大模型到底是怎么训练出来的?
本文揭秘了LLM(大型语言模型)的训练真相,指出其核心是预测下一个token,但背后需要海量数据、成千上万GPU及复杂工程系统支撑。文章详细解析了数据准备(“赛博洗菜”)、Tokenizer机制、预训练原理、扩展规律、工程系统挑战、后训练与对齐,以及持续评测迭代的全过程。强调大模型并非魔法,而是数据、算力与工程系统的复杂结合体,其发展像一座不断扩张的巨大工程城市。

一张图看懂 LLM 的“成长史”
这几年,大模型已经逐渐从“科技新闻里的未来概念”,变成了大家每天都能接触到的工具。它会写代码、做 PPT、整理会议纪要、生成图片,甚至还能像一个经验丰富的同事一样帮你分析问题。于是很多人开始好奇:这些看起来越来越“聪明”的 AI,到底是怎么被训练出来的?
很多人以为,大模型训练像电影里的科幻场景,工程师按下一个按钮,AI 就突然觉醒了。现实其实更像一座庞大的工业体系。大模型背后并不是“魔法”,而是一整套围绕数据、算法、算力、工程系统和人类反馈构建起来的复杂流程。简单来说,大模型训练的核心目标只有一个:
让模型能够根据上下文,更准确地预测下一个 token。
但为了把这件事做到极致,人类投入了海量数据、成千上万张 GPU,以及极其复杂的工程体系。今天,我们就用最通俗的方式,把大模型训练这件事彻底讲明白。
①数据准备:模型先要“吃饱饭”
训练大模型的第一步,其实并不是写算法,而是准备数据。因为模型本身并不会凭空产生知识,它看到的世界,本质上来自训练时“吃进去”的文本。
这些数据通常来自网页、书籍、论文、代码、问答、论坛、对话记录以及各种行业文档。听起来似乎很美好,但真实互联网的数据质量,其实相当混乱。里面既有高质量知识,也有大量重复内容、广告、标题党、错误代码,甚至还有 AI 自己生成的废话。如果把这些东西原封不动喂给模型,结果往往不会变成“超级智能”,而会变成“超级胡说八道”。
所以在真正训练之前,需要先做大量的数据处理工作,包括去重、清洗、去噪、安全过滤、数据配比和混合采样等。这个过程有点像做大型中央厨房。原材料再多,也不能不洗不挑就直接下锅。数据团队每天做的事情,本质上就是在进行一场“赛博洗菜”。
这一阶段有一个非常重要的行业共识:
数据质量决定模型上限,数据多样性决定模型泛化能力。
换句话说,垃圾数据即使再多,也不会自动长成一个优秀模型。模型最终能学到什么,很大程度上取决于它看过什么。
②Tokenizer:AI 其实并不“认识字”
很多人第一次接触大模型时,会下意识觉得 AI 是在“读文字”。但实际上,模型根本不直接理解中文、英文或者代码。它首先会把文本拆成一种叫 token 的单位。
比如一句“今天天气很好,我们去散步吧”,在进入模型之前,会先被拆分成多个 token,再转换成对应的数字编号(token ID),最后变成向量形式输入神经网络。整个流程大致可以理解为:
文本 → token → id → embedding → Transformer
所以模型真正处理的,其实是一堆高维数字坐标,而不是人类意义上的“文字”。
这里还有一个很关键的概念叫“位置编码”。因为模型不仅需要知道有哪些 token,还需要知道它们出现的顺序。比如“我喜欢你”和“你喜欢我”,字差不多,但意思完全不同。位置编码就是帮助模型理解“顺序关系”的机制。
从某种角度来说,大模型并不像人在阅读一本书,更像是在一个超高维数学空间里,学习不同 token 之间的统计关系。
③预训练:真正让模型变聪明的阶段
接下来进入整个训练流程里最核心的部分,也就是“预训练”。
预训练的本质其实非常朴素:让模型不断预测下一个 token。比如输入“北京是中国的”,模型需要预测下一个词大概率是“首都”;输入“老板说这个需求很简单,只需要”,模型可能会预测“今天下班前做完”。
听起来似乎只是一个简单的“文字接龙游戏”,但当这个过程在海量语料和超大参数规模下持续进行时,模型会逐渐学会语言规律、知识关联、代码结构,甚至形成一定程度的推理能力。
这里很多人容易误解,以为模型真的“理解”了世界。实际上,大模型更像是在海量文本中学习一种概率分布。它并不是像人类一样拥有真正的常识和意识,而是在训练过程中逐渐学会:
什么内容通常会接在什么内容后面。
当然,把这件事做到极致并不容易。训练过程中需要不断进行前向计算、损失计算和反向传播,再通过优化器更新参数。整个过程会重复无数次,直到模型从一个随机输出乱码的系统,逐渐成长为一个能够流畅对话、写代码、做推理的语言模型。
所以很多人说,大模型像“压缩后的互联网”。这句话其实很形象,因为它确实是在海量文本统计关系中,逐渐形成了某种对世界的抽象表示。
④Scaling Law:不是参数越大越好
过去几年,行业里最容易被外界误解的一件事,就是“参数崇拜”。很多人觉得,只要参数越大,模型就一定越强。
但现实没有这么简单。
研究发现,模型性能通常会随着参数规模、数据规模和训练计算量的提升而提升,这就是所谓的 Scaling Law(扩展规律)。但这里有个关键点:这三者需要协同增长,而不是只疯狂堆其中一个。
如果只增加参数,而没有足够高质量数据,模型就像一个巨大图书馆,但里面全是重复小广告;如果只有大量数据,没有足够算力,训练效率会非常低;如果只有算力而缺乏合理的数据和模型设计,那就像用超跑去送外卖,成本高得离谱。
这也是为什么现在行业越来越强调“计算最优训练”。真正优秀的大模型,并不是简单堆参数堆出来的,而是参数、数据和算力之间的一种动态平衡。
所以今天的大模型竞争,本质上已经从“谁模型更大”,逐渐演变成“谁的数据更好、训练系统更强、工程优化更成熟”。
⑤训练系统:真正困难的部分其实在工程
很多人以为训练大模型就是运行一句:python train.py
然后模型就自动开始变聪明了。
现实完全不是这样。真正困难的部分,往往不在算法,而在工程系统。
因为现在的大模型训练,通常需要成百上千张 GPU 协同工作,还涉及多机通信、显存管理、数据并行、张量并行、流水线并行等复杂机制。整个系统像一座超大型工业流水线,任何一个环节出问题,都可能导致训练中断。
工程团队每天面对的事情包括:显存不够、通信太慢、梯度爆炸、训练不稳定、Checkpoint 损坏、电费过高等等。很多时候,训练一个大模型更像是在运营一座“数字化发电厂”。
有业内工程师开玩笑说:
大模型训练最像的,其实是几千个厨师同时炒一锅蛋炒饭。
每个人负责不同部分,还必须同步节奏,不能有人突然断网、掉卡或者炸锅。
所以今天的大模型竞争,本质上不仅是算法竞争,更是系统工程能力的竞争。谁能更稳定、更高效、更低成本地完成训练,谁就拥有真正的优势。
⑥后训练与对齐:让模型学会“正常聊天”
经过预训练后,模型已经具备了很强的语言能力,但这时候它还不能算真正“好用”。
因为预训练模型虽然知道很多知识,却未必知道“怎么和人交流”。你让它写会议纪要,它可能突然开始长篇大论;你问它一个简单问题,它可能给你输出一段哲学散文。
于是行业开始引入后训练与对齐阶段,包括 SFT(监督微调)、RLHF(基于人类反馈的强化学习)、DPO(直接偏好优化)等方法。
这些技术的目标其实非常统一:
让模型更符合人类偏好。
换句话说,预训练解决的是“会不会”,而后训练解决的是“像不像一个靠谱助手”。
这一阶段里,人类会给模型大量“什么回答更好”的反馈,帮助它逐渐学会更自然、更安全、更符合用户需求的表达方式。所以今天我们看到的大部分聊天模型,其实不仅仅是“知识模型”,更是经过大量“社会化训练”的结果。
⑦评测与迭代:模型发布只是开始
很多人以为模型发布就是终点,但实际上,发布往往只是新一轮迭代的开始。
因为再强的模型,也会出现幻觉、错误推理、安全问题以及各种奇怪行为。所以模型上线之后,还需要持续评测,包括代码能力、数学能力、推理能力、安全性、指令遵循、人类偏好等多个维度。
发现问题之后,团队通常会重新补充数据、修复训练流程,再继续微调和优化。整个过程形成了一个持续循环:
评测 → 发现问题 → 数据回流 → 再训练 → 再评测
所以优秀模型从来不是“一次性训练成功”的,而是在长期迭代中慢慢长出来的。这一点其实和互联网产品非常像。真正成熟的系统,往往都不是第一次上线时最强,而是在持续打磨中逐渐稳定。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

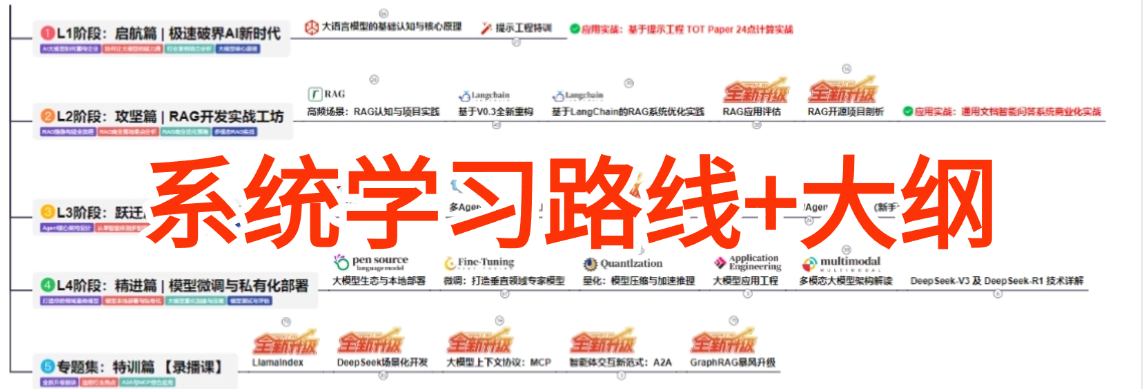
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)