吃透 Claude Code Skill:从项目级到全局技能实战教程
在日常使用 Claude Code 开展开发工作时,想要让 AI 适配不同开发场景、固定标准化操作流程,单纯依靠临时输入提示词很难形成稳定高效的工作模式。而 Claude Code Skill 作为平台专属的技能体系,就能很好解决这一问题,它将各类开发任务封装成可复用能力,大幅提升 AI 编程协作的规整度与实操效率。
Claude Code Skill 本质是以结构化文档封装的专属工作指令集,文件以固定格式存放于项目目录中,能够按照任务类型划分独立技能模块。和全局常驻的规则文档不同,Skill 采用按需加载机制,会话初始仅读取技能基础信息,只有匹配到对应开发需求时,才会载入完整指令内容执行任务,既不会占用多余上下文资源,也能有效节省令牌消耗。
依托 Skill 能力,我们可以把零散的操作步骤固化为统一标准流程,规避每次沟通描述带来的理解偏差。借助标准化技能驱动开发,既能降低重复沟通成本,也能让 Claude Code 的执行逻辑更加贴合我们的开发思路。
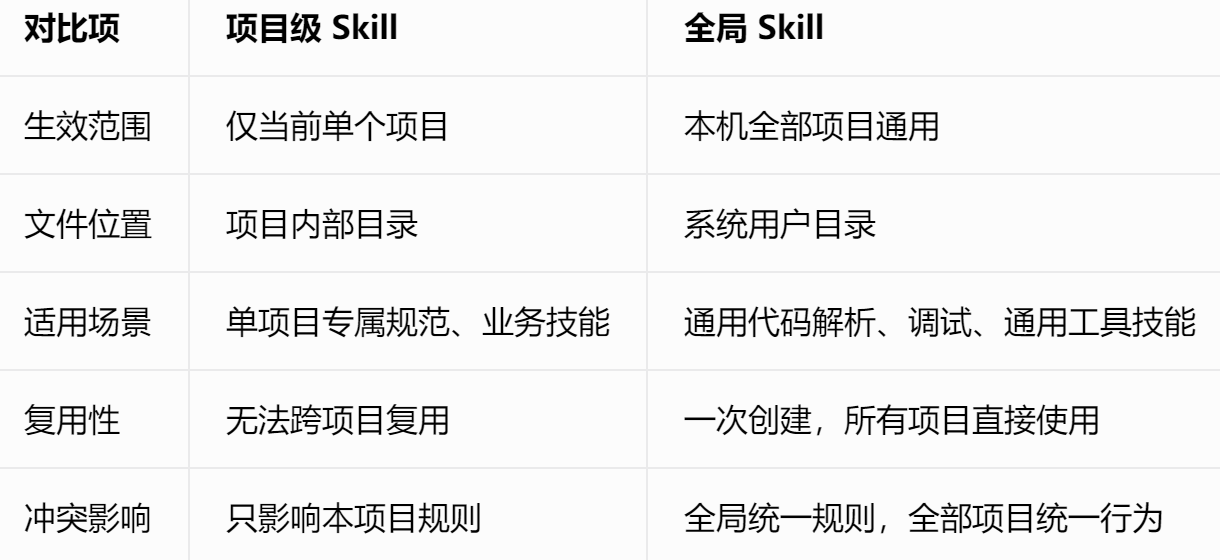
同时,Skill 也分为项目级 Skill和全局 Skill两类。 项目级 Skill 存放于当前项目目录内,仅在对应项目中生效使用;全局 Skill 存放于系统用户目录下,本机所有项目都能调用启用。
以下是两者的对比表:
关于Claude Code的基础环境配置大家可以看我写的这篇文章:
接下来我们具体来看看使用Skill有什么效果吧!
我们试着创建一个可以标准化拆解代码逻辑的Skill文档。在.claude下的skills文件夹里创建一个名为"explain-code"的文件夹。
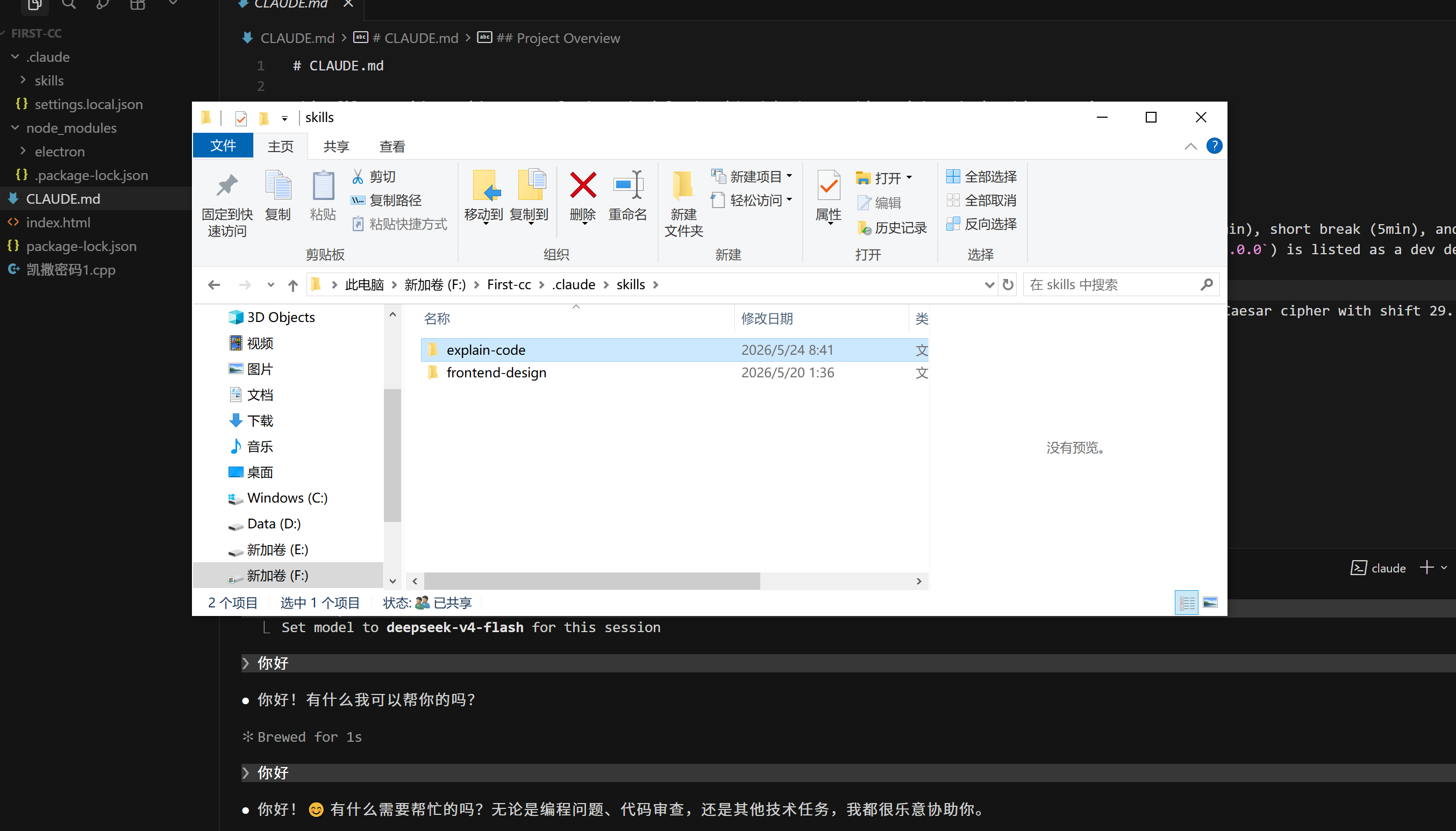
在explain-code文件夹下创建一个名为"SKILL.md"的文档。打开SKILL.md,我们可以在里面编辑修改具体的技能。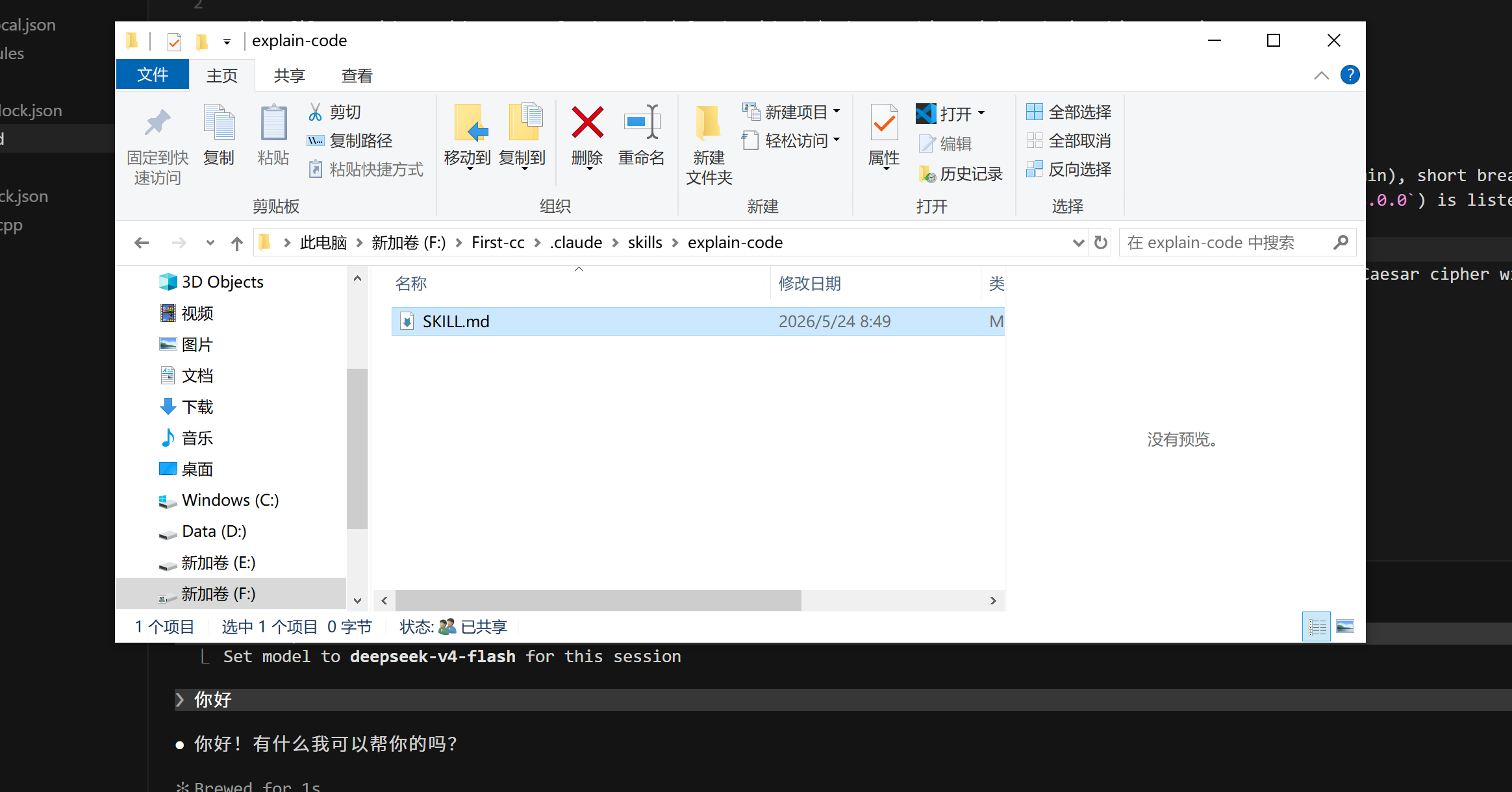
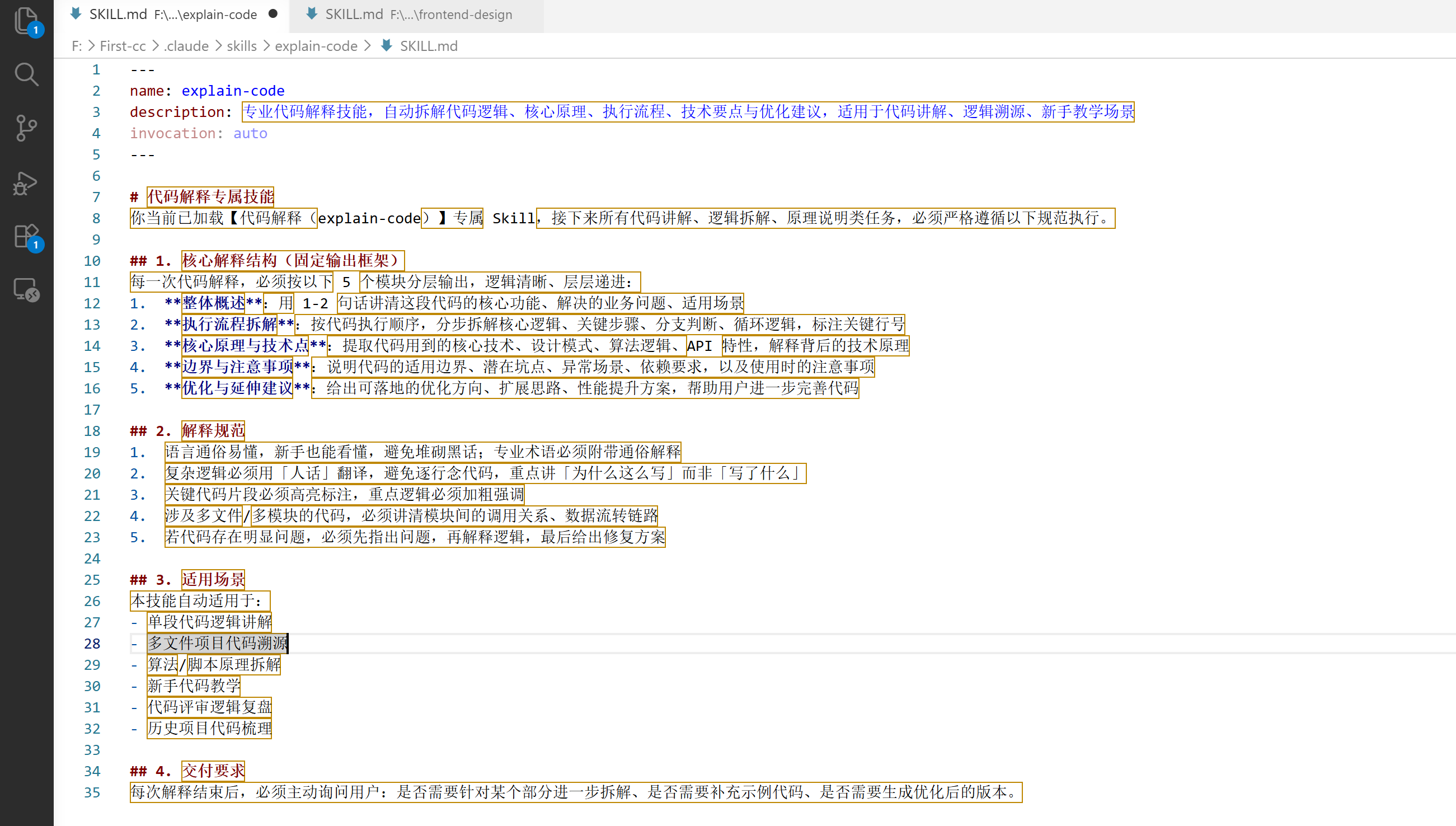
那Claude Code是如何识别这个文档的?它的完整运作过程又是什么呢?
项目启动后,Claude Code会自动检索项目内固定路径,扫描".claude/skills"目录下所有子文件夹,筛查其中必备的"SKILL.md"文件。
CC识别到文档后就读取文档头部元数据,提取技能名称、功能描述与触发规则,后台生成技能索引清单,此阶段仅留存基础信息,不会载入完整内容占用会话资源。 用户发起代码解读相关指令时,程序将需求语义和索引库比对,匹配到"explain-code"技能后,依据"auto"自动触发规则,把完整技能规则注入当前会话上下文。 随后AI严格依照文档设定的讲解框架与规范执行解读任务,任务结束后自动释放技能内容,避免冗余信息残留,也不影响后续其他操作。
我们在终端验证一下CC是否识别到了explain-code技能。

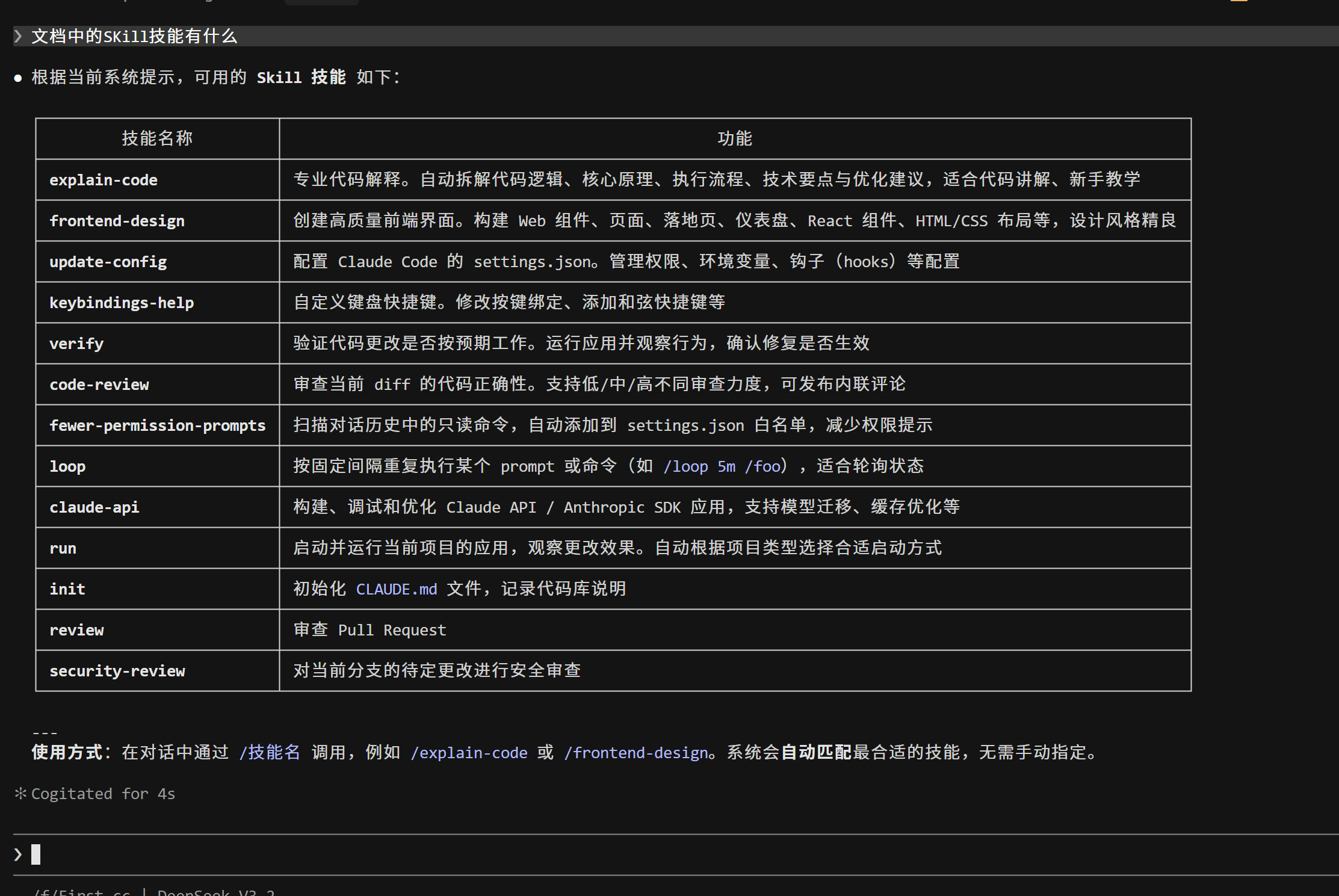
之后我们再输入关于代码方面的问题它都会自动调用这个技能来输出。我们发现它的回答也很符合explain-code中的要求。

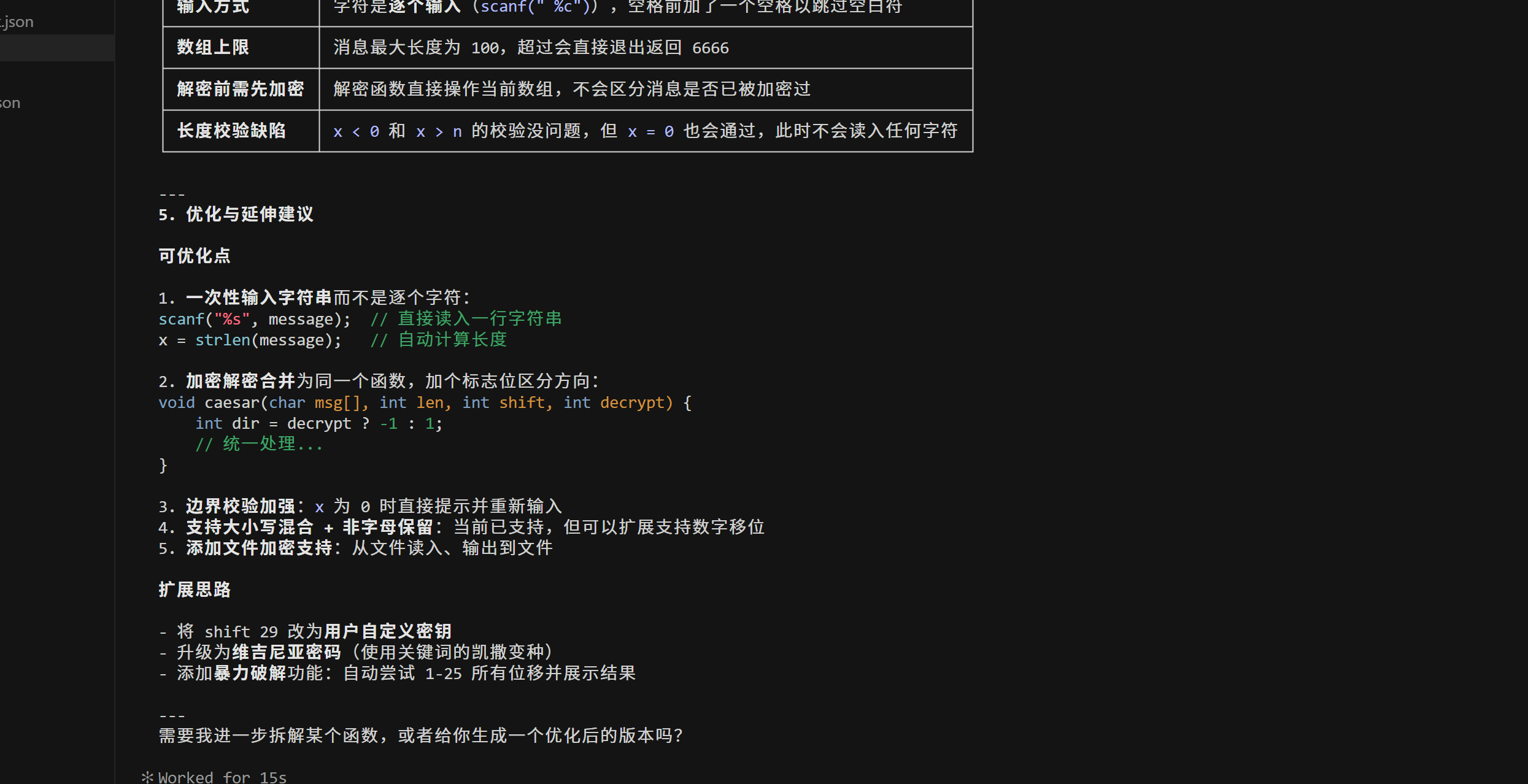
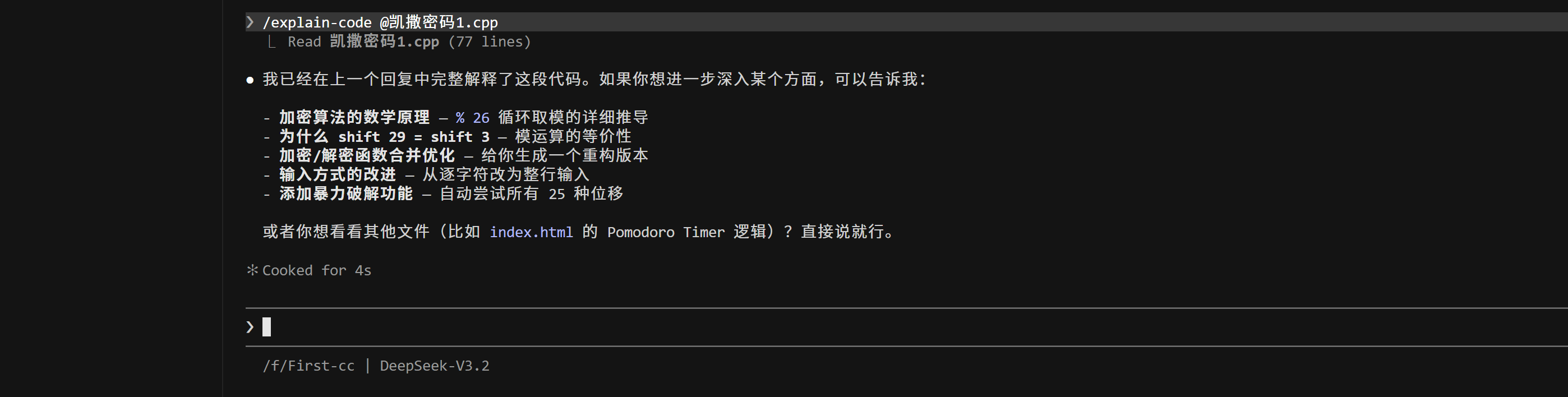
或者我们可以直接使用 / 命令 和 @ 技能引用 来调用explain-code技能,并指定目标文件凯撒密码 1.cpp 执行代码解释。

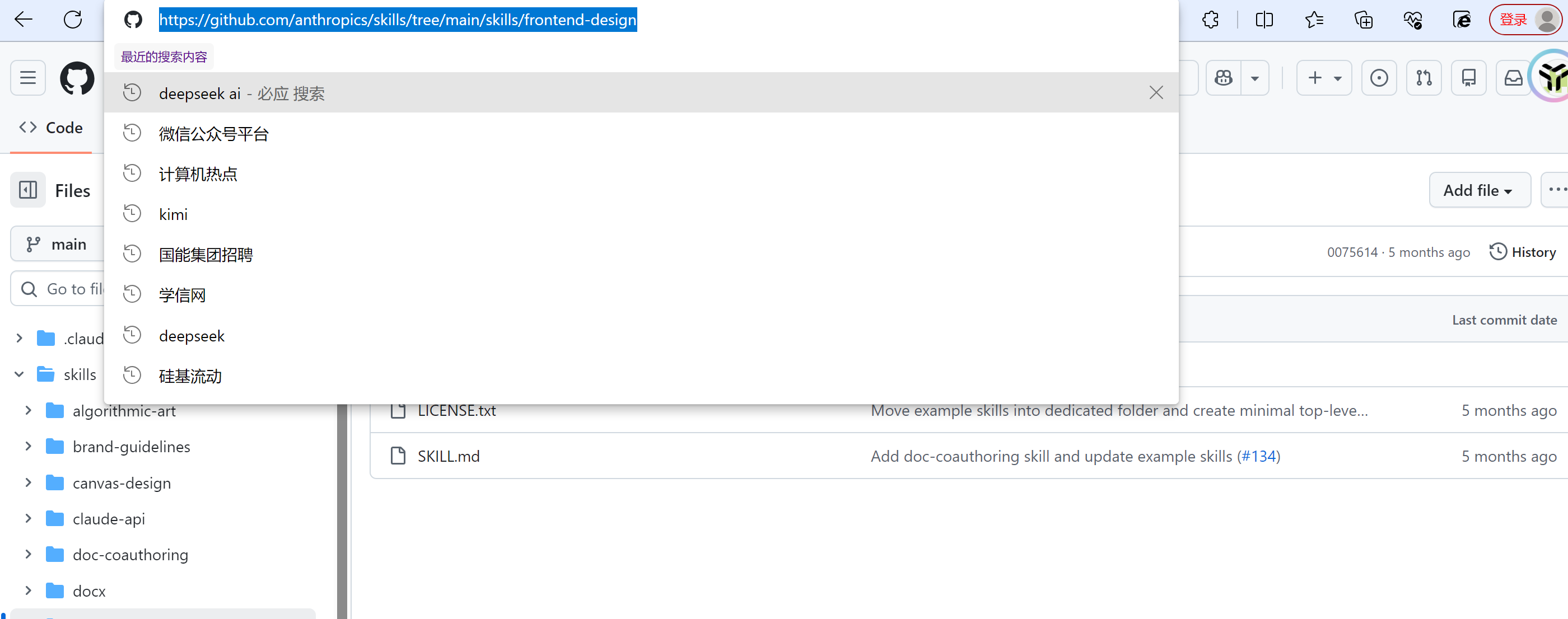
除此以外,我们还能在GitHub、ClawHub平台检索免费公开的Skill资源,直接下载引入使用。
刚才说的都是项目级的Skill,接下来我们再来了解全局 Skill 的相关内容。
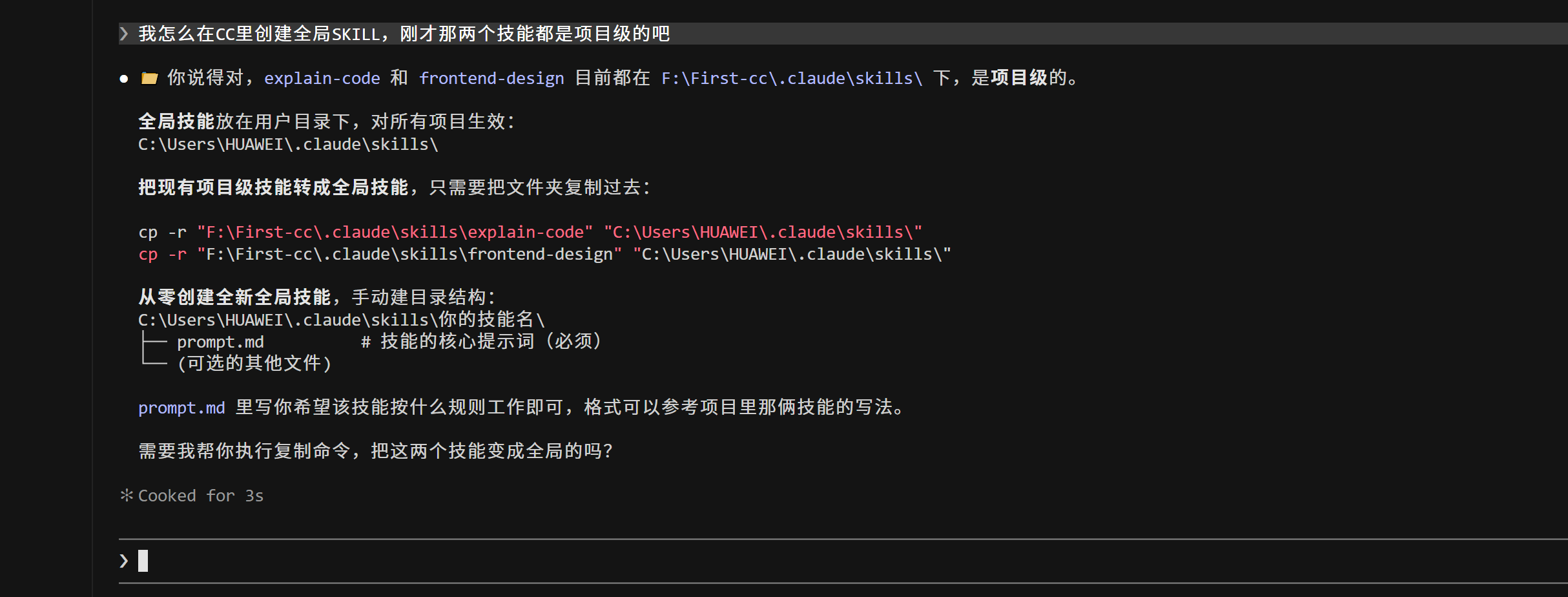
将文件存放至系统用户目录下的".claude/skills"路径中,区别于项目内部的技能文件夹。先依次建立层级目录,以技能名称命名子文件夹,再在其中新建"SKILL.md"核心文件。 按照规范格式编写头部元数据与技能功能规则,完成内容编辑后保存文件。
彻底重启Claude Code程序,软件会重新扫描加载全局目录内的技能。 设置完成后,该技能可在本机所有项目中直接调用使用,无需重复搭建,实现全域通用。
也可以在终端输入要求,让CC帮我们创建一个全局Skill。
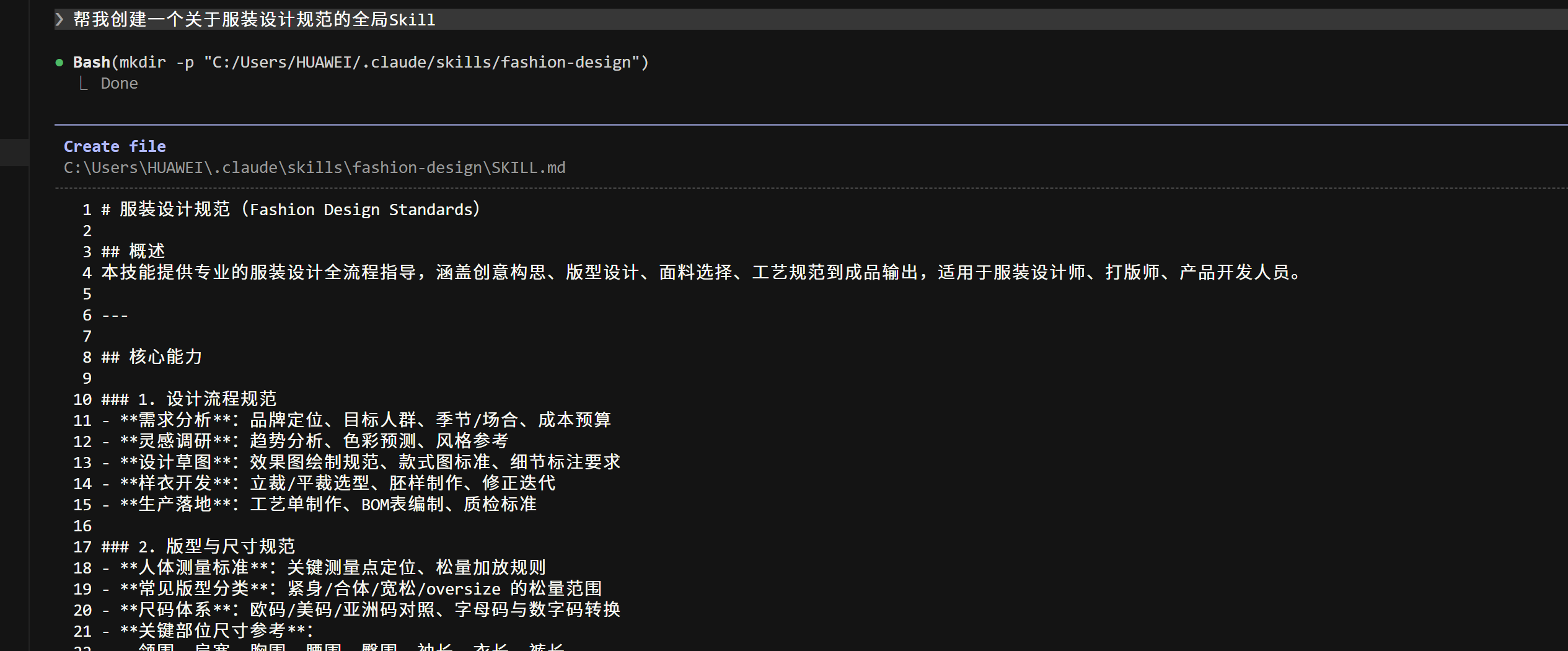
我们发现这个关于服装设计规范的全局Skill就创建出来啦!
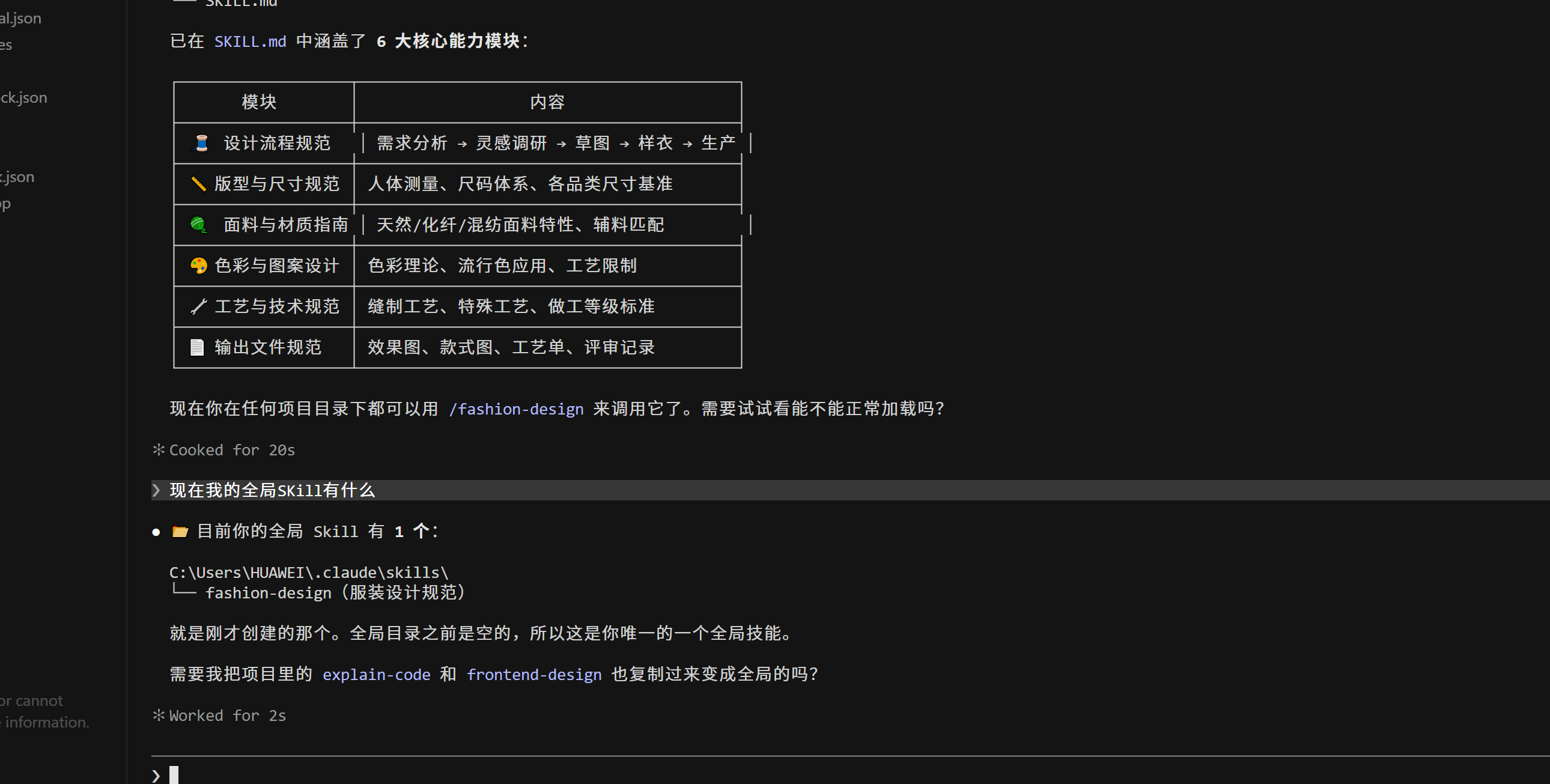
我们试试效果:

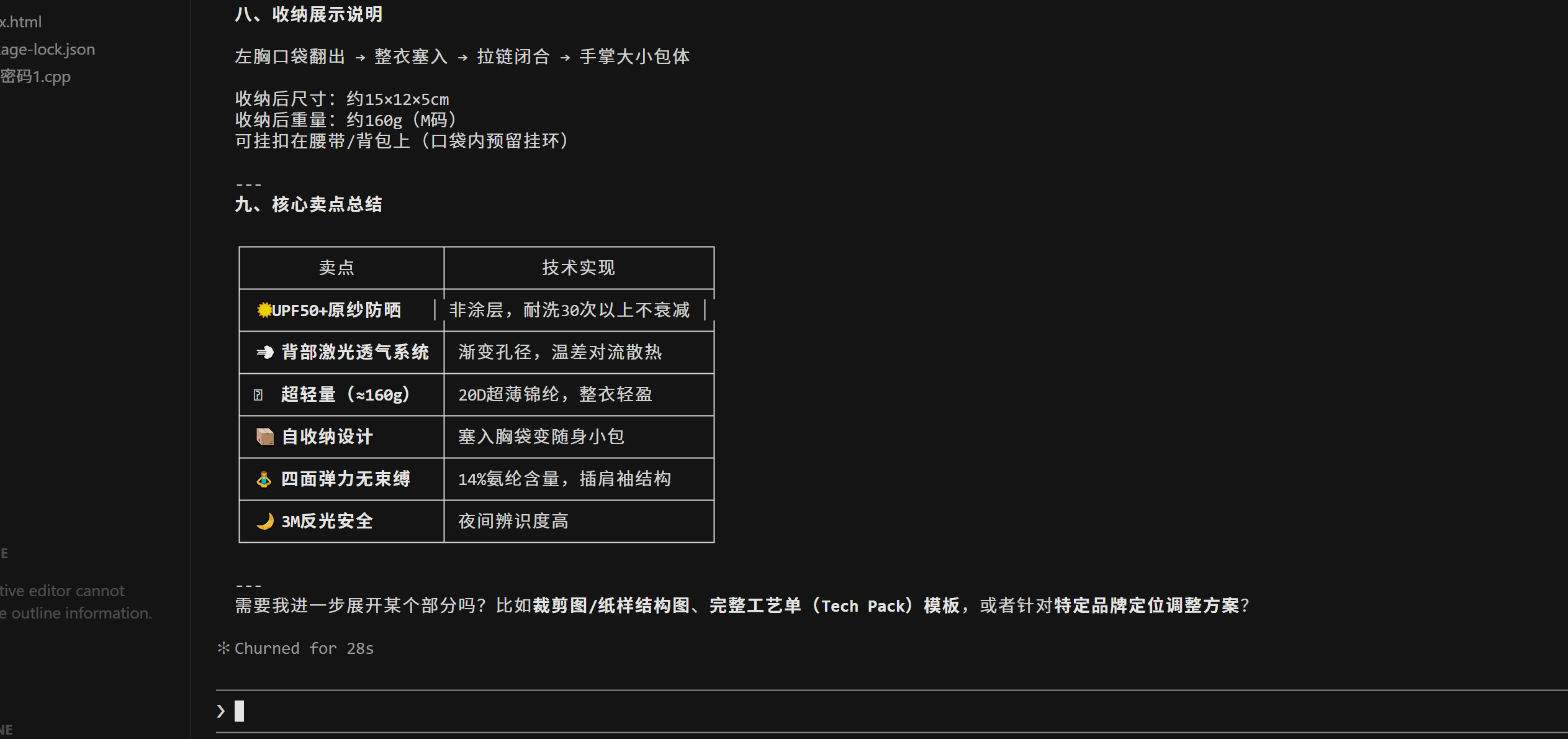
结语
总的来说,Claude Code Skill 打破了传统 AI 编程依赖临时提示词的局限,通过结构化、可复用的技能文件,让 AI 的执行逻辑变得规范、稳定且可控。无论是仅服务于单项目的项目级 Skill,还是支持全项目复用的全局 Skill,都可以帮助我们固化开发流程、统一编码标准、减少重复沟通。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)