大模型结构学习
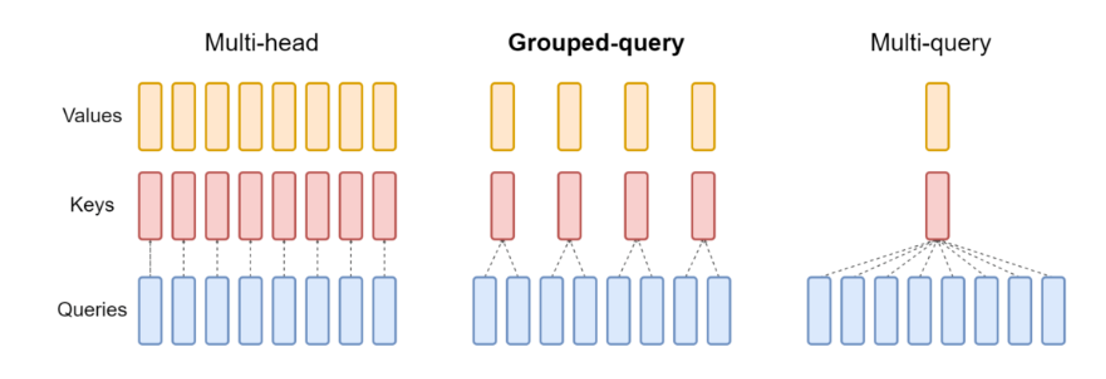
在transformer中经常做的改为 multi-head共享
过embedding层会得到 L*h的矩阵,为了得到Q、K、V,通常会将 L × h 的矩阵分别乘以 三个不同的权重矩阵 WQ,WK,WV,每个权重矩阵的尺寸是 h × h(假设保持维度不变)。
这样,三个结果分别都是 L × h 的矩阵。然后 Q*K.T得到L*L的attention矩阵。在这个过程中,人们发现K,V线性层不需要这么大,少一点,也能达到类似的效果
Multi-query:
人们为了减少运算量,K,V就不用 h*h了,用 h* h/12 这里的12是头数,一般的多头机制,bert为12,所以用12了就,然后就是 L*h/12,然后在计算注意力时,把这个
L × 64的 K 复制 12 份,让每个头的 Q 都能和它做点积但是由于参数量减少,速度虽然提升了,但效果也减少了,为了找到一个折中的方法就是Grouped-query
Grouped-query:
Multi-head中,k,v 和Q一样,Multi-query则是保持一份,这个则是保证一定比例,兼顾效果和速度
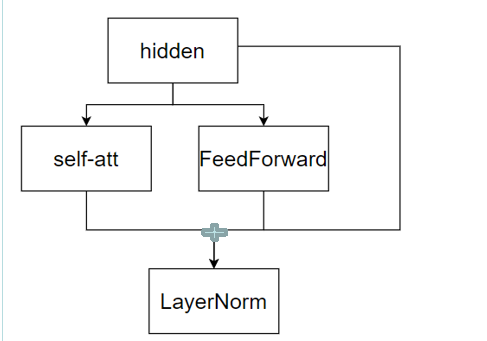
attention结构
GPTJ结构,平行放置attention layer 和feed forward layer
moss,palm用的这种结构,目前不算太主流
传统transformerblock
这个就是 hidden,就是attention,然后和做残差 (x+Attention(x)),然后归一化,就是+代表残差
y = x + MLP(LayerNorm(x+Attention(LayerNorm(x))))
GPTJ方式减少运算量
y =x + MLP(LayerNorm(x)) + Attention(LayerNorm(x))
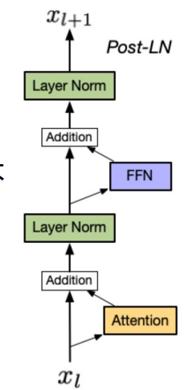
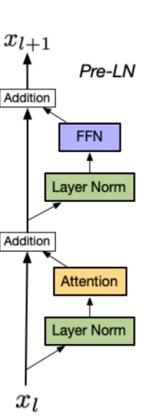
归一化层位置选择
Post LN: layer norm 在残差链接之后
使用post-LN的深层transformer容易出现训练不稳定的问题
Pre-LN: layer norm 在残差链接中
相对比Post-LN,使用Pre-LN的深层transformer训练更稳定,可以缓解训练不稳定问题
相比于Post-LN,Pre-LN的模型效果略差
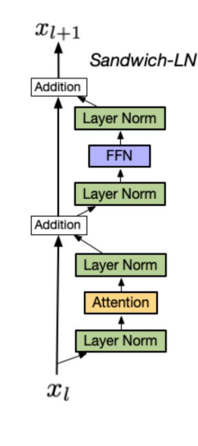
Sandwich-LN:在pre-LN的基础上,额外插入了一个layer norm
Cogview用来避免值爆炸的问题
缺点: 训练不稳定,可能会导致训练崩溃
归一化层的计算方式
常见的归一化层 LayerNorm
RMSNorm
目前主流做法是将Norm层提前到attention之前
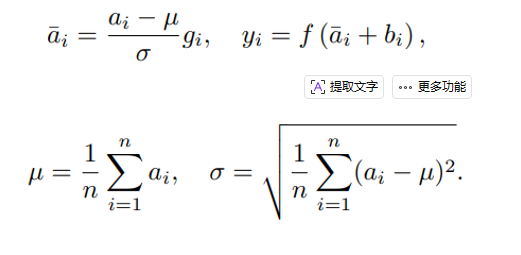

激活函数
最初的transformer中用的relu,bert则是gelu,在tranformer和bert中激活函数在Feeforward里
输入 (d_model) → 线性层1 → 激活函数 → 线性层2 → 输出 (d_model)
↑ ↑
扩大 4倍 缩回 d_model
(d_ff)
目前主流是Swish

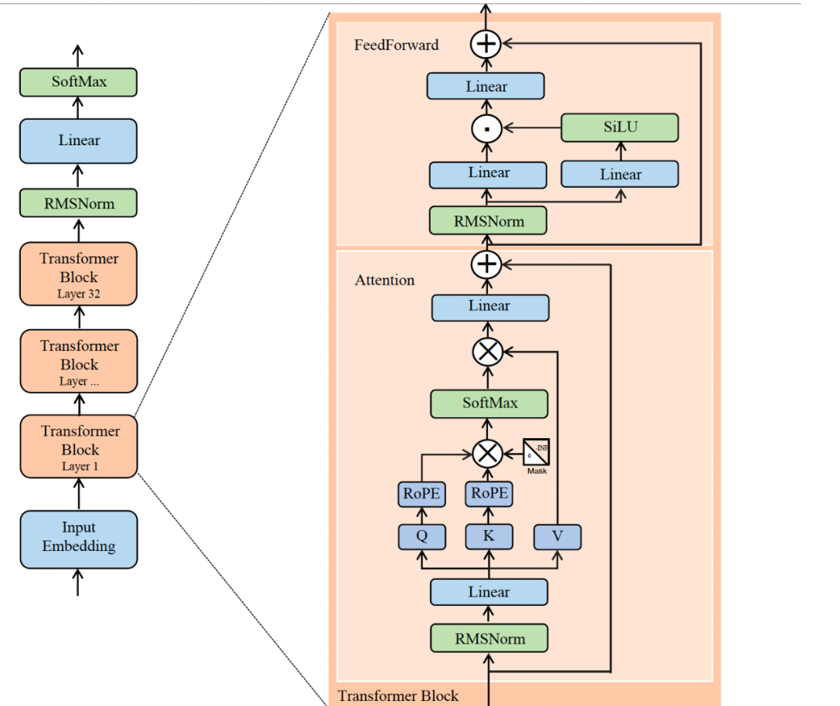
LLama2结构
SiLU说的是Swish激活函数
这个里面最常用的FeedForward
归一化层RMSNorm,然后分开过Linear层,transformer里面的linear是h*4h,不过后来发现4h有点冗余,就改成1.5h,然后跟过激活函数 swish的点积,然后再过Linear这里的(1.5h,h)然后进行残差
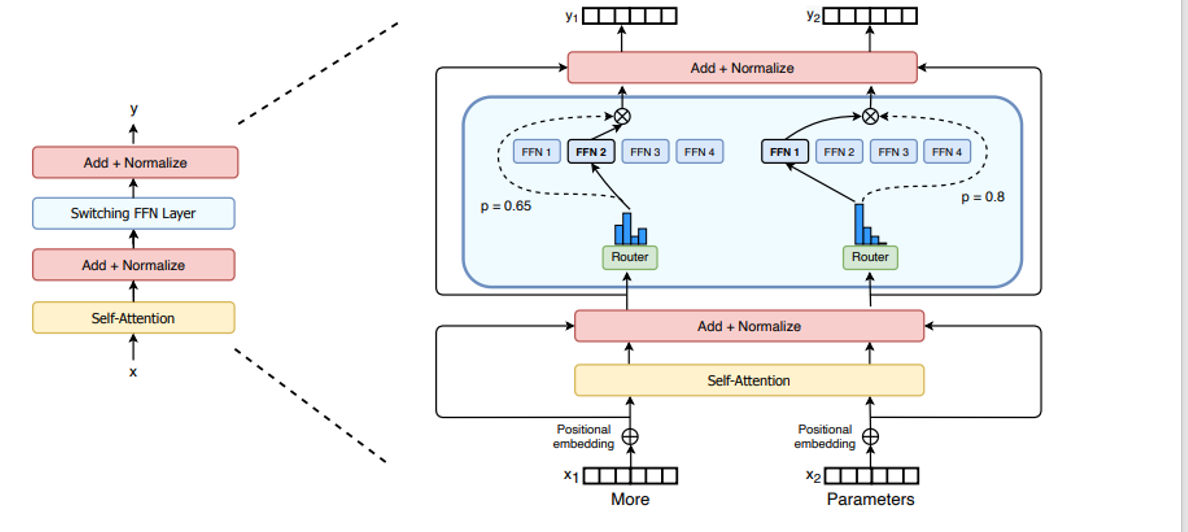
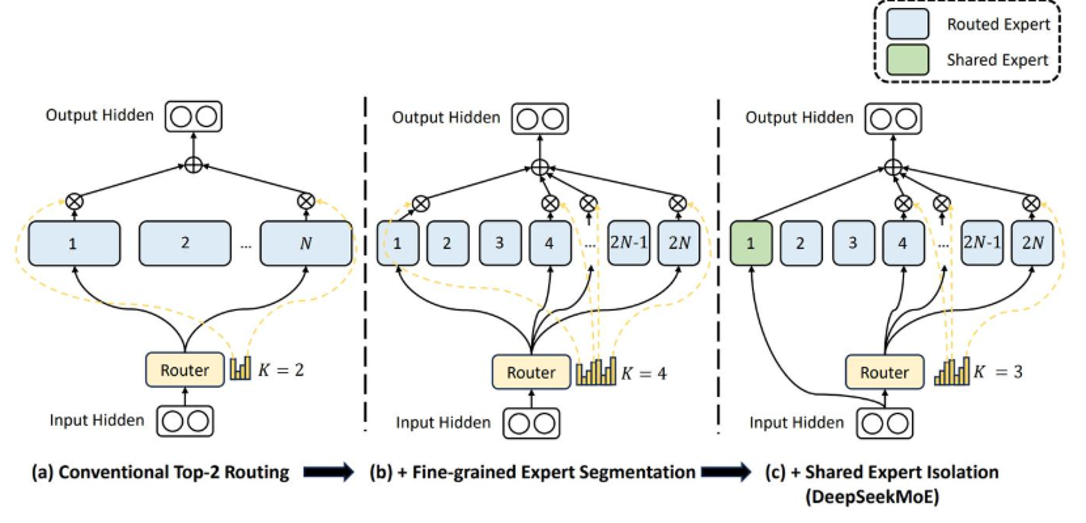
MoE架构 混合专家模型
deepseek有的版本就是MoE结构
MoE的改变主要是FeedForward上的改变
准备了很多FeedForward层,权重是独立的,如图所示有4个FeedForward层,从4个里面根据权重选一个,把每个FeedForward层称为以个专家,这也是名字的由来
另外还可以是一个输出可以由多个专家的输出根据权重结合起来一起输出
DeepSeek Moe
相比于Moe架构,增加了共享专家,总是会使用这个'专家'进行计算,其余的按照传统moe方式由模型自己挑选
位置编码和长度外推性
为何需要位置编码
由于transformer中使用的都是线性层,编码过程中没有明显的位置信息
字符位置的交换,仅相当于矩阵中行位置的交换
这带来并行计算的优势,但是也弱化了语序信息
因此需要引入位置编码来弥补

什么叫长度外推性
预测时序列长度比训练时候长,模型依然有好的表现,称为有较好的长度外推性
比如:
训练样本最大长度 512
预测过程输入样本长度 1024
长度外推性是一种理想的性质,并非是必要的
目前主流位置编码
| 模型 | 位置编码 |
| 原始Transformer | 正余弦位置编码 |
| Bert | 可学习位置编码 |
| ChatGLM,LLama | RoPE位置编码 |
| Baichuan 13B,Bloom | Alibi位置编码 |
正余弦位置编码

最右边的那4*4矩阵是怎么来的, i=0,i=0,i=1,i=1 这就是公式中pos说的不是在句子中的位置实在向量中位置,比如每个字把它分成4个字,那么就是上图
可学习位置编码
一般称为position embedding,以Bert为代表
如同token embedding 一样,随机初始化后,靠梯度反传学习调整缺点在于无法外推,需要预设最大长度
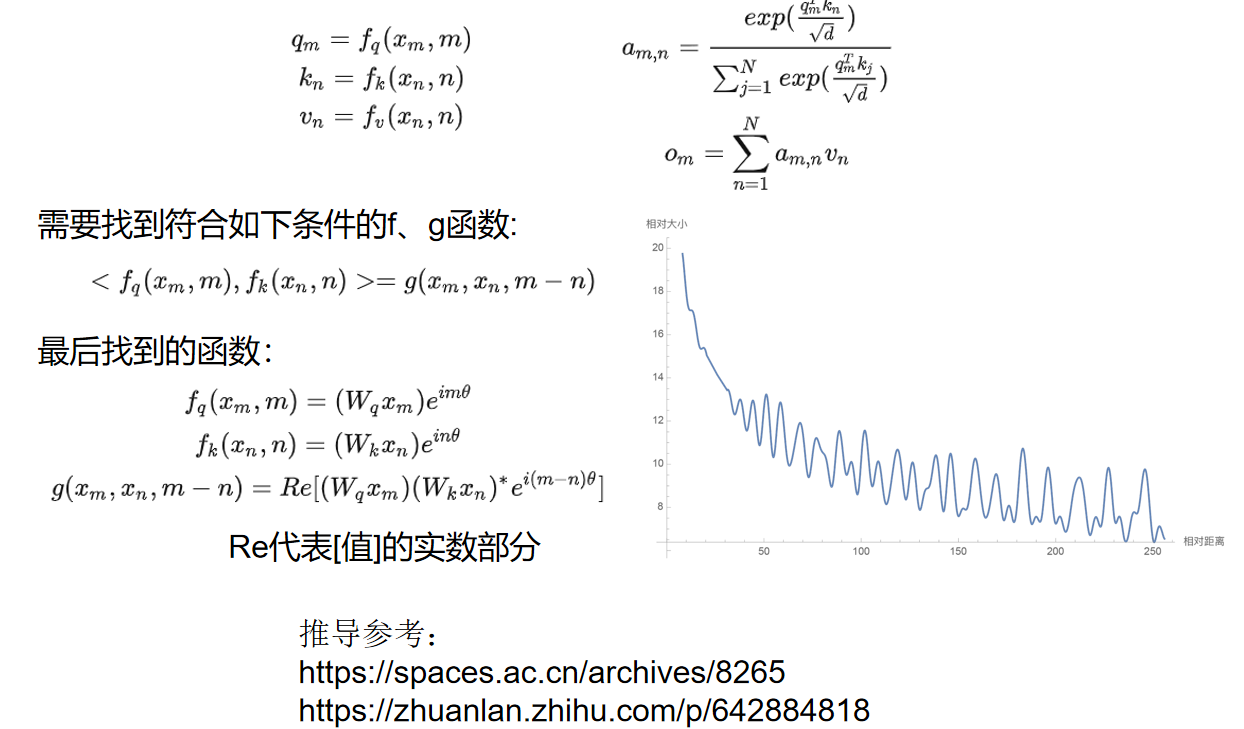
ROPE相对位置编码
Alibi位置编码
为了防止m固定影响模型的学习,所以m的头多机制每个m选不同的值

正余弦位置编码和可学习位置编码则是通过改变数值
这里其实ROPE与Alibi相似,都是与位置差有关,而ROPE做的是映射到一个函数,Alibi则是强行乘上一个位置差矩阵
投机采样加速推理
大模型推理慢,主要是因为参数量太多,运算量很大
一次输入多个token,进行并行运算
但是没办法一次给大模型那么多token,因为答案是一个词一个词生成出来的,每次生成一个,加在原来句子的后面进行重新计算,再次计算下一个
那么我们可以先用小模型打草稿
先让小模型预测出后面5,6个字,然后连起来一起送给大模型,但是有可能因为小模型较差,小模型预测的不对,
假如小模型比较差,小模型预测的第6个和大模型预测的第6个不一样,那么把大模型哪个补到原句后面,再送给小模型
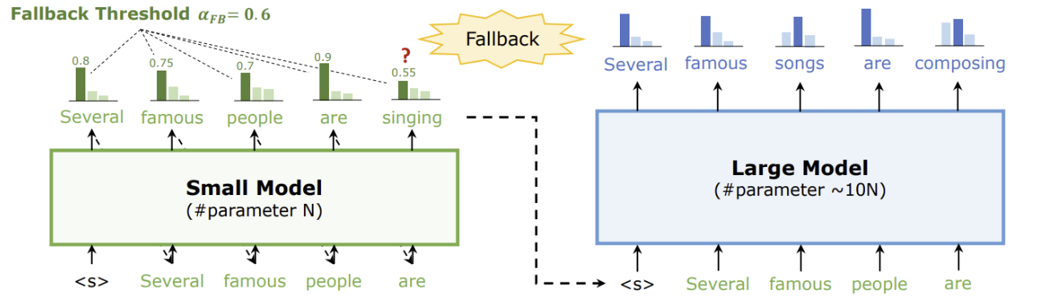
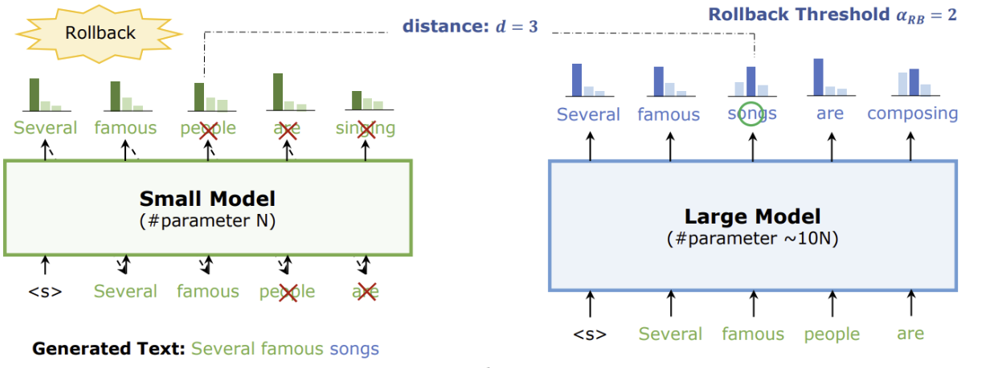
如果小模型效果很差,起不到加速的效果,所以投机采样的瓶颈在于小模型
那么能不能让大模型给自己打草稿?现在提出的美杜莎思想
模型自带多个头,代替small model 起到打草稿的目的
正常大模型,输出两个token,预测出下一个token,美杜莎多个头,一个头可以预测下个token,另一个头,预测下下个token,但是生成y4没有看到y3,依旧无法保证正确性
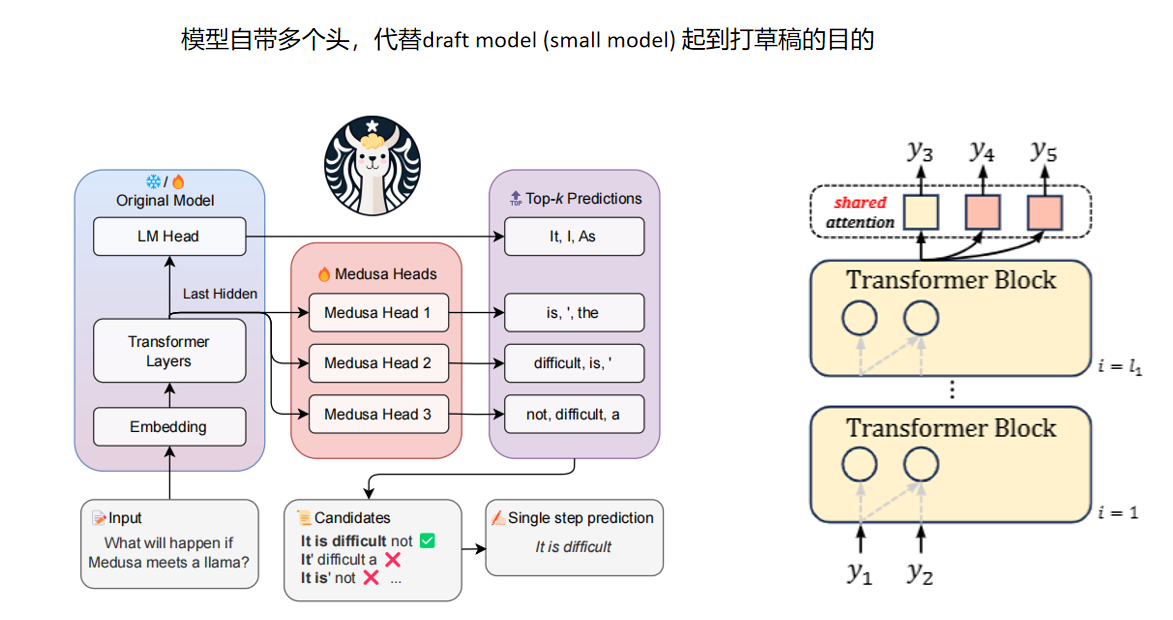
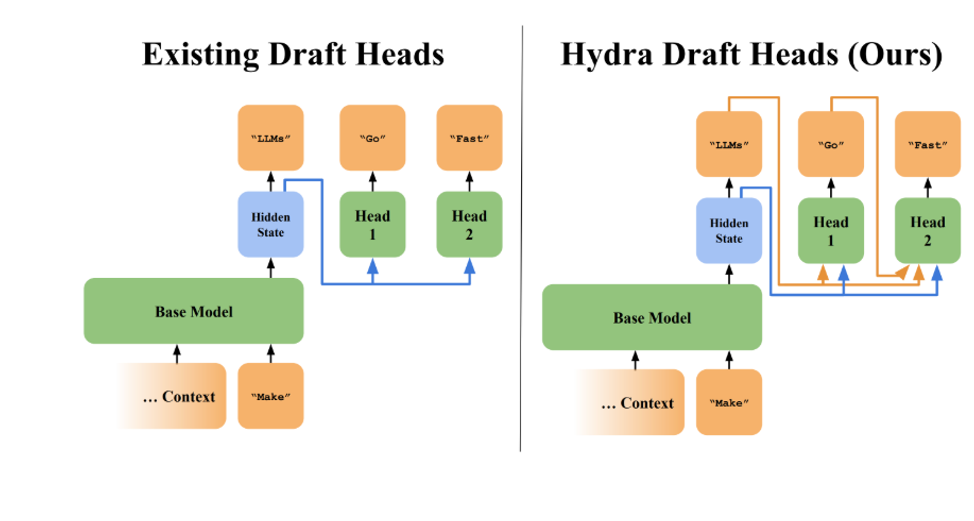
前一个头的输出,作为后一个头的输入的一部分
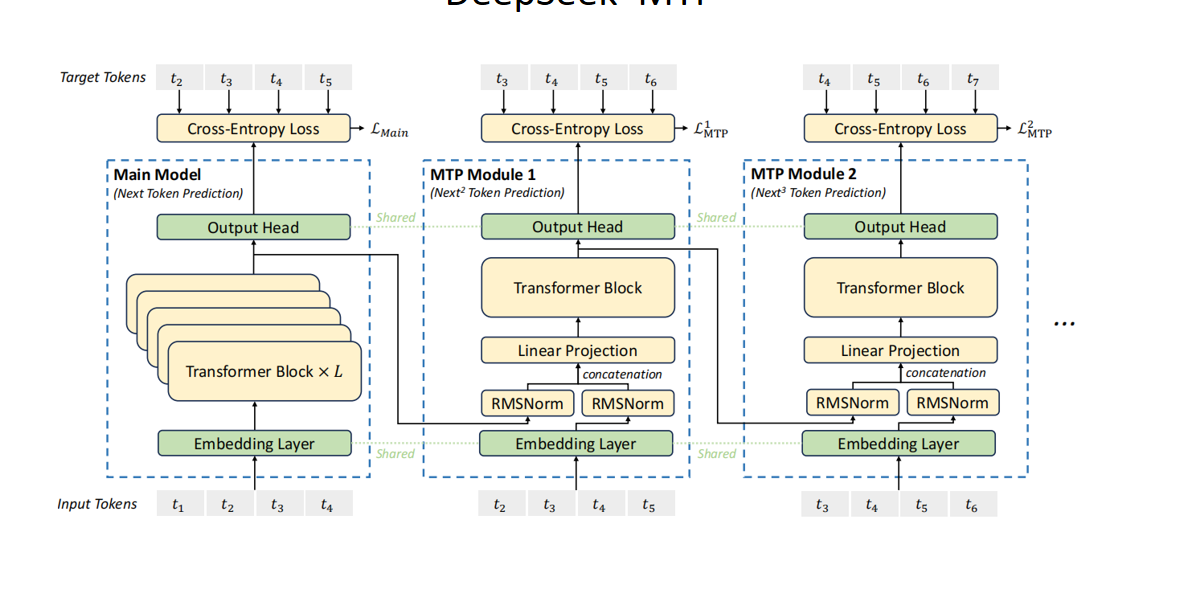
正常情况下,新生成的一个token假如第三个加到原来的后面,再次输出给模型,再次预测出第四个 图中右边,则是不在加到后面,加到模型预测的结果上,减少了计算量
Deepseek MTP

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)