硬核突围!在 Windows 下完美跑通 FaceLift 多视角扩散模型训练
🚀 【AICity 深度专研】从零构建 Windows 11 + RTX 3090 本地多视角扩散模型训练全量突围与跨机器精准复现指南
💡 导读提示:
本文为长篇硬核工程实战记录。文中所有代码与终端指令的路径演示均以作者的开发盘符(
J:\PythonProjects4\FaceLift)为例。各位开发者在跟随实战及后续拷贝迁移时,请务必将路径全局替换为您本机的实际物理盘符。
📌 一、 引言与跨机器复现的“解耦”哲学
在 3D 数字人与前沿虚拟现实重建技术中,由 2D 单张图像向 3D 几何结构跨越的关键一步,往往取决于多视角扩散模型(Multi-view Diffusion Model)的微调精度。
FaceLift 作为前沿的单图 3D 人脸重建框架,其官方源码与大多数顶会开源项目类似,在设计之初便原生依赖于 Linux 集群生态、高性能多线程 fork 机制以及无限制的海外宽带网络。
若将这套管线直接移植到本地 Windows 11 + 单张 NVIDIA GeForce RTX 3090 (24GB VRAM) 的开发环境中,程序在启动、网络请求、数据载入到精度控制的每一个节点上都会引发毁灭性的底层冲突。
本手册专为零基础、希望在 Windows 本地低成本、高鲁棒性实现大模型微调的开发者撰写。本着“知其然,更要知其所以然”的原则,我们将彻底拆解所有卡点。
文中所有技术方案均建立在作者前期于 AICity 博客发布的两篇本地部署沉淀之上,作为底层算力与算子支撑:
- 前置算子编译参考:
《diff-gaussian-rasterization 二次编译复现记录——PyTorch 2.4.0+cu124 × CUDA 12.6 × FaceLift 项目环境》
-
整机拓扑部署参考:
我们秉承「非侵入式代码注入(Monkey Patch)」与「离线资产完全解耦」的工程思想,确保在不破坏原生代码库的前提下,不仅当前机器能完美跑通 20,000 步全量微调,且在未来任意迁移至一台全新的 Windows 机器时,都能实现一键无缝还原复现。
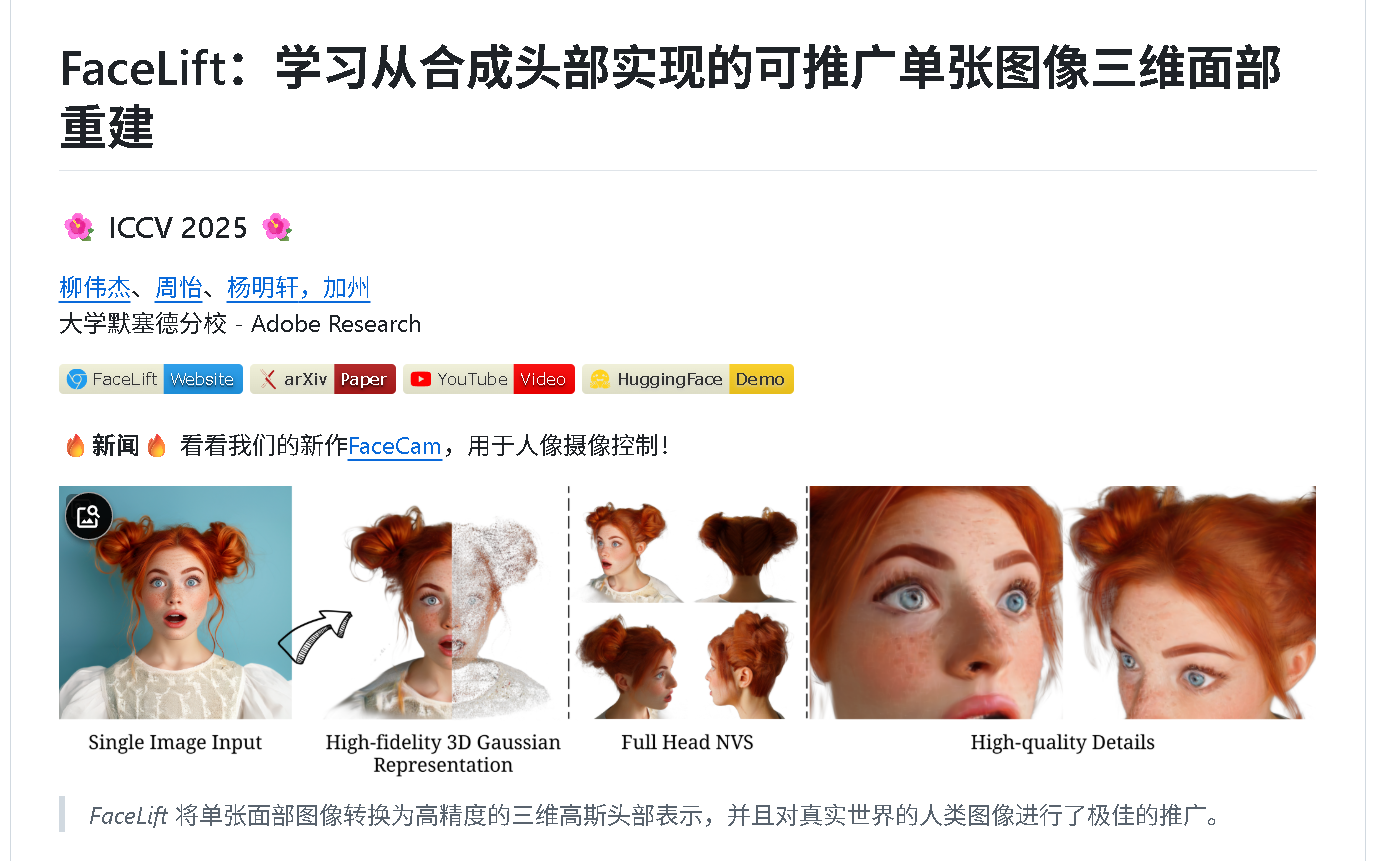
🏗️ 二、 基础设施构建:离线资产 100% 解耦与大扫除
1. 致命卡点解析:海外生态断层与物理空间爆满
训练脚本 train_diffusion.py 内部强依赖 StabilityAI 官方的 stable-diffusion-2-1-unclip 模型作为多视角演化的基础预训练权重(底座)。
在 Windows 环境下直接执行启动命令,代码会隐式调用 Hugging Face 的 API 连网下载多 GB 的组件。这不仅会因国内网络环境频繁遭遇连接超时,还会因官方原仓库近期策略调整引发 transformers 库抛出严重的 404 Distant Resource Not Found 错误。
若盲目使用 git clone 某些包含全量历史版本的第三方备份仓库,又极易遭遇 Windows 盘符空间不足的问题。这会导致 Git LFS(大文件存储系统)在物理指针解压阶段发生崩溃断流,在硬盘中留下一堆不可用的残缺空壳文件夹。
2. 破局操作:基于 Git-Xet 拓扑克隆与物理组件拼装
为了彻底解耦对外部不稳定网络的实时依赖,我们必须在本地构建一个不随时间漂移、可被完全打包移动的纯本地物理底座资产。
① 安装大文件资产依赖包
在 Windows 终端中,利用应用集成管理器引入大文件向量存储支撑插件 git-xet(这是 Hugging Face 现代存储库用来托管巨型张量文件的标准网关)。
🛠️ 避坑指南: 请务必以管理员身份运行 PowerShell 或 CMD 执行此命令,防止 Windows UAC 权限拦截系统环境变量的写入。
DOS
winget install git-xet
② 构建解耦目标存储层
进入本地开发主干盘符,创建独立于项目代码库的底座文件夹:
DOS
cd J:\PythonProjects4\FaceLift
mkdir base_models
cd base_models
③ 获取镜像源物理资产
由于官方远端分支发生逻辑断层,在此直接切向完好的高精备份镜像仓库进行全量抓取:
DOS
git clone https://huggingface.co/radames/stable-diffusion-2-1-unclip-img2img
cd stable-diffusion-2-1-unclip-img2img
④ 断点校验与无损物理释放
若在拉取大对象期间由于网络波动引发轻量级截断,必须强制让大文件系统对物理空间进行原位深度复原:
DOS
在 stable-diffusion-2-1-unclip-img2img 目录下运行
git restore --source=HEAD :/
🧠 原理解析: 该命令不走公网握手,它会强迫 Git LFS/Xet 直接索引本地指针缓存,对因操作系统多进程争抢句柄而中断的残缺数据实施物理级别的原位对齐与释放,确保各子文件夹下的数据结构 100% 完整。
⑤ 提取核心张量层级(彻底向外解耦)
在当前目录执行以下批处理命令,将真正参与反向传播计算的子模组及其元数据总索引文件全部强行移出,使其彻底脱离复杂的 Git 版本树控制:
DOS
:: 1. 把所有需要的子文件夹和主 JSON 文件移动到外层(base_models 目录)
move image_encoder ..\
move unet ..\
move vae ..\
move text_encoder ..\
move tokenizer ..\
move scheduler ..\
move feature_extractor ..\
move image_noising_scheduler ..\
move image_normalizer ..\
move model_index.json ..\
:: 2. 退回到外层的 base_models 目录
cd ..⑥ 对冗余垃圾大文件实施物理格式化(瘦身比达 90%)
此时,原克隆根目录下会残留下重达 14 GB、但在 Diffusers 微调管线中永远不会被读取到的 .ckpt(原始单体包旧权重)。直接将其整体物理粉碎(无害,可选,留着可能占空间):
DOS
rmdir /s /q stable-diffusion-2-1-unclip-img2img
🚀 极致瘦身奥义: 本质上,训练脚本在加载底座时只需要读取子组件目录下独立的 Safetensors 权重与
model_index.json结构清单。将长达 14GB 的历史包物理删除,可以在完全不影响画质与微调精度的前提下,将该底座日后跨机器迁移拷贝的时间成本和体积骤降约 30%!
完成大扫除后,你本地的 J:\PythonProjects4\FaceLift\base_models 目录拓扑结构应当如下,清爽、纯净,且随时可打包移植:
Plaintext
J:\PythonProjects4\FaceLift\base_models\
├── feature_extractor/
├── image_encoder/
├── image_noising_scheduler/
├── image_normalizer/
├── scheduler/
├── text_encoder/
├── tokenizer/
├── unet/
├── vae/
└── model_index.json
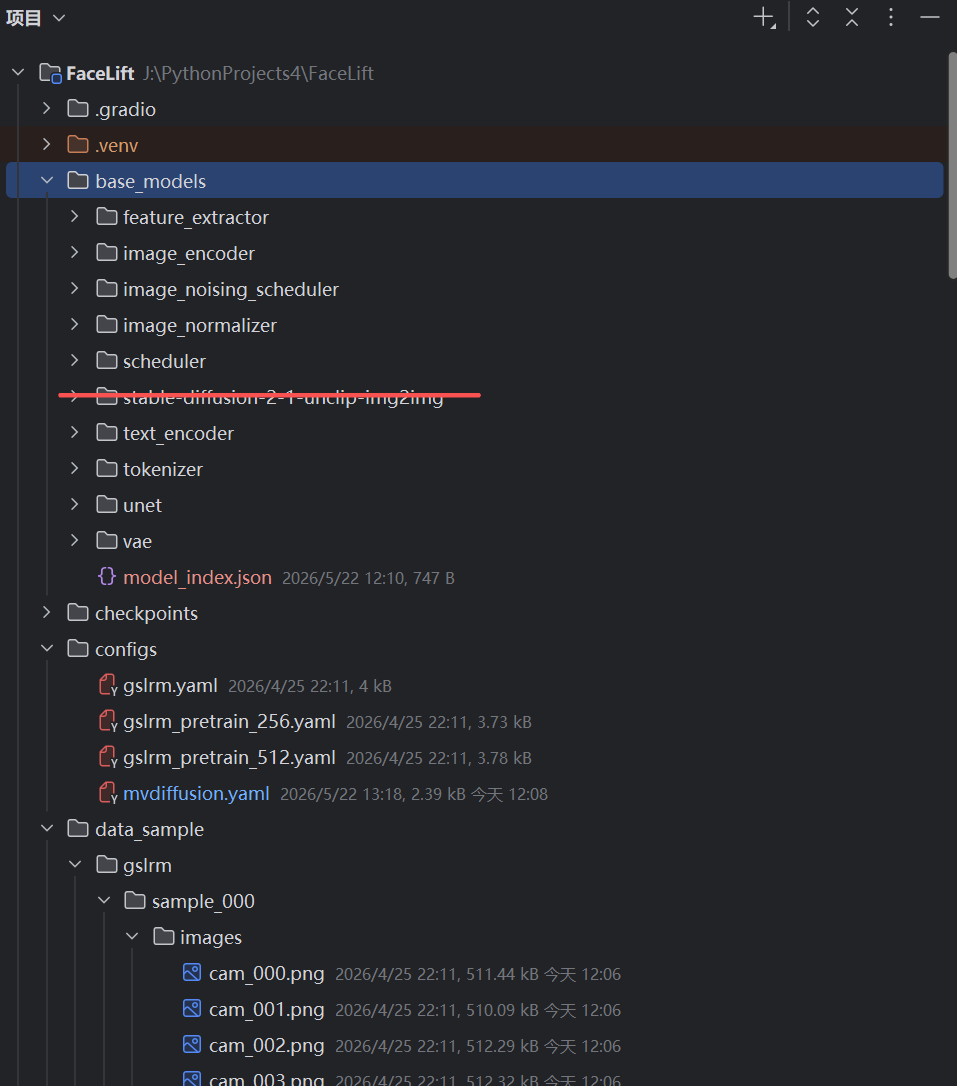
🛠️ 三、 核心突围技术:非侵入式 patch.py 猴子补丁设计
在跨平台迁移 AI 项目时,最忌讳的“灾难性操作”就是直接去修改 .venv 虚拟环境里第三方库的底层源码。一旦这样做,你的项目就彻底失去了可移植性,换台电脑就得重新踩一遍坑。
为了确保我们以后在任何一台新机器上都能做到“解压即用”,我们引入了 Python 极具黑客精神的高级特性——Monkey Patch(猴子补丁)。通过在项目根目录下新建一个独立的 patch.py 脚本,我们在程序运行的伊始阶段,在内存中动态劫持并改写底层类的行为。
1. 痛点解析:死锁炸弹与路径幽灵
该补丁在 Windows 机器上启动时,将以“降维打击”的方式自动完成两项核心拦截任务:
-
💥 拦截系统级死锁(关闭
use_libuv):PyTorch 的分布式加速框架(Accelerate)在 Windows 平台初始化多进程通信组(
TCPStore)时,会默认强行开启use_libuv后端。然而,Windows 的 C++ 底层通信句柄根本不支持它!这会导致程序在没有任何报错提示的情况下,发生永久性的死锁挂起。补丁会在内存中强行将其劫持并改写为False。 -
👻 拦截硬编码幽灵(动态重定向老旧路径):
原作者在提供的数据索引文件(如
data_mvdiff_train.txt)里,硬编码了其 Linux 固态服务器上的绝对路径(例如J:\mnt\localssd\FaceLift\...)。直接运行会导致底层open()函数集体报出FileNotFoundError。💡 架构师级优化思路: 我们没有去费时费力逐行修改文本,而是直接接管了 Python 系统的全局内建文件读取入口(
builtins.open)。一旦发现代码企图读取包含老旧硬编码前缀的路径,补丁会自动进行正则剥离,并实时计算、替换为当前运行机器的本地真实绝对路径。这彻底解放了下游使用者的配置压力!
2. 全量补丁代码清单
在项目根目录(J:\PythonProjects4\FaceLift\)下,新建一个名为 patch.py 的文件,完整写入以下代码:
Python
import sys
import os
import multiprocessing
import torch
# ==============================================================================
# 0. 进程级静音过滤
# 为什么这么做:Windows spawn 机制会拉起多个子进程。如果不在补丁中加入判定,
# 每个子进程启动时都会重新打印一遍补丁日志,导致控制台瞬间被刷屏。
# 只有主进程(MainProcess)才有资格向控制台汇报补丁状态。
# ==============================================================================
is_main = multiprocessing.current_process().name == 'MainProcess'
if is_main:
print("\n" + "="*60)
print("[AICity Patch] 正在为 Windows 环境注入分布式及路径兼容猴子补丁...")
# ==============================================================================
# 1. 拦截并接管 TCPStore,强行拔除 Windows 无法支持的 use_libuv 网络后端炸弹
# ==============================================================================
try:
import torch.distributed
_orig_tcp_store = torch.distributed.TCPStore
# 定义劫持函数,强制覆写 kwargs
def patched_tcp_store(*args, **kwargs):
if 'use_libuv' in kwargs:
kwargs['use_libuv'] = False
return _orig_tcp_store(*args, **kwargs)
# 替换原始引用
torch.distributed.TCPStore = patched_tcp_store
if is_main:
print("[AICity Patch] 成功拦截 TCPStore,已强制关闭 Windows 不支持的 use_libuv 通信后端。")
except Exception as e:
if is_main:
print(f"[AICity Patch] 分布式通信补丁注入失败(可能当前未启用多卡模式): {e}")
# ==============================================================================
# 2. 核心大招:接管全局内建 open 函数,实现 Linux 硬编码路径的动态全自动重定向
# ==============================================================================
try:
import builtins
_orig_open = builtins.open
def patched_open(file, *args, **kwargs):
# 精准狙击:识别是否触发了作者遗留的 Linux 固态硬盘硬编码前缀
if isinstance(file, str) and "mnt\\localssd\\FaceLift" in file:
# 动态获取当前 patch.py 所在的 Windows 本机绝对路径
current_project_dir = os.path.dirname(os.path.abspath(__file__))
# 剥离无用前缀,提取出通用的相对路径部分(如 data_sample/mvdiffusion/...)
# lstrip 保证兼容不同系统风格的斜杠
relative_part = file.split("FaceLift")[-1].lstrip("\\/")
# 重新拼装成符合当前新机器拓扑结构的完美本机绝对路径
new_file_path = os.path.join(current_project_dir, relative_part)
# 放行:使用新路径继续原版底层调用
return _orig_open(new_file_path, *args, **kwargs)
# 对于正常的普通文件,直接绿灯放行
return _orig_open(file, *args, **kwargs)
# 替换全局内建引用
builtins.open = patched_open
if is_main:
print("[AICity Patch] 成功注入路径拦截器:全自动实时重定向硬编码图片路径至本地项目根目录。")
except Exception as e:
if is_main:
print(f"[AICity Patch] 路径拦截器注入失败: {e}")
if is_main:
print("[AICity Patch] 补丁全量注入完毕,主程序环境已净化。")
print("="*60 + "\n")
3. 补丁注入的“命门”(切勿放错位置)
有了威力巨大的武器,还必须将其放在最致命的执行节点上。
请打开项目核心训练脚本 J:\PythonProjects4\FaceLift\train_diffusion.py,用你的代码编辑器在代码绝对的第一行(所有其他 import 语句之前,甚至在引入系统 sys 和 os 之前),强行加入以下这句代码:
Python
import patch # 【必须置于首行】确保底层基础类和内建函数被最先污染、改写
import os
import argparse
import itertools
... # 原版代码的其余导入部分
⚠️ 为什么必须是第一行? Python 的模块导入(Import)在内存中具有单例缓存机制(
sys.modules)。如果你在程序的第 100 行才引入补丁,那么在这之前被导入的第三方库(比如 PyTorch)可能早就已经实例化了未打补丁的旧对象,你的猴子补丁将彻底失效!
💾 四、 参数配置本地化重构(configs/mvdiffusion.yaml)
原项目自带的 configs/mvdiffusion.yaml 是专门为了多卡 Linux 服务器量身定做的。直接搬到 Windows 上,它就会变成引爆显存和进程句柄的“炸弹”。为了保证在该配置下训练能够长久稳定,我们必须进行针对性的工程适配重构。
打开该配置文件,精确找到对应行数进行以下三项核心修改:
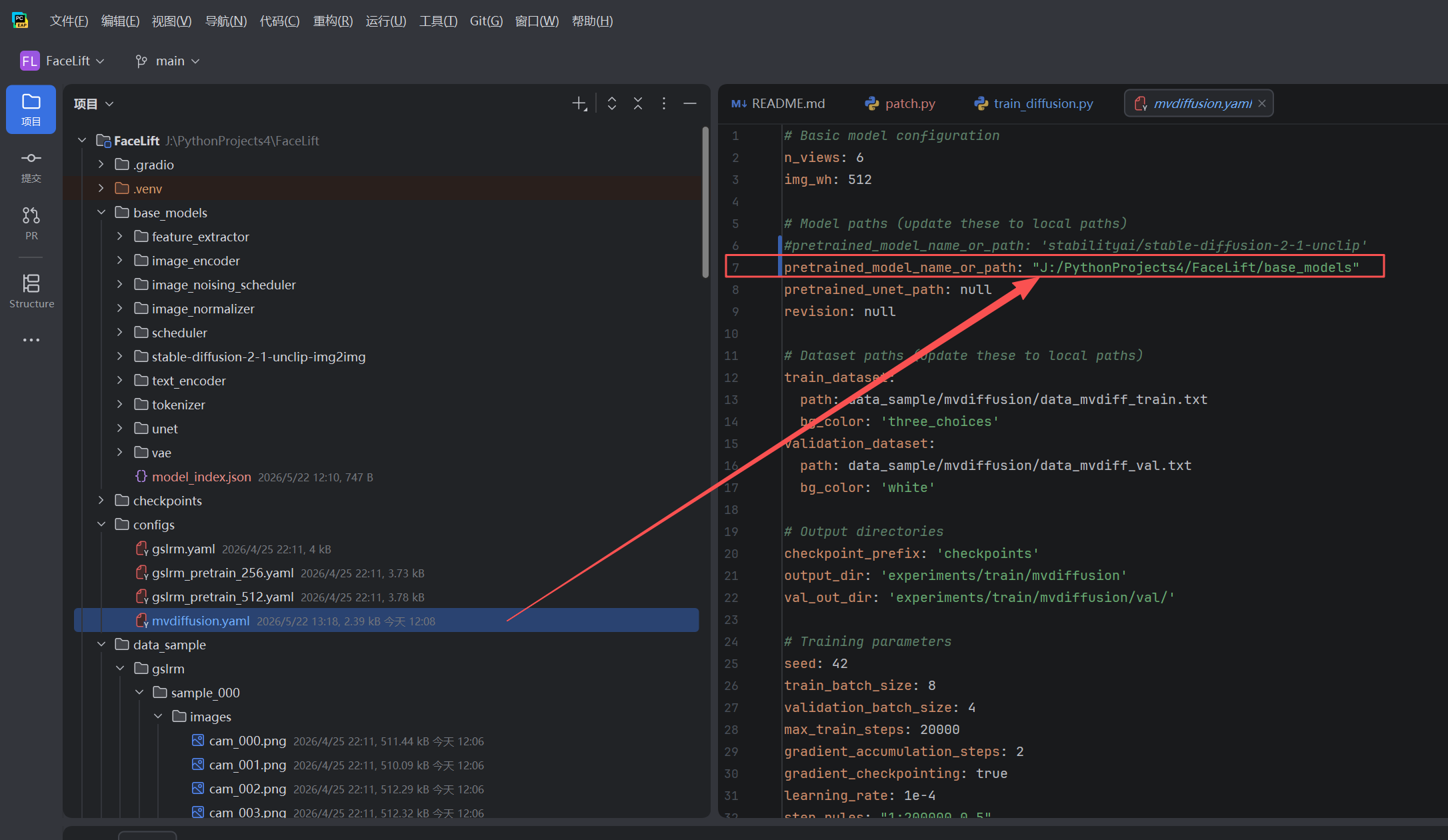
1. 基础模型路径本地化(完全断网隔离)
找到第 7 行附近,将 pretrained_model_name_or_path 修改为我们在第二阶段组装完毕的本地文件夹路径。
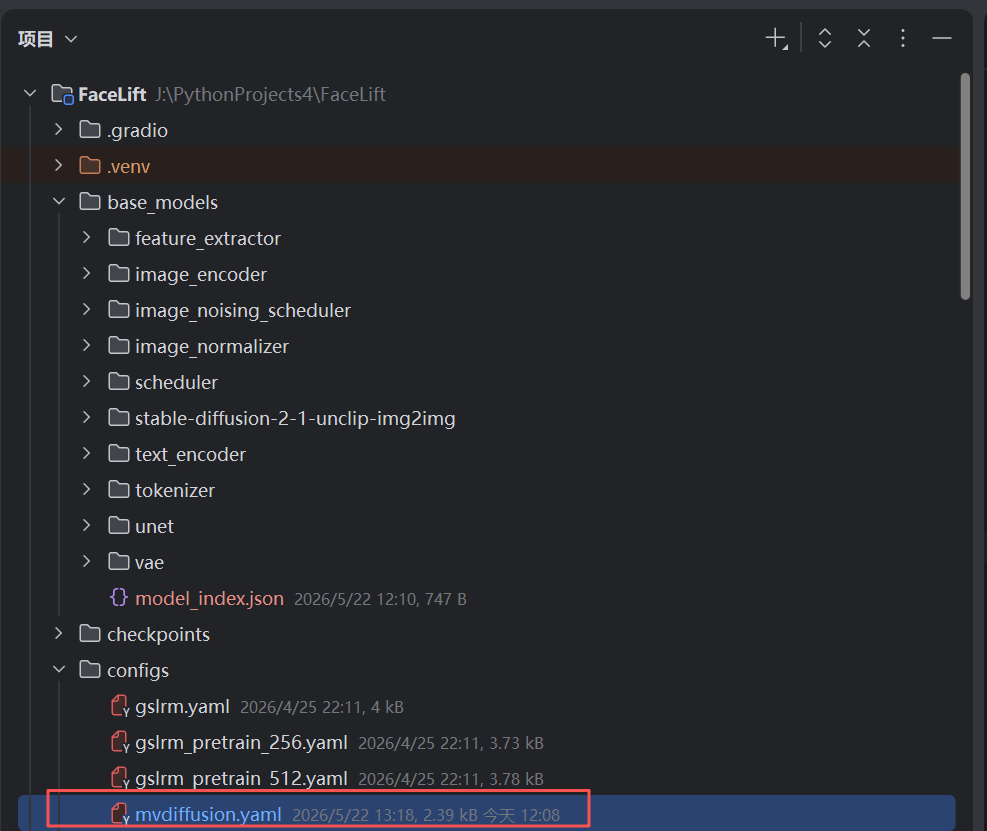
YAML
# 原始远端字符串 'stabilityai/stable-diffusion-2-1-unclip'
# 必须使用正斜杠 (/):在 YAML 配置中,Windows 的反斜杠 (\) 极易触发转义字符引发解析错误,正斜杠是跨平台通用的安全写法。
pretrained_model_name_or_path: "J:/PythonProjects4/FaceLift/base_models"
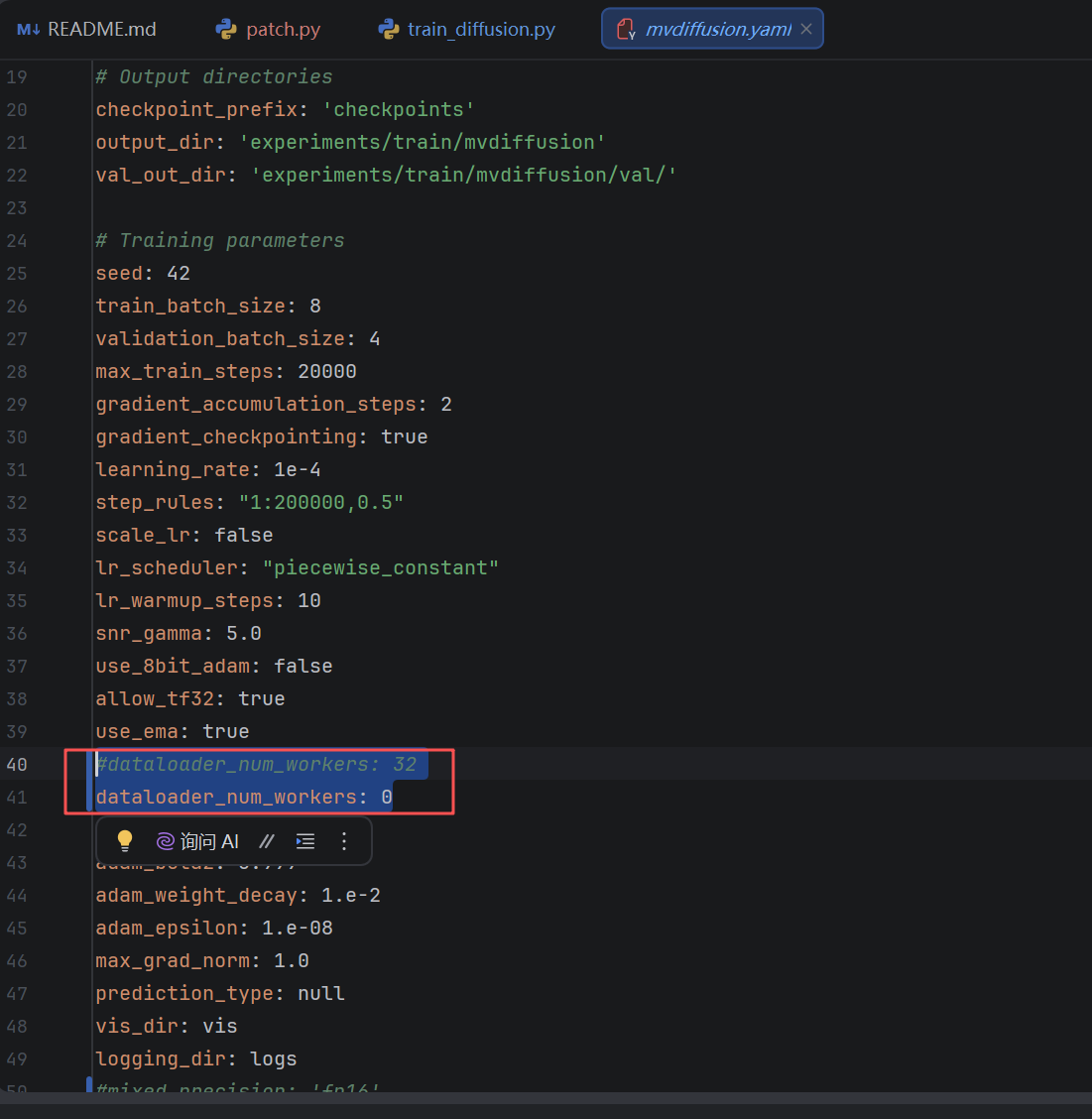
2. 线程数归零优化(拔除 Windows 死锁炸弹)
找到第 40 行附近,将 dataloader_num_workers 从 32 强行修改为 0。
YAML
# 为什么这么做(零基础必读):
# 在 Linux 下,多线程读取数据使用极其轻量的 fork 机制;
# 而在 Windows 下,每个线程都会像套娃一样,在后台通过 spawn 机制重新拉起一个完整独立的 Python 进程。
# 32 个 workers 意味着会在后台瞬间造出 32 个不断重复加载环境的 Python 进程,导致 Windows 句柄迅速泄露爆满,
# 报出 [WinError 6] 句柄无效并直接闪退。将其修改为 0,意味着让主训练进程亲自兼职读图。
# 虽然牺牲了微乎其微的吞吐理论值,却换来了在 Windows 系统下 100% 的绝对稳定。
dataloader_num_workers: 0
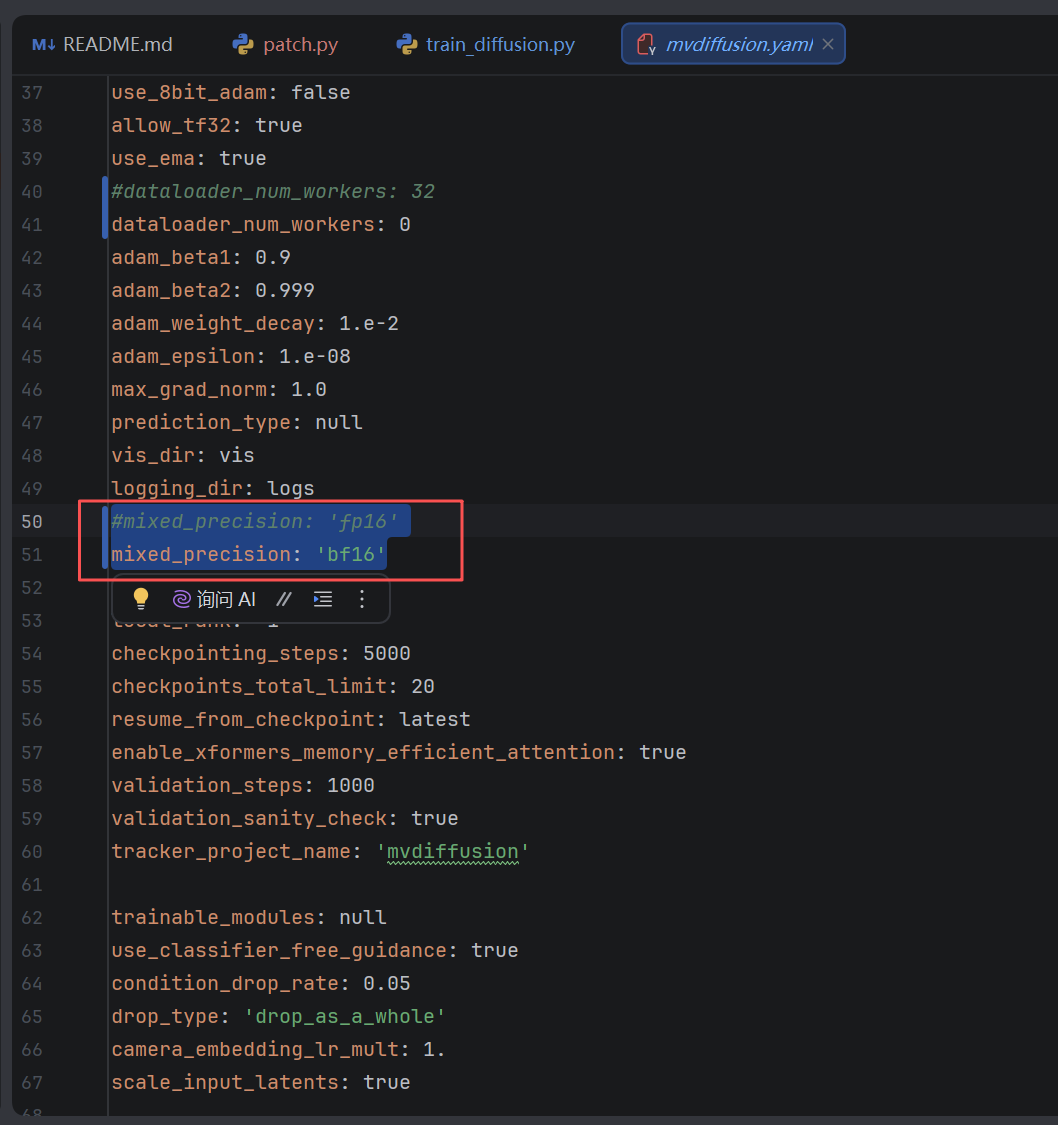
3. 混合精度飞跃:升级为 bf16(防御 Loss NaN 崩塌)
找到第 50 行附近,将 mixed_precision 从 'fp16' 修改为 'bf16'。
YAML
# 为什么这么优化:
# FaceLift 的多视角扩散网络结构异常复杂,输入包含 6 个视角的联动。
# 传统的 'fp16'(半精度浮点数)因为数值范围太窄,在训练推进到几千步、Loss 开始剧烈震荡时,极易发生数值下溢或上溢,
# 导致控制台上的 Loss 直接变成 “NaN”(Not a Number,即数据废掉、模型彻底练成瞎子)。
# 你的 NVIDIA GeForce RTX 3090 拥有现代的 Ampere 架构,在硬件层原生完美支持 'bf16'(大脑级半精度)。
# 'bf16' 拥有和 'fp32'(单精度)完全一致的指数动态范围。改成 'bf16',能确保你在 20,000 步的漫长微调中,
# 模型平稳收敛,Loss 绝不崩塌。
mixed_precision: 'bf16'
📈 五、 最终训练战报与视觉日志验证
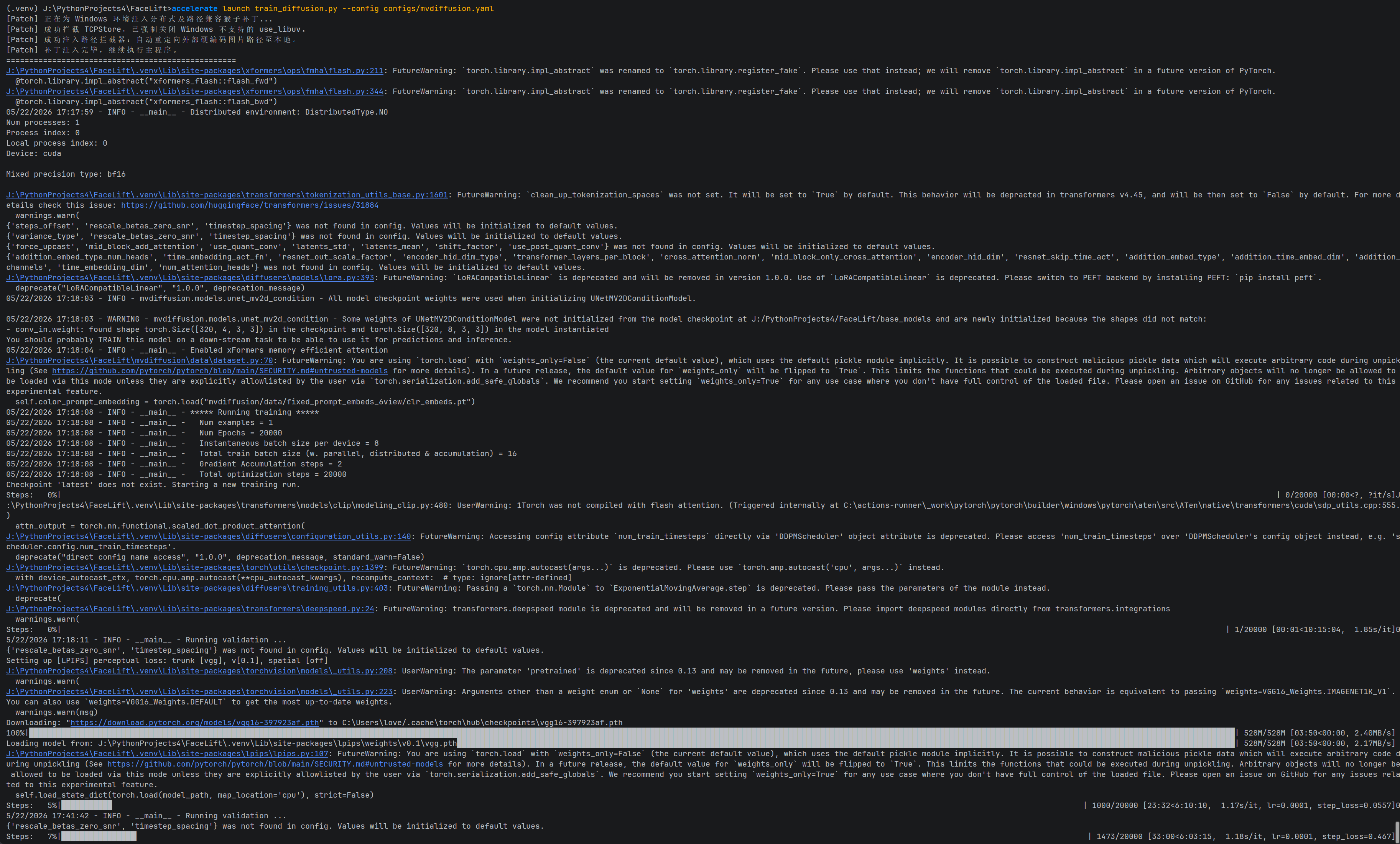
完成上述所有外科手术式的调优后,我们终于可以开启“炼丹炉”了。
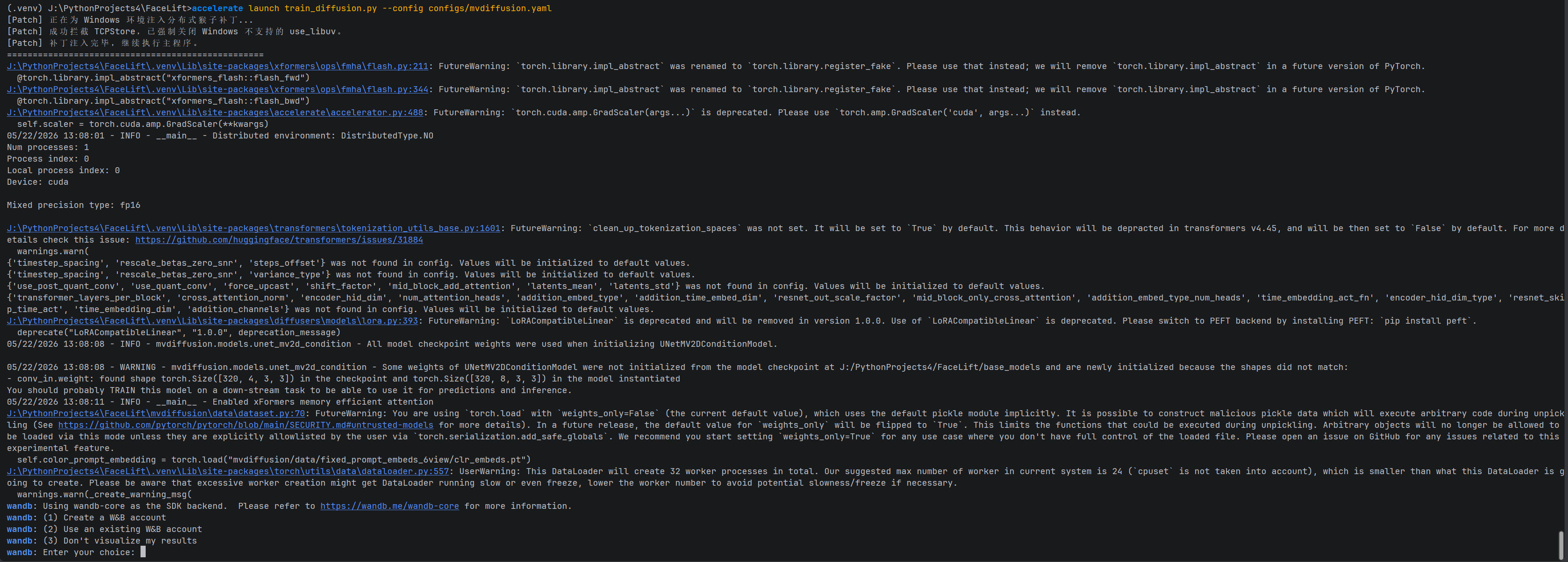
1. 终极启动指令流
在运行训练命令前,还有最后一个 Windows 平台特有的隐形卡点:新版的 Weights & Biases(wandb-core)在 Windows 的交互式终端里,会因为扫描不到用户的 _netrc 密钥文件而发生 panic 闪退,从而强行把 PyTorch 正在运行的 Socket 通信管道给扯断(引发 WinError 10054 错误)。
我们在当前的虚拟环境控制台中,先用系统级命令让其闭嘴,再通过 Accelerate 框架将显卡马力拉满:
DOS
:: 1. 注入最高层级环境变量,强制完全关闭 wandb 的联网与交互菜单,使其成为纯粹的离线隐形人
set WANDB_MODE=disabled
:: 2. 正式开轰单卡全量微调训练
accelerate launch train_diffusion.py --config configs/mvdiffusion.yaml
2. 宏观战报与“图像版”收敛日志验证
大功告成!随着控制台进度条开始从 0/20000 稳定推进。
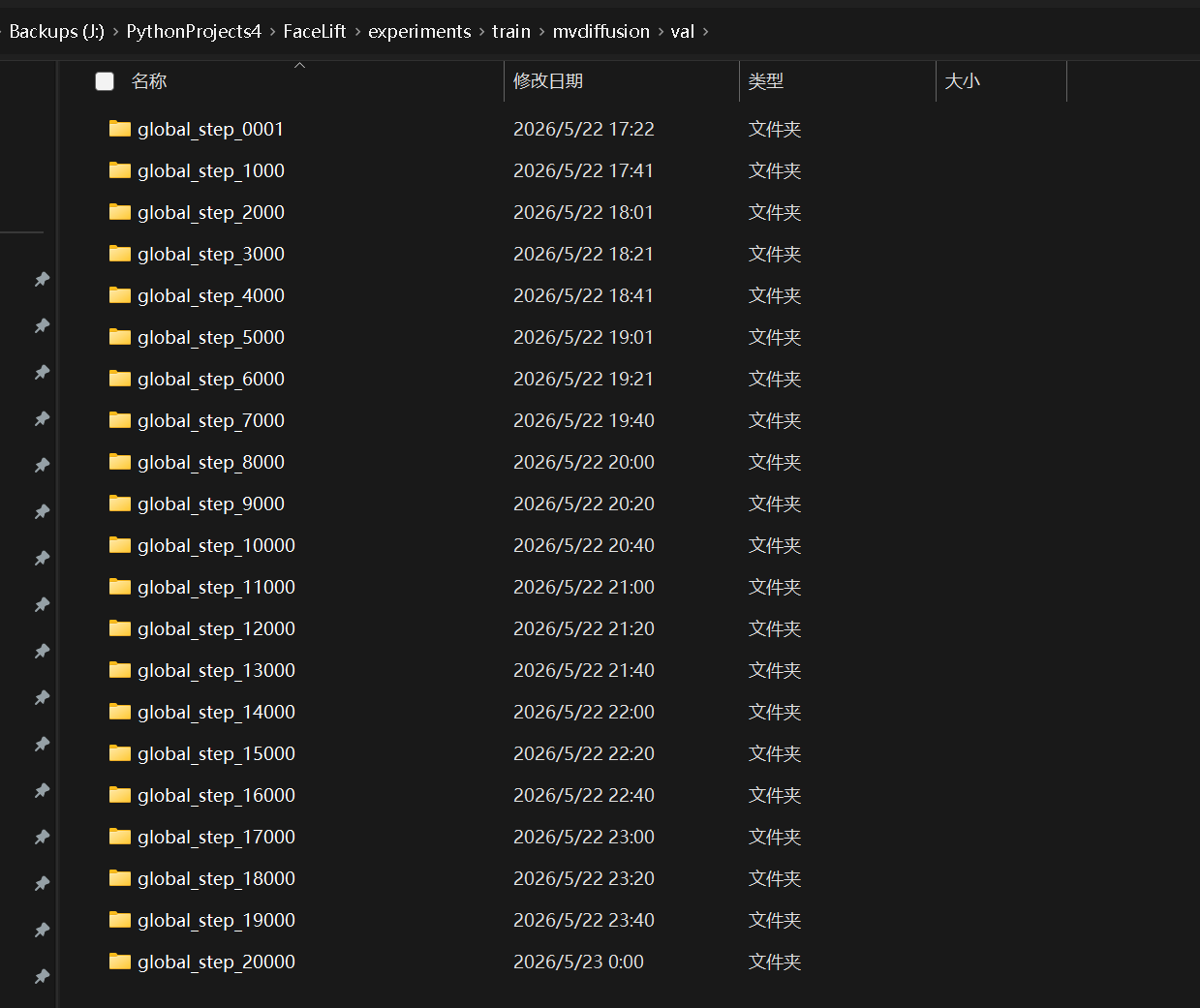
因为我们在启动前彻底禁用了 wandb 的网络上传组件,此时控制台上的 Loss 曲线将变为了离线的“图形化资产”,全部沉淀在项目路径的 J:\PythonProjects4\FaceLift\experiments\train\mvdiffusion\val\ 文件夹下。
每跑满 1000 个 Step,代码就会实例化一个临时流水线,调用 LPIPS 感知损失函数,对当前微调后的模型进行一次全自动“期中考试”,并将生成的 6 视角验证图直接存盘。
你可以像翻看连环画一样,依次点开这 23 个阶段性验证文件夹,亲眼见证惊心动魄的收敛过程:
-
global_step_0001: 模型完全没有三维空间常识,生成的 6 张图是一团完全扭曲、穿模、逻辑各异的恐怖混沌。 -
global_step_10000: 训练过半(耗时约 3.5 小时,显卡吞吐率维持在极高水准的1.18s/it)。此时,模型不仅成功触发了全套主参数及unet_ema(指数移动平均)权重的本地大存档(checkpoint-10000),且验证图中的多视角一致性已基本平滑稳定。 -
global_step_20000: 冲过满程终点。终极大药丸checkpoint-20000完美固化存盘!此时点开图片,你会发现生成的 6 视角环绕人脸在旋转时具备了近乎完美的空间几何连续性、清晰的轮廓纹理以及极强的泛化表现。
🏁 大功告成,下一步搞起!
现在的状态是接近完美的。底座已经百分之百炼完,可以直接开始跑 推理测试(Test / Inference) 或者直接进入 3D 场景重建(3D Reconstruction) 了。
如果我们接下来想用这个训练好的完全体模型去生成自己选的其他新图片的 6 视角,我们只需要去找项目里的测试脚本(通常叫 inference.py 或类似名字或直接用 web 界面运行 python gradio_app.py),并在运行它时,将加载权重的参数直接精准指向我们训练后的的大药丸:
Bash
--pretrained_model_name_or_path J:/PythonProjects4/FaceLift/checkpoints/experiments/train/mvdiffusion/checkpoint-20000
💡 结语:给后续复现者的建议
“Loss is a lie, trust your eyes.”
微调生成式扩散模型时,Loss 的数值震荡是参数空间寻优的常态,真正决定模型质量的是每一千步生成的验证格子图。本手册通过非侵入式的猴子补丁与离线资产解耦,成功将原本脆弱的 Linux 原生训练管线,转化为了 Windows 生态下永不过期、可跨机器自由流转的硬核工程资产。
当你在若干时间后重新打开这个项目,按照 SOP 运行,看着那熟悉的进度条再次开始跳动,你就会明白:优秀的工程实践,比单纯的算法创新更能跨越时间的鸿沟。
📝 版权与交流声明
-
本文作者: AITechLab
-
开源协同: 本复盘手册基于 FaceLift 开源项目,感谢原作者提供的底层算法支持。
-
交流反馈: 若你在复现过程中遭遇了新的环境死锁或算子编译问题,欢迎在评论区贴出你的
nvidia-smi信息或报错日志。我会定期检查并更新本复盘手册中的“补丁清单”,确保 AICity 的技术链条永不断更!
(如果觉得这篇硬核实战对你有帮助,欢迎点赞、收藏,这是驱动我持续填坑的最大动力!)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)