腾讯面试官:RAG有5000万数据要换模型,怎么不停服?
一、面试现场
面试官提问
“5000 万向量换 embedding,停服重跑吗?”
腾讯索引迁移面。候选人答了三分钟,方向是"晚上停服全量重跑 embedding"。面试官追了一句:"出问题怎么回滚?"候选人卡住了。这道题看似在问迁移步骤,实际在考你能不能区分"原地升级"和"新索引切读"——前者根本回不去,后者出事能秒退。
直接回答: 换 embedding 不是原地升级,是切读哪个索引。
听起来有点玄。我们先看大多数候选人是怎么栽的,再讲怎么做对。
二、大多数人怎么答的
典型翻车回答
“停服 2 小时,全量重新生成 embedding,再切流量。”
停服重跑三个硬伤:5000 万条重算时间不可控,停服窗口覆盖不住;切完没影子对比,新模型好不好全凭运气;最严重的是没回滚窗口——出事只能硬扛。
新旧向量空间距离不可比——没有影子流量和事前写死的回滚阈值,就别让新索引直接接用户。下面把"正确的换法"拆成四个判断点,一条一条对照。
三、深度解析(判断框架)
四个判断点:新旧空间隔离、双写压窗口、影子流量先看、回滚阈值先写死。下面逐条拆开。
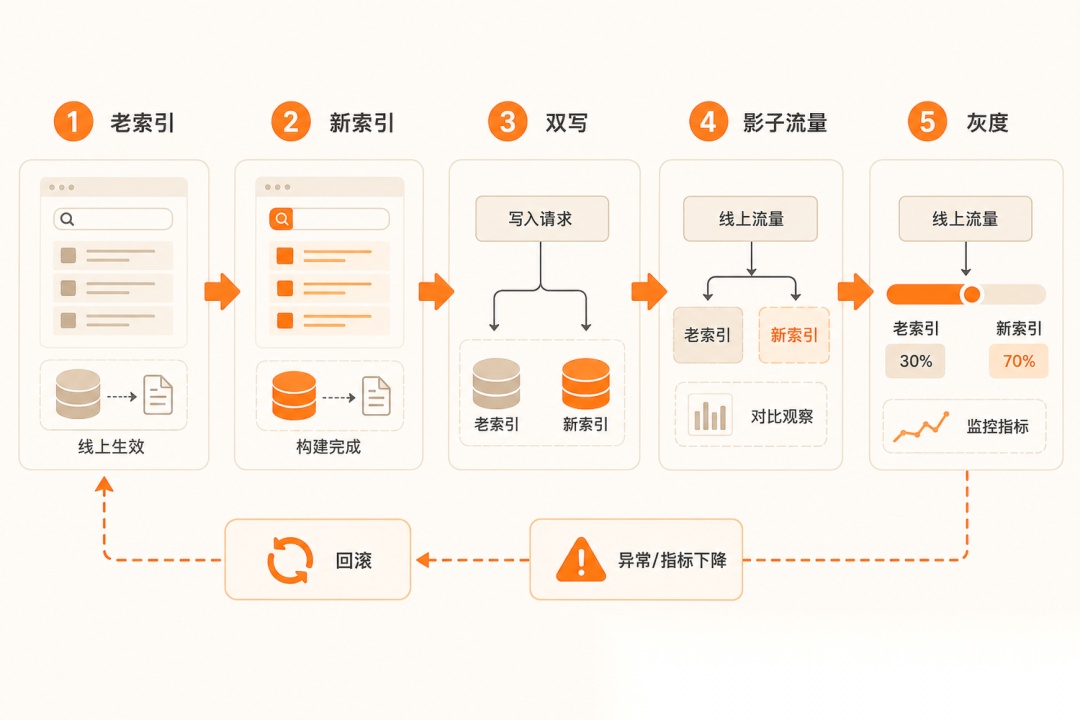
判断 1:新旧向量空间不可比,必须建新索引
v1 和 v2 维度可能不同;就算同维度,“靠近"的含义也变了——v2 向量灌进 v1 索引,召回会乱套。关键在于: v2 向量一律进新索引,老索引原样保留,“切换” = 切读流量指向哪个索引,不是"原地升级”。Milvus / Pinecone / Weaviate 等向量库都支持索引版本化,并存两份就好。
判断 2:双写压窗口——迁移期越短越不容易脏
上线起,新增 / 变更文档同时写老索引和新索引;否则迁移跑一周,新索引就落后一周的数据,越拖越脏。别混: 双写不是 A/B——双写是"两份索引都写满",A/B 是"用户分两组看不同结果",面试时别串。
判断 3:影子流量先看——新结果不给用户,只对比命中差
抽一部分线上请求同时打新老索引,新索引结果落库但不返用户。对比命中率、人工答对率、长尾召回。坑: 影子流量一旦返用户就变成 A/B——影子是"零风险先看一眼",破了就没意义。
判断 4:回滚阈值事前写死——不靠"看一眼觉得不对"
切第一档之前就把量化触发条件写进配置:命中率跌超 3% / 答对率跌超 2% / 点踩率涨超 1.5 倍,任一命中自动回切。坑: "感觉不对再回滚"两头不讨好——要么舍不得回(都切 30% 了),要么草木皆兵。阈值写死 + 自动触发,不靠情绪。
排查顺序:先看流量打的哪个索引,再看影子期指标对比,最后看 chunk 参数。trace 表必须有五列——查询内容、索引版本、返回文档 ID、是否命中、用户反馈,五列补齐再谈自动化。80% 的迁移事故不是新模型不好,是没影子对比直接切、回滚阈值没写、或灰度跳档(5% 直接到全量)。
框架讲完,面试现场不会放过——下面三个最常见的追问。
四、面试官追问链
追问 1
“双跑期间存储成本翻倍,怎么压缩窗口?”
三招压窗口:
① 离线重建用空闲时段批量算力——5000 万条压到 1-2 天跑完
② 双写窗口只覆盖"重建期 + 影子期 + 灰度期"——稳定 N 天就下老索引
③ 老索引灰度期降冷存 / 小副本——把老索引搬到便宜的冷存储 / 把机器数缩小,只做兜底回滚不扛线上流量
算笔账: 总窗口 = 重建 + 影子 48h + 灰度 1 周 + 观察 N 天,到点强制下老索引。
追问 2
“影子流量怎么对比’哪个模型更好’?指标用什么?”
不能只看一个数,分三层:
① 自动指标——标注集上的命中率和新老 top-k 重叠度
② 半自动——抽差异最大的请求人工标"哪边更相关"
③ 端到端——接到生成,人工评答对率
坑: 只看命中率涨就切,结果生成端答对率没动甚至掉了——检索更"准"不等于答案更好。优先顺序: 自动指标筛掉明显变差的 → 人工标长尾 → 端到端评一小批再切。
追问 3
“切到新模型 30% 流量后发现命中率降了 4%,是回滚还是先排查 chunk?”
看降幅是否过回滚阈值。3% 阈值下 4% 已过线——先回滚止血,至少把灰度降回 5%,再慢慢排查。排查方向:
① chunk 切分参数对新模型不合适(对 chunk 长度更敏感)
② 某几个长尾类目掉得特别狠——先只回滚那些类目
③ 影子期样本量不够没暴露问题
坑: “先排查再决定要不要回”——30% 用户已经受影响,排查一查就是几小时,不能让用户陪你调试。
五、5000 万向量平滑迁移实战
场景:知识库 5000 万条向量,从 v1 升到 v2,线上不能停。下面一次完整迁移,每步先给动作、再给结果。
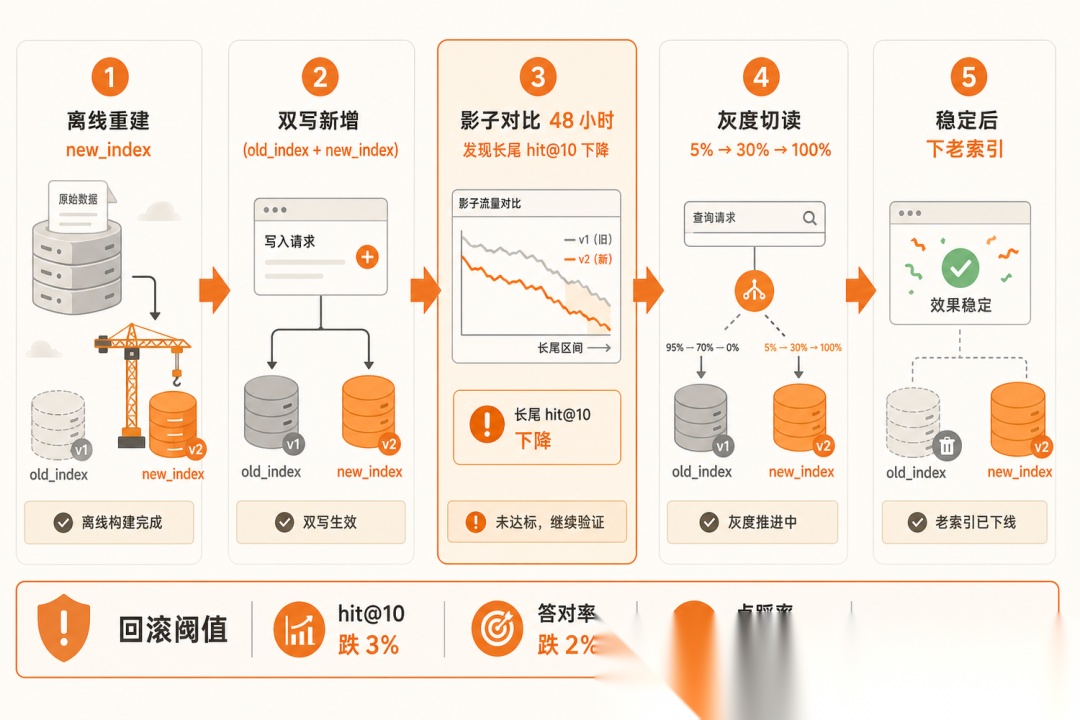
STEP 1 · 离线重建新索引
现有文档全量用 v2 写入新索引,离线跑、不影响线上。
↳ 结果:5000 万条约 1.5 天跑完,老索引照常服务。
STEP 2 · 双写新增
新增/变更文档同时写老索引(v1)和新索引(v2),迁移期两份都活。
↳ 结果:新索引不会落后,迁移期再拖也不脏。
STEP 3 · 影子对比 48 小时
抽 20% 请求暗打新索引,结果不返回用户,只比命中率和答对率。
↳ 结果:发现长尾类目命中率 -4.6%,先回去调 chunk 参数,没带病上线。
STEP 4 · 灰度切读 5% → 30% → 全量
按用户分桶逐档放量,每档盯回滚阈值(同判断 4),任一触发就回切,稳定 N 天后下老索引。
↳ 结果:灰度全程零回滚,30% 那档没有放大成全量事故。
↳ 改造数字
匿名迁移复盘(示意口径):5000 万 条向量 v1 升 v2,全程线上不停;影子期发现长尾类目命中率 -4.6%,修完 chunk 参数再启灰度;灰度 5% → 30% → 全量 历时约 9 天,零回滚。没停服、没事故,靠的是"先影子后灰度 + 阈值写死"。
我的判断
我的优先顺序: 先物理隔离新老索引,再上双写和影子,最后才灰度切读——回滚阈值必须在切第一档之前就写进配置,没写死就别切。
六、本课总结
一句话总结
换 Embedding 不出事的核心:新老向量空间隔离 + 双写 + 影子流量 + 量化回滚阈值,停服全量重跑是最差的解。
面试锦囊
先说: embedding 切换的本质是向量空间不兼容,必须建新索引,老索引保留做回滚,“切换” = 切读流量指向。再说: 双写压窗口;影子流量先看(不返用户,只比命中率/答对率/长尾);回滚阈值事前写死(命中率跌 3% / 答对率跌 2% / 点踩率涨 1.5x 任一触发)。最后补: trace 必有索引版本、是否命中、用户反馈三列;灰度按用户分桶 5% → 30% → 全量,不跳档;稳定 N 天才下老索引。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)