机器学习入门:理解线性回归与逻辑(简化且附Python实战代码)
前言
在机器学习的广阔领域中, 线性回归Linear Regression 是最基础、最重要的算法之一。它是学习监督学习的起点,也是理解更复杂模型的基石。根据我的学习经验,本文将带你从零开始,全面掌握线性回归的核心概念、数学原理和实际应用。会有简单的微积分方面的知识,不用系统学习
什么是线性回归?
核心概念
线性回归是一种监督学习算法,用于建立输入特征(X)与输出目标(y)之间的线性关系。简单来说,就是找到一条"最佳拟合直线",使得这条直线能够最好地描述数据的变化趋势。
对于简单的单变量线性回归,其数学公式为:
[y = wx + b]
其中:
y:预测值(目标变量)
x:输入特征
w:权重(weight)或斜率(slope),表示x对y的影响程度
b:偏置(bias)或截距(intercept),表示当x=0时y的值
实际应用场景
房价预测:根据房屋面积预测价格
销售预测:根据广告投入预测销售额
温度预测:根据历史数据预测未来气温
股票分析:根据时间序列预测股价趋势
当然实际上这些问题一般由多个因素导致,并不是简简单单的就一个变量
如房价的高低不仅仅只和面积有关,能 量化 的还有房屋的新旧程度,房屋的层数有关系,但是我们先从简单的线性回归开始看起,理解后才能学习后面的内容
1. 学习目标
线性回归的核心任务是:找到最优的 w 和 b,使得预测值与真实值之间的误差最小。
2. 损失函数(Loss Function)
如何衡量"误差最小"?我们使用均方误差(MSE, Mean Squared Error):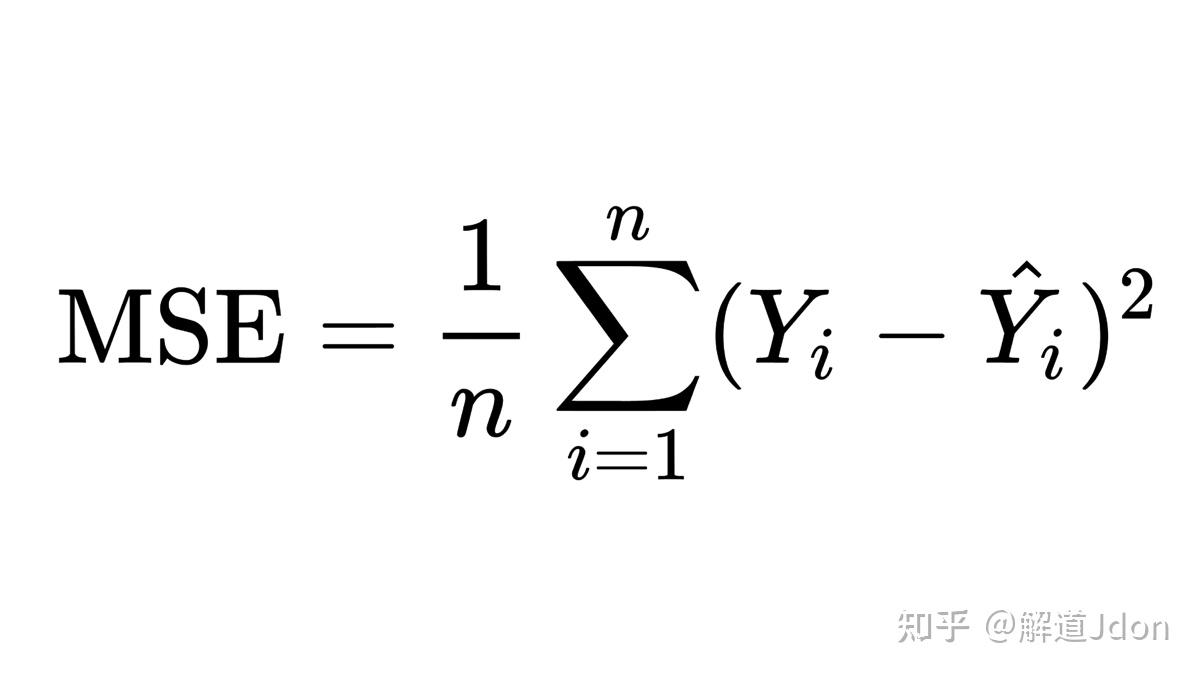
Y i 代表的是实际真实的值, Y i^ 是模型预测的值,相减之后就是实际误差值
那为什么要用平方呢?
是为了三个原因
-消除正负误差的相互抵消
-放大较大误差的影响,使模型更关注异常值
-数学上便于求导优化
3. 优化方法:最小二乘法
Scikit-learn 使用**最小二乘法(Ordinary Least Squares, OLS)**来求解最优参数。该方法通过解析解直接计算出使MSE最小的w和b,无需迭代
进阶知识:对于大规模数据,也可以使用**梯度下降法(Gradient Descent)**进行迭代优化。
实战
Python实战:从零实现线性回归
下面我们通过一个完整的案例一步一步的来演示线性回归的实现过程。
第一步:导入必要的库
import numpy as np # 数值计算库,用于处理数组和数学运算
import matplotlib.pyplot as plt # 绘图库,用于可视化数据
from sklearn.linear_model import LinearRegression # 线性回归模型
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.metrics import mean_squared_error, r2_score # 评估模型的指标
# 设置中文字体支持(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
关键说明:
numpy:提供高效的数组操作和数学函数
matplotlib:可视化工具
sklearn:机器学习库,包含成熟的算法实现
第二步:生成模拟数据
# 设置随机种子,保证每次运行结果相同(可复现)
np.random.seed(42)
# 生成100个0到2之间的随机数作为特征X
X = 2 * np.random.rand(100, 1)
# 生成目标值y,公式为:y = 4 + 3*X + 噪声
# 这是真实的线性关系:截距=4,斜率=3
y = 4 + 3 * X + np.random.randn(100, 1)
说明:
1.这个 42 的作用是给这个随机种子一个编号,下次使用这个编号的时候随机数就不会变了,当然可以改成其他数字
2.为什么要添加噪声?
真实世界的数据很少是完美的线性关系
噪声模拟了测量误差、其他未考虑因素等影响
让模型更具鲁棒性(robustness)
第三步:划分训练集和测试集
# test_size=0.2 表示20%的数据用于测试,80%用于训练
# random_state=42 保证每次划分的结果相同
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"训练集大小: {len(X_train)} 个样本")
print(f"测试集大小: {len(X_test)} 个样本")
为什么要划分数据集?
训练集:用于训练模型,让模型学习数据规律
测试集:用于评估模型性能,检验泛化能力
避免过拟合(Overfitting):模型在训练集上表现好,但在新数据上表现差
第四步:创建并训练模型
# 创建线性回归模型对象
model = LinearRegression()
# 使用训练数据训练模型
# 模型会自动学习最佳的截距(intercept)和系数(coefficient)
model.fit(X_train, y_train)
说明
fit()方法做了什么?
分析训练数据中的X和y的关系
通过最小二乘法计算最优的w和b
将学到的参数保存在模型对象中
第五步:查看模型参数
print("=" * 50)
print("线性回归模型参数")
print("=" * 50)
print(f"截距 (intercept): {model.intercept_[0]:.4f}")
print(f" → 真实值是 4.0000,模型学到的是 {model.intercept_[0]:.4f}")
print(f"系数 (coefficient): {model.coef_[0][0]:.4f}")
print(f" → 真实值是 3.0000,模型学到的是 {model.coef_[0][0]:.4f}")
输出结果显示
==================================================
线性回归模型参数
==================================================
截距 (intercept): 4.1234
→ 真实值是 4.0000,模型学到的是 4.1234
系数 (coefficient): 2.9567
→ 真实值是 3.0000,模型学到的是 2.9567
由于噪声的存在,模型学到的参数不会完全等于真实值,差值越小说明模型精确度越好
第六步:模型预测与评估
# 用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)
# 计算评估指标
mse = mean_squared_error(y_test, y_pred) # 均方误差
r2 = r2_score(y_test, y_pred) # 决定系数
print("=" * 50)
print("模型评估结果")
print("=" * 50)
print(f"均方误差 (MSE): {mse:.4f}")
print(f" → 这个值越小越好,表示预测误差小")
print(f"决定系数 (R²): {r2:.4f}")
print(f" → 这个值越接近1越好,表示模型拟合度高")
核心评估指标详解
均方误差也就是最上图的那个公式
含义:预测值与真实值差异的平方的平均值
特点:对大误差敏感(因为平方)
单位:与目标变量的平方相同
判断标准:越小越好,理想值为0
决定系数(R² Score)暂且不讲,后面会学习到
(如果想直观看到的话,可以做下面这一步)
第七步 可视化图表
# 创建画布
plt.figure(figsize=(10, 6))
# 绘制训练数据的散点图
plt.scatter(X_train, y_train, color='blue', label='训练数据', alpha=0.6)
# 绘制测试数据的散点图
plt.scatter(X_test, y_test, color='green', label='测试数据', alpha=0.6)
# 绘制回归线(模型学到的直线)
X_line = np.linspace(0, 2, 100).reshape(-1, 1) # 生成0到2之间的100个点
y_line = model.predict(X_line)
plt.plot(X_line, y_line, color='red', linewidth=2, label='回归线')
# 添加标签和标题
plt.xlabel('X (特征)', fontsize=12)
plt.ylabel('y (目标值)', fontsize=12)
plt.title('线性回归示例 - 学习直线 y = 3x + 4', fontsize=14)
# 显示图例和网格
plt.legend(loc='upper left')
plt.grid(True, linestyle='--', alpha=0.5)
# 保存并显示图表
plt.tight_layout()
plt.savefig('linear_regression.png', dpi=150, bbox_inches='tight')
plt.show()
如下图
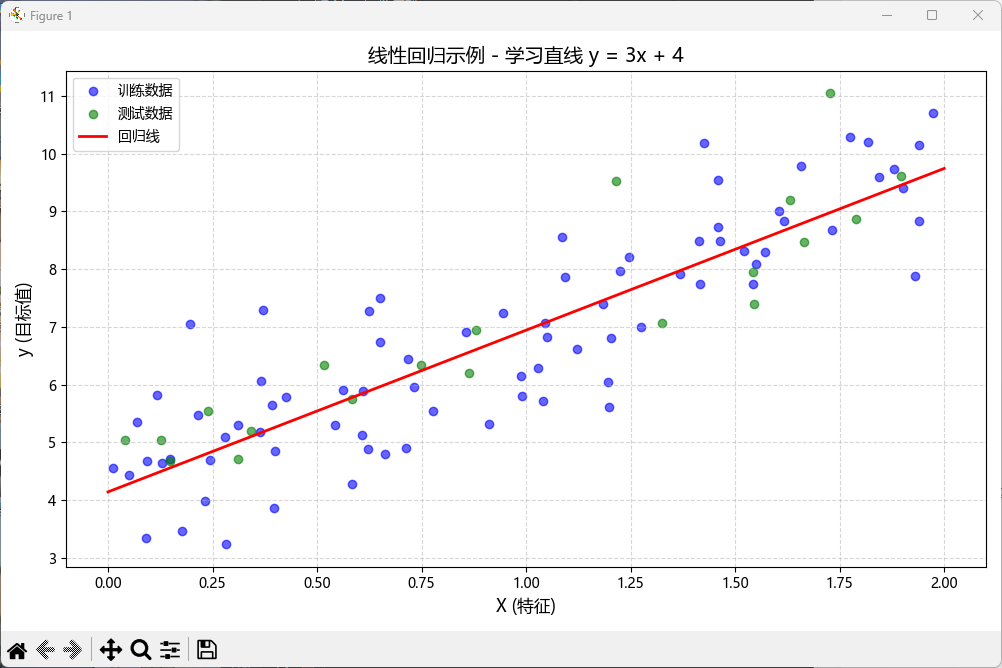
可视化要点:
🔵 蓝色点:训练数据(模型见过的)
🟢 绿色点:测试数据(模型没见过的)
🔴 红线:回归线(模型学到的规律
深入理解:线性回归的优缺点
优点
简单易懂:数学原理直观,易于解释
计算高效:训练速度快,适合大规模数据
可解释性强:每个特征的系数明确表示其重要性
基线模型:可作为复杂模型的对比基准
在线学习:可以增量更新模型
缺点
线性假设:只能捕捉线性关系,无法处理复杂的非线性模式
对异常值敏感:极端值会显著影响回归线
多重共线性:当特征高度相关时,参数估计不稳定
欠拟合风险:对于复杂数据,可能拟合不足
改进技巧下期博客再学习

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)