目标失真变形并且存在冗余计算、检测速度慢。针对这个问题,He等人提出了SPP-Net,在卷积层和全连接层之间增添一个空间金字塔池化模块,不仅可以对候选区域进行变换为任意比例的区域特征提取,而且可以减少候选区域的重复计算,该算法不仅提高了目标检测的精度,同时又提升了目标检测速度,但训练过程仍是多阶段的,而且无法实现端到端训练。2015年,Girshick等人结合R-CNN和SPP-Net的特点提出了Fast R-CNN,通过卷积层对整张图像和候选区域进行特征提取,并使用感兴趣池化层和Softmax分别取代空间金字塔池化模块和SVM,同时提高了精度和速度,但由于选择性搜索算法只能使用CPU,仍无法实现实时检测。Ren等人针对此问题在同年提出了Faster R-CNN,Faster R-CNN最大的特点是首次提出了一个全新的候选区域网络(Region Proposal Network, RPN),该算法不仅可以端到端训练,而且可以在GPU上实时性检测,但由于anchor的使用,仍对小目标的检测效果并不理想。Lin等人于2017年在Faster R-CNN基础上提出了特征金字塔网络检测算法FPN,通过多层特征融合,大大提高了小目标物体的检测效果。
为了契合对检测性能与实时性的更高要求,本文选用以 YOLOv11 为根基的单阶段目标检测算法作为基准。YOLOv11 模型作为迭代升级的实时目标检测框架,凭借其更为迅猛的检测速率以及大幅提升的检测精度,在同类算法中展现出显著优势,其网络结构如图所示。本文深入研究的算法正是在 YOLOv11 的基础上开展改进与优化工作,旨在进一步强化目标检测的准确性与实时性,从而更好地适配特定应用场景的复杂多样需求。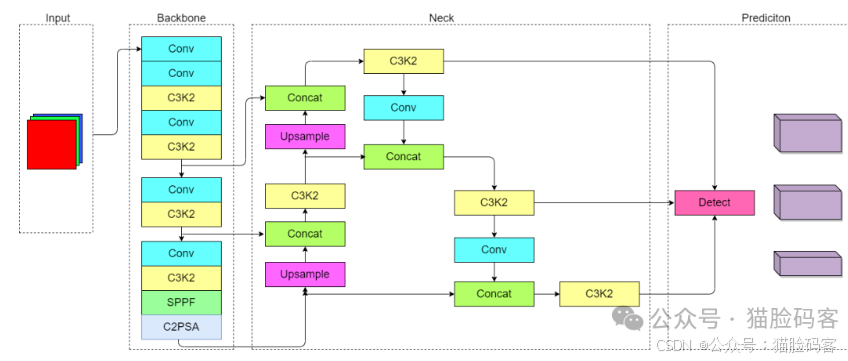
3、数据集
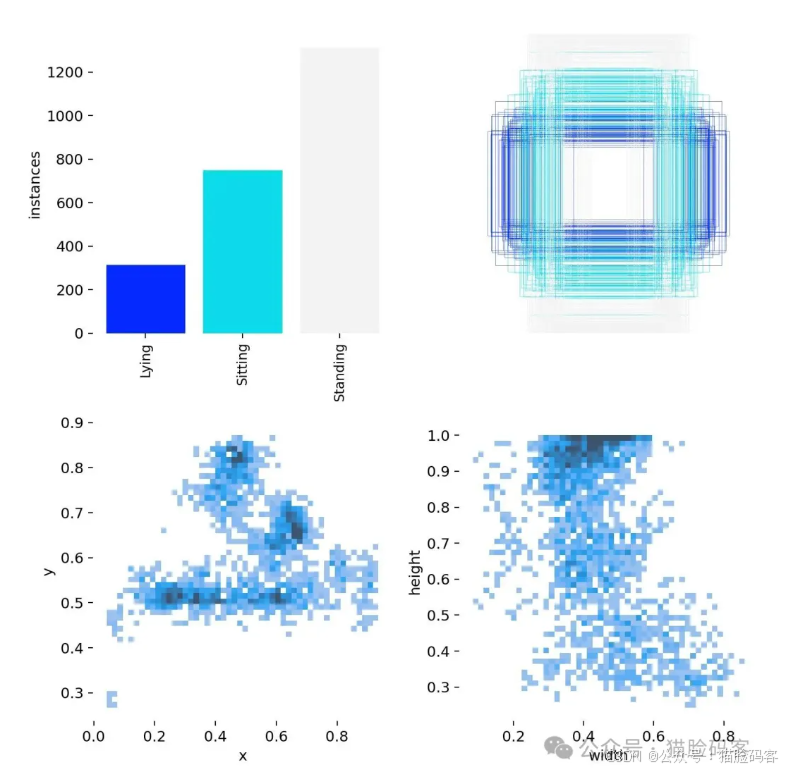
本算法研究数据集来源于公开数据集InfraredHumanBehaviorDataset进行实验,InfraredHumanBehaviorDataset数据集信息如图所示。本文共选取的3356张图像,每张图像的大小为640x640像素,包括不同光照强度、不同角度的图像。然后通过在线标注工具MakeSense(https://www.makesense.ai/)进行标注,将标注后的图像划分为2350张图像作为训练集,671张图像作为训练集,335张图像作为测试集。
# 目录结构
InfraredHumanBehaviorDataset
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
# 适用算法
"yolov26/yolov13/yolov12/yolov11/yolov10/yolov8/yolov5等YOLO系列"
# 类别
'Lying'
'Sitting'
'Standing'
# yaml文件配置
path: InfraredHumanBehaviorDataset # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: images/test # test images (optional)
# Classes
names: ['Lying', 'Sitting', 'Standing']

4、评价指标
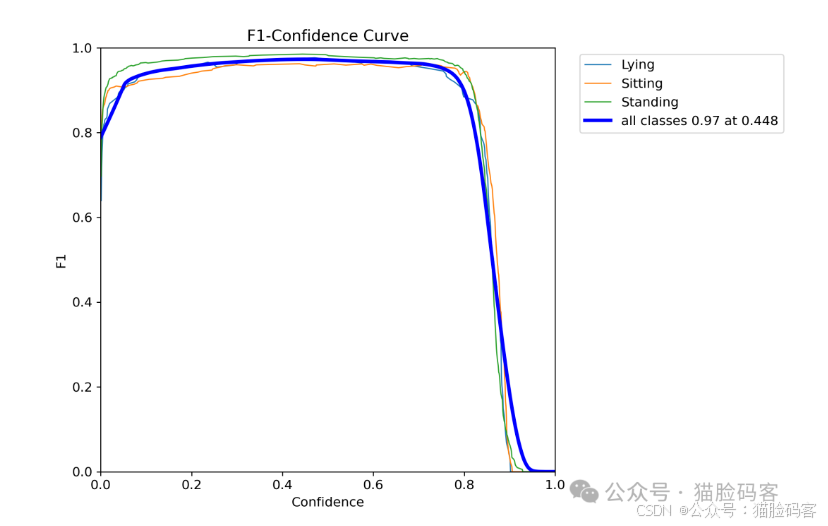
本文选取的评估指标包括综合精确率Precision和召回率Recall的F1-Score、平均精度均值mAP、计算量GFLOPs和权重大小Model Size等。mAP表示IoU阈值取0.5时的值。具体计算公式如下。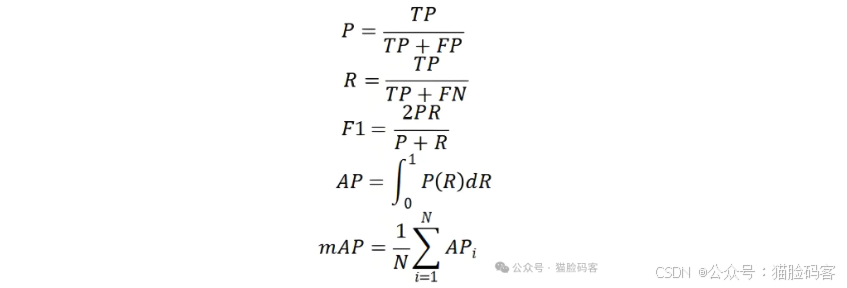
式中:TP为真正例,FP为假正例,FN为假负例,AP为平均精度,P为精确率,R为召回率。
5、实验环境
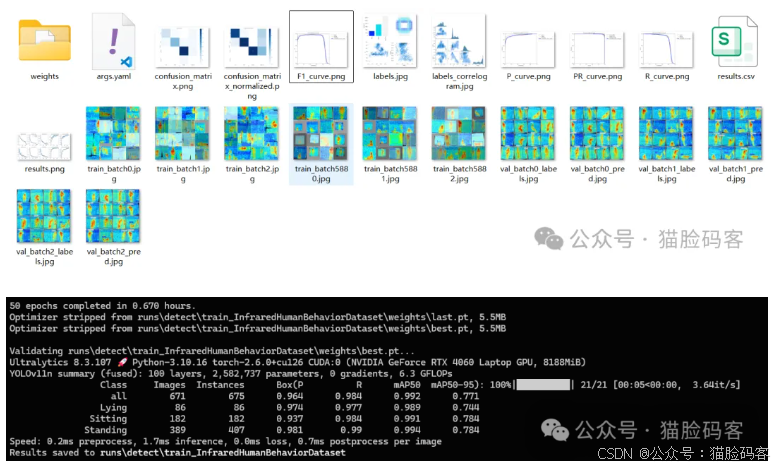
本实验的环境在Window操作系统上进行,采用的深度学习框架为Pytorch 2.6.0+126,编程语言为Python 3.10.0,CUDA版本12.6,GPU为NVIDIA GeForce RTX 4060,显存为8GB。在模型训练过程中,模型的批处理大小BatchSize设为32,总次数Epochs设为50,初始学习率被设置为0.01,动量参数因子为0.937,优化器权重衰减系数设为0.0005,以使其更快收敛并获得更好的性能。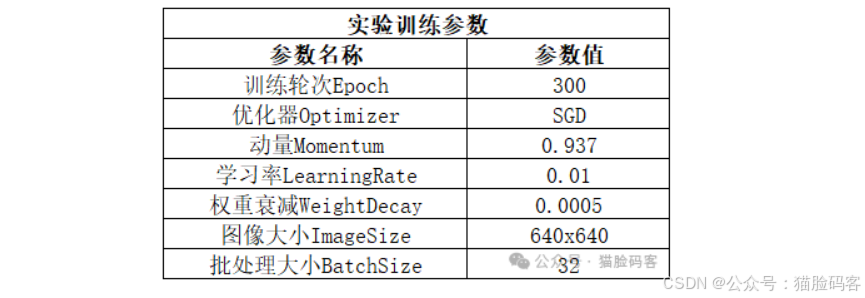
6、训练脚本
# train.py
from ultralytics import YOLO
if __name__ == '__main__':
# 初始训练
model = YOLO(r"yolov11n.yaml")
model.load("yolo11n.pt")
results = model.train(data=r"data.yaml",
epochs=50,
imgsz=640,
batch=32,
workers=4,
device=0,
name="train")
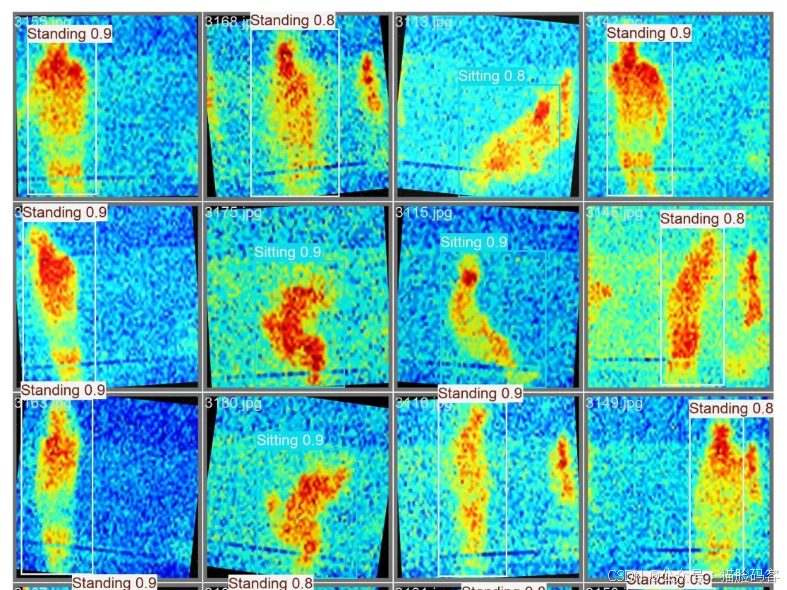
7、实验结果
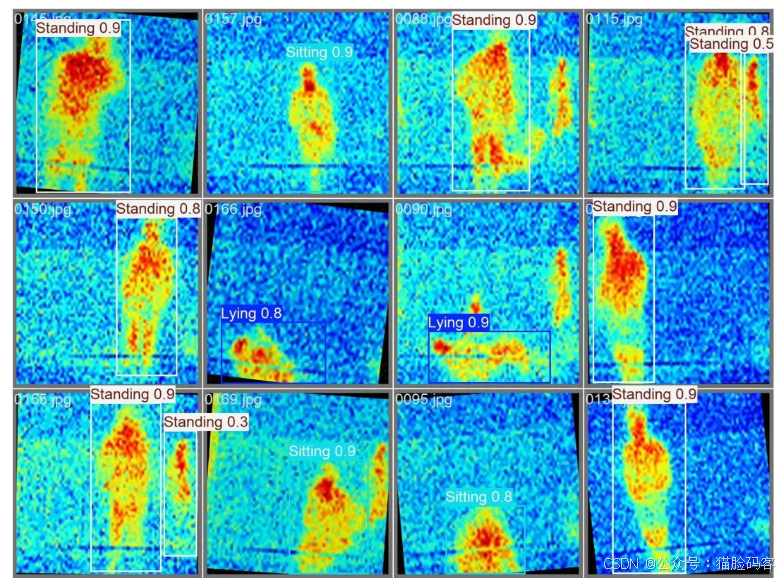
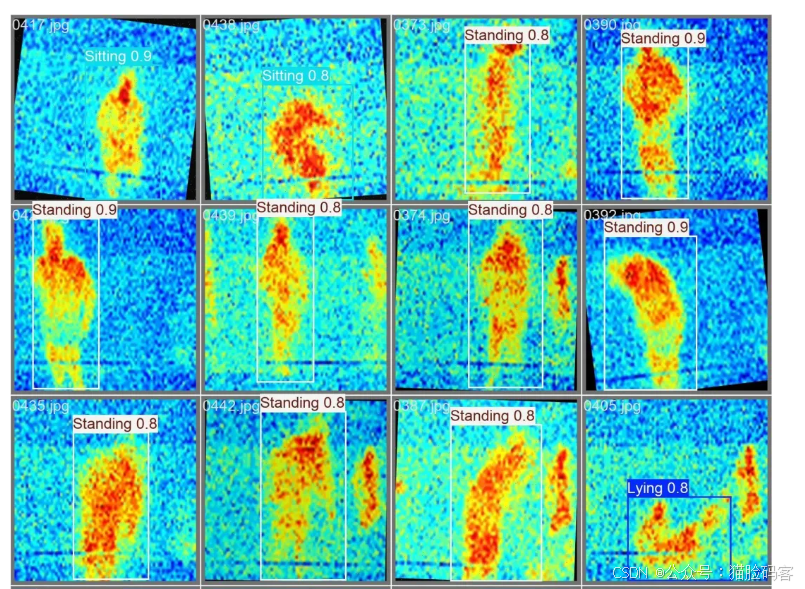
8、系统实现
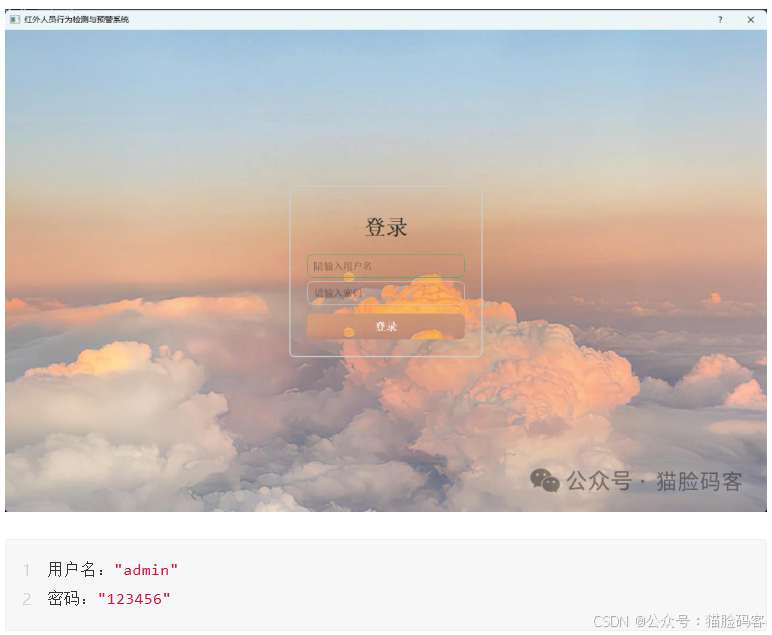
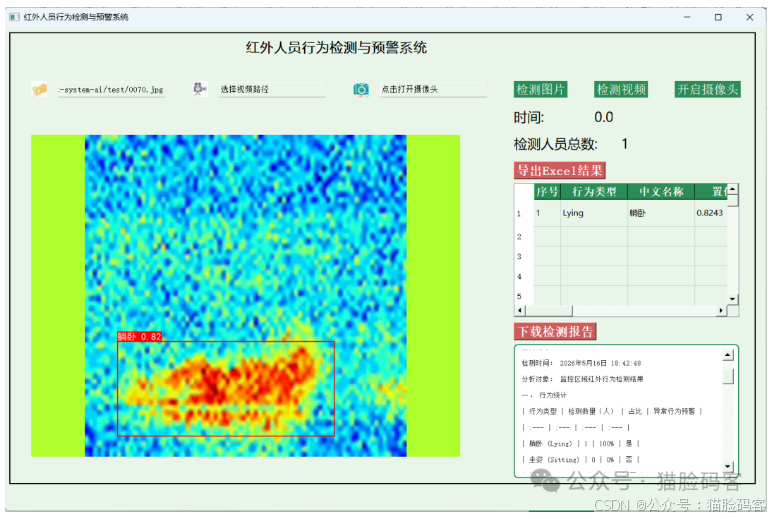
YOLO目标检测系统主要包括登录页面和主页面,其中主页面集成了三大核心检测功能,各功能操作便捷、检测高效,具体介绍如下:
登录页面:作为系统入口,用户需输入正确的账号密码完成登录,验证通过后方可进入主页面使用各项检测功能,保障系统使用安全性,防止未授权访问。
主页面:为核心操作区域,集中展示图片检测、视频检测、摄像头实时检测三大功能入口,界面简洁直观,方便用户快速找到所需功能,后续各项检测操作均在主页面内完成。
✅ 图片检测:支持单张图片输入检测,用户上传图片后,YOLO模型将快速对图像进行分析,精准识别图像中的各类目标,自动在图像中框选目标位置,并同步返回检测框坐标及目标类别信息,让检测结果直观可见,适用于单帧图像的快速目标识别场景。
✅ 视频检测:支持各类常见格式视频文件输入,检测过程中,YOLO模型会对视频中的每一帧进行逐帧分析、精准识别,在每帧画面中标记出检测到的目标,最终可输出带有目标框的完整视频文件,也可进行实时画面展示,广泛应用于视频监控、动态场景分析等需求场景。
✅ 摄像头实时检测:支持连接USB摄像头,实现实时目标监测功能。YOLO模型可实时捕捉摄像头传输的视频流,同步进行目标检测与识别,即时在画面中显示检测结果,提供快速、精准的即时反馈,适用于安防监控、无人驾驶、智能交通等对实时性要求较高的应用场景。
此外,系统所有检测功能均支持deepseek ai对检测结果进行AI分析,可进一步挖掘检测数据的深层信息,提升检测结果的实用性和解读效率,为用户提供更全面的检测服务。
登录界面
主界面
9、应用场景
基于深度学习+AI的红外人体行为目标检测与预警系统,聚焦Lying(躺卧)、Sitting(坐姿)、Standing(站立)三大类人体核心行为目标,依托红外成像设备、高清监控设备全天时、全场景、无死角监测的优势,结合AI智能分析可精准捕捉人体各类行为的动作特征、姿态差异与行为规律,穿透夜间昏暗、光线不足、遮挡遮挡、恶劣天气(雨雪、雾霾、沙尘)等干扰的特性,搭配深度学习算法的高效识别、精准判定与实时预警能力,广泛应用于各类安防监控、老人照料、特殊区域管控、应急救援及园区管理场景:安防监控场景可精准识别监控范围内人体的各类行为,实时统计各类行为频次、定位异常行为人员、研判人员活动状态与区域安全适配度,破解传统人工巡检耗时耗力、监测不全面、异常行为发现不及时、安全隐患难排查的痛点;老人照料场景可实现居家养老、养老院等场所的全域无死角监测,快速定位老人躺卧、坐姿、站立等核心行为,同步推送异常行为(如长时间躺卧不起、异常坐姿)预警信息至照料人员终端,助力及时掌握老人身体状态,防范因人体行为监测不及时导致的意外跌倒、突发疾病、无人照料等问题;特殊区域管控可精准识别人体异常行为(如违规躺卧、长时间停留坐姿、擅自站立逗留),实时捕捉人体行为异常变化,为区域安全管控提供精准依据,弥补传统管控人工排查效率低、漏判误判率高、违规行为初期难以发现的短板。
此外,在安防监控、老人照料、特殊区域管控等监管范围广、环境条件复杂、人工监测难度大的场景,可依托固定监控全覆盖、移动巡航灵活补盲的双重优势,精准识别不同区域人体行为的分布规律、频次特征,实时跟踪人体行为变化、身体状态波动,同步推送预警信息与管理指引,弥补人工监测盲区、降低安全管理与照料服务成本;在居家养老、养老院等照料场景中,可快速区分人体正常行为与异常行为、合理行为与危险行为(如长时间躺卧不起、坐姿异常倾斜),精准定位人体活动过程中的行为异常与安全隐患,同步推送预警信息与处置建议,助力照料人员及时干预,防范因人体行为异常导致的意外受伤、突发疾病延误救治等问题,保障照料对象安全与照料服务质量;在特殊区域管控场景中,可通过监测人体群体行为的变化规律、个体行为异常,精准定位安全管控重点对象,同步推送预警信息与管控处置建议,助力强化区域安全管控、防范安全事故发生,避免因人体行为异常监测疏漏导致的安全隐患与管理损失;在应急救援场景中,可依托红外成像的穿透优势,在昏暗、遮挡、恶劣天气等复杂环境下,精准识别被困人员的躺卧、坐姿、站立等行为,快速定位被困人员位置,为应急救援提供精准指引,提升救援效率、减少救援耗时,保障被困人员生命安全。该系统全方位满足各类场景下人体三大核心行为的精准检测、异常判定、实时预警与动态管理需求,破解传统人体行为监管识别不准、异常判定滞后、人工成本过高、适配复杂环境能力弱的痛点,为安防监控、老人照料、特殊区域管控、应急救援等领域的规范化管理、精准防控、效能提升、成本降低提供智能化科技支撑,显著提升各类场景的综合管理水平与安全保障能力。
10、源码获取(网盘地址)
[猫脸码客:catcode2020]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)