第 004 期精读:DuplexSLA 如何打破 ASR→LLM→TTS 的串行枷锁,实现 160ms 全双工对话
Speech AI · FRONTIER — 第 004 期精读
DuplexSLA:第一个把"听说想"压进同一个 160ms 的语音大模型
📄 原文:DuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
👥 作者:Haoyang Zhang, Jun Chen, Donghang Wu, Yuxin Li, Yuxin Zhang 等(共 16 位,来自多个机构)
📅 日期:2026-05-20 | 🏷️ 来源:arXiv eess.AS | 💻 代码:github.com/hyzhang24/DuplexSLA
📌 一句话总结
DuplexSLA 用一个统一的自回归模型,在每 160ms 的时间块里同时完成"听用户说话、生成自己的语音、规划动作/调用工具",彻底告别了传统语音助手 ASR→LLM→TTS 的串行管线。
🤔 这篇论文要解决什么问题?
痛点一:串行管线的天然延迟。 当前主流语音助手的架构是 VAD → ASR → LLM → TTS 的顺序流水线,用户说完一句话之后,系统才开始识别、理解、生成语音回复。这条链路上每个模块都要等上一个模块,总延迟往往在 2~5 秒,远远无法支撑自然对话。
痛点二:打断、回声、重叠无法处理。 人类对话里充斥着"嗯"“对”"等一下"这样的插话(回声/backchannel)和真正的打断(interrupt)。传统系统没有实时监听用户的能力——它在说话时根本听不到用户。要想支持打断,必须在 TTS 之外额外挂一个 VAD 模块硬切,效果粗糙且容易误触发。
痛点三:边说边规划/调用工具是空白。 现有方案里,工具调用(Tool Calling)只能在 LLM 生成文本完成后触发,用户必须等助理说完才能看到工具执行结果。如果能在助理讲话的同时悄悄发起工具请求,整体交互效率会提升一个量级。
DuplexSLA 的切入点是:把以上三件事——听(Listening)、说(Speaking)、想/做(Action)——压缩进同一个自回归模型的同一个时间块里,让三者真正并行,而不是顺序堆叠。
🏗️ 核心方法
整体架构
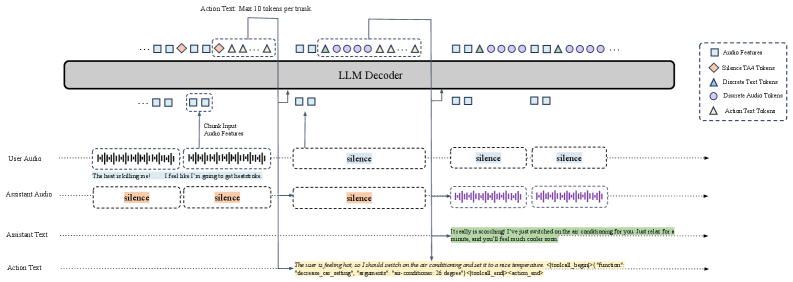
▲ 架构图详解:
图 1 展示了 DuplexSLA 的核心时间线设计。整个系统以 160ms 为一个处理单元(chunk),三条通道在同一个 chunk 内严格同步:
- 用户通道(User Channel):每个 chunk 贡献 2 帧因果音频特征,每帧覆盖 80ms,完整覆盖当前 chunk 的用户侧音频,且只使用过去和当前帧(因果,不看未来)。
- 助理通道(Assistant Channel):每个 chunk 产出 1 个 TA4 单元,TA4 = 1 个文本锚点(Text Anchor)+ 4 个离散音频 token,每个音频 token 对应 40ms 语音,4 个合计恰好是 160ms,与 chunk 对齐。文本锚点是当前 chunk 的转写字符,作为语义锚定。
- 动作通道(Action Channel):每个 chunk 最多发出 10 个文本 token,内容可以是延迟转写(ASR 文本)、规划文本、交互标签(response/interrupt/backchannel/asr),或工具调用(函数名+参数)。超出 10 个 token 的部分溢出到下一个 chunk,遵循 FIFO 队列纪律。
同一个 7B 规模的骨干语言模型(初始化自 Step-Audio 2 mini)在一次前向中同时自回归预测助理 TA4 和动作文本,用户音频特征作为条件输入。整个设计的核心约束是:所有决策都在 160ms 内完成,不依赖任何外部 VAD 或独立的 ASR 模块。
关键技术点一:TA4——把文本锚点织进语音 token
是什么
传统语音 LM 要么只生成音频 token(如 VoiceCraft),要么先生成文本再合成语音(串行)。TA4(Text Anchor + 4 Audio tokens)在每 40ms 粒度上将一个文本字符与 4 个声学 token 绑定,二者同时预测。
为什么有效
文本锚点给声学 token 提供了强语义约束,避免了纯音频自回归常见的音节漂移和重复问题。同时,文本锚点精确记录了"这个字是在哪个 chunk 说出来的",为动作通道的时间对齐提供了基准——动作 token 可以精确地在"说到这个词时"触发。
与已有方法的区别
已有的双工模型(如 IntrinsicVoice)大多将文本和语音解耦到不同解码头,缺乏帧级时间对齐。TA4 将两者绑定在同一个 40ms stride 内,使得"说到哪个字"和"做了什么动作"之间的时间关系可精确追踪。
关键技术点二:原生轮次控制(Turn-Taking)
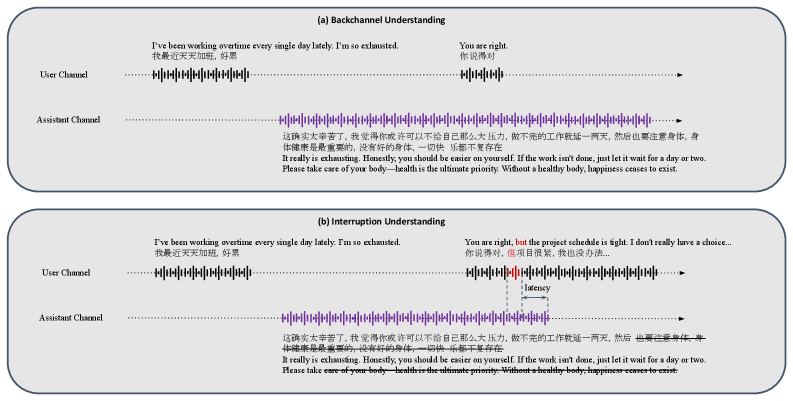
▲ 交互控制行为详解:
图 2 展示了两种核心交互控制场景。图 2(a) 是回声(Backchannel)场景:用户说"You are right",这是一句话题无关的简短反馈,DuplexSLA 在动作通道发出 backchannel 标签,助理语音继续播放不打断。图 2(b) 是**打断(Interrupt)**场景:用户说"You are right, but the project schedule is tight…",前半段与 (a) 相同,但后半段携带新的话题意图,模型检测到语义上的"floor transfer"信号,动作通道发出 interrupt 标签,助理在 chunk 级延迟内(≤160ms 感知延迟)让出发言权。
这两种行为完全由骨干模型的内部状态驱动,不依赖任何外部 VAD 或规则系统。模型在训练时见过大量带标注的 backchannel/interrupt/pause 样例(post-training 阶段约 36k 小时),习得了从声学+语义联合信号中判断用户意图的能力。Pause 场景(用户停顿但未结束)同样被纳入训练,避免"用户思考时被误打断"的常见问题。
关键技术点三:边说边调工具(In-Conversation Tool Calling)
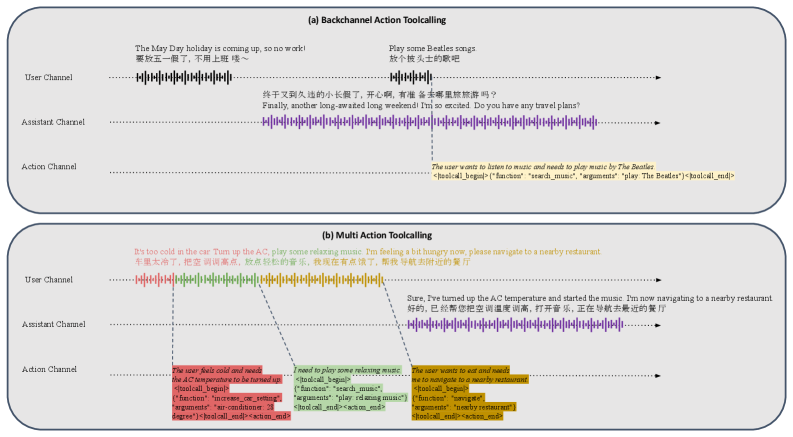
▲ 工具调用集成详解:
图 3 展示了两种工具调用场景。图 3(a) Backchannel 触发工具调用:用户在助理讲话中途简短说"帮我放首披头士",动作通道在不打断助理语音的前提下悄悄发出 play_music("The Beatles"),助理语音和工具执行并行运行。图 3(b) 多动作工具调用:用户一句话包含三个意图(调空调、放音乐、导航),模型按语义顺序在动作通道串行发出三条工具调用,每条调用的触发时间与其在助理话语中被"语义暗示"的 chunk 对齐。工具调用的语义偏移(semantic offset)在数据构建时由 LLM 标注,训练时模型学习复现这个对齐关系。评测中 DuplexSLA 平均工具调用延迟为 0.64 秒,而 ASR+LLM 级联方案需要 2.77 秒,约快 4 倍。
数据构建与训练策略
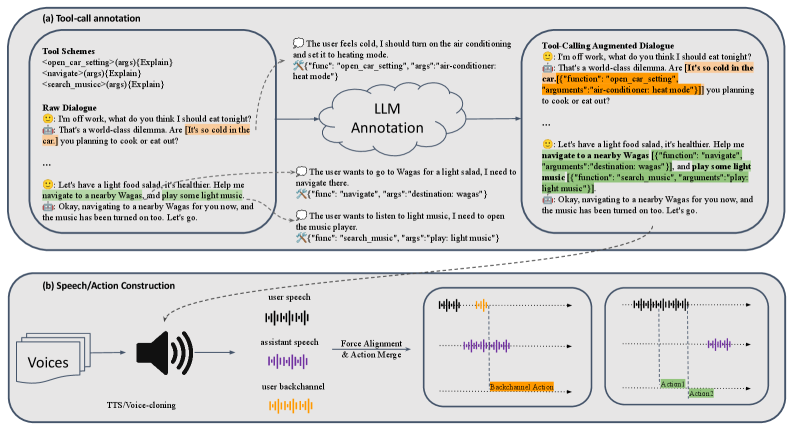
▲ 数据构建流程详解:
图 4 展示了数据构建的两个阶段。阶段 (a):LLM 对原始对话文本进行标注,为每段对话添加工具调用对象(函数名、参数、规划文本、语义偏移量)和交互标签(backchannel/interrupt/pause)。阶段 (b):将用户侧和助理侧的文本分别用 TTS 和声音克隆合成为音频,通过强制对齐将字符与音频帧绑定,再按 160ms chunk 网格将双侧音频、动作标签合并成训练格式,输出完整的三通道训练样本。
训练分两阶段:持续预训练(CPT) 使用约 50 万小时音频(双工对话 32 万小时 + 双侧 ASR 各 9 万小时)和 192 万文本样本,目标是让模型习得 chunk 格式和时间对齐;能力后训练(Post-Training) 使用约 5 万小时更精准的数据(交互控制 3.6 万小时 + 工具调用 1.4 万小时),聚焦于轮次控制和工具调用的精确行为。损失函数为标准交叉熵,作用于助理 TA4 token 和动作 token,辅以全双工感知的掩码和对关键状态 token(如 interrupt、backchannel 标签)的逐 token 重加权。
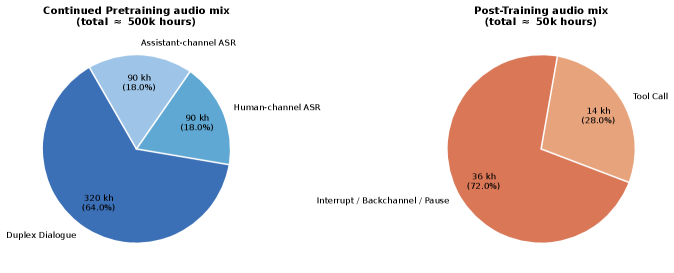
▲ 训练数据分布:图 5 直观展示了 CPT 和 Post-Training 的数据构成。CPT 以双工对话为主(约 64%),双侧 ASR 各占约 18%,强调时间对齐的基础能力;Post-Training 以交互控制数据为主(约 72%),工具调用约 28%,强调精细化行为能力。
📊 实验结果
DuplexSLA-Bench 轮次控制评测(Context Prefill 设置)
评测集共 2,100 条(轮次控制 1,200 + 工具调用 900),每类 300 条。
| 场景 | 准确率 | 延迟 |
|---|---|---|
| Normal(正常响应) | 96.00% | 0.27s |
| Pause(用户停顿) | 93.33% | 0.27s |
| Interrupt(用户打断) | 99.33% | 0.40s |
| Backchannel(用户回声) | 98.33% | 0.32s |
📌 关键数据:四类场景准确率均超 93%,延迟均在 0.4 秒以内;Backchannel 场景是评测中唯一有原生支持的系统。
工具调用评测对比(DuplexSLA vs ASR+LLM 级联)
| 系统 | 平均准确率 | 平均延迟 |
|---|---|---|
| DuplexSLA | 85.56% | 0.64s |
| ASR+LLM 级联 | 91.33% | 2.77s |
📌 关键数据:DuplexSLA 延迟仅为级联系统的 23%(约快 4 倍),准确率差距为 5.77%,是以少量准确率换取大幅延迟压缩的典型工程权衡。
无上下文预填充设置(更贴近实际部署)
| 场景 | 平均准确率 | 平均延迟 |
|---|---|---|
| Normal + Pause | 94.34% | 0.30s |
📌 关键数据:无预填充下平均延迟仅 0.30 秒,是评测中唯一延迟低于 1 秒且准确率具竞争力的系统。
消融实验亮点
双侧 ASR 监督的必要性:移除双侧 ASR(即去掉助理侧转写的重新发射和时间锚定)后,工具调用的触发时间偏移显著增大,说明文本锚点对动作通道的时间对齐至关重要。
Post-Training 数据规模的影响:仅用 CPT 模型(无 Post-Training)时,Interrupt 场景准确率大幅下降,误打断率(将 Backchannel 误识别为 Interrupt)明显上升,印证了精细化后训练数据的必要性。
💡 个人点评
优势——范式清晰,工程意义突出。 DuplexSLA 最大的贡献不是某个具体算法,而是提出了一个完整、自洽的三通道统一框架,并附上了开源代码和评测基准。TA4 格式将语音 token 与文字时间戳绑定的设计尤其精妙,既保留了离散 token 便于自回归建模的优势,又解决了动作通道时间对齐的难题。
局限——工具调用准确率尚有差距。 相比 ASR+LLM 级联的 91.33%,DuplexSLA 只达到 85.56%,差距约 6 个点。在需要高准确率工具调用的场景(如医疗、金融)中,这个差距不可忽视。此外,当前工具 schema 仅涵盖 50 个车机/智能家居函数,真实场景的工具数量往往是数百至数千,泛化能力有待验证。
工程价值——对实时语音产品的直接启发。 160ms 的处理粒度对 GPU/NPU 推理的吞吐量要求是明确的,工程落地时需重点评估批处理策略和推理加速。TA4 格式和三通道数据构建流程都有详细描述,对自建双工语音系统的团队有很强的参考价值。
未来方向——多模态扩展与更大规模工具池。 动作通道的设计天然支持扩展:可以将工具调用之外的"视觉感知结果"、"数据库查询结果"也流入动作通道,向真正的多模态全双工智能体演进。同时,如何在工具数量扩展到数千时保持准确率,是下一个值得攻克的工程问题。
🔗 资源链接
- 📄 论文链接:arxiv.org/abs/2605.20755
- 💻 代码与评测基准:github.com/hyzhang24/DuplexSLA
- 🎯 相关论文推荐:
- Step-Audio 2(DuplexSLA 骨干模型来源):arxiv.org/abs/2502.11946
- Mini-Omni2(早期双工探索):arxiv.org/abs/2410.11190
- IntrinsicVoice(双工对话模型对比基线):arxiv.org/abs/2410.08035
Speech AI · FRONTIER · 论文精读系列 · 第 004 期
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文解读与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)