2026山东大学软件学院项目实训个人blog(七)
目录
一、本期个人核心任务
负责AI 图片收集服务的设计与落地、工作节点开发及提示词增强节点实现,打通 “图片素材收集→提示词融合→内容生成” 的链路,解决平台生成内容缺乏图片素材支撑的问题,提升 AI 生成项目的视觉丰富度与素材适配性。
二、核心开发与技术落地
当前平台生成的前端内容仅依赖文本信息,缺乏图片素材的配套支撑,导致生成的项目视觉效果单一,无法满足用户对丰富视觉呈现的需求。
因此本次开发的核心目标是:构建 AI 驱动的图片素材收集能力,通过工作节点串联图片收集与提示词增强流程,让 AI 在生成内容时可直接调用收集到的图片素材,提升生成内容的完整性与美观度。
(一)需求分析
平台现有生成链路仅聚焦于代码 / 文本内容生成,未考虑视觉素材的配套生成与使用,具体痛点包括:
-
生成的网页无配套图片素材,需用户手动补充,使用体验差;
-
缺乏标准化的图片素材收集机制,AI 无法自主获取适配的图片资源;
-
图片素材与生成逻辑割裂,无法融入到前端项目生成的提示词体系中。
为解决上述问题,本次开发需实现:
-
构建 AI 图片收集服务,支持 AI 自主获取适配场景的图片素材信息;
-
开发工作节点,将图片收集能力融入现有工作流,实现自动化调用;
-
实现提示词增强节点,将收集到的图片信息融合到原始提示词中,引导 AI 利用素材生成内容;
通过本次需求落地,平台将新增 “图片素材收集” 能力,形成 “素材收集→提示词增强→内容生成” 的完整链路,提升生成内容的视觉表现力。
(二)方案设计
针对 AI 图片收集与融合的需求,梳理了两种技术方案并进行对比分析:
1. 结构化输出方案
基于 LangChain4j 的结构化输出能力,定义 JSON Schema 约束 AI 返回格式,让 AI 直接返回 List 类型的图片信息结构,后端可直接解析使用。
该方案的优势是数据格式规范、解析成本低,可直接将返回结果映射为 Java 对象,便于后续逻辑处理;
理想情况下 AI 服务肯定是采用结构化输出:
/**
* 图片收集 AI 服务接口
* 使用 AI 调用工具收集不同类型的图片资源
*/
public interface ImageCollectionService {
/**
* 根据用户提示词收集所需的图片资源
* AI 会根据需求自主选择调用相应的工具
*/
@SystemMessage(fromResource = "prompt/image-collection-system-prompt.txt")
List<ImageResource> collectImages(@UserMessage String userPrompt);
}但由于我们返回的是 List<POJO> 类型,这里会遇到一些坑!
首先,要配置结构化输出的 JSON Schema,必须要开启下列设置才能支持返回这种类型:
supportedCapabilities(RESPONSE_FORMAT_JSON_SCHEMA)

否则会报错:
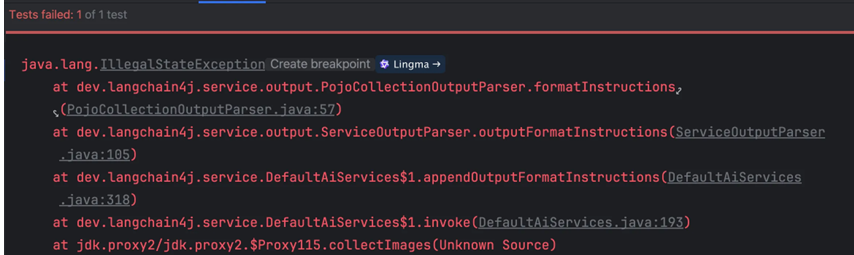
但是,DeepSeek 模型又不支持这个参数!
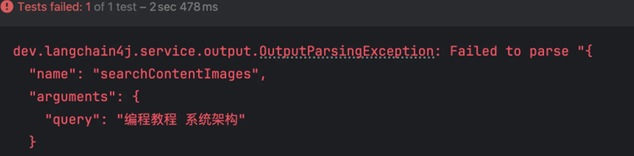
然后我尝试了 阿里云百炼模型,因为它也兼容 Open AI,但是必须要在提示词中引导 AI 回复 JSON 格式:

结果,我测试阿里云百炼大模型时发现,AI 的工具调用意图被错误地尝试解析为结构化输出的返回值:
2. 文本输出 + 后续处理方案
放弃结构化输出,让 AI 以纯文本格式返回图片信息。
复用原有 ChatModel 配置,通过提示词引导 AI 输出规范格式的文本(如按固定分隔符拼接图片 URL、描述等),后续在工作节点中对文本进行解析 / 拼接处理。
3. 最终方案
综合模型兼容性,最终选择第二种方案 ——文本输出 + 后续处理。
核心思路:
-
复用现有 ChatModel 配置,避免新增模型适配成本;
-
通过定制化提示词引导 AI 输出规范格式的图片信息文本;
-
开发工作节点完成图片信息的接收与传递,再通过提示词增强节点将文本信息融合到原始提示词中,规避结构化输出的兼容性问题。
(三)提示词设计
为保证 AI 收集的图片素材适配前端生成场景,定制了专属的图片收集系统提示词(image-collection-system-prompt.txt:
你是一个专业的图片收集助手。根据用户的网站需求,智能选择并调用相应的工具收集不同类型的图片资源。
你可以根据需要调用下面多个工具,收集全面的图片资源:
1. searchContentImages - 搜索内容相关图片,用于网站内容展示
2. searchIllustrations - 搜索插画图片,用于网站美化和装饰
3. generateArchitectureDiagram - 根据技术主题生成架构图,用于展示系统结构和技术关系
4. generateLogos - 根据描述生成Logo设计图片,用于网站品牌标识
请根据用户的需求分析,优先选择与用户需求最相关的图片类型:- 如果涉及技术、系统、架构等内容,调用 generateArchitectureDiagram 生成架构图- 如果需要品牌标识、Logo设计,调用 generateLogos 生成Logo- 如果需要内容相关图片,调用 searchContentImages 搜索图片- 如果需要装饰性插画,调用 searchIllustrations 搜索插画
你必须按照 JSON 格式输出!三、图片收集AI服务
1)创建图片收集 AI 服务类ImageCollectionService,定义流式调用方法,复用现有 ChatModel 配置:
public interface ImageCollectionService {
/**
* 根据用户提示词收集所需的图片资源
* AI 会根据需求自主选择调用相应的工具
*/
@SystemMessage(fromResource = "prompt/image-collection-system-prompt.txt")
String collectImages(@UserMessage String userPrompt);
} 2)构建 AI 服务工厂类ImageCollectionServiceFactory,注入指定 ChatModel 与图片收集工具,实现服务的统一创建:
@Slf4j
@Configuration
public class ImageCollectionServiceFactory {
@Resource
private ChatModel chatModel;
@Resource
private ImageSearchTool imageSearchTool;
@Resource
private UndrawIllustrationTool undrawIllustrationTool;
@Resource
private MermaidDiagramTool mermaidDiagramTool;
@Resource
private LogoGeneratorTool logoGeneratorTool;
/**
* 创建图片收集 AI 服务
*/
@Bean
public ImageCollectionService createImageCollectionService() {
return AiServices.builder(ImageCollectionService.class)
.chatModel(chatModel)
.tools(
imageSearchTool,
undrawIllustrationTool,
mermaidDiagramTool,
logoGeneratorTool
)
.build();
}
} 3)扩展WorkflowContext状态类,新增imageListStr字符串字段,用于存储 AI 返回的图片信息文本:
/**
* 图片资源字符串
*/
private String imageListStr;4)编写单元测试,验证 AI 图片收集服务:
@SpringBootTest
class ImageCollectionServiceTest {
@Resource
private ImageCollectionService imageCollectionService;
@Test
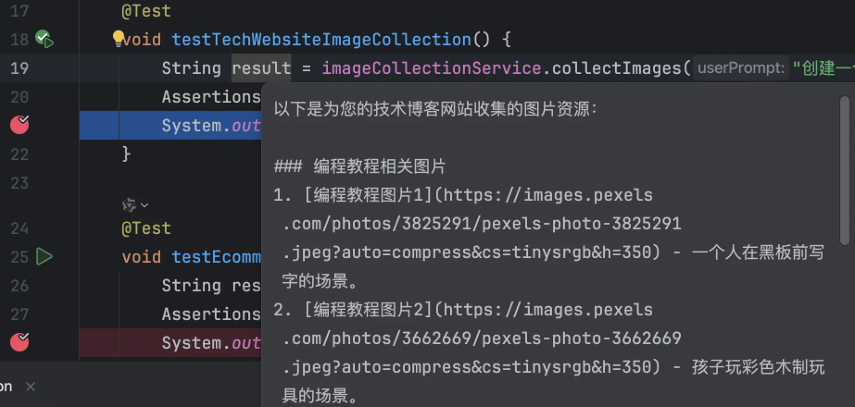
void testTechWebsiteImageCollection() {
String result = imageCollectionService.collectImages("创建一个技术博客网站,需要展示编程教程和系
统架构");
Assertions.assertNotNull(result);
System.out.println("技术网站收集到的图片: " + result);
}
@Test
void testEcommerceWebsiteImageCollection() {
String result = imageCollectionService.collectImages("创建一个电商购物网站,需要展示商品和品牌形
象");
Assertions.assertNotNull(result);
System.out.println("电商网站收集到的图片: " + result);
}
}执行效果如图,还挺不错的:
四、工作节点开发
1)编写 Spring Bean 静态工具类,解决静态工作节点方法中获取 Spring 容器内ImageCollectionService的问题,避免修改原有代码架构
/**
* Spring上下文工具类
* 用于在静态方法中获取Spring Bean
*/
@Component
public class SpringContextUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
SpringContextUtil.applicationContext = applicationContext;
}
/**
* 获取Spring Bean
*/
public static <T> T getBean(Class<T> clazz) {
return applicationContext.getBean(clazz);
}
/**
* 获取Spring Bean
*/
public static Object getBean(String name) {
return applicationContext.getBean(name);
}
/**
* 根据名称和类型获取Spring Bean
*/
public static <T> T getBean(String name, Class<T> clazz) {
return applicationContext.getBean(name, clazz);
}
}2)改造图片收集节点:
/**
* 图片收集节点
* 使用AI进行工具调用,收集不同类型的图片
*/
@Slf4j
public class ImageCollectorNode {
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
String originalPrompt = context.getOriginalPrompt();
String imageListStr = "";
try {
// 获取AI图片收集服务
ImageCollectionService imageCollectionService =
SpringContextUtil.getBean(ImageCollectionService.class);
// 使用 AI 服务进行智能图片收集
imageListStr = imageCollectionService.collectImages(originalPrompt);
imageCollectionService.collectImages(originalPrompt);
} catch (Exception e) {
log.error("图片收集失败: {}", e.getMessage(), e);
}
// 更新状态
context.setCurrentStep("图片收集");
context.setImageListStr(imageListStr);
return WorkflowContext.saveContext(context);
});
}
}五、提示词增强节点
编写提示词增强节点代码,核心逻辑:
-
读取 WorkflowContext 中的
imageListStr字段(图片信息文本); -
兼容图片对象列表(预留扩展字段),拼接时做非空校验;
-
将图片信息按固定格式拼接至原始提示词末尾,引导 AI 利用图片素材生成内容。
@Slf4j
public class PromptEnhancerNode {
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
log.info("执行节点: 提示词增强");
// 获取原始提示词和图片列表
String originalPrompt = context.getOriginalPrompt();
String imageListStr = context.getImageListStr();
List<ImageResource> imageList = context.getImageList();
// 构建增强后的提示词
StringBuilder enhancedPromptBuilder = new StringBuilder();
enhancedPromptBuilder.append(originalPrompt);
// 如果有图片资源,则添加图片信息
if (CollUtil.isNotEmpty(imageList) || StrUtil.isNotBlank(imageListStr)) {
enhancedPromptBuilder.append("\n\n## 可用素材资源\n");
enhancedPromptBuilder.append("请在生成网站使用以下图片资源,将这些图片合理地嵌入到网站的相
应位置中。\n");
if (CollUtil.isNotEmpty(imageList)) {
for (ImageResource image : imageList) {
enhancedPromptBuilder.append("- ")
.append(image.getCategory().getText())
.append(":")
.append(image.getDescription())
.append("(")
.append(image.getUrl())
.append(")\n");
}
} else {
enhancedPromptBuilder.append(imageListStr);
}
}
String enhancedPrompt = enhancedPromptBuilder.toString();
// 更新状态
context.setCurrentStep("提示词增强");
context.setEnhancedPrompt(enhancedPrompt);
log.info("提示词增强完成,增强后长度: {} 字符", enhancedPrompt.length());
return WorkflowContext.saveContext(context);
});
}
}
▼ java
@Slf4j
public class RouterNode {
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
log.info("执行节点: 智能路由");
CodeGenTypeEnum generationType;
try {
// 获取AI路由服务
AiCodeGenTypeRoutingService routingService =
SpringContextUtil.getBean(AiCodeGenTypeRoutingService.class);
// 根据原始提示词进行智能路由
generationType = routingService.routeCodeGenType(context.getOriginalPrompt());
log.info("AI智能路由完成,选择类型: {} ({})", generationType.getValue(),
generationType.getText());
} catch (Exception e) {
log.error("AI智能路由失败,使用默认HTML类型: {}", e.getMessage());
generationType = CodeGenTypeEnum.HTML;
}
// 更新状态
context.setCurrentStep("智能路由");
context.setGenerationType(generationType);
return WorkflowContext.saveContext(context);
});
}
}六、开发过程中的问题与解决方案
问题 :结构化输出适配性差
现象:
尝试配置 JSON Schema 实现结构化输出时,DeepSeek 模型因不支持核心参数报错;切换至阿里云百炼模型后,AI 的工具调用意图被错误解析为结构化输出返回值,导致图片信息获取失败。
原因:
不同大模型对结构化输出的支持度不一致,DeepSeek 未开放结构化输出的核心配置参数,阿里云百炼模型对 “工具调用” 与 “结构化输出” 的返回逻辑处理存在冲突。
解决方案:
放弃结构化输出方案,复用现有 ChatModel,通过定制提示词约束 AI 输出文本格式,后续在工作节点中处理文本解析与拼接,规避模型兼容性问题。
七、实训收获与技术成长
本次开发完成了从 “纯文本内容生成” 到 “文本 + 图片素材融合生成” 的链路拓展,核心收获体现在:
-
掌握了大模型兼容性问题的解决方案,学会在不同模型能力差异下平衡技术方案的适配性与开发成本;
-
理解工作流节点的开发逻辑,掌握了 “静态方法 + Spring Bean 工具类” 的适配技巧,在不破坏原有架构的前提下扩展功能;
八、后续开发计划
完善图片信息解析能力:优化文本格式解析逻辑,增加容错处理,应对 AI 输出格式不规范的情况;
优化图片素材来源:接入免费图片 API,实现图片素材的自动下载与本地化存储,避免依赖外部 URL 失效问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)