Redis为何如此快?揭秘IO多路复用技术【个人八股】

既然我们前面聊到了什么是redis?redis有什么用?以及redis里面有很多的数据结构
我有个疑惑就是?redis快仅仅是因为它将数据存储在内存当中吗?请你回答一下 redis为什么快?
这里就会引入IO多路复用技术是什么?IO多路复用技术的主要作用是什么?怎么实现的?
那redis是从哪一个版本开始引入IO多路复用技术的呢?
你能不能说一下IO多路复用技术的底层实现机制是什么?
你能不能说一下redis中的单线程和多线程?
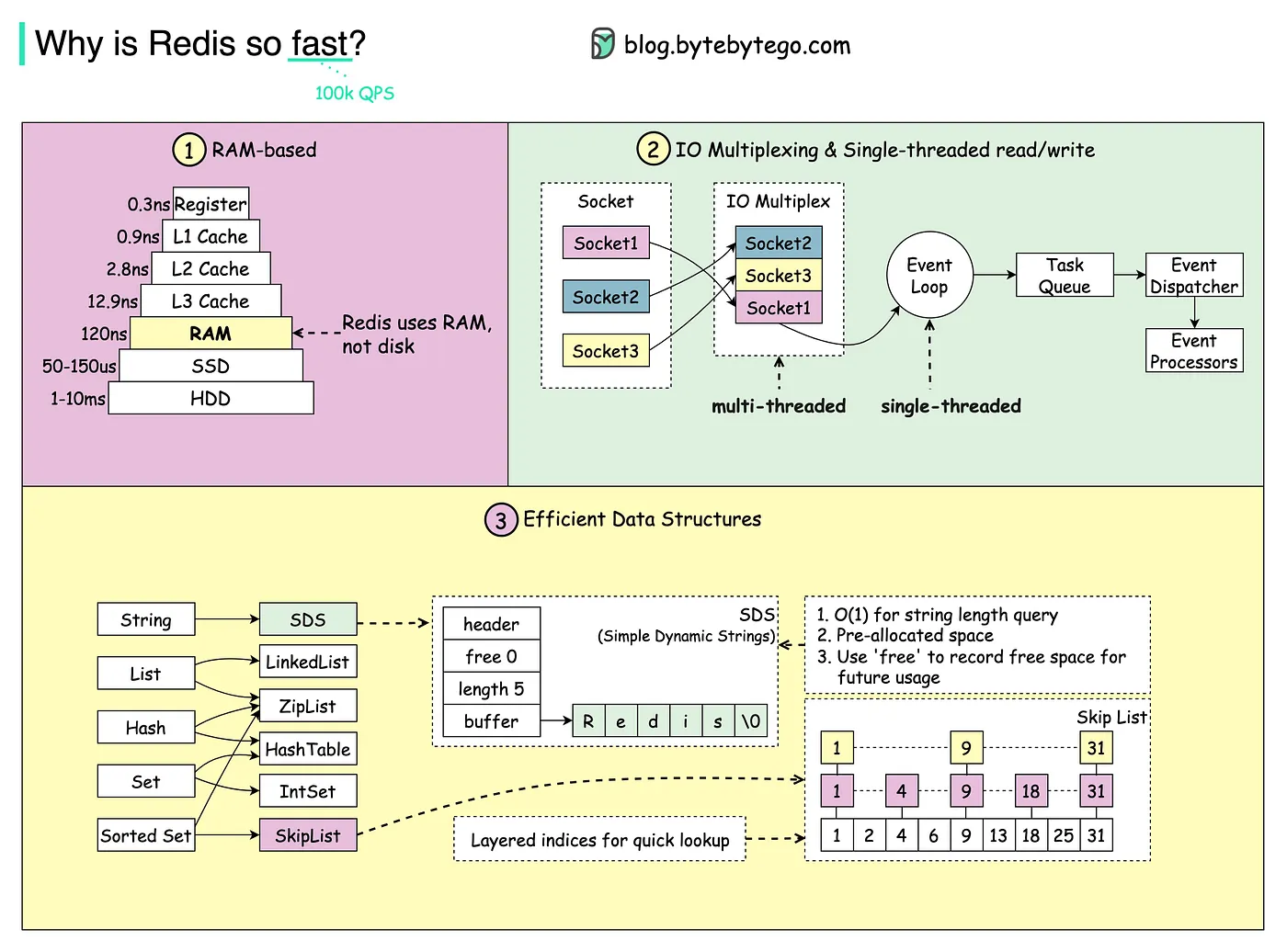
Redis 为什么快呢?
第一,redis将数据保存在内存当中,内存的响应速度是非常快的,通常是可以达到微秒级
第二,Redis 采用了基于 IO 多路复用技术的事件驱动模型来处理 客户端请求和执行 Redis 命令。
其中的 IO 多路复用技术可以在只有一个线程的情况下,同时监听成千上万个客户端连接,解决传统 IO 模型中每个连接都需要一个独立线程带来的性能开销。
IO 多路复用会持续监听请求,然后把准备好的请求压入到一个队列当中,并将其有序地传递给文件事件分派器,最后由事件处理器来执行对应的 accept、read 和 write 请求。
第三,Redis 对底层数据结构做了极致的优化,比如说 String 的底层数据结构动态字符串支持动态扩容、预分配冗余空间,能够减少内存碎片和内存分配的开销。
可能的几个追问点:
因为前面我们聊过redis的数据是保存在内存当中的,这个地方就不做过多的赘述,主要是还是将redis和MySQL来做一个对比的方式来进行考察
接着就是redis用到了IO多路复用技术,这个话会考察
如果上面没有答到IO多路复用技术:可以同时监听上万个客户端连接,解决传统IO模型当中每一个连接都需要一个现成的开销问题的话,这里就会被问到 您不能具体说一说IO多路复用技术可以实现哪些功能
然后就是问你IO多路复用技术的底层原理,底层的实现机制你到底了不了解?
IO多路复用技术是从哪一个版本开始引进的,在引进之前MySQL是怎么实现对应的缓存机制的!
第三点的话就是我们前面提到过的,数据结构的底层实现机制,这个点还是非常重要的!需要大家多花点时间去好好学习一下这部分的内容!
redis的IO复用技术是在哪一个版本进行引入的?
在 Redis 6.0 之前,包括连接建立、请求读取、响应发送,以及命令执行都是在主线程中顺序执行的,这样可以避免多线程环境下的锁竞争和上下文切换,因为 Redis 的绝大部分操作都是在内存中进行的,性能瓶颈主要是内存操作和网络通信,而不是 CPU。
为了进一步解决网络 IO 的性能瓶颈,Redis 6.0 引入了多线程机制,把网络 IO 和命令执行分开,网络 IO 交给线程池来处理,而命令执行仍然在主线程中进行,这样就可以充分利用多核 CPU 的性能。
主线程专注于命令执行,网络IO 由其他线程分担,在多核 CPU 环境下,Redis 的性能可以得到显著提升。
碎碎念一下
首先就是讲一讲redis的工作机制:主要就是包括了连接建立,建立完成连接之后,就可以处理和读取请求,根据请求内部的内容执行对应的命令,命令的执行都是在主线程当中来完成的!
所以我们就可以去分析主要的性能瓶颈会出现在哪里?网络连接的建立以及命令的执行部分了!
为什么不用多线程?多线程存在的问题是,你用多线程,肯定得上锁吧?所以会有多线程锁的竞争问题。多线程之间的上下文切换等问题!
既然你前面提到了IO多路复用技术有很大的作用,那你能不能来详细的聊一聊IO多路复用技术?
能详细说一下IO多路复用吗?
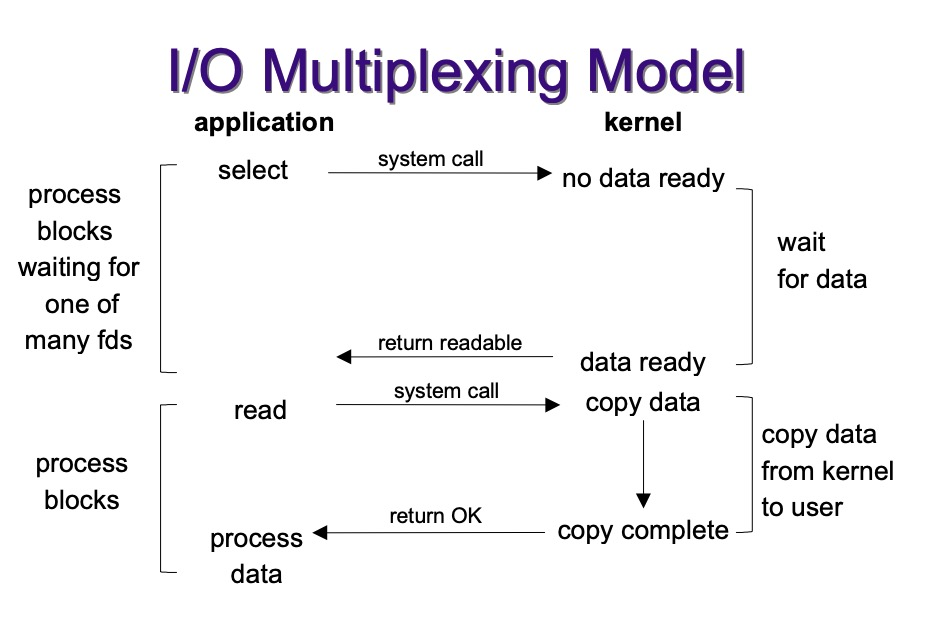
IO 多路复用是一种允许单个进程同时监视多个文件描述符的技术,使得程序能够高效处理多个并发连接而无需创建大量线程。
IO 多路复用的核心思想是:让单个线程可以等待多个文件描述符就绪,然后对就绪的描述符进行操作。这样可以在不使用多线程或多进程的情况下处理并发连接。
主要的实现机制包括 select、poll、epoll、kqueue 和 IOCP 等。
底层的实现机制主要有5种,重点还是掌握前面的前三种!后面两种做一个了解。
请说说 select、poll、epoll、kqueue 和 IOCP 的区别?
select 的缺点是单个进程能监视的文件描述符数量有限,一般为 1024 个,且每次调用都需要将文件描述符集合从用户态复制到内核态,然后遍历找出就绪的描述符,性能较差。
poll 的优点是没有最大文件描述符数量的限制,但是每次调用仍然需要将文件描述符集合从用户态复制到内核态,依然需要遍历,性能仍然较差。
epoll 是 Linux 特有的 IO 多路复用机制,支持大规模并发连接,使用事件驱动模型,性能更高。其工作原理是将文件描述符注册到内核中,然后通过事件通知机制来处理就绪的文件描述符,不需要轮询,也不需要数据拷贝,更没有数量限制,所以性能非常高。
kqueue 是 BSD/macOS 系统下的 IO 多路复用机制,类似于 epoll,支持大规模并发连接,使用事件驱动模型。
IOCP 是 Windows 系统下的 IO 多路复用机制,使用使用完成端口模型而非事件通知。
大概有个印象就是 select和poll的机制是怎么实现的?两者的缺点是什么?
然后要了解到为什么 epoll的性能和实现的机制要比select和poll要好的多?
emmmmm,你既然提到了他们5种不同的工作机制,各自是怎么发挥作用的,那你能不能说说前三种的底层实现原理呢?
select、poll 和 epoll 的实现原理?
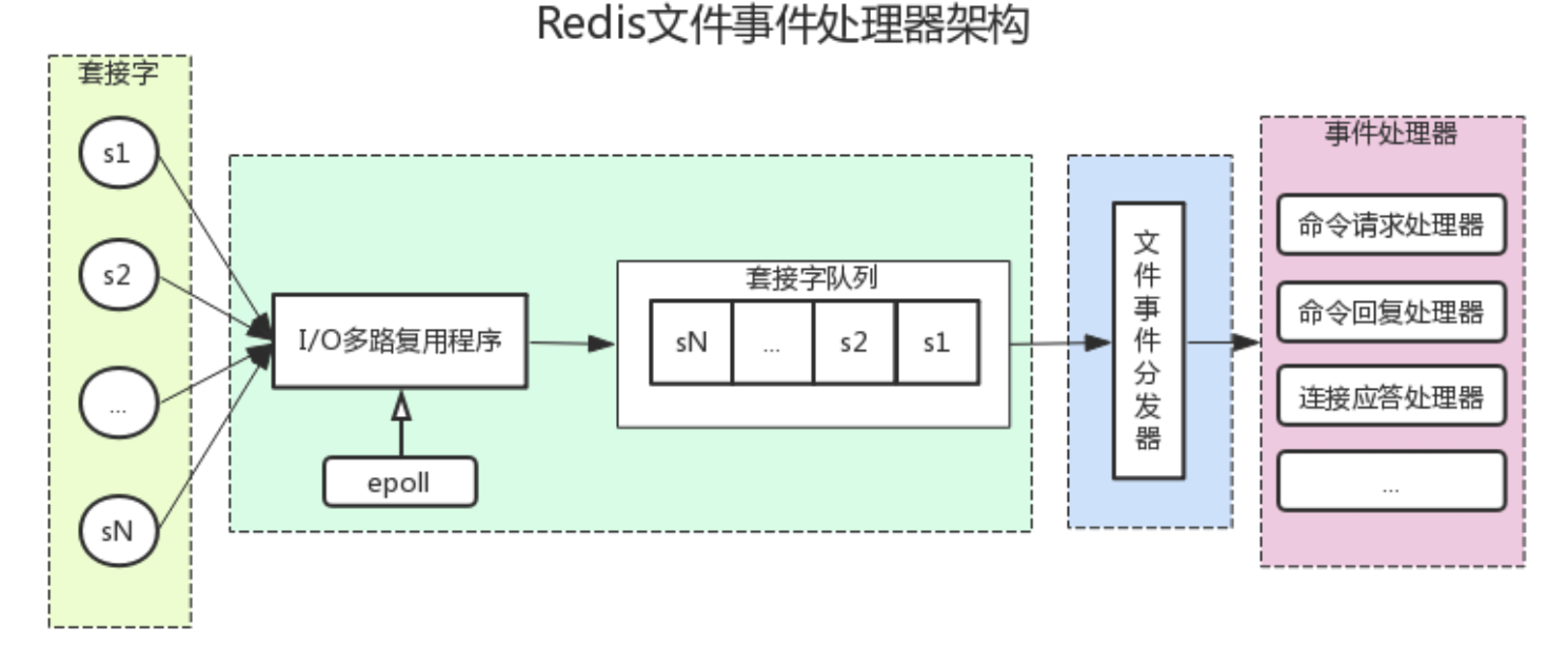
select 和 poll 都是通过把所有文件描述符传递给内核,由内核遍历判断哪些就绪。
select 将文件描述符 FD 通过 BitsMap 传入内核,轮询所有的 FD,通过调用 file->poll 函数查询是否有对应事件,没有就将 task 加入 FD 对应 file 的待唤醒队列,等待事件来临被唤醒。
poll 改进了连接数上限问题,不再用 BitsMap 来传入 FD,取而代之的是动态数组 pollfd,但本质上仍是线性遍历,性能没有提升太多。
select和poll的模式都是,一次将参数拷贝到内核空间,等有结果了再一次拷贝出去。
epoll 将监听的 FD 注册进内核的红黑树,由内核在事件触发时将就绪的 FD 放入 ready list。应用程序通过 epoll_wait 获取就绪的 FD,从而避免遍历所有连接的开销。
epoll 最大的优点是:支持事件驱动 + 边缘触发,ADD 时拷贝一次,epoll_wait 时利用 MMAP 和用户共享空间,直接拷贝数据到用户空间,因此在高并发场景下性能远高于 select 和 poll。
那你能不能说一下早期的redis为什么使用单线程,单线程的好处在哪里?
Redis为什么早期选择单线程?
第一,单线程模型不需要考虑复杂的锁机制,不存在多线程环境下的死锁、竞态条件等问题,开发起来更快,也更容易维护。
第二,Redis 是IO 密集型而非 CPU 密集型,主要受内存和网络 IO 限制,而非 CPU 的计算能力,单线程可以避免线程上下文切换的开销。
哪怕我们在一个普通的 Linux 服务器上启动 Redis 服务,它也能在 1s 内处理 1000000 个用户请求。
第三,单线程可以保证命令执行的原子性,无需额外的同步机制。
Redis 虽然最初采用了单线程设计,但后续的版本中也在特定方面引入了多线程,比如说 Redis 4.0 就引异步多线程,用于清理脏数据、释放无用连接、删除大 Key 等。
诶,你前面提到了redis的多线程,那这是怎么回事?有没有可能会出现死锁的问题?
Redis 6.0 使用多线程是怎么回事?
Redis 6.0 的多线程仅用于处理网络 IO,包括网络数据的读取、写入,以及请求解析。
而命令的执行依然是单线程,这种设计被称为“IO 线程化”,能够在高负载的情况下,最大限度地提升 Redis 的响应速度。
单线程的Redis QPS 能到多少?(补充)
根据官方的基准测试,一个普通服务器的 Redis 实例通常可以达到每秒十万左右的 QPS。
Redis 的 QPS(每秒请求数)性能取决于多种因素,包括硬件配置、网络延迟、数据结构、命令类型等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)