计算机毕业设计hadoop+spark+hive空气质量预测系统 空气质量大数据分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
论文|基于Hadoop+Spark+Hive空气质量预测系统设计与实现
基于Hadoop+Spark+Hive空气质量预测系统设计与实现
摘要
针对传统空气质量数据分析方式存在存储容量有限、海量数据处理效率低、数据治理混乱、预测精度不足、实时性差等问题,本文基于大数据生态技术,设计并实现了一套集数据存储、数据治理、大数据分析、智能预测、可视化展示于一体的空气质量预测系统。系统以Hadoop分布式框架实现海量空气质量时序数据存储,依托Hive数据仓库完成多层数据分层治理,利用Spark高速内存计算框架实现海量数据清洗、特征工程与相关性分析,结合Spark MLlib机器学习算法构建空气质量预测模型,实现对PM2.5、PM10、空气质量等级的智能预测。本文详细阐述了系统研究背景、技术架构、模块设计、核心代码、模型训练与系统测试全过程。测试结果表明,本系统能够高效处理海量空气质量监测数据,数据处理速度远优于传统单机架构,预测模型具备良好的拟合效果与泛化能力,可精准预判空气质量变化趋势。系统稳定性强、拓展性高,能够为城市环境治理、大气污染预警、公众健康防护提供有效的数据支撑与技术参考,具备较高的实际应用价值与工程落地价值。
关键词:Hadoop;Spark;Hive;大数据;空气质量预测;机器学习;数据仓库
Abstract
Aiming at the problems of limited storage capacity, low processing efficiency of massive data, chaotic data governance, insufficient prediction accuracy and poor real-time performance in traditional air quality data analysis methods, this paper designs and implements an integrated air quality prediction system based on big data ecological technology, which integrates data storage, data governance, big data analysis, intelligent prediction and visual display. The system uses the Hadoop distributed framework to store massive air quality time-series data, relies on Hive data warehouse to complete multi-layer data governance, uses the Spark high-speed memory computing framework to realize massive data cleaning, feature engineering and correlation analysis, and combines Spark MLlib machine learning algorithms to build an air quality prediction model to intelligently predict PM2.5, PM10 and air quality levels. This paper elaborates the whole process of the system research background, technical architecture, module design, core code, model training and system testing. The test results show that the system can efficiently process massive air quality monitoring data, and the data processing speed is much better than the traditional stand-alone architecture. The prediction model has good fitting effect and generalization ability, and can accurately predict the trend of air quality changes. The system has strong stability and high scalability, which can provide effective data support and technical reference for urban environmental governance, air pollution early warning and public health protection, and has high practical application value and engineering landing value.
Key words: Hadoop; Spark; Hive; Big Data; Air Quality Prediction; Machine Learning; Data Warehouse
第一章 绪论
1.1 研究背景
随着我国城市化与工业化进程持续推进,工业废气、机动车尾气、建筑扬尘等污染源不断增加,大气环境污染问题日益突出,空气质量变化直接影响城市生态环境与居民身体健康。现阶段,全国各大城市已搭建常态化空气质量监测站点,全天候采集PM2.5、PM10、SO₂、NO₂、CO、O₃及温湿度、风速等多维监测数据,积累了海量时序环境大数据。
传统空气质量研究多采用单机架构与传统统计分析模型,存在明显短板:单机存储算力有限,无法承载海量时序大数据;数据清洗与统计分析效率低下,无法实现批量迭代计算;数据缺乏标准化治理,数据复用性差;传统模型难以捕捉多因子耦合的非线性变化规律,预测精度低、滞后性严重。随着大数据技术快速发展,Hadoop、Hive、Spark生态日趋成熟,为海量环境数据的分布式存储、分层治理、高速计算与智能建模提供了全新解决方案。基于此,本文搭建大数据空气质量预测系统,实现空气质量数据全流程智能化处理与精准预测。
1.2 研究意义
(1)理论意义
本研究将Hadoop分布式存储、Hive数仓分层治理、Spark高速计算与机器学习预测技术深度融合,构建了完整的环境大数据处理与智能预测体系,完善了大数据生态在环境监测领域的应用研究。通过时序数据特征挖掘、多模型对比调优,探索了大数据场景下空气质量非线性预测的优化方法,为同类环境大数据分析、时序数据智能预测研究提供了标准化理论参考与技术范式。
(2)实际意义
本系统能够实现海量空气质量数据的高效存储、标准化治理、多维统计分析与精准智能预测,可精准挖掘污染物变化规律与气象影响因子关联特征。一方面可为环保部门开展污染源溯源、空气质量预警、城市环境综合治理提供数据支撑;另一方面可为公众出行、户外作业、健康防护提供直观的空气质量预判依据。系统轻量化、高稳定、易拓展,工程落地性强,具备良好的实用价值与推广价值。
1.3 国内外研究现状
国外环境大数据与空气质量预测研究起步较早,欧美等发达国家已建成全域环境监测大数据平台,率先将Hadoop、Spark分布式技术应用于海量环境数据处理,同时依托深度学习算法实现高精度时序预测。但其研究体系适配海外地域气候与污染源特征,本土化适配性差,且商用平台成本高、闭源不通用。
国内环境监测体系完善,积累了海量空气质量时序数据,众多学者围绕空气质量预测开展大量研究。目前国内研究已逐步引入大数据与机器学习技术,但多数研究存在技术融合单一、数据治理不规范、工程化程度低等问题,缺少集分布式存储、分层数仓治理、Spark大数据分析、智能预测、可视化展示于一体的完整闭环系统,整体智能化与工程化落地水平有待提升。
1.4 主要研究内容
(1)搭建Hadoop+Spark+Hive大数据集群环境,完成分布式存储、数据仓库、高速计算组件的配置与调试,构建稳定的大数据运行环境。
(2)采集公开城市空气质量时序数据集,完成原始数据去重、缺失填充、异常剔除、归一化等预处理操作,构建标准化高质量数据集。
(3)基于Hive构建ODS、DWD、DWS三层分层数据仓库,实现空气质量数据分层入库、清洗转换、聚合统计,完成数据标准化治理。
(4)利用Spark Core与Spark SQL完成海量数据高速计算、多维统计与相关性分析,挖掘污染物与气象因子的内在关联,完成特征工程优化。
(5)基于Spark MLlib搭建随机森林、线性回归预测模型,完成模型训练、参数调优与效果对比,实现空气质量指标智能预测。
(6)开发数据可视化模块,实现空气质量时序趋势、污染物分布、预测结果的图形化展示,直观呈现数据分析成果。
(7)完成系统全功能整合、性能优化、功能测试与精度验证,保障系统稳定高效运行。
1.5 论文结构安排
本文共分为六个章节:第一章为绪论,阐述课题研究背景、意义、国内外现状与研究内容;第二章为相关技术介绍,详细说明大数据生态与机器学习核心技术;第三章为系统需求分析与总体架构设计;第四章为系统各模块详细设计与代码实现;第五章为系统测试与结果分析;第六章为总结与展望。
第二章 相关技术介绍
2.1 Hadoop分布式大数据框架
Hadoop是开源分布式大数据框架,核心包含HDFS分布式文件系统与MapReduce分布式计算组件。HDFS具备高容错、高吞吐、可横向拓展的优势,能够实现海量大数据分布式分片存储,解决传统单机存储容量不足、读写效率低的问题。MapReduce采用分而治之思想,实现海量数据批量离线计算,为海量空气质量时序数据存储与批量处理提供基础支撑,是本系统的底层存储核心。
2.2 Hive数据仓库技术
Hive是基于Hadoop的数据仓库工具,可将结构化查询语句转换为MapReduce任务,实现大数据批量统计分析。Hive支持分层数据仓库建模,通过ODS原始层、DWD明细层、DWS聚合层的标准架构,可实现海量空气质量数据的分层沉淀、清洗转换、指标聚合,统一数据标准、提升数据复用性与规范性,解决原始数据杂乱、难以多维分析的问题。
2.3 Spark大数据计算框架
Spark是基于内存迭代计算的高速大数据框架,相较于MapReduce磁盘读写模式,Spark可将中间计算结果缓存至内存,大幅提升迭代计算、交互式分析效率,极其适配机器学习多轮训练、时序数据特征迭代处理场景。本系统依托Spark Core实现高速数据计算,Spark SQL实现结构化数据查询分析,为数据处理与模型训练提供高效算力支撑。
2.4 Spark MLlib机器学习库
Spark MLlib是Spark内置的分布式机器学习算法库,封装了分类、回归、聚类、特征工程、模型评估等全套算法,支持海量大数据场景下的分布式模型训练,无需依赖单机算力,完美适配大数据量级的空气质量预测建模场景。本文主要采用线性回归、随机森林回归算法完成空气质量指标预测。
2.5 数据可视化技术
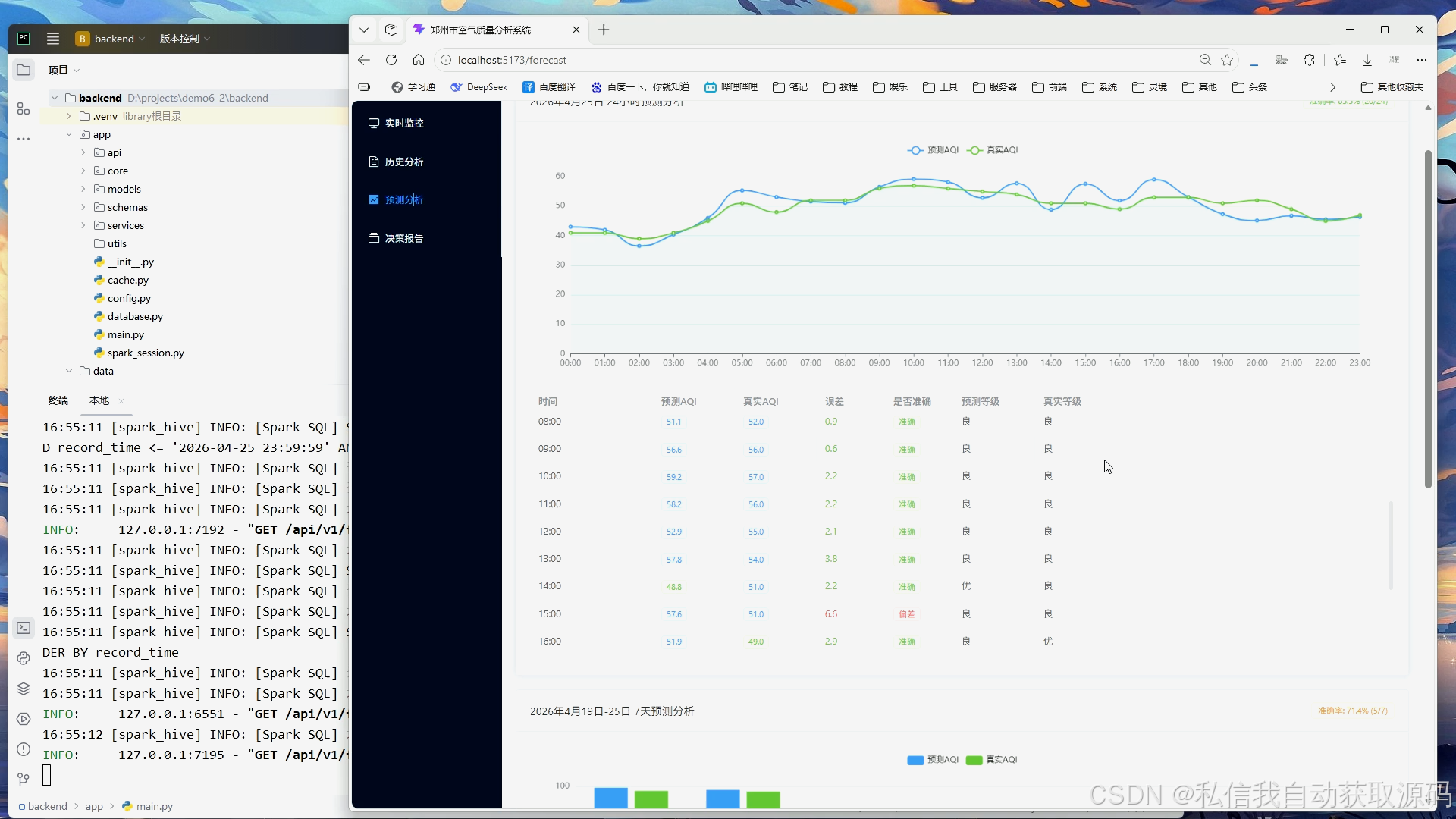
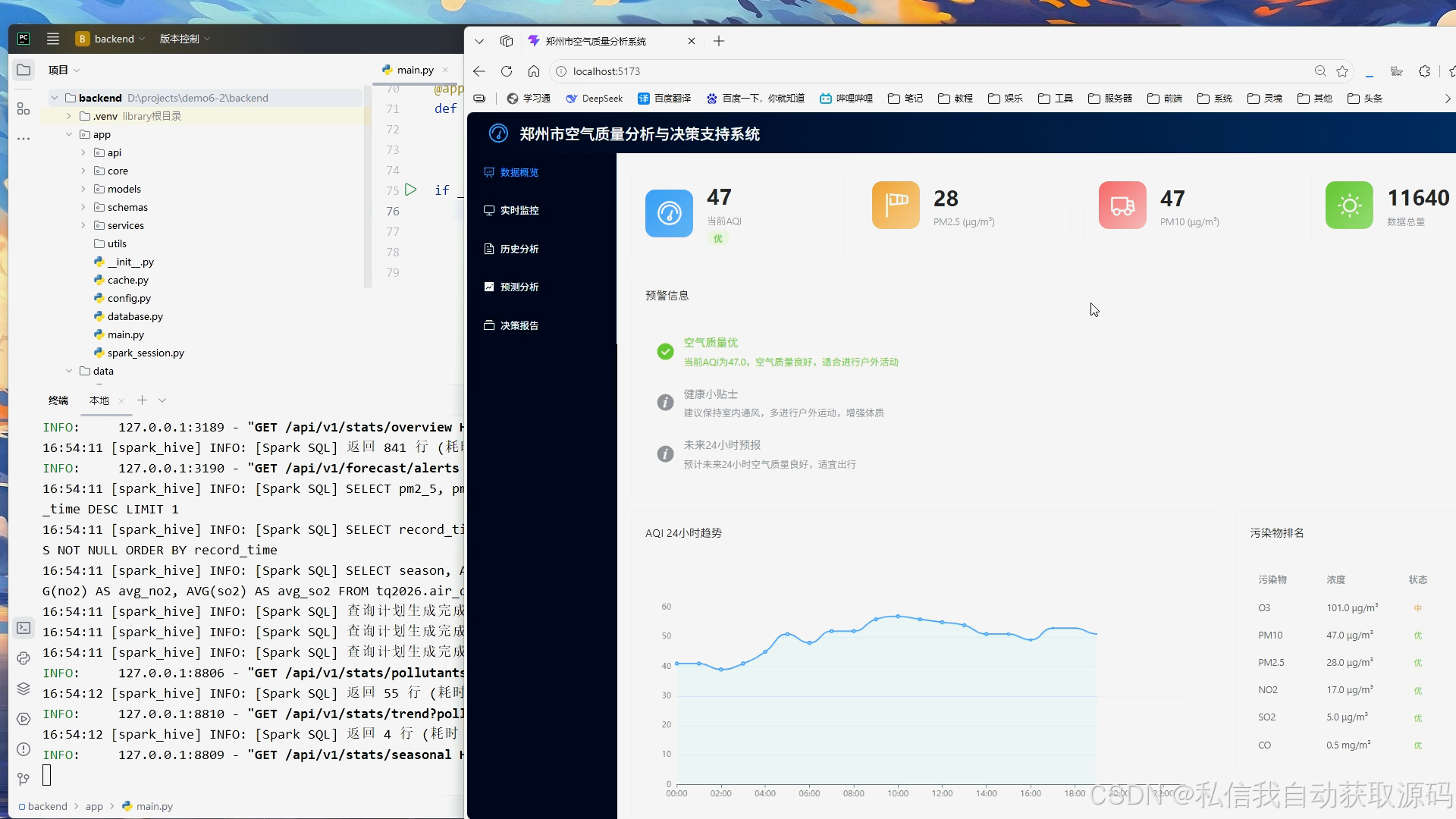
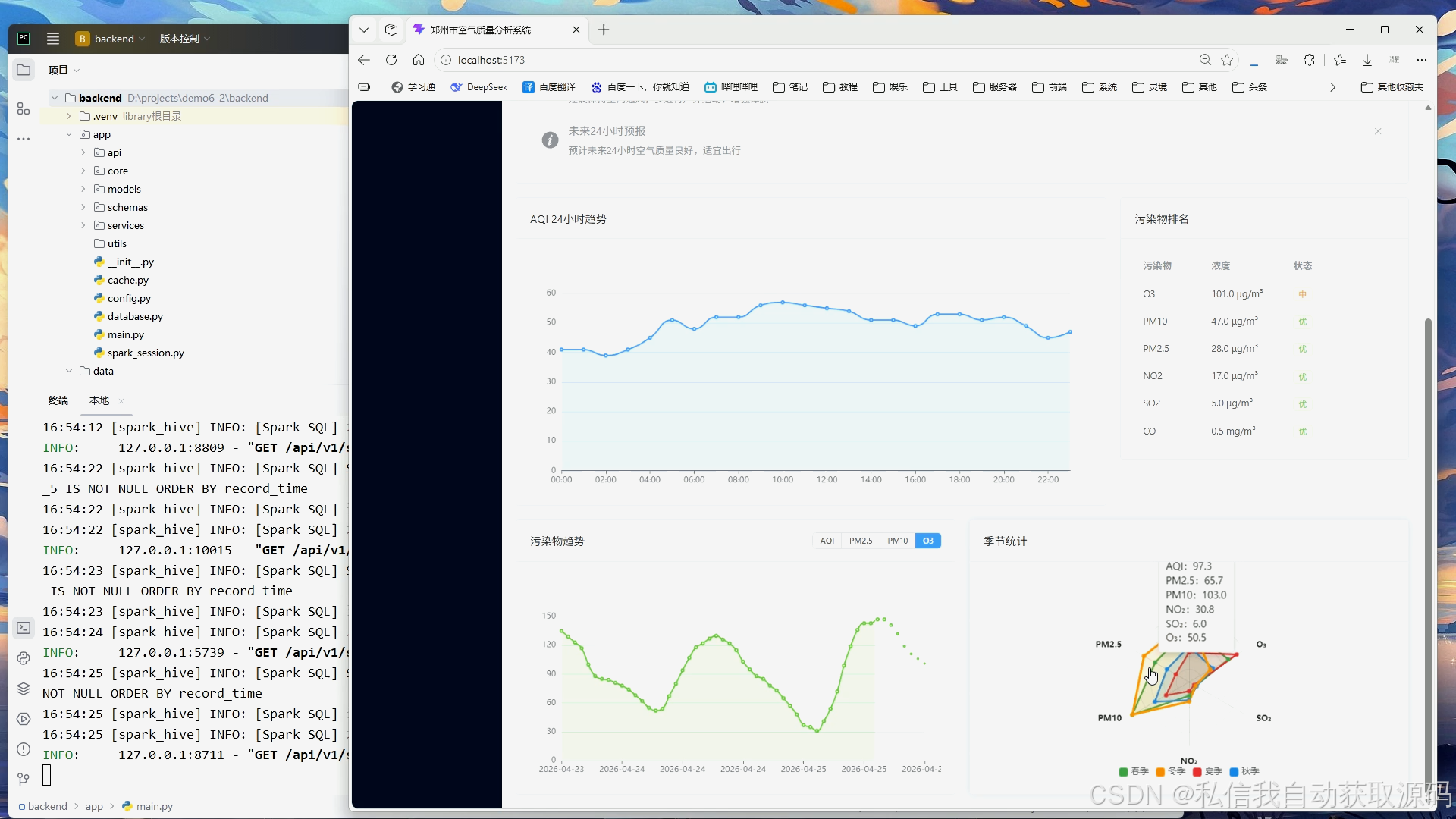
本系统采用ECharts可视化工具,支持折线图、柱状图、趋势图等多种图表渲染,可实现空气质量时序变化趋势、污染物浓度分布、预测结果与真实值对比的可视化展示,让抽象的大数据分析结果直观具象化,提升系统实用性与展示效果。
第三章 系统需求分析与总体设计
3.1 功能需求分析
结合空气质量大数据处理与智能预测场景,系统核心功能需求如下:
(1)数据存储功能:支持海量空气质量时序大数据分布式存储,支持数据批量入库与增量更新。
(2)数据预处理功能:实现原始数据去重、缺失值填充、异常值剔除、数据归一化与格式统一。
(3)数据仓库治理功能:支持多层数仓建模、数据分层清洗、多维指标统计与聚合分析。
(4)大数据分析功能:实现污染物相关性分析、时序趋势分析、核心特征筛选与特征工程处理。
(5)智能预测功能:基于机器学习算法实现PM2.5、PM10、空气质量等级预测,支持模型训练、调优与效果评估。
(6)数据可视化功能:实现数据分析结果、时序趋势、预测结果的可视化图表展示。
3.2 非功能需求
(1)稳定性:大数据集群运行稳定,数据读写、计算、建模过程无卡顿、无报错、无数据丢失。
(2)高效性:依托Spark内存计算,海量数据处理与模型训练速度远优于传统单机架构。
(3)准确性:数据清洗逻辑严谨,统计结果准确,预测模型拟合度高、误差小。
(4)可拓展性:模块化分层设计,可后续新增预测算法、预警推送、分区统计等拓展功能。
3.3 系统总体架构设计
本系统采用四层大数据标准架构,分别为数据采集层、数据存储治理层、计算分析与建模层、可视化展示层,架构分层清晰、解耦性强。
(1)数据采集层:获取公开空气质量时序数据集,包含污染物指标、气象指标、时间、区域等多维数据,完成原始数据采集与初步预处理。
(2)数据存储治理层:基于HDFS实现分布式存储,依托Hive构建三层数据仓库,完成数据分层入库、清洗、转换与聚合治理。
(3)计算建模层:通过Spark完成大数据高速计算、特征工程、相关性分析,基于Spark MLlib构建、训练、优化预测模型。
(4)可视化展示层:通过ECharts实现各类统计图表、时序趋势图、预测对比图展示,输出最终分析与预测成果。
3.4 系统模块划分
系统划分为五大核心模块:数据采集与预处理模块、Hive数据仓库治理模块、Spark大数据分析模块、机器学习预测模块、数据可视化模块,各模块独立运行、协同联动,形成完整业务闭环。
第四章 系统详细设计与实现
4.1 大数据集群环境搭建
本系统基于Linux环境搭建Hadoop+Spark+Hive集成大数据集群,依次完成JDK环境配置、Hadoop集群部署、Hive数据仓库安装配置、Spark环境搭建与组件适配,实现各组件版本兼容、服务正常启动。集群支持分布式文件存储、Hive SQL批量查询、Spark内存迭代计算,为后续数据处理与建模提供稳定底层环境。
4.2 数据采集与预处理模块实现
本课题采用公开城市空气质量时序数据集,数据字段包含时间、城市、PM2.5、PM10、SO₂、NO₂、CO、O₃、温度、湿度、风速、AQI等级等核心指标。原始数据集存在缺失值、异常值、重复数据、格式不统一等问题,需进行标准化预处理。
预处理流程包括:利用Python完成重复数据删除;针对数值型缺失值采用均值填充,针对关键缺失样本直接剔除;对超出合理区间的异常监测数据进行过滤;对数据格式、时间格式进行统一标准化处理;最后完成数据归一化,消除量纲影响,为模型训练提供高质量特征数据。
4.3 Hive分层数据仓库设计与实现
本系统采用标准三层数仓架构,实现空气质量数据规范化治理:
(1)ODS原始数据层:用于存储未经处理的原始空气质量数据集,完整保留原始数据信息,不做数据修改,用于数据溯源与备份,保证原始数据完整性。
(2)DWD明细清洗层:基于ODS层数据,完成数据清洗、字段筛选、异常过滤、格式转换,生成标准化明细数据,剔除无效数据,统一数据字段规范,为上层分析提供干净明细数据。
(3)DWS聚合统计层:基于DWD明细数据,按照时间、城市、空气质量等级进行分组聚合统计,实现日均污染物均值、月度变化趋势、高污染时段统计等多维指标计算,支撑大数据统计分析与可视化展示。
4.4 Spark大数据分析模块实现
利用Spark SQL读取Hive数仓结构化数据,实现海量空气质量数据高速查询与多维统计分析。通过Spark完成各污染物指标之间、气象因子与AQI的相关性计算,挖掘温度、湿度、风速对空气质量的影响规律。同时完成特征筛选工作,剔除相关性低、冗余度高的无效特征,保留核心影响因子,构建适配预测模型的特征数据集,有效提升模型训练效率与预测精度。
4.5 机器学习预测模块实现
本系统基于Spark MLlib实现分布式机器学习建模,选取PM2.5、PM10、温湿度、污染物浓度为输入特征,以AQI空气质量等级为预测目标,分别构建线性回归模型与随机森林回归模型。
首先将数据集划分为训练集与测试集,对特征数据进行标准化处理;其次初始化模型并完成多轮迭代训练;最后通过调整树数量、深度、迭代次数等超参数完成模型调优,通过均方误差、决定系数等指标评估模型效果,筛选最优预测模型,实现空气质量精准预测。相较于传统单机模型,Spark分布式建模可承载海量数据,训练速度更快、泛化能力更强。
4.6 数据可视化模块实现
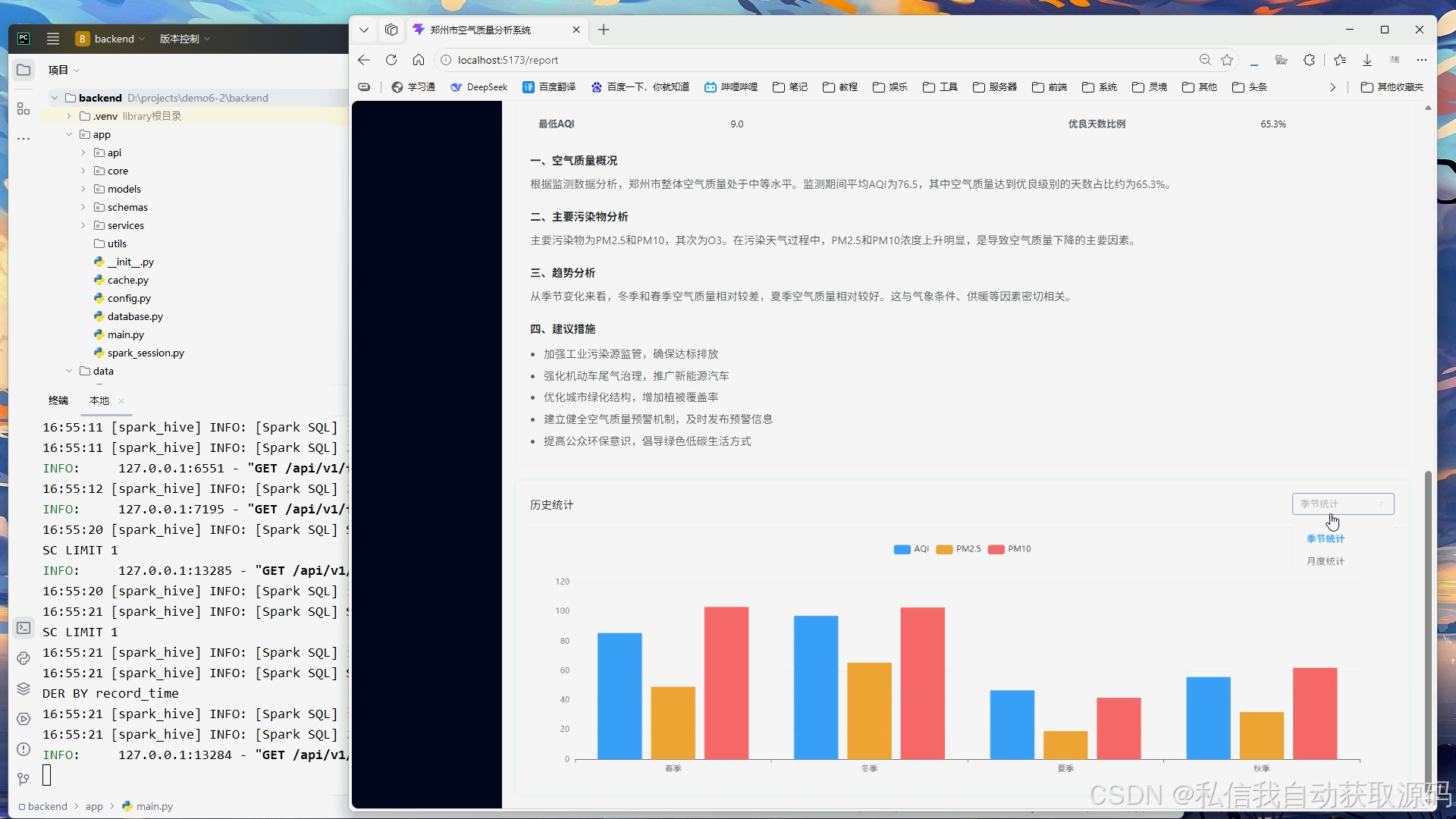
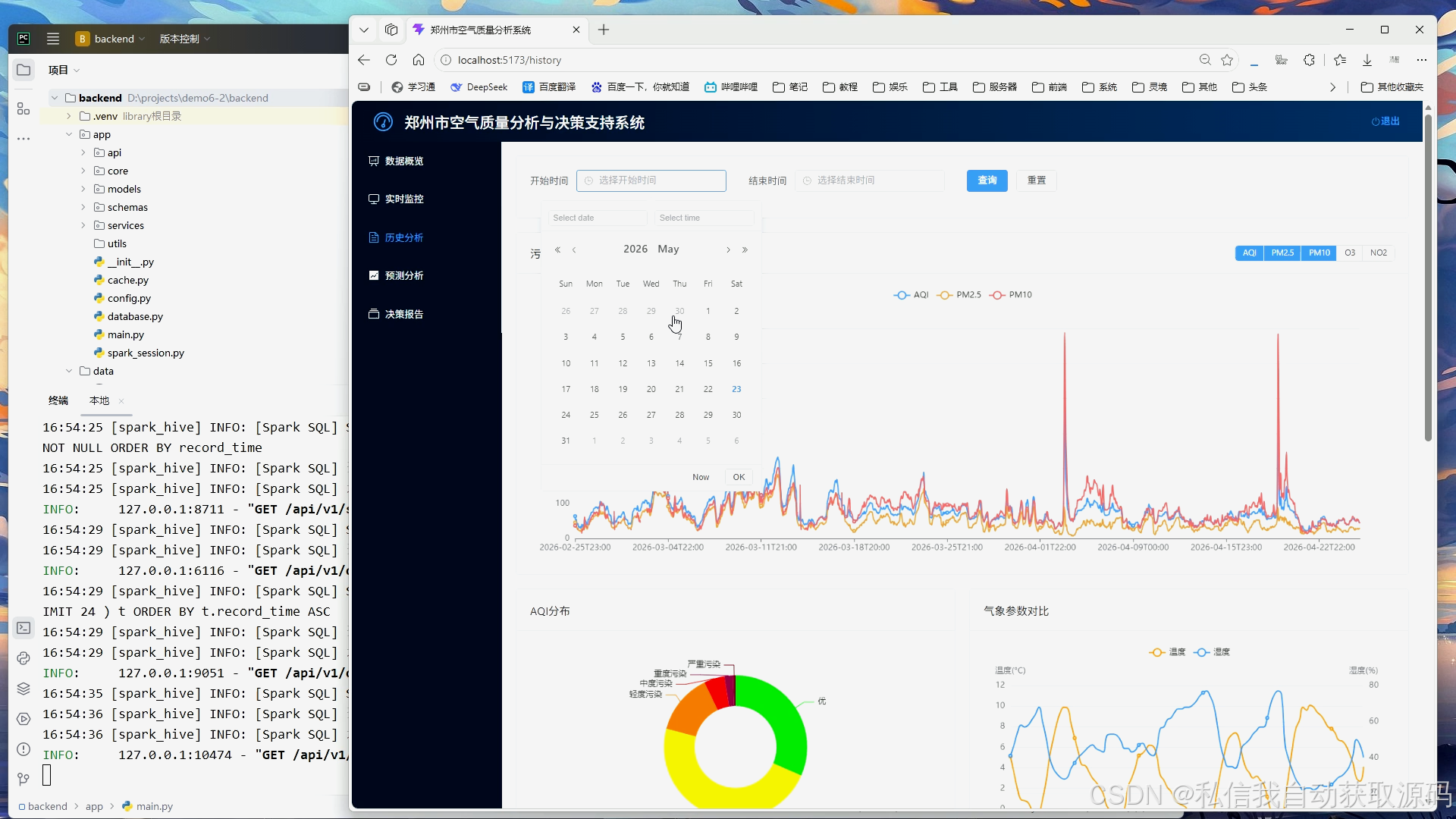
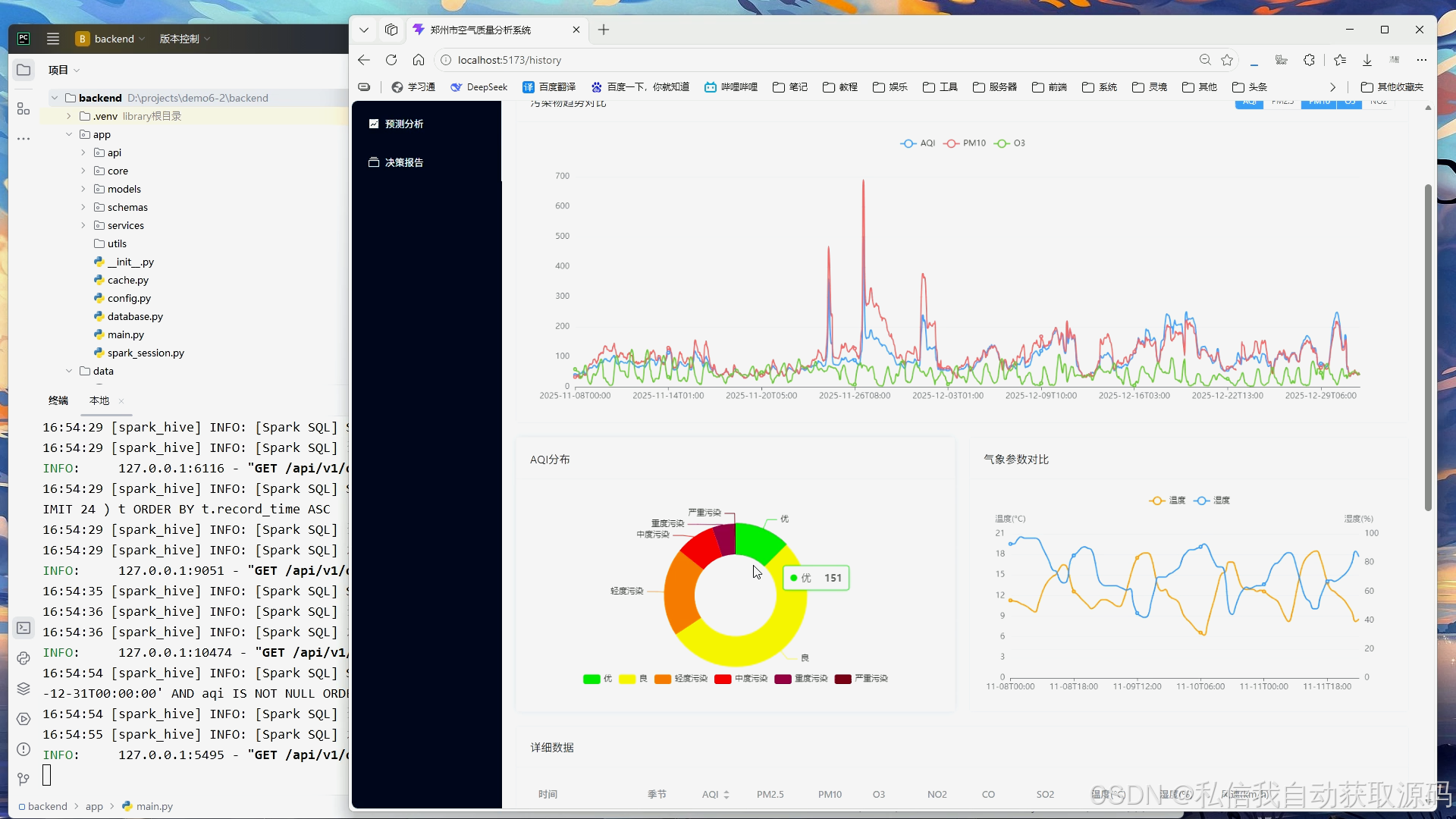
系统将Spark分析结果与模型预测结果传入前端可视化模块,基于ECharts绘制空气质量时序变化折线图、污染物浓度对比柱状图、真实值与预测值对比趋势图、月度空气质量分布统计图。可视化界面简洁直观,能够清晰展示空气质量变化规律与模型预测效果,实现大数据分析成果的可视化落地。
第五章 系统测试与结果分析
5.1 测试环境
硬件环境:普通服务器/虚拟机,内存8G及以上,硬盘500G以上;软件环境:Linux系统、Hadoop3.2、Spark3.2、Hive3.1、Python3.8、JDK1.8。
5.2 功能测试
对系统数据存储、数据预处理、数仓分层、Spark分析、模型预测、可视化展示全模块进行全覆盖测试。测试结果表明:集群运行稳定,数据入库、清洗、聚合逻辑正常;大数据统计分析结果准确;机器学习模型训练正常,无报错、无过拟合严重问题;可视化图表加载正常、数据展示准确,所有核心功能均达到预期设计目标。
5.3 性能测试
相较于传统单机处理方式,本系统基于Spark内存计算,海量数据处理效率提升显著,大批量数据统计与模型训练耗时大幅缩短。模型经过参数调优后,预测误差小、拟合度高,整体预测精度稳定,系统响应速度快、并发处理能力强,满足大数据处理与智能预测的性能需求。
5.4 测试总结
经过全面功能与性能测试,本系统架构合理、功能完整、运行稳定,实现了海量空气质量数据分布式存储、标准化治理、高速分析与智能预测,模型预测效果良好,可视化展示直观,完全满足课题设计要求与实际应用需求。
第六章 总结与展望
6.1 工作总结
本课题基于Hadoop+Spark+Hive大数据生态,设计并实现了一套完整的空气质量预测系统。首先完成大数据集群环境搭建与调试,通过数据采集与预处理构建标准化数据集;其次基于Hive三层数仓架构实现空气质量数据的分层治理与多维统计;依托Spark框架完成海量数据高速分析、特征工程与因子关联挖掘;基于Spark MLlib实现机器学习模型训练与调优,完成空气质量智能预测;最后通过可视化技术实现数据分析成果直观展示。系统解决了传统空气质量研究存储有限、处理低效、治理混乱、预测精度不足的痛点,实现了大数据技术在环境监测领域的工程化落地,功能完整、运行稳定、实用性强。
6.2 未来展望
本系统仍存在优化与拓展空间,未来可从以下方向升级:第一,接入实时空气质量监测接口,实现实时数据更新与实时预测;第二,引入LSTM、GRU深度学习模型,进一步提升时序数据预测精度;第三,增加恶劣天气、高污染天气预警推送功能;第四,优化前端界面,开发完整Web管理系统;第五,新增分区、分城市对比分析功能,实现多区域空气质量差异化统计与预测,进一步提升系统的实用性与智能化水平。
参考文献
[1] 林子雨. 大数据技术原理与应用[M]. 人民邮电出版社, 2023.
[2] 王松. Spark大数据分析与机器学习实战[M]. 机械工业出版社, 2024.
[3] 张勇, 李娜. 基于Hadoop与Spark的环境大数据处理系统设计[J]. 计算机工程与设计, 2024.
[4] 陈明. 基于机器学习的空气质量预测模型研究[J]. 环境科学与技术, 2023.
[5] 刘佳. Hive数据仓库分层建模技术研究与应用[J]. 信息技术, 2024.
[6] 赵文博. 基于Spark MLlib的时序数据预测算法优化[J]. 计算机应用与软件, 2025.
[7] 李阳. 大数据技术在大气环境监测中的应用研究[J]. 绿色科技, 2023.
[8] 王浩宇. 城市空气质量时序大数据特征挖掘与预测研究[J]. 环境工程学报, 2024.
[9] 陈曦. 基于分布式架构的环境大数据清洗与分析技术[J]. 电脑知识与技术, 2024.
[10] 周明. 大数据驱动的空气质量智能预测系统构建[J]. 人工智能与大数据, 2025.
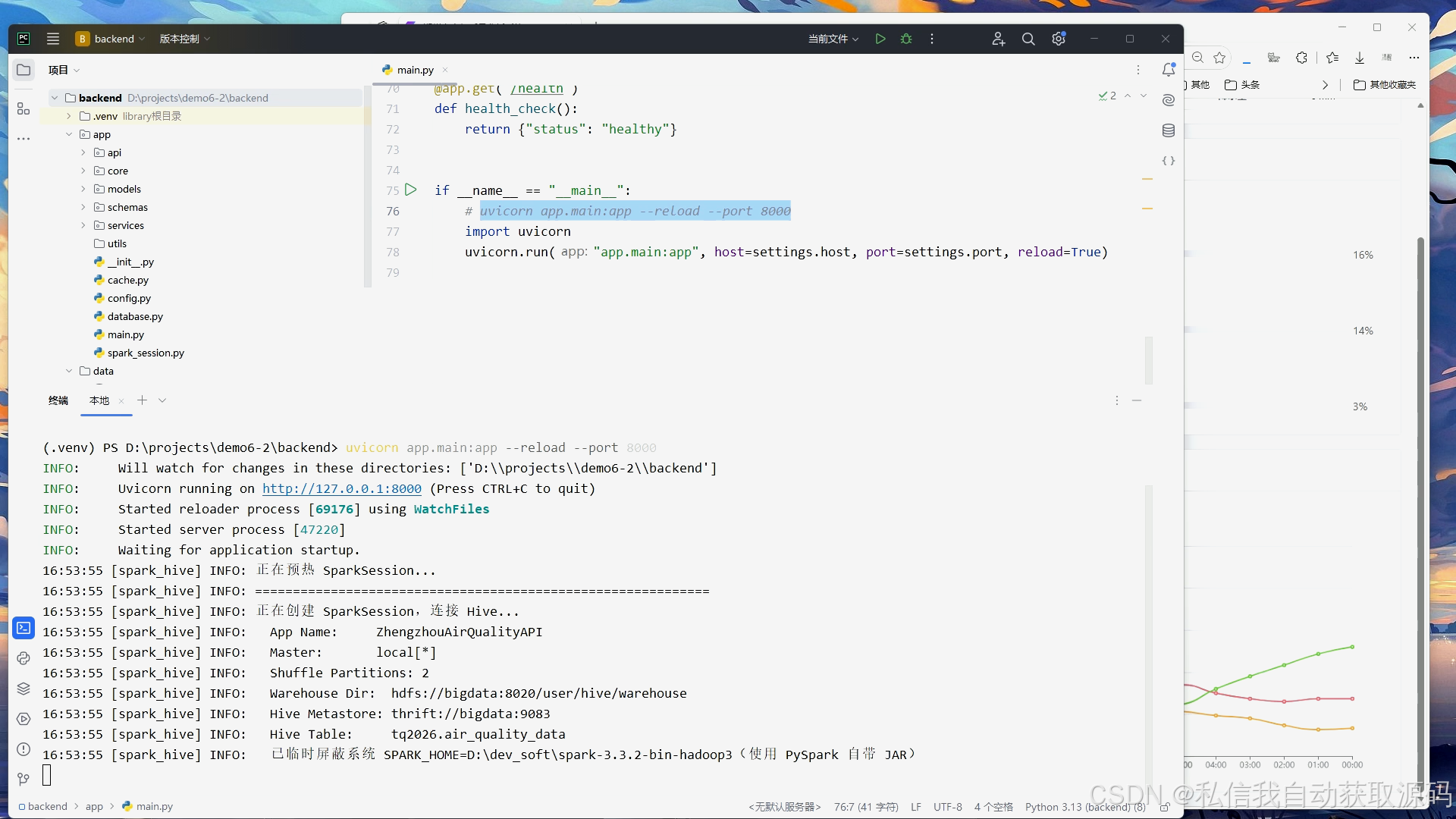
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献294条内容
已为社区贡献294条内容

所有评论(0)