RAG大模型落地必杀技:解决幻觉、私有数据三大痛点,提升回答可信度!
本文深入解析了检索增强生成(RAG)技术,旨在解决大模型应用中的知识过时、幻觉和私有数据使用难题。文章详细阐述了RAG的三大核心模块——知识库、检索和生成,并系统讲解了索引、检索、生成的具体实施流程和优化策略。此外,还提供了提升RAG检索准确率的实用方法论和评估体系,旨在帮助企业构建更可信、更贴合业务的大模型应用。
在大模型应用日益普及的今天,知识过时、产生幻觉、无法使用私有数据成为落地中的三大核心痛点。检索增强生成(RAG)正是解决这些问题的主流技术方案。它通过“外部知识库+精准检索+可控生成”的组合,让大模型输出更可信、更贴合业务的回答。
本文将从基础架构出发,系统讲解索引、检索、生成三大环节,最后给出可落地的准确率提升方法论与评估体系。
一、什么是RAG?
RAG(Retrieval-Augmented Generation),中文全称检索增强生成,是一种将信息检索与大语言模型(LLM)相结合的 AI 技术框架,相当于给大模型装上了一个可随时更新、可精准调用的外部知识库。
它经历了三个阶段的演进:
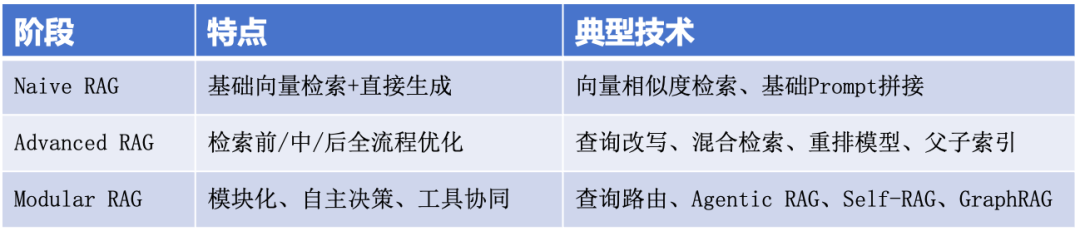
核心本质:用精准检索约束大模型生成,实现“知识可信、来源可查、实时更新”。
二、RAG 基础架构与核心流程
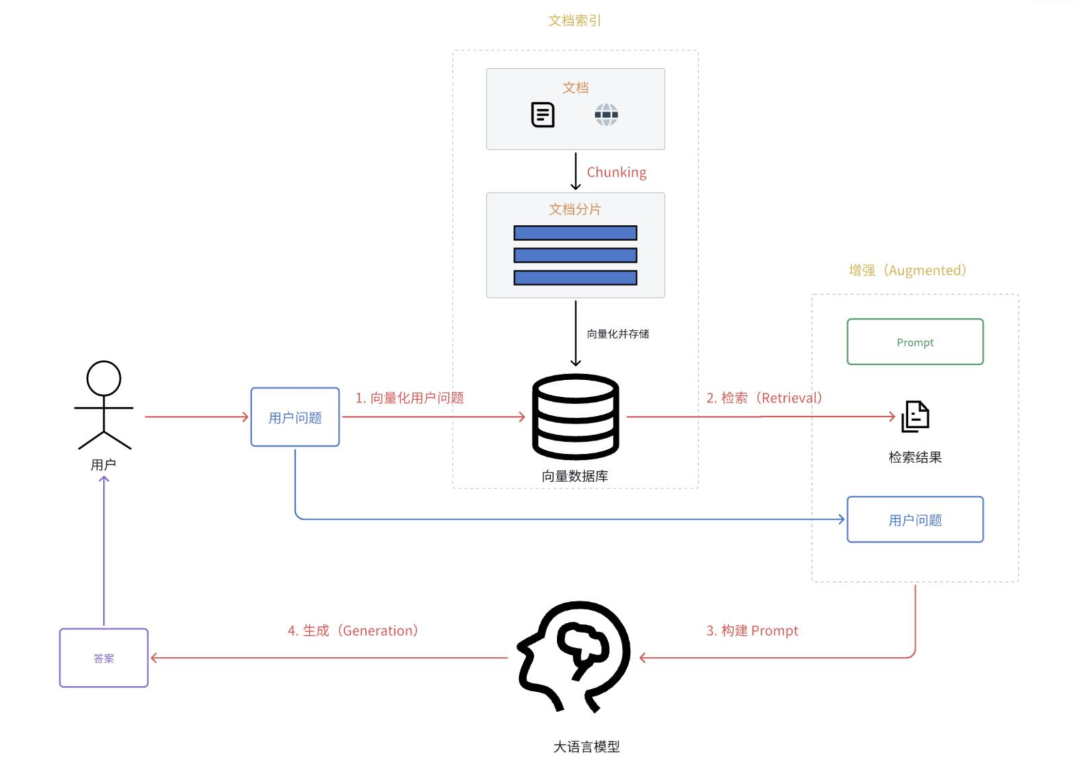
RAG 核心由三大模块协同工作:
1.知识库模块:存储PDF/Word/网页/表格/数据库等多源数据,预处理后存入向量数据库(Milvus、Chroma、Pinecone)。
2.检索模块:根据用户问题,从知识库中召回最相关内容,决定效果的关键环节。
3.生成模块:以检索内容为约束,让大模型生成不编造、可溯源的回答。
RAG的整体工作流程如下:
三、索引阶段:知识准备(离线处理)
(一)数据采集与清洗
文本清洗:剔除重复、错误、过时内容;去除页眉页脚、乱码、广告、无关格式标签。
多模态处理:
·图片:OCR提取文字或用多模态模型生成图片描述文本。
·表格:专用解析器(Table Transformer、Camelot)转Markdown,避免直接硬切。
·扫描版PDF:先OCR识别,再进行版面分析,区分正文、标题、页眉页脚。
处理后的内容再与其他文本一起分块入库。
(二)文档分块(Chunking)
超长文档直接向量化会导致语义稀疏、精度下降,按文档类型选择分块策略:
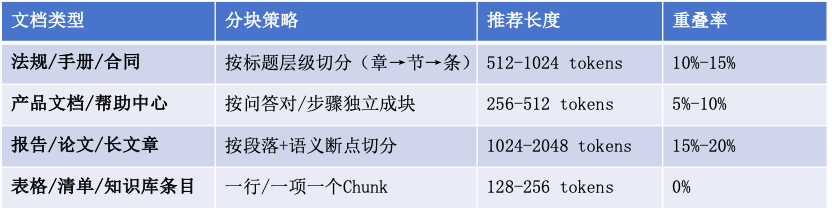
通用策略建议:
·优先按语义完整性切分(利用句子边界、段落、标题等)。
·分块长度:取嵌入模型的最大输入长度的30%-70%。
·推荐父子索引:将大切片作为“父切片”(保留上下文),小切片作为“子切片”(用于检索)。
(三)向量化与入库
用嵌入模型(Embedding Model)将文本块转为高维向量,与元数据(来源、标题、时间、部门)一起存入向量数据库,并建立索引以支持快速相似性搜索。
四、检索阶段:从召回 to 精排
(一)查询理解与预处理
1.基础预处理:去除冗余字符、纠正拼写歧义。
2.意图识别:明确查询类型(事实查询、操作指南、对比分析、摘要请求等)。
3.查询改写(可选优化):
标准化改写:将口语化查询转为规范表达(如“怎么报销”→“公司差旅费用报销流程及标准”)。
HyDE:用LLM生成假设理想回答,再用该回答的向量去检索,能显著提升口语化查询的召回率。
子问题分解:将复杂多跳问题拆分为多个子问题分别检索(如“对比A和B在C场景下的优缺点”→拆成3个子问题)。
4.多轮对话处理:将最近3-5轮问答压缩为上下文,进行指代消解(如“那它的价格呢?”中的“它”需替换为前文实体),再重构查询。
⚠️ 注意:查询改写、意图识别通常需要额外调用 LLM,会带来延迟和成本,属于高级优化,适用于对准确率要求极高的场景。
(二)查询向量化(Query Embedding)
经过预处理的查询文本,需要编码为与文档同一语义空间的高维向量,才能与向量数据库中的文档切片进行相似度比对。
(三)混合召回(Hybrid Retrieval)
检索模块将编码后的查询向量,与向量数据库中存储的切片向量进行相似性比对,初步召回一批相关度较高的切片。单一检索方式存在局限,工业级 RAG 普遍采用混合召回:
语义检索(向量检索):擅长捕捉文本语义相似性,适合处理复杂、口语化的查询;
关键词检索(如BM25算法):擅长精确匹配专有名词、核心短语,计算高效。
两种结果通过RRF(倒数排序融合)算法进行融合,避免单一检索方式导致的漏检、误检。
(四)重排与过滤(Reranking)
初步召回的内容存在噪声,必须二次精筛:
1.重排模型:使用 Cross-Encoder(交叉编码器)深度计算查询与文档的相关性。
2.结果过滤:保留 Top 5-10 条最相关内容,剔除相似度低于阈值(如0.5)的片段,合并重复内容。
⚠️ 性能权衡:Cross-Encoder计算开销较大(对Top 100重排可能比检索本身更耗时)。追求低延迟时,可先用轻量级重排模型(如BGE-Reranker)或仅依赖混合检索。
五、生成阶段:从检索结果到可信回答
生成模块不是简单地把检索文本塞给大模型,而是需要通过结构化的 Prompt 工程,让模型理解检索内容的边界、遵循引用规范、并在知识不足时主动拒绝。
(一)Prompt 构建与上下文组织
Prompt 通常分为 System Prompt(系统指令)和 User Prompt(用户查询+检索上下文) 两部分:
1.System Prompt 模板
示例:

2.User Prompt 模板(检索上下文注入)
示例:

3.少样本示例(可选)
对于复杂格式,可在 User Prompt 中加入 1-2 个示例:

(二)生成策略与约束机制
1.拒绝回答机制(Guardrails)
前置过滤:若 Top-1 检索片段相关度低于阈值(如 0.4),直接返回“未找到相关信息”
后置校验:解析回答中的 [n] 引用标记,验证编号是否存在、引用内容是否与原文一致
2.提示词压缩(Prompt Compression)
当召回内容超过 LLM 上下文限制时,使用LLMLingua等工具去除冗余 Token。
(三)反馈闭环
反馈:用户点赞/点踩、手动纠错
持续优化:利用反馈数据定期优化 Prompt 模板和检索策略
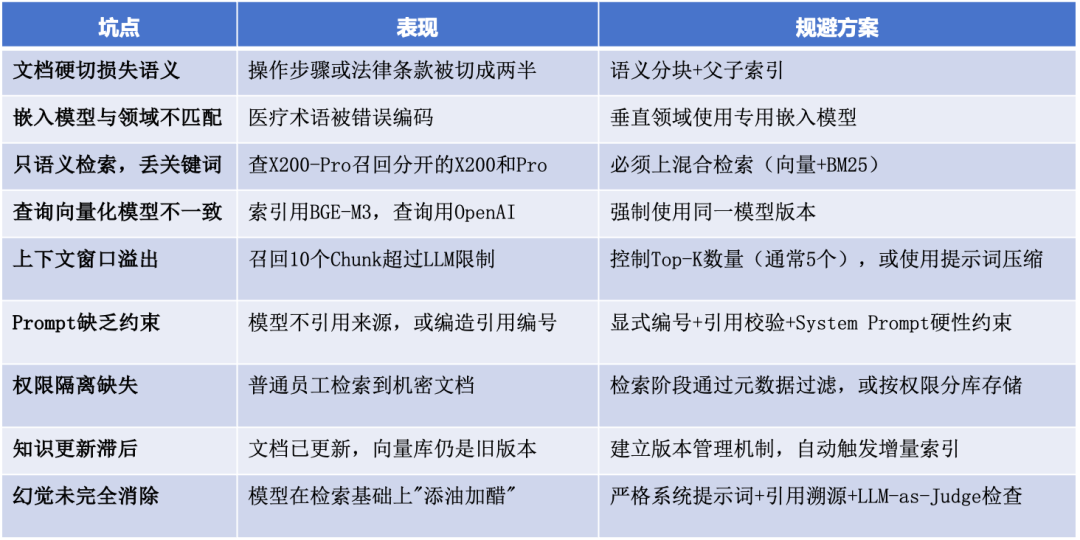
六、RAG 落地易踩坑点与规避
七、如何提升RAG检索准确率
建议按以下优先级优化:
Level 1:数据与索引(ROI最高)
清洗脏数据,建立标准化流水线
优化分块:语义分块+父子索引,长度匹配嵌入模型
丰富元数据:文档类型、部门、时间、权限标签
向量库索引参数调优:平衡速度与精度
Level 2:查询理解与检索策略
意图识别:明确查询类型,必要时引入交互式澄清(如追问"您指的是A产品还是B产品?")
查询向量化:确保模型一致、指令模板正确、度量方式对齐
混合检索:语义+关键词,RRF融合
查询改写:同义词扩展、HyDE(成本允许时)
复杂问题分解:将多跳问题拆分为多个子问题分别检索,再聚合结果
重排优化:引入Cross-Encoder(延迟允许时)
Level 3:模型与架构
领域适配:微调嵌入模型或重排模型
引入进阶技术:查询路由(多库场景)、GraphRAG(复杂推理场景)
Level 4:生成与评估
Prompt工程优化:显式编号、引用约束、拒绝回答机制
持续评估与A/B测试:部署自动化指标监控,对比不同策略效果,形成优化闭环。
八、RAG 的评估方法
没有评估就无法客观衡量优化效果。建议同时评估检索和生成两个环节:
检索指标:
Hit Rate(Top-K 中是否包含正确答案)
MRR(平均倒数排名)
NDCG(考虑排序质量)
生成指标:
Faithfulness(回答是否忠实于检索资料)
Answer Relevance(回答是否切题)
Hallucination Rate(幻觉率)
Citation Accuracy(引用准确率)
总结
RAG 的本质是:用精准检索约束大模型生成,实现 “知识可信、来源可查、实时更新”。
它没有唯一最优解,但遵循以下顺序能稳定满足企业级需求:
数据质量>分块策略>查询向量化>检索策略>重排模型>Prompt工程>生成优化
建议从 Naive RAG 快速验证,逐步引入 Advanced RAG 技术,再根据业务复杂度考虑 查询路由、GraphRAG 等进阶模块。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)