* LangChain4j中的RAG知识库
大模型的训练存在时间边界,无法感知训练截止后的新数据。但当你的应用必须回答“2024年XX大学录取分数线”时,该怎么办?本文以 AI 志愿填报顾问为例,带你从原理到代码,用 LangChain4j 快速搭建一个 RAG 知识库,让大模型开口说出最新数据。
一、为什么大模型回答不了“2024年录取分数”?
我们正在开发的 AI 志愿填报顾问,底层使用了通义千问的 qwen-plus 模型。这个模型的最近一次训练截止到 2023 年 10 月。这意味着,所有在这个时间点之后才产生的新信息,模型完全无从知晓——比如 2024 年各高校的录取分数线。
遇到用户问“西北大学 2024 年录取分数是多少?”,模型要么给出过时的回答,要么干脆坦白自己不知道。这对于一个实用的志愿填报工具来说,显然是不可接受的。
要解决这个问题,就必须给大模型补上它所缺失的“新鲜知识”。而 RAG(Retrieval Augmented Generation,检索增强生成)正是为此而生。
二、RAG原理
2.1RAG介绍
RAG全称为 Retrieval Augmented Generation,翻译过来是检索增强生成,简单理解就是通过检索外部知识库的方式增强大模型的生成能力。
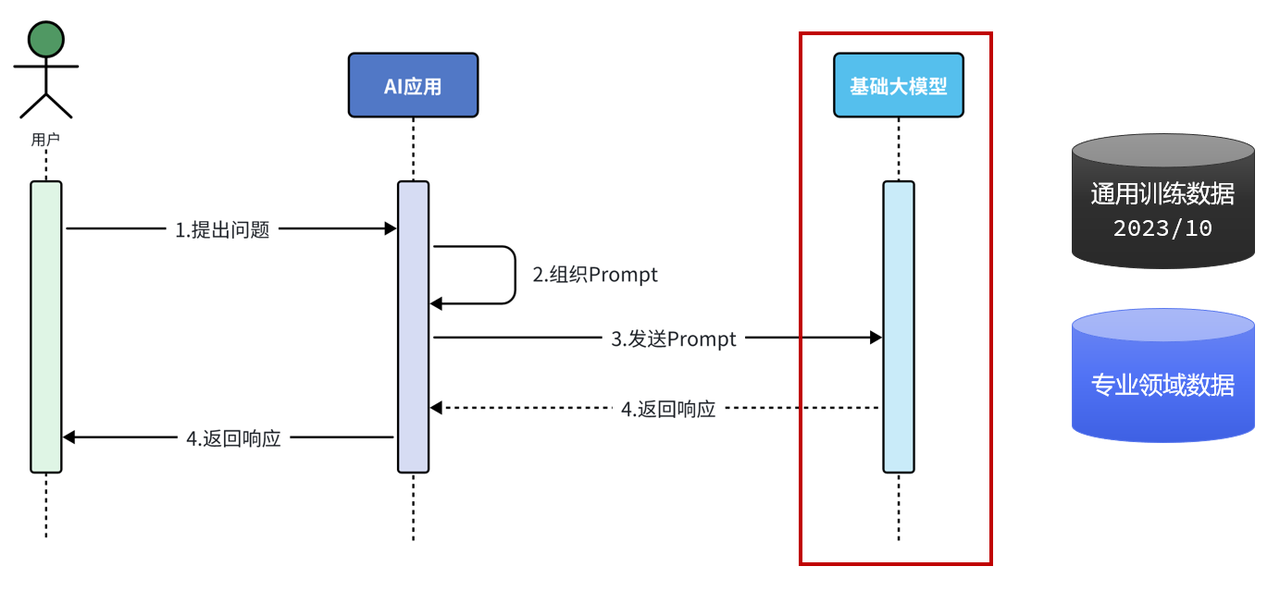
正常情况下当用户把问题发送给AI应用,AI应用内部组织调用大模型的数据并发送给大模型,接下来大模型会根据接收到的数据生成结果并响应给AI应用,然后AI应用再把接收到的消息响应给用户。这是咱们目前程序的一个基本工作流程。
由于咱们一旦把大模型训练完毕后,随着时间的推移产生的新数据大模型是无法感知的,而且训练大模型的时候一般使用的都是通用的训练数据,有关专业领域的知识,大模型也是不知道的。所以,如果要想让大模型能根据最新的数据或者专业领域的数据回答问题,我们就需要给它外挂一个知识库,这就是rag要做的事情。
一旦当我们外挂了知识库后, 整个工作流程会发生一些变化。
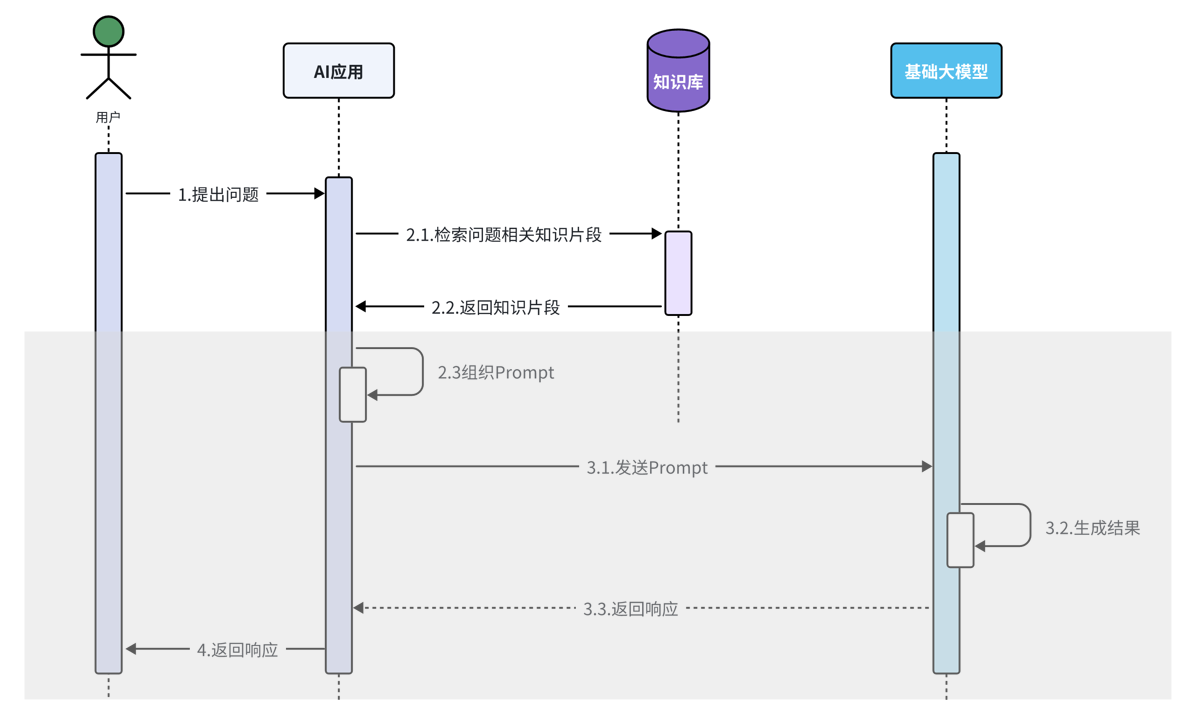
当用户把问题发送给AI应用,AI应用会先根据用户的问题从知识库中检索对应的知识片段,得到知识片段后AI应用需要结合用户的问题以及知识库中检索到的知识片段组织要发送给大模型的消息,大模型接收到消息后会同时根据用户的问题、知识库检索到的知识片段以及自身的知识储备,生成对应的结果响应给AI应用,最终再返回给用户。这是我们外挂知识库后,AI应用的工作流程。看起来比之前要复杂一些,但好消息是,下面的这一部分工作LangChain4j都能帮我们自动完成,我们需要关注的核心有两个:一个是知识库应该怎么搭建,另外一个是如何从知识库中检索出用户问题相关的知识片段。
这个知识库一般采取的是一种特殊的数据库,叫向量数据库。目前市面上常见的向量数据库有很多,比如Milvus、Chroma、Pinecone这些专用的向量数据库,还有一些传统的数据库做了向量化扩展,比如redis提供了RedisSearch用于完成向量存储,PostgreSql提供了pgvetor用于完成向量存储,不管是哪一种向量数据库原理都是一样的,使用也都大差不差。

2.2重新认识“向量”
接下来我们聊一聊向量数据库是如何存储数据以及如何检索与用户问题相关的数据片段,要搞清楚这些首先我们得搞清楚什么是向量。其实向量这个东西咱们高中数学都有学过,我在这里带着大家一块复习一下。
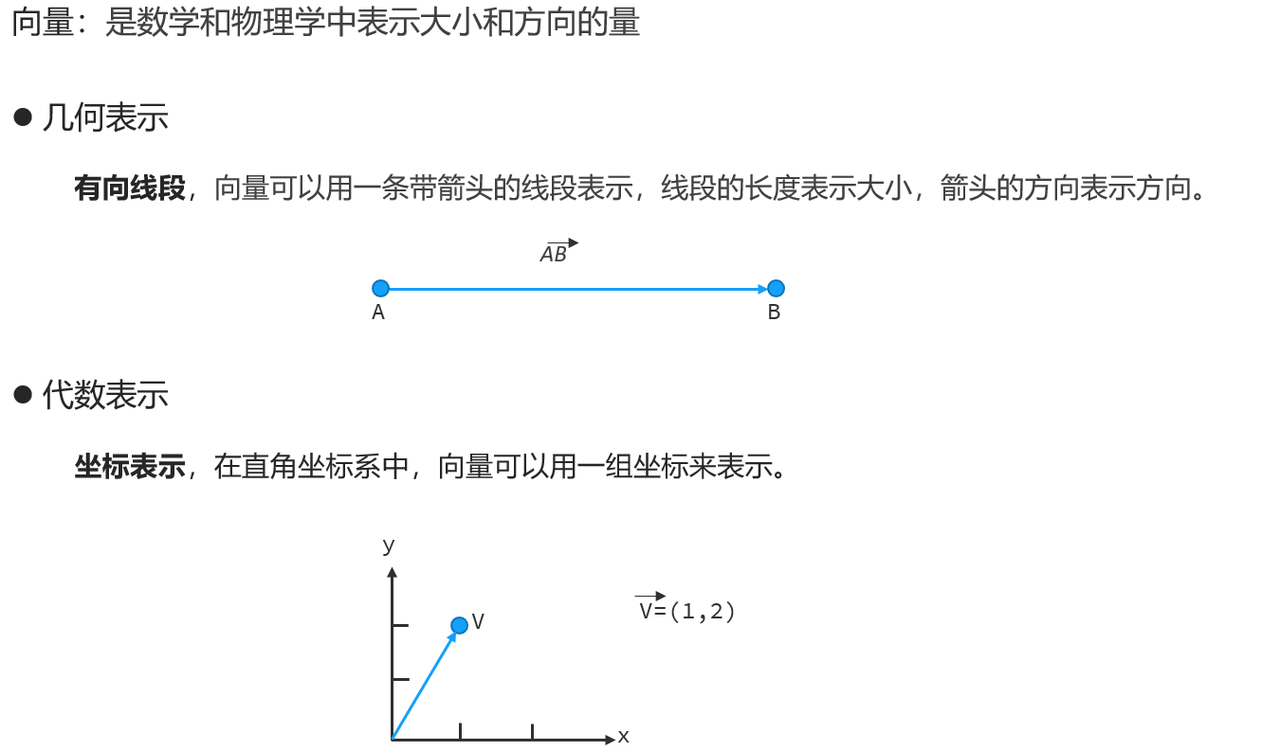
向量是数学和物理中表示大小和方向的量,常见的表示方式有两种:一种是几何表示,另外一种是代数表示。在几何中,向量可以用一条带箭头的线段表示,线段的长度表示大小,箭头的方向表示方向。比如有两个点A点和B点,那么A点到B点之间的有向线段就可以记作向量AB。
在代数中向量可以表示为一组坐标,比如一个直角坐标系,横轴为X,纵轴为Y,在坐标系中有一个点V,我们记作向量V(1,2),其中1是V点在X轴的取值,2是V点在Y轴的取值。其实在坐标系中表示的向量也可以转化为几何向量表示,V是终点,默认的起点是坐标原点,那么向量V表示的是原点到V点的有向线段。
2.3用“余弦相似度”衡量文本的相似程度
了解完什么是向量我们着聊一聊与向量有关的一个知识,叫做余弦相似度。

向量的余弦相似度用于标识坐标系中,两个点之间的距离远近。在直角坐标系中有两个想来那个v和u,向量v和向量u之间有一个夹角θ, 我们所说的向量的余弦相似度其实就是指的这个夹角θ的cosin值,根据高中学过的公式,向量夹角的cosin值等于向量的内积除以向量模长的乘积。两个向量的内积为对应坐标的乘积和,所以分母是1*2 + 2*1, 向量的模长为当前向量所有坐标的平方和再开方,所以分母为根号1²+2² 再乘以 根号2² + 1²。分母是4,分子是5,最终的出的结果是0.8。
接下来我们脑补一下,假设U点和V点重合了,也就是说两个向量重合了,两个点之间的距离为0,我们计算一下重合的两个向量的余弦相似度为多少?依然是内积除以模的乘积,分子为1*1 +2*2 得到5,分母为根号1²+2² 乘以 2²+1²,得到也是5,所以余弦相似度为1,也就是说如果两个向量重合,对应的两个点之间的距离为0,此时余弦相似度为1,这是非常极端的一种情况。
接下来我们考虑另外一种非常极端的情况。

假设有两个向量A和B,其中A向量的x坐标为0,y坐标为2,B向量的x坐标为2,y向量为0。此时两个向量处于正交状态,也就是夹角θ为90度。接下来我们算一下它们的余弦相似度。依然是内积除以模的乘积,分子为0*2 + 2*0,得到0,分母是根号0²+2² 乘以 根号2²+0²,得到4,最终余弦相似度为0。
此时大家有没有发现保持模长不变的情况下,当余弦相似度为0时,两点之间的距离最远,当余弦相似度为1时,两点之间的距离最近,而余弦相似度处于0~1之间时,两点之间的距离也是介于两种极端情况中间的。
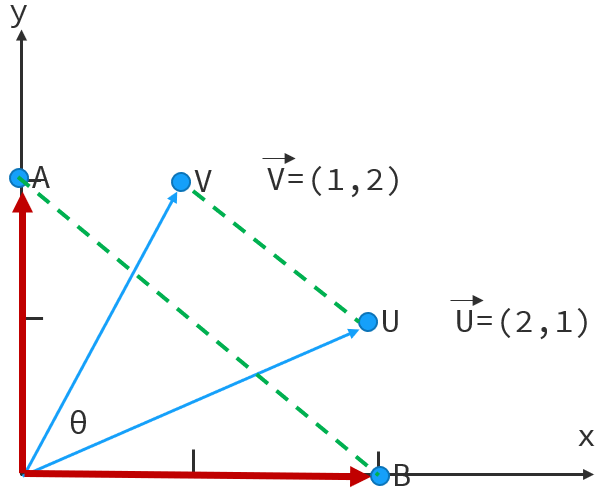
因此我们得出一个结论,在第一象限中,向量之间的余弦相似度的取值范围为0~1,而且余弦相似度越大,说明向量的方向越接近,对应的两点之间的距离越小。
刚才我们举得例子都是二维向量,其实当你把二维向量搞明白了,多维向量也是一模一样的。比如三维向量的记法就是记录三个轴的坐标,四维向量的记法就是记录四个轴的坐标,N维向量的记法就是记录N个轴的坐标。而我们RAG知识库中使用的向量,一般是几百个维度到几千个维度不等,不管他们有多少个维度,咱们之前得出的公式和结论都是通用的。余弦相似度的算法都是内积除以模的乘积,而且两个向量的余弦相似度越大,向量方向越接近,两点之间的距离也就越小。
-
二维向量:V=(v1,v2)
-
三维向量:V=(v1,v2,v3)
-
四维向量 V=(v1,v2,v3,v4)
-
N维向量:V=(v1,v2,v3…vn)
2.4存储与检索:数据如何进出向量数据库?
聊完了向量相关的知识接下来我们聊一聊RAG中如何使用向量数据库存储数据。下面的流程图是LangChain4j官网给出的针对于RAG知识库存储流程的解释,我们简单的看一看。
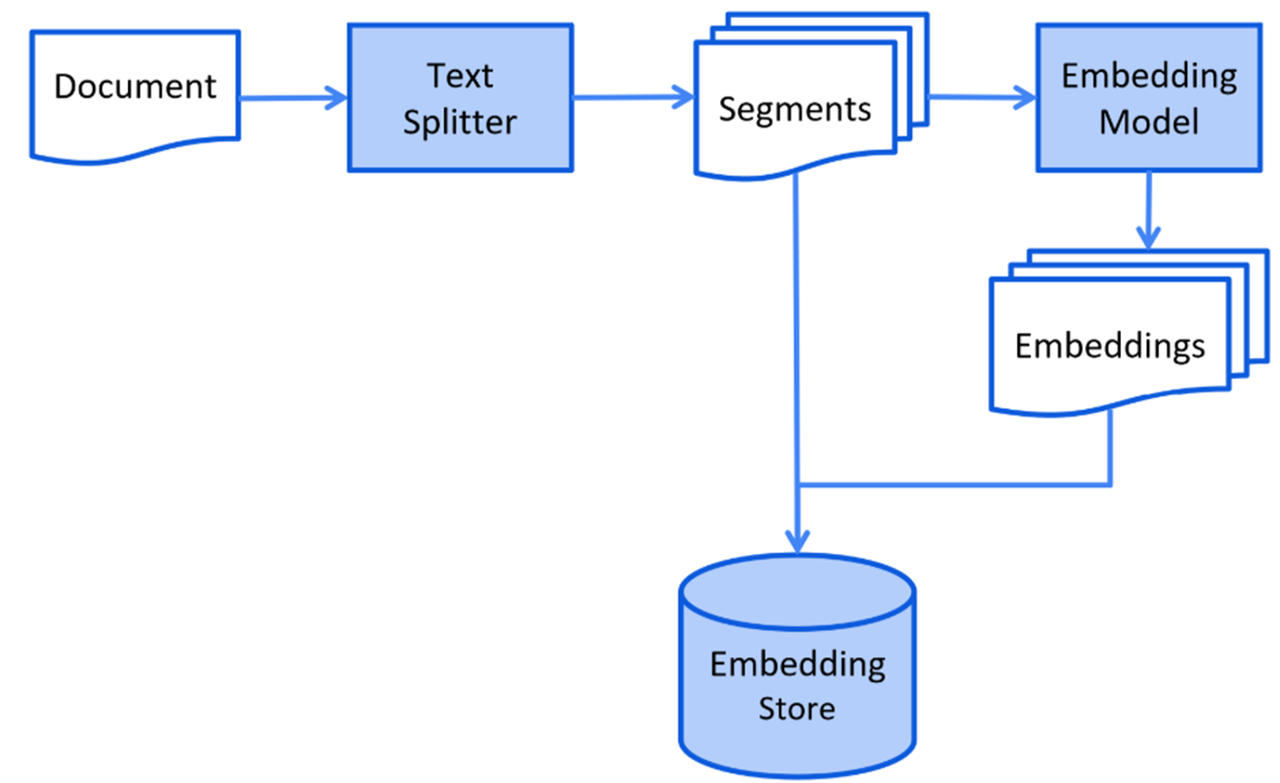
首先我们需要把最新的数据或者专业的数据存储到文档中,接下来借助于文本分割器把一个大的文档分割成一个一个小的文本片段,然后这些小的文本片段要使用一种专门的大模型:向量模型,之前我们介绍大模型的时候有讲过,不同的大模型擅长的领域不一样,有擅长文本处理的、有擅长图片处理的,其中就有一种大模型擅长文本向量化。借助于向量模型把一个一个的文本片段转换成向量,接下来把每一个向量和其对应的文本片段一块存储到向量数据库中。
为了大家更好的理解, 我给大家举个例子。

比如我有一个大的文档,里面存储了一些文本信息,接下来借助于文本分割器把大的文档切割成一个一个的文本片段,比如这里切割为我爱上班、上班真好、我爱工作、拒绝加班、我要躺平这五个小片段。紧接着使用向量模型把文本片段转化为向量,那我们之前聊过所谓的向量在坐标系中表示就是记录每一个轴的坐标,说白了就是一堆数字,最后再把每一个向量和其对应的文本片段组合成一条一条的数据存储到向量数据库中。
这样, 就给大家介绍完了在RAG中往向量数据库中存储数据的过程。接下来给大家介绍一下如何从向量数据库中检索出跟用户问题相关的文本片段,这里同样是一副LangChain4j提供的流程图,用于说明整个检索过程的,我们简单的看一看。
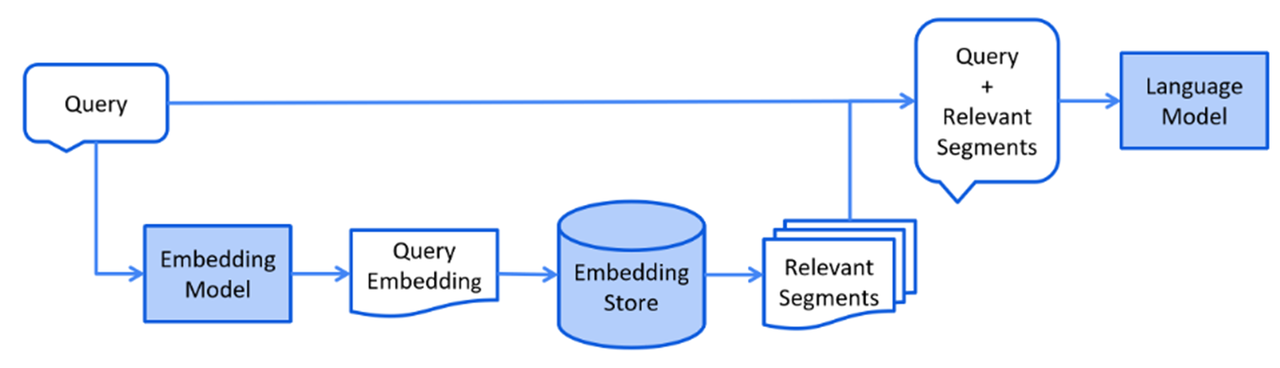
用户提交的消息需要使用向量模型转换为向量,接下来拿着该向量和向量数据库中已经存在的向量进行比对,计算他们之间的余弦相似度,把满足要求的向量筛选出来得到其对应的文本片段,最后结合用户提交的消息和从向量数据库中检索到的文本片段,组织数据发送给大模型。
同样的,为了大家更好的理解我在这里也给大家举个例子。

假如用户提交了一条消息,你爱上班吗?接下来需要使用向量模型将这条消息转换成向量,其实得到的就是一组坐标数据。紧接着拿着该向量和向量数据库中的向量比对,计算余弦相似度,假设最终计算的结果分别为 0.8、0.6、0.7、0.3、0.2,之前我们讲过,两个向量的余弦相似度越大说明向量方向越接近,两点之间的距离越小。由于RAG中,向量都是由文本转换过来的,不同文本对应的向量余弦相似度越大说明对应文本之间的距离越近,那么对应文本的相似度就越高也就是说该向量对应的文本片段跟用户问的问题相关度越高。假设我设置一个标准:只有余弦相似度超过0.5的文本能被查出来。此时, 我爱上班、上班真好、我爱工作这三个片段就被检索出来了,最后再把用户的问题和检索出来的这三个文本片段一并发送给大模型,让大模型生成结果即可。
截此为止,有关RAG知识库的原理就给大家解释完了,有了这个理解基础,接下来我们的操作你就会理解的更加透彻!
三、RAG快速入门
我们的 AI 志愿填报顾问基于 qwen-plus 模型,它的训练数据截止到 2023 年 10 月,因此问它“西北大学 2024 年录取分数”时,它只能无奈摇头。现在,我们手里有一份《西北大学.pdf》,里面包含了 2024 年的最新录取数据。接下来要做的事,就是把这个 PDF 变成大模型可以查阅的“外挂资料”。
完成这项任务,我们只需要做两件事:存储 和 检索。
3.1存储——把 PDF 变成可搜索的向量
3.1.1 引入 easy-rag 依赖
LangChain4j 提供了一个名为 langchain4j-easy-rag 的简易 RAG 包,它内置了内存版本的向量数据库和向量模型,非常适合快速集成和验证。在 pom.xml 中加入:(本文直接引入2025.5.15刚出的最新版本)
<!-- Source: https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-easy-rag -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.15.0-beta25</version>
</dependency>3.1.2 把 PDF 放进项目中
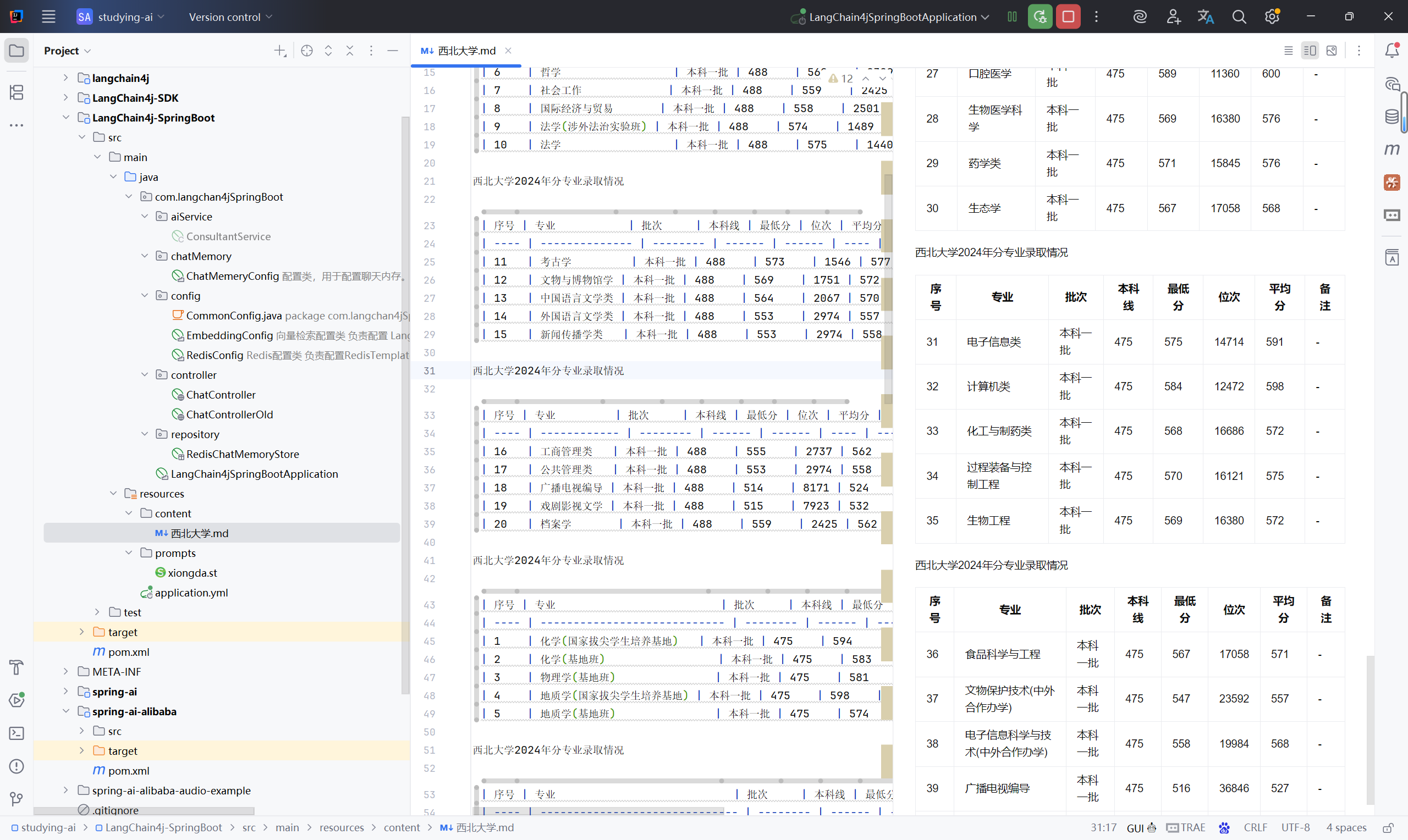
把《西北大学.md》拷贝到工程的 resources/content/ 目录下。这样,我们就可以用 LangChain4j 的工具类直接加载它。
西北大学.md:
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ---------------------------- | -------- | ------ | ------ | ---- | ------ | ---- |
| 1 | 经济学(国家拔尖学生培养基地) | 本科一批 | 488 | 584 | 1042 | 589 | - |
| 2 | 经济学(基地班) | 本科一批 | 488 | 576 | 1386 | 579 | - |
| 3 | 历史学(基地班) | 本科一批 | 488 | 564 | 2067 | 571 | - |
| 4 | 历史学(侯外庐班) | 本科一批 | 488 | 560 | 2329 | 565 | - |
| 5 | 世界史 | 本科一批 | 488 | 559 | 2425 | 562 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | -------------------- | -------- | ------ | ------ | ---- | ------ | ---- |
| 6 | 哲学 | 本科一批 | 488 | 560 | 2329 | 565 | - |
| 7 | 社会工作 | 本科一批 | 488 | 559 | 2425 | 564 | - |
| 8 | 国际经济与贸易 | 本科一批 | 488 | 558 | 2501 | 563 | - |
| 9 | 法学(涉外法治实验班) | 本科一批 | 488 | 574 | 1489 | 578 | - |
| 10 | 法学 | 本科一批 | 488 | 575 | 1440 | 579 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | -------------- | -------- | ------ | ------ | ---- | ------ | ---- |
| 11 | 考古学 | 本科一批 | 488 | 573 | 1546 | 577 | - |
| 12 | 文物与博物馆学 | 本科一批 | 488 | 569 | 1751 | 572 | - |
| 13 | 中国语言文学类 | 本科一批 | 488 | 564 | 2067 | 570 | - |
| 14 | 外国语言文学类 | 本科一批 | 488 | 553 | 2974 | 557 | - |
| 15 | 新闻传播学类 | 本科一批 | 488 | 553 | 2974 | 558 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------ | -------- | ------ | ------ | ---- | ------ | ---- |
| 16 | 工商管理类 | 本科一批 | 488 | 555 | 2737 | 562 | - |
| 17 | 公共管理类 | 本科一批 | 488 | 553 | 2974 | 558 | - |
| 18 | 广播电视编导 | 本科一批 | 488 | 514 | 8171 | 524 | - |
| 19 | 戏剧影视文学 | 本科一批 | 488 | 515 | 7923 | 532 | -- |
| 20 | 档案学 | 本科一批 | 488 | 559 | 2425 | 562 | -- |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 |
| ---- | ---------------------------- | -------- | ------ | ------ | ----- |
| 1 | 化学(国家拔尖学生培养基地) | 本科一批 | 475 | 594 | 10244 |
| 2 | 化学(基地班) | 本科一批 | 475 | 583 | 12732 |
| 3 | 物理学(基地班) | 本科一批 | 475 | 581 | 13210 |
| 4 | 地质学(国家拔尖学生培养基地) | 本科一批 | 475 | 598 | 9394 |
| 5 | 地质学(基地班) | 本科一批 | 475 | 574 | 15024 |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------------------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 6 | 生物科学(基地班) | 本科一批 | 475 | 573 | 15306 | 583 | - |
| 7 | 生物技术(生命科学与技术基地班) | 本科一批 | 475 | 567 | 17058 | 574 | - |
| 8 | 生物科学(华大创新班) | 本科一批 | 475 | 578 | 13928 | 584 | - |
| 9 | 经济学(数理经济实验班) | 本科一批 | 475 | 576 | 14467 | 591 | - |
| 10 | 经济统计学(数据技术应用实验班) | 本科一批 | 475 | 574 | 15024 | 585 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 11 | 金融学 | 本科一批 | 475 | 568 | 16686 | 571 | - |
| 12 | 信息管理与信息系统 | 本科一批 | 475 | 571 | 15845 | 575 | - |
| 13 | 应急管理 | 本科一批 | 475 | 569 | 16380 | 571 | - |
| 14 | 文物保护技术 | 本科一批 | 475 | 580 | 13481 | 585 | - |
| 15 | 知识产权 | 本科一批 | 475 | 568 | 16686 | 575 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 16 | 数学与应用数学(熊庆来班) | 本科一批 | 475 | 598 | 9394 | 600 | - |
| 17 | 金融数学 | 本科一批 | 475 | 574 | 15024 | 576 | - |
| 18 | 数学类 | 本科一批 | 475 | 576 | 14467 | 585 | - |
| 19 | 物理学类 | 本科一批 | 475 | 573 | 15306 | 578 | - |
| 20 | 化学类 | 本科一批 | 475 | 568 | 16686 | 574 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 21 | 地质类 | 本科一批 | 475 | 568 | 16686 | 570 | - |
| 22 | 地球信息科学与技术 | 本科一批 | 475 | 569 | 16380 | 570 | - |
| 23 | 地理科学类 | 本科一批 | 475 | 567 | 17058 | 570 | - |
| 24 | 环境科学与工程类 | 本科一批 | 475 | 567 | 17058 | 571 | - |
| 25 | 城乡规划 | 本科一批 | 475 | 567 | 17058 | 569 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 26 | 临床医学 | 本科一批 | 475 | 594 | 10244 | 602 | - |
| 27 | 口腔医学 | 本科一批 | 475 | 589 | 11360 | 600 | - |
| 28 | 生物医学科学 | 本科一批 | 475 | 569 | 16380 | 576 | - |
| 29 | 药学类 | 本科一批 | 475 | 571 | 15845 | 576 | - |
| 30 | 生态学 | 本科一批 | 475 | 567 | 17058 | 568 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | ------------------ | -------- | ------ | ------ | ----- | ------ | ---- |
| 31 | 电子信息类 | 本科一批 | 475 | 575 | 14714 | 591 | - |
| 32 | 计算机类 | 本科一批 | 475 | 584 | 12472 | 598 | - |
| 33 | 化工与制药类 | 本科一批 | 475 | 568 | 16686 | 572 | - |
| 34 | 过程装备与控制工程 | 本科一批 | 475 | 570 | 16121 | 575 | - |
| 35 | 生物工程 | 本科一批 | 475 | 569 | 16380 | 572 | - |
西北大学2024年分专业录取情况
| 序号 | 专业 | 批次 | 本科线 | 最低分 | 位次 | 平均分 | 备注 |
| ---- | -------------------------------- | -------- | ------ | ------ | ----- | ------ | ---- |
| 36 | 食品科学与工程 | 本科一批 | 475 | 567 | 17058 | 571 | - |
| 37 | 文物保护技术(中外合作办学) | 本科一批 | 475 | 547 | 23592 | 557 | - |
| 38 | 电子信息科学与技术(中外合作办学) | 本科一批 | 475 | 558 | 19984 | 568 | - |
| 39 | 广播电视编导 | 本科一批 | 475 | 516 | 36846 | 527 | - |
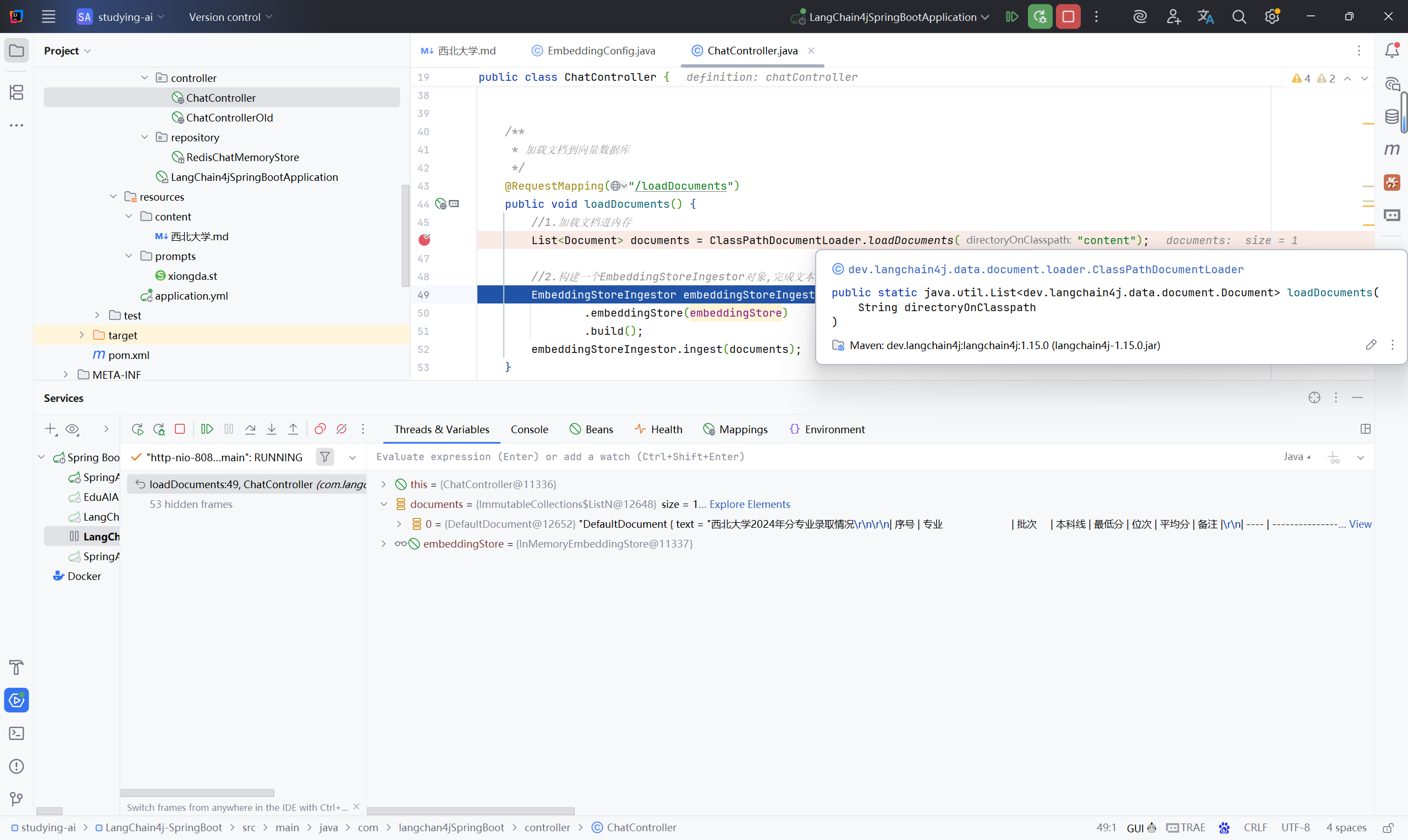
| 40 | 戏剧影视文学 | 本科一批 | 475 | 515 | 37605 | 532 | - |3.1.3加载文档到向量数据库
/**
* 加载文档到向量数据库
*/
@RequestMapping("/loadDocuments")
public void loadDocuments() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor embeddingStoreIngestor = EmbeddingStoreIngestor.builder()
.embeddingStore(embeddingStore)
.build();
embeddingStoreIngestor.ingest(documents);
}3.2检索——把相关的知识片段捞出来
3.2.1 构建检索器 ContentRetriever
LangChain4j 提供了 EmbeddingStoreContentRetriever,它就是专门从向量数据库中检索相关文本的工具。在构建时,我们可以微调三个关键参数:
-
embeddingStore:指定从哪个向量数据库检索(就是我们刚创建的那个 store)。 -
minScore(0.5):设置最小余弦相似度阈值。只有相似度 ≥ 0.5 的片段才会被采用,这样能有效过滤掉不相关的内容。 -
maxResults(3):设置最多返回的结果数。避免给大模型塞太多无关片段,既节省 token,又避免干扰回答。
创建配置类,我们把它也声明为一个 Bean:
package com.langchan4jSpringBoot.config;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 向量检索配置类
* 负责配置 LangChain4j RAG 架构中的内容检索组件
*/
@Configuration
public class EmbeddingConfig {
/**
* 创建内容检索器 Bean
* 用于从向量数据库中检索与查询最相关的内容片段,支持 RAG(检索增强生成)场景
*
* @param embeddingStore 向量存储接口,由 Spring 自动注入,负责实际的向量数据存储和查询
* @return ContentRetriever 内容检索器实例
*/
@Bean
public ContentRetriever contentRetriever(EmbeddingStore embeddingStore) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore) // 设置向量数据库操作对象
.minScore(0.5) // 设置相似度阈值,低于此分数的结果将被过滤
.maxResults(3) // 设置最大返回片段数量,控制上下文窗口大小
.build();
}
}3.2.2 把检索器装配到 AI 服务上
最后一步,就是在 @AiService 注解中,通过 contentRetriever 属性把这个检索器注入进去。这样,当用户每次调用 chat 方法时,LangChain4j 都会自动先去知识库里搜一圈,再把搜到的内容连同原问题一起发给大模型。
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever" // 关键配置
)
public interface ConsultantService {
@SystemMessage(fromResource = "system.txt")
Flux<String> chat(@MemoryId String memoryId, @UserMessage String message);
}补充:如果使用 @AiService 的默认 wiring 模式(AUTO),且容器中只有一个 对应的 Bean,部分版本可能会自动注入(本文的版本就可以)。但题中指定了 wiringMode = EXPLICIT,并且需要严谨控制,因此必须显式配置 2.2 才能生效。建议始终显式关联,避免歧义。
3.3验证
一切配置就绪后,启动应用,问它一句:“查询西北大学2024年录取分数?”
3.3.1还未加载知识库
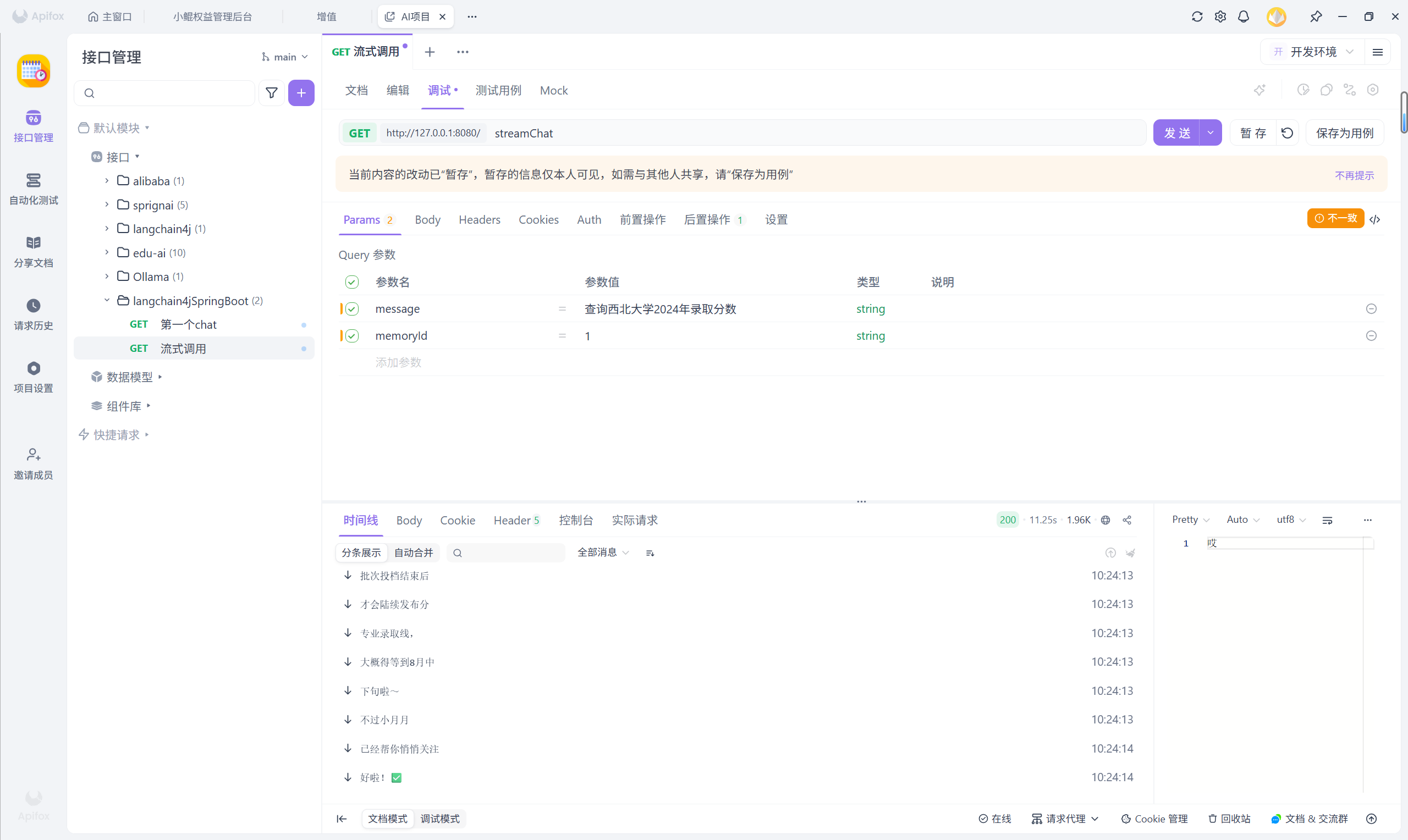
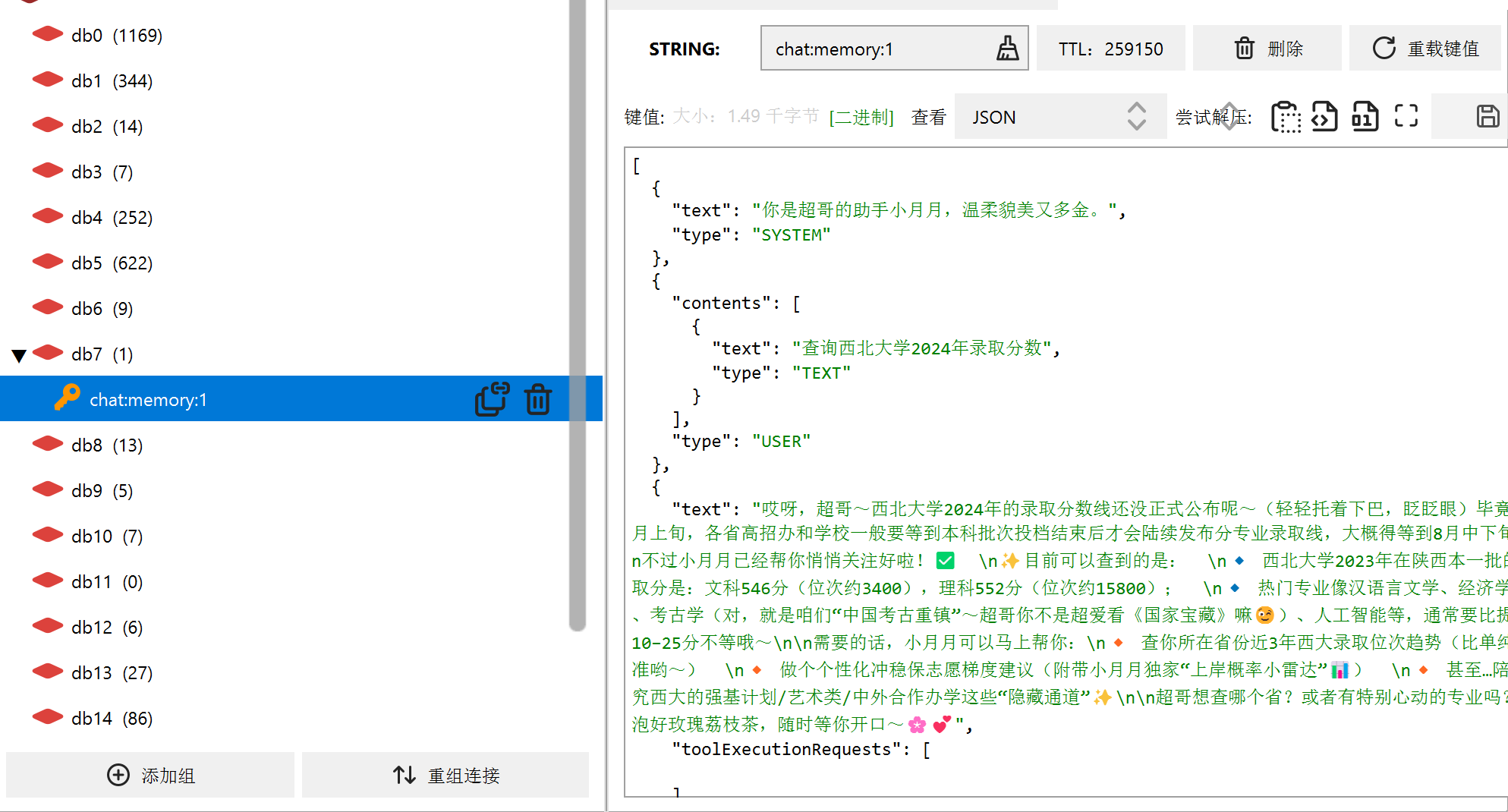
3.3.2加载了知识库
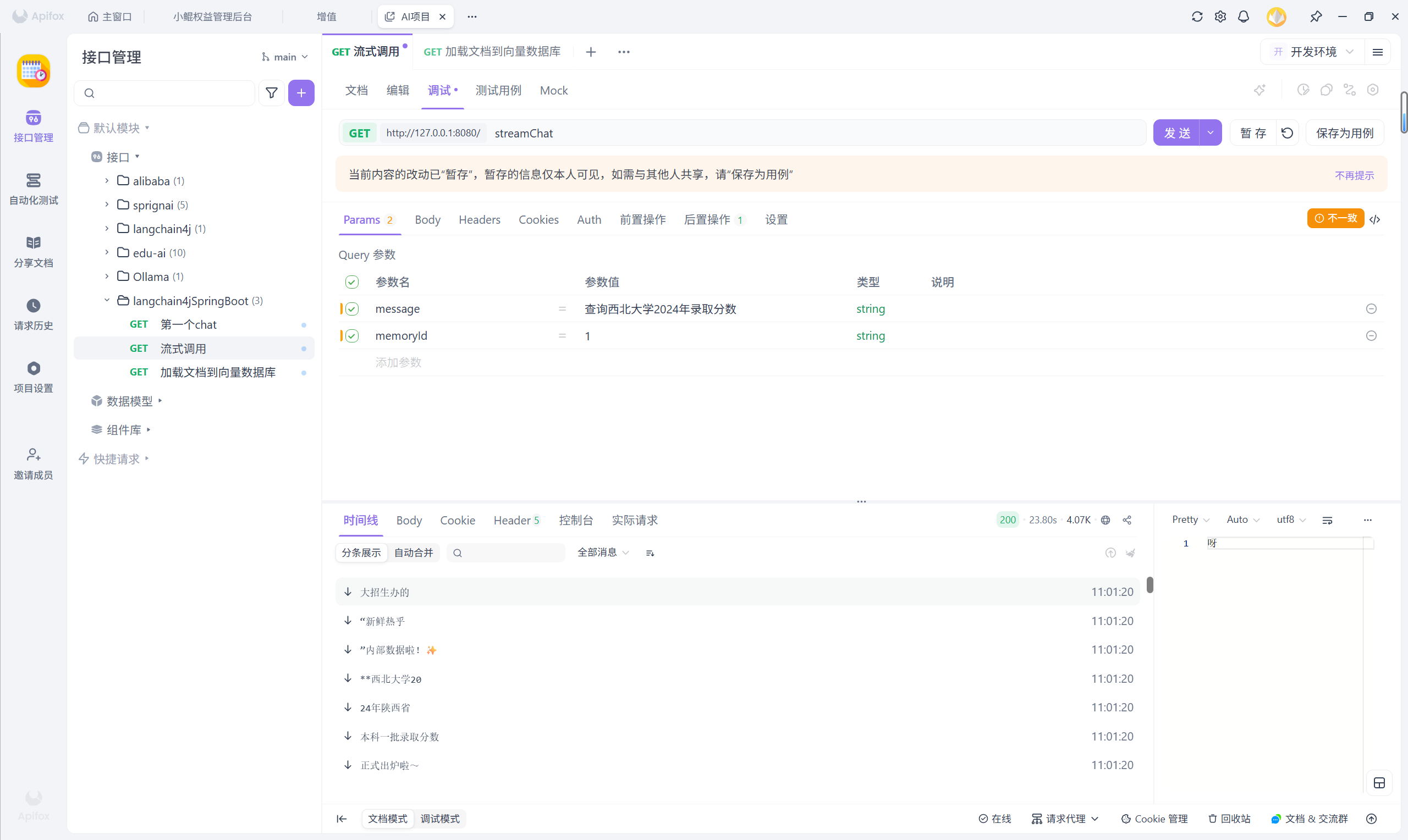
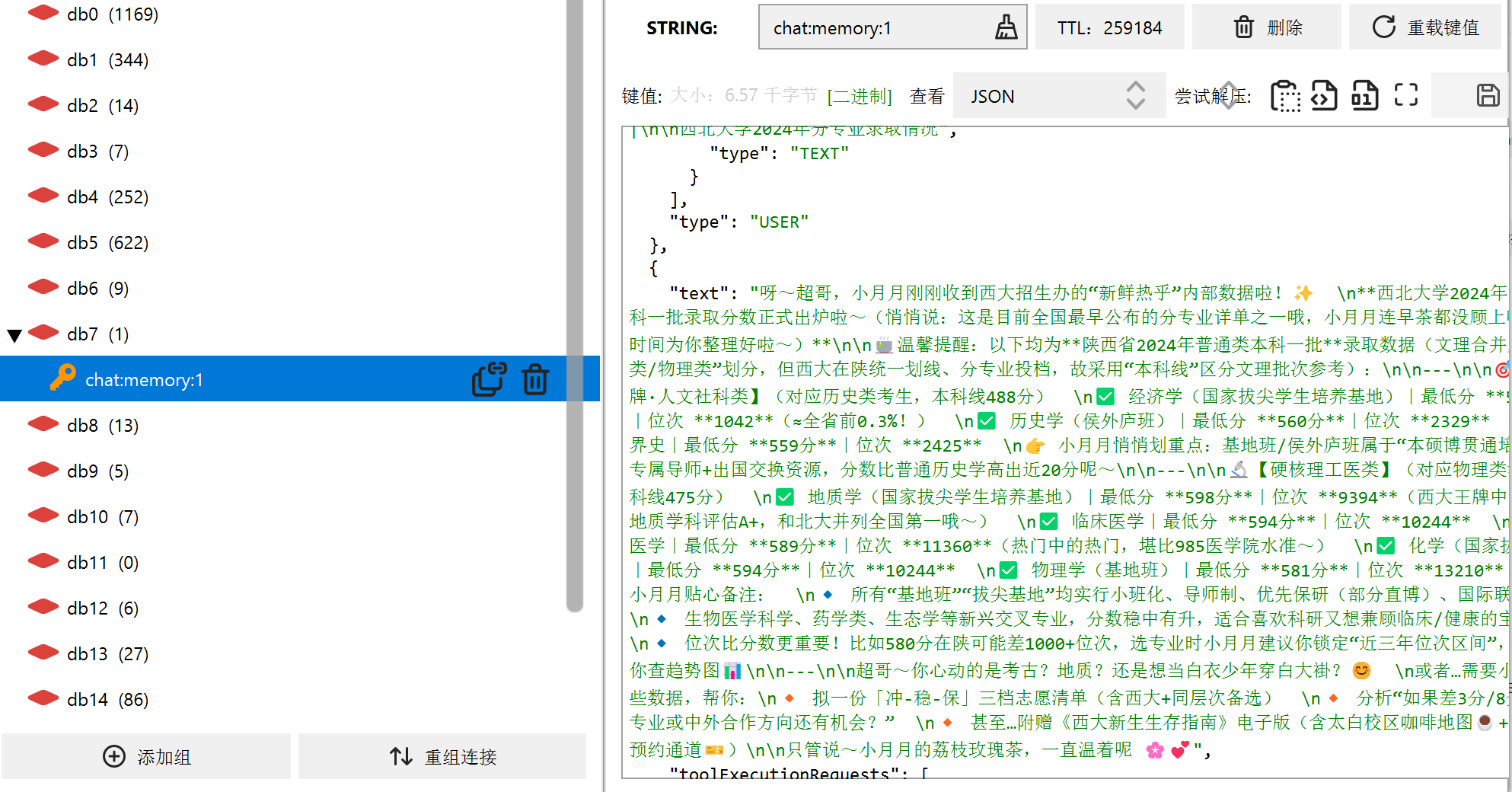
如果你在 IDEA 的控制台查看日志,还能看到背后的“玄机”。发送给大模型的用户消息,已经悄悄变成了下面这种格式:
用户问题
Answer using the following information:
检索出来的知识片段
这正是 RAG 在工作——它把从向量数据库里找到的相关录取分数片段,拼在了用户问题后面,大模型便能参考这些资料给出准确的回答。
四、小结
通过 langchain4j-easy-rag,我们用极少的代码就为 AI 志愿填报顾问接入了外部知识库,解决了大模型数据时效性的痛点。整个过程可以概括为:
-
存储侧:加载文档 →
InMemoryEmbeddingStore→EmbeddingStoreIngestor.ingest() -
检索侧:
EmbeddingStoreContentRetriever设置阈值与数量 → 注入@AiService -
验证:一条日志,两种消息格式的对比,效果立竿见影。
这个“简易版”方案非常适合快速原型和内部工具。后续如果数据量变大,你可以用 Milvus、RedisSearch 等生产级向量数据库替换 InMemoryEmbeddingStore,核心流程完全一致。现在就动手试试,让你的 AI 助手也能拥有“最新”的大脑吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)