RAG必备!6种相似性度量指标大揭秘,COSINE、BM25怎么选?附超全选型指南!
本文整理了六种常见的相似性度量指标:L2欧氏距离、内积、COSINE余弦相似度、汉明距离、杰卡德相似度和BM25。针对不同场景,如文本语义、图像特征、全文检索等,详细分析了各类指标的性质、适用范围和关键点。最后,提供了极简选型口诀,帮助读者在技术选型时快速找到最合适的度量方式。
在做RAG的时候,一般都会要求指定相似性度量的metric,对于文本语义,一般使用 COSINE,全文检索一般使用 BM25,这里对各种相似性度量指标做个整理归纳,供大家做技术选型。
统一前置规则
- • 距离类:数值越小 → 越相似
- • 相似度/打分类:数值越大 → 越相似
- • 分三类:稠密浮点度量、二进制度量、稀疏文本度量
- L2 欧氏距离(Euclidean)
=====================
公式
性质
- • 类型:距离,越小越相似
- • 同时看:向量方向 + 绝对数值幅值
适用
- • 图像特征、点位坐标、物理传感器数值、聚类任务
- • 不适合:文本 Embedding(幅值无物理意义)
关键点
不能随便归一化,幅值本身有业务含义
- IP 内积(Inner Product)
=======================
公式
性质
- • 类型:相似度,越大越相似
- • 同时看:方向 + 向量模长(长度)
适用
- • 推荐系统 MIPS 最大内积召回
- • 未归一化的业务打分向量
关键结论
向量L2归一化后:
排序结果完全一样,IP 计算更快
- COSINE 余弦相似度
===============
公式
性质
- • 类型:相似度,越大越相似
- • 只看向量方向,完全忽略长度/幅值
适用
- • 文本 Embedding、RAG、语义检索、问答、大模型向量
最佳实践
向量先归一化,直接用 IP 替代余弦,效果一致、性能更高
- HAMMING 汉明距离
===============
定义
两个二进制 0/1 向量,对应位置不一样的位数总数
性质
- • 类型:距离,越小越相似
- • 只看「每一位是否相同」,不看数值大小
适用
- • 图片哈希、感知指纹、短文本指纹、二进制编码
- • 配套索引:
BIN_FLAT、IVF_BIN
限制
只能用于纯二进制 0/1 向量,不能用在浮点稠密向量
- JACCARD 杰卡德相似度
=================
公式
性质
- • 类型:相似度,越大越相似
- • 只看集合有没有共同元素,不看权重、不看频次
适用
- • 用户标签、兴趣集合、商品类目、行为序列匹配、人群圈选
- • 适配:二元稀疏向量、集合型数据
特点
只关心「有无」,不关心「权重大小、出现多少次」
- BM25(Best Matching 25)
=========================
本质
TF-IDF 升级版,工业级全文检索打分算法
综合:词频TF + 逆文档频率IDF + 文档长度惩罚
性质
- • 类型:检索打分,越大越相关
- • 只做关键词字面匹配,无语义泛化
适用
- • 全文检索、RAG 关键词召回、专业术语/专有名词兜底
- • 配套:稀疏向量 +
SPARSE_INVERTED_INDEX/SPARSE_WAND
定位
RAG 标配:BM25(稀疏关键词) + COSINE(稠密语义) 混合检索
六种相似性度量指标对比
| 度量 | 类别 | 规则 | 核心关注点 | 适配向量类型 | 典型场景 |
|---|---|---|---|---|---|
| L2 | 稠密距离 | 越小越像 | 方向 + 绝对幅值 | 浮点稠密 | 图像、坐标、物理特征、聚类 |
| IP | 稠密相似度 | 越大越像 | 方向 + 向量长度 | 浮点稠密 | 推荐MIPS、归一化后替代余弦 |
| COSINE | 稠密相似度 | 越大越像 | 只看方向、忽略长度 | 浮点稠密 | 文本Embedding、RAG、语义检索 |
| HAMMING | 二进制距离 | 越小越像 | 二进制位差异数 | 0/1二进制 | 哈希指纹、图片去重、编码比对 |
| JACCARD | 集合相似度 | 越大越像 | 集合交集/并集 | 二元稀疏/集合 | 标签匹配、用户兴趣、人群圈选 |
| BM25 | 稀疏文本打分 | 越大越相关 | 词频+IDF+文档长度 | 词条稀疏向量 | 全文检索、RAG关键词召回 |
极简选型口诀
-
- 文本语义、Embedding、RAG → COSINE
-
- 推荐召回、利用向量长度做热度 → IP
-
- 图像、坐标、物理数值特征 → L2
-
- 二进制指纹、哈希去重 → HAMMING
-
- 标签、兴趣、集合匹配 → JACCARD
-
- 全文检索、关键词字面召回、RAG兜底 → BM25
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

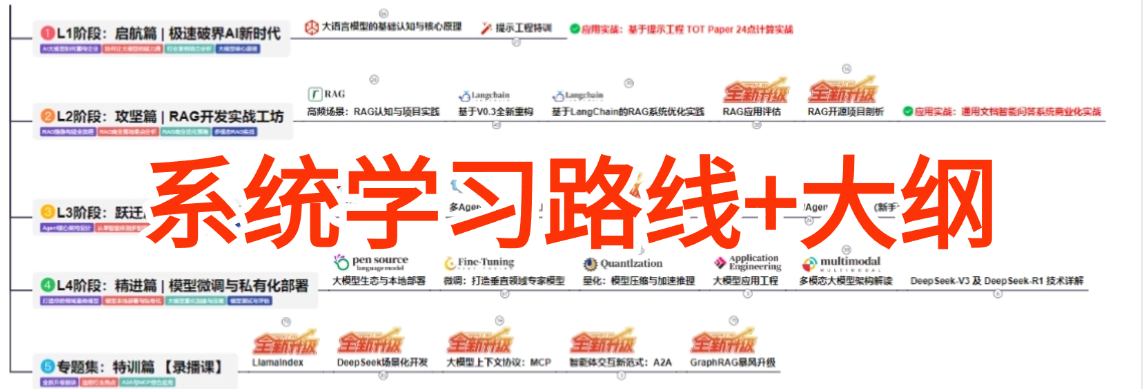
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)