【RT-2论文阅读】:首次实现把互联网知识装进机器人大脑的视觉-语言-动作大模型
论文信息
- 标题:RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 会议:arXiv preprint (2023)
- 机构:Google DeepMind
- 代码:github.com/google-research/robotics_transformer
- 论文:https://arxiv.org/pdf/2307.15818
一、引言:机器人终于能"上网学习"了
还记得我们上次聊的RT-1吗?那个能完成700多个任务的机器人Transformer确实很厉害,但它有个致命的缺点:它的所有知识都只能来自机器人自己的演示数据。这就像一个孩子只能从自己的亲身经历中学习,永远不能看书、不能上网,那他的知识面肯定非常有限。
而我们人类之所以聪明,很大程度上是因为我们能通过语言和文字,学习前人积累的海量知识。那能不能让机器人也这样呢?能不能让机器人直接从互联网上的数十亿张图片和文本中学习,然后把这些知识用到真实世界的操作中?
这就是RT-2(Robotics Transformer 2)要解决的问题。RT-2提出了一个极其简单但又极其有效的想法:把机器人的动作也当成一种语言。这样一来,我们就可以直接用训练视觉-语言模型(VLM)的方法来训练机器人控制模型,让机器人直接继承互联网上的海量知识。
二、RT-2整体架构:视觉-语言-动作三位一体
RT-2的核心创新是提出了视觉-语言-动作(VLA)模型的概念。它不再把机器人控制当成一个独立的问题,而是把它变成了一个多模态生成问题。
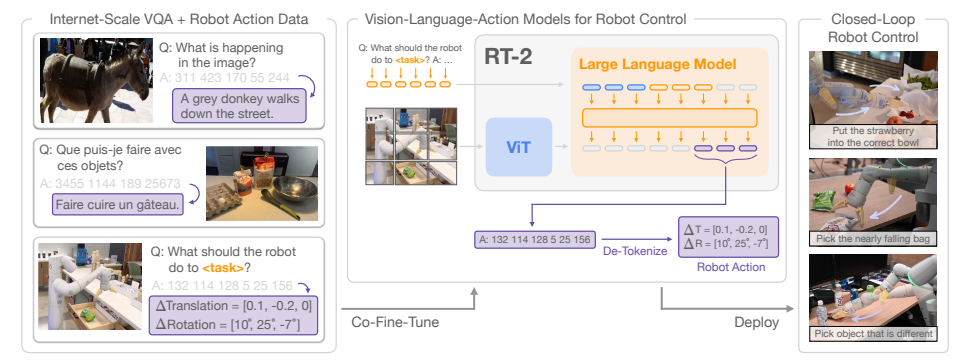
图1:RT-2整体架构概览(来源:论文Figure 1)
从图1可以看出,RT-2的工作流程非常简单:
- 输入:一张机器人摄像头拍摄的图像和一个自然语言指令(比如"把草莓放进正确的碗里")
- 处理:一个大型预训练视觉-语言模型(VLM)同时处理图像和文本
- 输出:一串表示机器人动作的文本token,这些token会被解码成真实的机器人控制命令
通俗易懂的解释:你可以把RT-2想象成一个"全能机器人管家"。它不仅能听懂你说的话(语言理解),能看清周围的环境(视觉感知),还能自己决定应该做什么动作(动作生成)。最神奇的是,它的这些能力有很大一部分是从互联网上学来的,而不是只能从机器人的演示中学习。
RT-2并不是从零开始构建的,而是基于两个已经非常强大的预训练VLM:
- PaLI-X:谷歌最新的多语言视觉-语言模型,有5B和55B两个版本
- PaLM-E:谷歌的具身多模态语言模型,有12B版本
三、核心技术细节
3.1 最关键的创新:把动作变成语言
RT-2最天才的地方就是它的动作表示方法。它没有像传统机器人学习那样使用连续的动作向量,而是把机器人的每个动作都编码成一串文本token。
具体来说,RT-2使用了和RT-1相同的动作空间:
- 7个手臂维度:x, y, z(位置),roll, pitch, yaw(姿态),gripper(夹爪开合度)
- 1个终止维度:表示任务是否完成
每个连续维度都被离散化为256个bin,这样一个完整的机器人动作就可以用8个整数来表示。例如,一个动作可能是:1 128 91 241 5 101 127 255。
然后,RT-2把这8个整数直接当成文本token来处理。对于不同的VLM,处理方式略有不同:
- PaLI-X:它的词汇表中本来就有0-1000的数字token,所以直接使用这些token来表示动作
- PaLM-E:它没有专门的数字token,所以RT-2直接覆盖了它词汇表中256个最不常用的token来表示动作
通俗易懂的解释:这就像我们教机器人一门新的语言,每个动作都是一个"句子",由8个"单词"(数字)组成。这样一来,大模型就可以像理解和生成自然语言一样,理解和生成机器人的动作了。
3.2 联合微调:让机器人不忘本
如果我们直接用机器人数据微调一个预训练的VLM,会发生什么?模型会很快忘记它在互联网上学到的知识,这就是所谓的"灾难性遗忘"。
为了解决这个问题,RT-2使用了联合微调(co-fine-tuning)的方法:
Ltotal=λLrobot+(1−λ)Lweb\mathcal{L}_{\text{total}} = \lambda \mathcal{L}_{\text{robot}} + (1-\lambda) \mathcal{L}_{\text{web}}Ltotal=λLrobot+(1−λ)Lweb
其中:
- Lrobot\mathcal{L}_{\text{robot}}Lrobot:机器人任务的损失函数(下一个token预测)
- Lweb\mathcal{L}_{\text{web}}Lweb:互联网任务的损失函数(VQA、图像描述等)
- λ\lambdaλ:平衡两个任务的权重,RT-2-PaLI-X设置为0.5,RT-2-PaLM-E设置为0.66
通俗易懂的解释:这就像我们在学习一门新技能的时候,不能把以前学的知识都忘了。联合微调就是让模型在学习机器人控制的同时,还要继续做它以前会做的事情(比如回答问题、描述图片),这样它就能保留从互联网上学到的知识。
3.3 实时推理:让大模型跑在机器人上
RT-2最大的挑战之一是它的模型规模太大了。最大的RT-2-PaLI-X-55B模型有550亿个参数,这在普通的机器人GPU上根本跑不起来。
为了解决这个问题,谷歌的研究人员采用了云-边协同的方案:
- 把RT-2模型部署在谷歌云的TPU集群上
- 机器人通过网络把图像和指令发送到云端
- 云端的模型计算出动作token,然后发送回机器人
- 机器人解码动作token并执行
通过这种方式,RT-2-PaLI-X-55B可以达到1-3Hz的控制频率,而较小的RT-2-PaLI-X-5B可以达到5Hz,完全满足实时控制的要求。
四、实验结果与分析
谷歌的研究人员进行了超过6000次真实世界的机器人实验,全面评估了RT-2的性能。
4.1 整体性能对比
研究人员将RT-2与四个最先进的基线模型进行了对比:
- RT-1:上一代机器人Transformer
- VC-1:专为机器人设计的视觉基础模型
- R3M:基于人类视频预训练的视觉表示模型
- MOO:使用VLM进行语义分割的机器人模型
对比结果如下:
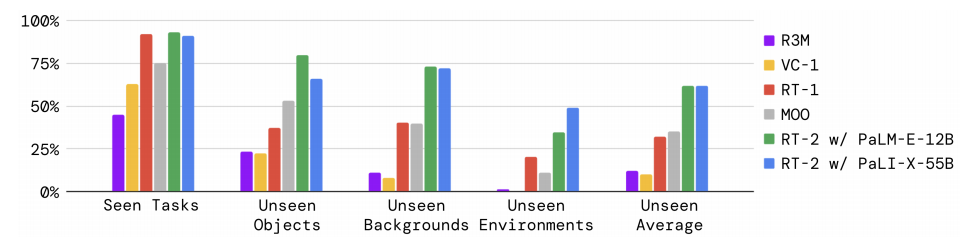
图2:RT-2与基线模型的整体性能对比(来源:论文Figure 4)
从图2可以看出:
- 已见任务:RT-2的性能和RT-1差不多,都在90%以上
- 未见任务:RT-2的性能是RT-1的2倍,是其他基线的6倍
- 泛化能力:RT-2在未见物体、未见背景和未见环境上的表现都远远超过了所有基线
这说明RT-2确实成功地将互联网上的知识迁移到了机器人控制中,大大提高了模型的泛化能力。
4.2 Language-Table基准测试
为了进一步验证RT-2的通用性,研究人员还在开源的Language-Table仿真环境上进行了测试:
| Model | Language-Table Success Rate |
|---|---|
| BC-Zero | 72 ± 3 |
| RT-1 | 74 ± 13 |
| LAVA | 77 ± 4 |
| RT-2-PaLI-3B (ours) | 90 ± 10 |
表1:Language-Table仿真环境测试结果(来源:论文Table 1)
RT-2在这个完全不同的仿真环境上也取得了最好的成绩,说明它的方法具有很好的通用性。
4.3 最惊艳的部分:涌现能力
RT-2最令人兴奋的地方是它展现出了一系列涌现能力。这些能力从来没有在机器人的演示数据中出现过,完全是从互联网级别的预训练中继承来的。
研究人员把这些涌现能力分为三类:
- 符号理解:理解数字、图标、标志等抽象符号
- 推理:进行视觉推理、数学推理、多语言理解等
- 人类识别:识别人类的特征和身份
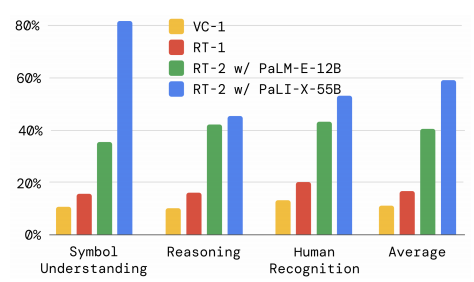
图3:RT-2的涌现能力对比(来源:论文Figure 6a)
从图3可以看出,RT-2在这些涌现能力上的表现是RT-1的3倍以上。
有趣的案例:
- 符号理解:RT-2可以执行"把苹果移到数字3上"、"把可乐罐放在心形图标上"这样的指令,尽管它从来没有在机器人数据中见过这些数字和图标
- 推理:RT-2可以执行"把苹果移到相同颜色的杯子里"、"拿一个健康的饮料"这样的指令,这需要它理解颜色匹配和健康概念
- 多语言:RT-2可以执行法语指令"déplacer les frites verts dans la tasse rouge"(把绿色薯条放进红色杯子里)
- 人类识别:RT-2可以执行"把可乐罐移到戴眼镜的人那里"这样的指令
4.4 模型大小与训练策略消融
研究人员还进行了一系列消融实验,研究模型大小和训练策略对性能的影响:
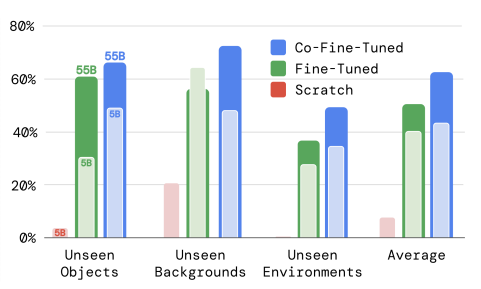
图4:模型大小与训练策略消融(来源:论文Figure 6b)
从图4可以得出三个重要结论:
- 从零开始训练完全不行:即使是5B参数的模型,从零开始训练的性能也非常差
- 联合微调比只微调机器人数据好:联合微调可以让模型保留更多的预训练知识,从而获得更好的泛化能力
- 模型越大,泛化能力越好:55B参数的RT-2-PaLI-X比5B参数的版本泛化能力强很多
4.5 思维链推理:让机器人先思考再行动
受到大语言模型中思维链(Chain-of-Thought)提示的启发,研究人员还尝试让RT-2先生成一个自然语言的计划,然后再生成动作。
他们只需要对训练数据做一个小小的修改:在动作token前面加上一个"Plan:"部分,例如:
Instruction: 我饿了。
Plan: 拿巧克力能量棒。
Action: 1 128 124 136 121 158 111 255
结果令人惊讶:RT-2现在可以进行非常复杂的语义推理了!

图5:RT-2的思维链推理示例(来源:论文Figure 7)
最有趣的案例:
- 指令:“我需要钉一个钉子,场景中的哪个物体可能有用?”
- RT-2的回答:“Plan: 拿石头。Action: 1 129 138 122 132 135 106 127”
RT-2竟然知道石头可以当锤子用!这完全是从互联网上学来的知识,从来没有在机器人数据中出现过。
五、核心代码实现
下面是RT-2模型的核心代码实现(基于PyTorch和HuggingFace Transformers):
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor
class RT2ActionTokenizer:
"""RT-2动作tokenizer,将机器人动作转换为文本token"""
def __init__(self, num_bins=256, action_dim=8):
self.num_bins = num_bins
self.action_dim = action_dim
# 动作范围,需要根据实际机器人调整
self.action_ranges = [
(-0.1, 0.1), # delta x
(-0.1, 0.1), # delta y
(-0.1, 0.1), # delta z
(-10, 10), # delta roll (degrees)
(-10, 10), # delta pitch (degrees)
(-10, 10), # delta yaw (degrees)
(0, 1), # gripper opening
(0, 1) # terminate
]
def encode(self, action):
"""将连续动作编码为数字token字符串"""
tokens = []
for i in range(self.action_dim):
min_val, max_val = self.action_ranges[i]
# 将连续值离散化为0-255的整数
bin_idx = int((action[i] - min_val) / (max_val - min_val) * (self.num_bins - 1))
bin_idx = max(0, min(self.num_bins - 1, bin_idx))
tokens.append(str(bin_idx))
return " ".join(tokens)
def decode(self, token_str):
"""将数字token字符串解码为连续动作"""
tokens = token_str.strip().split()
action = []
for i in range(self.action_dim):
bin_idx = int(tokens[i])
min_val, max_val = self.action_ranges[i]
# 将离散整数转换回连续值
val = min_val + (bin_idx / (self.num_bins - 1)) * (max_val - min_val)
action.append(val)
return action
class RT2(nn.Module):
"""RT-2视觉-语言-动作模型"""
def __init__(self, model_name="google/paligemma-3b-mix-224", num_bins=256, action_dim=8):
super().__init__()
self.processor = PaliGemmaProcessor.from_pretrained(model_name)
self.model = PaliGemmaForConditionalGeneration.from_pretrained(model_name)
self.action_tokenizer = RT2ActionTokenizer(num_bins, action_dim)
# 冻结大部分参数,只微调最后几层
for param in self.model.parameters():
param.requires_grad = False
for param in self.model.language_model.lm_head.parameters():
param.requires_grad = True
for param in self.model.language_model.model.layers[-2:].parameters():
param.requires_grad = True
def forward(self, images, instructions, actions=None):
"""
前向传播
Args:
images: 机器人摄像头图像 (batch_size, 3, height, width)
instructions: 自然语言指令列表
actions: 机器人动作张量 (batch_size, action_dim),训练时需要
Returns:
loss: 训练损失(训练模式)
action_logits: 动作logits(推理模式)
"""
batch_size = images.shape[0]
# 构建输入提示
prompts = []
for instr in instructions:
prompt = f"Q: What action should the robot take to {instr}? A:"
prompts.append(prompt)
# 处理图像和文本
inputs = self.processor(
text=prompts,
images=images,
return_tensors="pt",
padding=True,
truncation=True
).to(self.model.device)
if actions is not None:
# 训练模式:计算损失
labels = []
for i in range(batch_size):
action_str = self.action_tokenizer.encode(actions[i])
label = self.processor.tokenizer(
action_str,
return_tensors="pt",
padding="max_length",
max_length=16,
truncation=True
).input_ids[0].to(self.model.device)
labels.append(label)
labels = torch.stack(labels)
# 前向传播
outputs = self.model(**inputs, labels=labels)
return outputs.loss
else:
# 推理模式:生成动作token
outputs = self.model.generate(
**inputs,
max_new_tokens=16,
num_beams=1,
do_sample=False
)
# 解码动作
generated_text = self.processor.batch_decode(outputs, skip_special_tokens=True)
actions = []
for text in generated_text:
# 提取动作部分
action_str = text.split("A:")[-1].strip()
try:
action = self.action_tokenizer.decode(action_str)
except:
# 如果解码失败,返回一个安全的动作
action = [0.0] * self.action_tokenizer.action_dim
actions.append(action)
return torch.tensor(actions)
# 示例用法
if __name__ == "__main__":
# 初始化模型
model = RT2()
# 模拟输入
batch_size = 2
images = torch.randn(batch_size, 3, 224, 224)
instructions = ["pick up the coke can", "move the apple to the bowl"]
# 推理
predicted_actions = model(images, instructions)
print(f"Predicted actions shape: {predicted_actions.shape}")
print(f"Predicted actions: {predicted_actions}")
# 训练
true_actions = torch.randn(batch_size, 8)
loss = model(images, instructions, true_actions)
print(f"Training loss: {loss.item()}")
六、结论与展望
RT-2是机器人学习领域的一个革命性突破。它证明了:
- 我们可以直接将互联网级别的视觉-语言知识迁移到机器人控制中
- 把动作当成语言是一个极其简单且有效的方法
- VLA模型可以展现出令人惊讶的涌现能力,包括符号理解、推理和人类识别
当然,RT-2也有一些局限性:
- 不能学习新的动作:RT-2只能复用在机器人数据中见过的动作,不能学习全新的运动技能
- 计算成本高:需要在云端的TPU集群上运行,延迟较高
- 推理能力有限:只能进行简单的单步推理,不能进行复杂的多步规划
未来的研究方向包括:
- 扩大模型规模和数据集规模
- 让模型能够学习新的动作技能
- 结合强化学习进一步提升性能
- 研究模型压缩和蒸馏技术,让大模型能够直接在机器人上运行
有趣的展望:想象一下,未来的机器人可以直接在互联网上学习新技能。你想让你的机器人学会泡咖啡吗?它只需要在YouTube上看几个视频,然后就可以自己动手了。RT-2让我们离这个梦想又近了一大步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)