03 | Mem0 框架分析:为什么只用 ADD 就够了?
03 | “只增不改”——V3 为什么只用 ADD 就够了
一个记忆系统居然不更新、不删除?第一次看到 V3 架构的人,几乎都会觉得荒谬。但 Mem0 的答案不仅不荒谬,而且是整个 V3 架构最核心的设计决策。理解了"只增不改"的必然性,你就理解了 V3 一半以上的设计选择。
ADD/UPDATE/DELETE——看起来更合理的幻觉
先回到直觉。一个记忆系统,用户说过"我喜欢披萨",后来改口说"我现在喜欢寿司了",自然的反应是:UPDATE 旧记忆,把"披萨"换成"寿司"。用户说"我不再吃肉了",自然的反应是:DELETE 相关旧记忆。这不就是数据库的基本操作吗?
V1/V2 正是这样做的。在 DEFAULT_UPDATE_MEMORY_PROMPT 中,LLM 被要求同时判断四种操作:
- add into the memory,
- update the memory
- delete from the memory
- no change.
这个设计在概念上无懈可击,但在工程实践中却是一场灾难。原因不是某一个孤立的 bug,而是一组相互放大的系统性问题。
破:三操作模型的四重困境
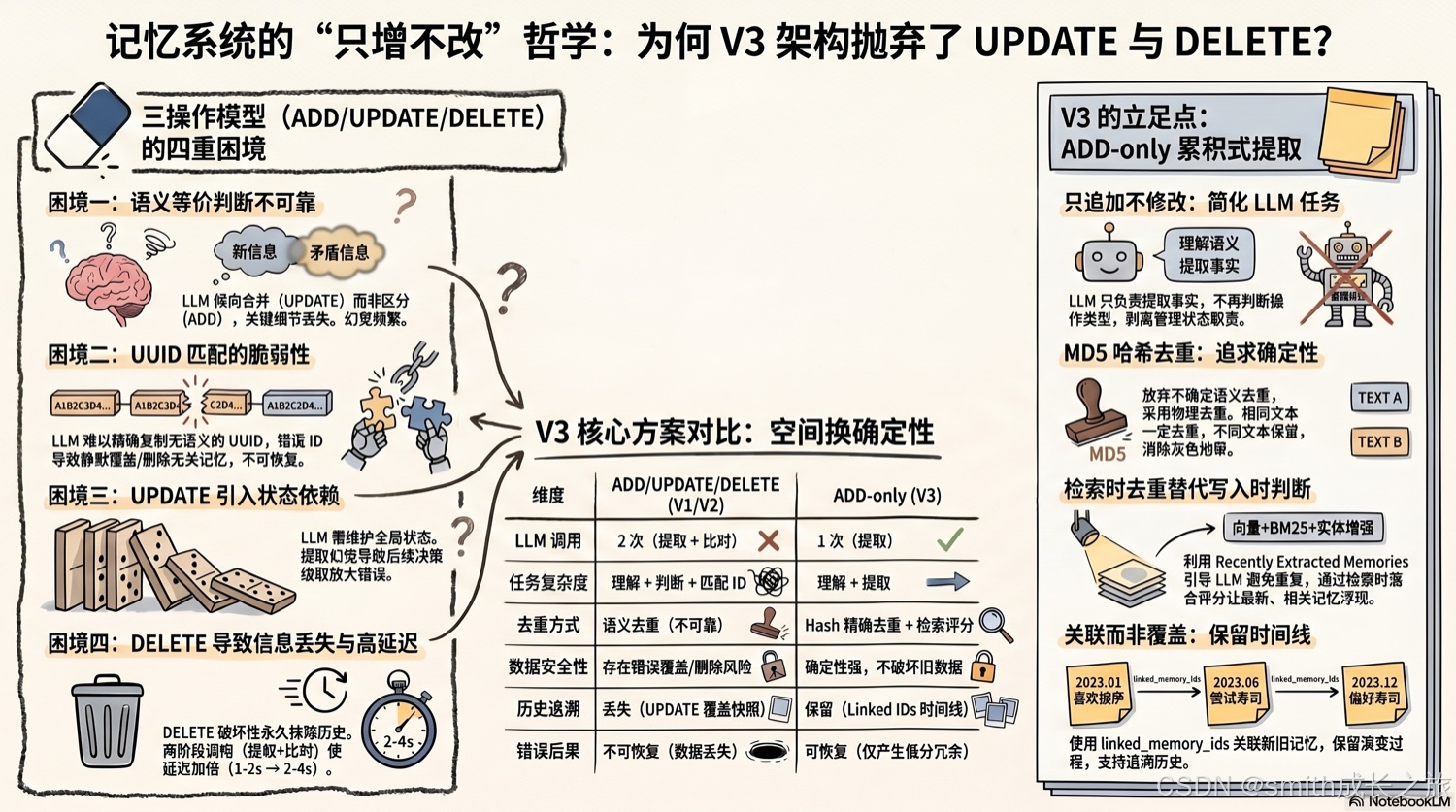
三操作模型的四重困境 vs ADD-only 累积式提取
困境一:LLM 判断幻觉——不是"偶尔出错",是"系统性不可靠"
让 LLM 同时区分 ADD/UPDATE/DELETE,本质上是在要求它做三件完全不同的事:识别新信息、匹配已有信息、判断矛盾信息。每一次判断都是一个独立的决策点,而每个决策点都有独立的出错概率。
看 V1/V2 的 UPDATE prompt 示例:
Old Memory: [{"id": "0", "text": "I really like cheese pizza"}]
Retrieved facts: ["Loves chicken pizza"]
Expected: UPDATE id=0 to "Loves cheese and chicken pizza"
这个例子暗示 LLM 应该把"喜欢芝士披萨"和"喜欢鸡肉披萨"合并。但如果 retrieved fact 是"Loves chicken pizza instead of cheese"呢?是 UPDATE 还是 DELETE+ADD?
这不仅仅是"边界情况"。在真实对话中,这种模糊性无处不在:
- 用户说"我不用 MySQL 了",这是 UPDATE(改用其他数据库)还是 DELETE(不再用数据库)?没有后续上下文,LLM 无法判断。
- 用户说"我上个月说的那个偏好改了",LLM 必须先理解"那个偏好"指什么(代词消解),再判断是 UPDATE 还是 ADD。两次推理,任何一次出错都会导致最终操作错误。
- 用户说"我以前喜欢猫,现在喜欢狗了",应该 UPDATE 旧记忆还是 ADD 一条新记忆并链接旧记忆?两种处理方式都是合理的,但 prompt 没有给出明确的判定规则。
更致命的是,LLM 的判断错误不是随机的,而是有偏向的——它倾向于合并(UPDATE)而不是区分(ADD)。因为 LLM 在训练中学到的"常识"是"相关的东西应该归在一起"。这导致它经常把应该独立存在的两条记忆合并成一条模糊的 UPDATE,丢失了关键细节。
困境二:UUID 匹配的脆弱性——一个错误的 ID 就能毁掉一切
V1/V2 的 UPDATE/DELETE 操作要求 LLM 返回已有记忆的 ID。这意味着 LLM 必须:
- 理解已有的记忆列表(包含 UUID)
- 正确判断新事实与哪条旧记忆关联
- 精确返回那个 UUID
UUID 是毫无语义的随机字符串(如 "a1b2c3d4-5678-9abc-def0-111111111111")。LLM 根本不具备精确复制 UUID 的能力。它可能返回一个不存在的 ID,或者篡改了几位字符。
这个问题的严重性怎么强调都不过分。让我们追踪一个 UUID 错误的后果链:
假设有两条记忆:
- ID
aaa-111: “用户是素食者” - ID
bbb-222: “用户喜欢跑步”
用户说"我最近改吃鱼了",LLM 应该 UPDATE aaa-111,但它错误地返回了 bbb-222。结果是"用户喜欢跑步"被覆盖为"用户最近改吃鱼了"。不仅正确的记忆没有被更新,另一条完全无关的记忆还被毁掉了。 这比不做任何操作还糟糕——不做操作至少不会破坏已有的正确数据。
更可怕的是,这种错误是静默的。系统不会报错——它忠实地执行了 UPDATE 操作,只是目标错了。你只有在下次检索"用户喜欢什么运动"时才发现记忆被篡改了,但你已经无法知道原始内容是什么(除非你有历史审计日志)。
V3 在 Phase 1 中意识到了这个问题,采用了 UUID 映射机制:把真实的 UUID 替换成简单的整数索引(0, 1, 2…)给 LLM 看,然后在后处理阶段映射回真实 ID。这降低了 LLM 返回错误 ID 的概率(整数比 UUID 简单得多),但没有从根本上消除风险——LLM 仍然可能返回 ID “3” 而列表中只有 0-2。
困境三:复杂对话的分类混乱——真实对话不按套路出牌
真实对话不是结构化的。“我今天加班到很晚,不过明天可以早退,对了上周那个项目延期了,我老板说可以申请额外资源。”
这段话里混合了:
- 事实陈述(加班到很晚)
- 计划变更(明天早退)
- 过去事件回顾(项目延期)
- 新信息(可以申请额外资源)
让 LLM 对每一条同时判断 ADD/UPDATE/DELETE,等于是要求它在理解语义的同时还要维护一个全局一致性状态。当记忆条目增多、话题交织时,LLM 的判断质量急剧下降。
更具体地说,分类混乱会以三种形式出现:
-
应该 ADD 的被 UPDATE:用户说"我买了个新椅子",LLM 发现已有记忆"用户在家办公",就 UPDATE 为"用户在家办公,买了新椅子"——把两条独立的事实合并了,导致检索"用户买了什么"时只能找到"椅子"但丢失了"在家办公"的独立性。
-
应该独立 ADD 的被合并:一条消息涉及三个话题,LLM 只提取了两条记忆,把第三个话题的信息塞进了第二条里——检索时只有同时匹配前两个话题才能找到第三条信息,召回率暴跌。
-
应该 ADD 的新信息被标为 NONE:LLM 认为"用户说加班到很晚"与已有记忆"用户工作很忙"语义重叠,标记为 NONE(不做变更)。但"加班到很晚"是一个具体事件,"工作很忙"是一个抽象状态——它们不是同一条信息。
困境四:多次 LLM 调用的延迟与成本——错误还会级联放大
V1/V2 的典型流程是:
- 第一次 LLM 调用:从对话中提取事实
- 第二次 LLM 调用:拿提取的事实与已有记忆对比,决定 ADD/UPDATE/DELETE
两次 LLM 调用意味着两倍的延迟和两倍的成本。以 GPT-4o 为例,每次调用的 p50 延迟约 1-2 秒,两次就是 2-4 秒。对于一个需要在实时对话中使用的记忆系统,这个延迟是致命的。
但更严重的问题是错误的级联放大:
- 如果提取阶段遗漏了一个关键事实,比对阶段根本看不到它——这条信息永久丢失。
- 如果提取阶段产生了一个幻觉事实,比对阶段可能基于这个幻觉做出错误的 UPDATE/DELETE 决策——不仅记了错误的东西,还可能破坏了正确的已有记忆。
- 如果比对阶段的已有记忆列表(通过向量检索获得)不完整(比如 top_k=10 但相关记忆排在第 11 位),LLM 就看不到真正的关联记忆,做出错误的 ADD 判断——同一条事实被重复添加。
两次调用之间没有反馈机制——第一次的错误无法在第二次被纠正,只会被继承和放大。
立:ADD-only 累积式提取
V3 的方案极其简洁——只做 ADD,不做 UPDATE,不做 DELETE。在 ADDITIVE_EXTRACTION_PROMPT 的开篇就定调:
Your sole operation is ADD: identify every piece of memorable
information and produce self-contained, contextually rich
factual statements.
一个"sole operation",把四重困境全部消解。但我们不能只说"消解"就完了——要追问到底:为什么"只做 ADD"就能解决这四个问题?
为什么单次 LLM 调用就够?
因为"提取事实"和"管理状态"是两种完全不同的认知任务。提取只需要理解语义——"用户说了什么值得记住的?"管理状态需要判断关系——“这句话和已有的哪些记忆是什么关系?应该增还是改还是删?”
当你把管理状态的任务从 LLM 的职责中剥离,LLM 只需要做它最擅长的事:理解语义。提取事实的准确率远高于判断操作类型的准确率,因为前者是单步推理(“这段话说了什么”),后者是多步推理(“这段话说了什么 → 和已有记忆什么关系 → 应该做什么操作”),每多一步推理就多一步出错的可能。
MD5 Hash 去重:为什么不是 SHA256?为什么不是语义去重?
ADD-only 最直接的担忧是重复:如果用户每次提到"我是软件工程师"都 ADD 一条新记忆,存储会无限膨胀。
V3 的解法是 MD5 hash 精确去重。在 Phase 4 中:
mem_hash = hashlib.md5(text.encode()).hexdigest()
if mem_hash in existing_hashes or mem_hash in seen_hashes:
continue
seen_hashes.add(mem_hash)
为什么用 MD5 而不是 SHA256?因为这里不需要密码学安全性——我们不需要防范"恶意构造碰撞",只需要在统计意义上避免误碰撞。MD5 产生 128 位哈希,碰撞概率约 2^-64,对于记忆系统来说完全足够。而 MD5 的计算速度比 SHA256 快约 3 倍——在每次 add 都要计算哈希的热路径上,这个差异是值得的。
为什么不用语义相似度去重?比如用 embedding 余弦相似度 > 0.95 就认为是重复?因为语义去重引入了一个新的不确定性来源——阈值的选择。“User is a software engineer” 和 “User works as a software developer” 的余弦相似度可能只有 0.88,低于 0.95 阈值,不会被去重——但它们确实是同一条信息。而 “User is a software engineer at Google” 和 “User is a software engineer at Meta” 的余弦相似度可能高达 0.96,超过阈值——但它们是完全不同的两条信息。
语义去重的根本问题是:相似度不等于等价性。两条文本可以高度相似但含义不同,也可以措辞完全不同但含义相同。没有任何一个阈值能同时正确处理这两种情况。Hash 去重放弃了语义层面的去重,换来了确定性保证——相同的文本一定去重,不同的文本一定不去重,没有灰色地带。
那语义层面的冗余怎么办?交给另一个机制处理:prompt 中的 Recently Extracted Memories 和 Existing Memories 让 LLM 在提取阶段就知道哪些事实已被捕获,从而在源头避免重复提取。这不是"去重",而是"不重复提取"——效果相似,但可靠性更高,因为 LLM 在 few-shot 示例的引导下判断"是否已捕获"比判断"是否应该 UPDATE/DELETE"要容易得多。
linked_memory_ids:用关联代替覆盖——为什么不直接覆盖?
如果用户先说"我喜欢披萨",后说"我改吃寿司了",ADD-only 意味着两条记忆都会存在。但 V3 并不是简单地把它们堆在一起不管。
ADDITIVE_EXTRACTION_PROMPT 要求 LLM 在提取新记忆时,如果发现与已有记忆的关联,把已有记忆的 ID 写入 linked_memory_ids:
When a new memory is related to an Existing Memory — same topic,
overlapping entities, updated/shifted preference, follow-up event,
or continuation of a narrative — include the Existing Memory's ID
in the new memory's "linked_memory_ids" array.
linked_memory_ids 的本质是一条时间线而不是一个快照。它记录了"Poppy 的健康状况"这个主题的演变,而不是用新状态覆盖旧状态。
为什么不直接覆盖?因为覆盖会丢失信息。考虑这个场景:
- 用户说"我喜欢披萨"→ 记忆 A:“用户喜欢披萨”
- 用户说"我改吃寿司了"→ 如果 UPDATE,记忆 A 变为"用户喜欢寿司"
- 用户问"我之前喜欢吃什么?"
如果你做了 UPDATE,第三步的答案是"寿司"——但用户明明问的是"之前",他想知道的是历史偏好。覆盖操作破坏了时间维度。
linked_memory_ids 保留了时间线:记忆 A 和记忆 B 同时存在,通过 linked_memory_ids 关联。检索时,系统可以根据查询的时间语义(“之前"vs"现在”)返回不同的记忆——这是一个 UPDATE 操作永远无法实现的能力。
检索时评分排序:冗余记忆不影响检索质量
当存储了多条相关记忆时,谁优先被返回?V3 在 search 方法中实现了一套混合评分机制:
- 语义向量检索:embedding 余弦相似度
- BM25 关键词匹配:基于 lemmatized text 的词频匹配,通过 sigmoid 归一化到 [0, 1]
- Entity Boost:从查询中提取实体,在 entity store 中匹配,对关联的记忆加分
最新添加的记忆天然有优势——它们与当前对话的语义距离更近,embedding 相似度更高。这意味着当用户说"我改吃寿司了"之后,“喜欢寿司"这条记忆的检索得分通常会高于旧的"喜欢披萨”,无需显式的 UPDATE 操作就能实现"新信息优先"的效果。
那旧的"喜欢披萨"怎么办?它会以较低的分数排在后面。如果你只需要 top 3 结果,它可能根本不会出现在返回列表中。但它仍然存在——如果用户问"我之前喜欢什么",它就能被召回了。
存储膨胀 vs 提取精度
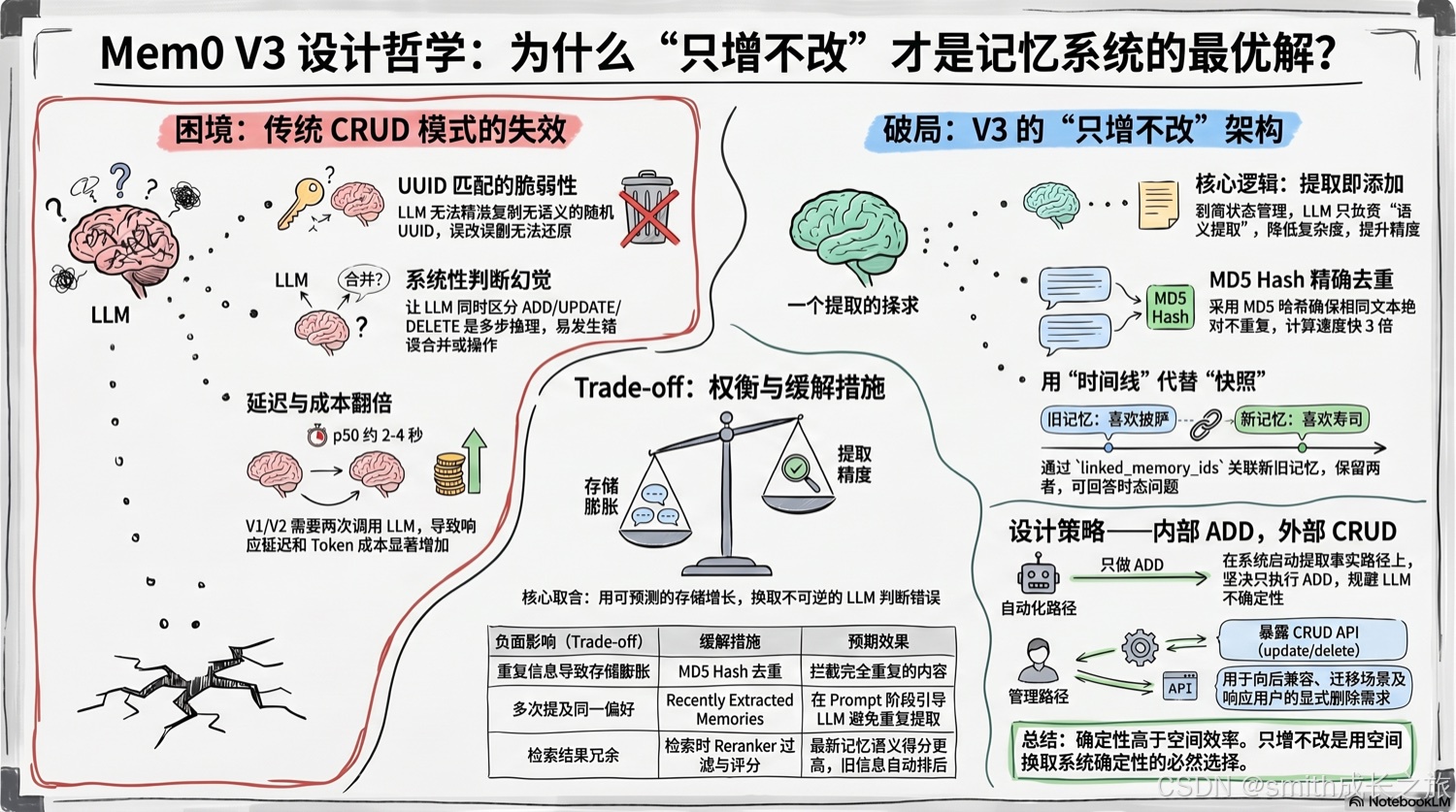
ADD-only 不是免费的。它的代价是存储膨胀:
- 用户反复提到同一偏好(但措辞略有不同),会产生多条语义重叠的记忆
- 偏好变迁后,旧记忆仍然存在,占用存储空间
- 随着对话累积,记忆数量线性增长
缓解机制有三层:
- hash 去重拦截完全重复的提取
- Recently Extracted Memories让 LLM 在提取阶段就知道哪些事实已被捕获,避免重复提取
- 检索时评分排序确保最相关的记忆优先返回,冗余记忆即使存在也不影响检索质量
真正的权衡在于:存储空间的增长是可预测、可控制的(可以通过定期清理或 TTL 机制管理),但 LLM 判断错误导致的 UPDATE/DELETE 误操作是不可预测、不可恢复的。
让我们精确比较两种失败的代价:
| 失败类型 | 发生概率 | 后果 | 可恢复性 |
|---|---|---|---|
| ADD 冗余(V3) | 中 | 多一条低分记忆,检索时被排序靠后 | 可通过定期清理解决 |
| UPDATE 错误目标(V1/V2) | 中 | 正确记忆被覆盖,无关记忆被篡改 | 不可恢复(除非有审计日志) |
| DELETE 错误目标(V1/V2) | 中 | 正确记忆被永久删除 | 不可恢复 |
| UPDATE 合并不当(V1/V2) | 高 | 独立事实被合并,丢失细节 | 不可恢复 |
一条被错误 DELETE 的记忆永远丢失了。一条被错误 UPDATE 覆盖的原始信息无法还原。而一条冗余 ADD 的记忆,最坏情况只是在检索时多了一条低分结果,不会破坏已有数据的正确性。
这是一个经典的可靠性 vs 效率权衡。Mem0 选择了可靠性,因为记忆系统的核心价值不是存储效率,而是信息完整性。丢失一条记忆的代价远大于多存一条冗余记忆的代价。
为什么 UPDATE 和 DELETE 仍然作为 API 存在
值得注意的是,Memory.update() 和 Memory.delete() 方法在 V3 的代码中依然存在,但它们是用户主动调用的管理接口,不是 LLM 自动执行的路径。
区分两条路径至关重要:
- 自动路径(
add()内部的 LLM 提取):只做 ADD,因为 LLM 不可靠 - 手动路径(用户显式调用
update()/delete()):允许 UPDATE/DELETE,因为人类决策可靠
这就像数据库的写入路径和 DBA 的维护操作是分开的一样。自动写入保证安全(只增),维护操作允许破坏性变更(因为有人类背书)。
小结
V3 的 ADD-only 不是偷懒,而是从工程实践中提炼出的设计智慧:
| 维度 | ADD/UPDATE/DELETE | ADD-only |
|---|---|---|
| LLM 调用次数 | 2次(提取+比对) | 1次(提取) |
| LLM 任务复杂度 | 理解+判断+匹配ID | 理解+提取 |
| 去重方式 | 语义去重(LLM判断,不可靠) | hash精确去重+检索评分 |
| 偏好变迁处理 | UPDATE覆盖(丢失历史) | ADD新记忆+linked_memory_ids关联 |
| 存储增长 | 受控(覆盖旧数据) | 线性增长(但有缓解机制) |
| 数据一致性 | 不可靠(LLM幻觉风险) | 确定性强(hash去重可验证) |
| 错误可恢复性 | 不可恢复(覆盖/删除是破坏性的) | 可恢复(冗余ADD不破坏已有数据) |
“只增不改"的本质是用空间换确定性。在一个记忆系统中,确定性远比空间效率重要——因为记忆的价值不在于"存了多少”,而在于"存对了没有"。ADD-only 不是妥协,而是必然——但"只做 ADD"只回答了"做什么",真正的难题是"怎么 ADD":一个 500 行的 ADDITIVE_EXTRACTION_PROMPT,到底在防什么?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)