NTK / YaRN(RoPE 外推技术)详解
基础定义
- 全称:NTK-aware Scaling(神经切线核感知缩放)/ YaRN(Yet another RoPE extensioN)
- 核心目标:解决原生 RoPE超出训练长度后性能骤降的致命缺陷,实现 "训练短、测试长"
前置知识:RoPE 频率分工
RoPE 旋转角度公式:
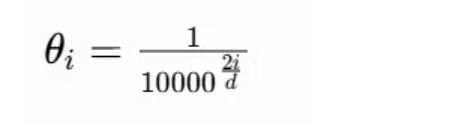
- 低频维度(小旋转角度,长波长):负责长距离依赖、全局位置信息,泛化能力极差
- 高频维度(大旋转角度,短波长):负责局部细节、相邻 token 顺序,泛化能力极强
原生 RoPE 外推失败的本质
训练时模型只见过 [0, L_{train}] 的角度分布:
- 高频维度:只关心相对角度差,pos 变大差不变,天然可外推
- 低频维度:角度直接超出训练见过的分布,模型完全无法识别,导致整体崩溃
三代 RoPE 外推技术演进
初代:位置插值(PI,已淘汰)
- 核心思路:所有位置统一压缩到训练范围:

- 致命缺陷:局部失明—— 高频维度也被压缩,相邻 token 区分度消失
- 最大外推:2~4 倍,性能损失大
二代:NTK-aware Scaling(过渡方案)
- 核心:高频外推、低频内插
- 实现方式:一行代码缩放 base: 此base代替了RoPE 旋转角度公式的分母10000
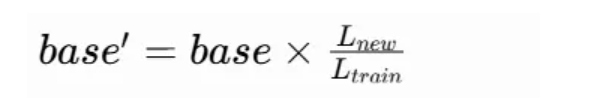
Ltrain 训练上下文长度 Lnew 新推理上下文长度
- 效果:自动实现非线性分治 —— 低频明显压缩,高频几乎不变
- 升级:动态 NTK(根据输入长度自动调整缩放因子)
三代:YaRN(当前工业界最优)
- 核心改进 1:显式分段频率插值(比 NTK 更精准)
1)高频段:λi<Ltrain(短波长,高频维度):
波长小于训练长度,原生θi天然可外推,不做任何修改 ![]()
旋转角度:![]() ,保持原生 RoPE 周期循环特性,角度差Δϕ=Δpos⋅θi 稳定。
,保持原生 RoPE 周期循环特性,角度差Δϕ=Δpos⋅θi 稳定。
2)中频段:Ltrain<λi<Lnew(中等波长,中频维度)→ 线性混合插值在「原生基频θi」和「NTK 全局缩放基频θi/s」之间做线性插值:
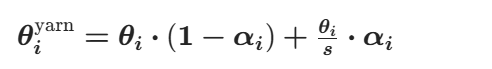
其中插值权重: 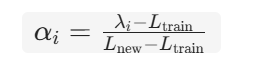 ,实现平滑过渡,避免角度突变。
,实现平滑过渡,避免角度突变。
3)低频段:λi>Lnew(长波长,低频维度)→ 完全内插(和 NTK 一致):
![]()
此时总旋转角度: ![]()
保证超长 pos 下,ϕ(i,pos )落在训练时的角度区间内,解决低频维度角度超出分布的问题。
- 核心改进 2:注意力温度修正—— 解决长序列 logits 方差爆炸导致的注意力坍塌
- 温度系数定义 τ = log(s)
![]() :外推倍数(如训练 512→推理 4096,s=8)
:外推倍数(如训练 512→推理 4096,s=8)
本质:外推倍数越大,温度越高,压缩力度越强
2.修正后的注意力分数![]()
dk:原生注意力缩放项,和温度修正叠加
三代方案核心对比
|
方案 |
核心思路 |
最大外推倍数 |
性能损失 |
实现复杂度 |
现状 |
|
PI 位置插值 |
统一压缩所有位置 |
2~4 倍 |
大 |
极简 |
淘汰 |
|
NTK-aware |
缩放 base,隐式分治 |
4~8 倍 |
中 |
简单 |
过渡 |
|
YaRN |
分段插值 + 温度修正 |
16~64 倍 |
极小 |
稍复杂 |
工业界标配 |
与 ALiBi 终极对比
|
维度 |
ALiBi |
RoPE + YaRN |
|
外推能力 |
原生自带,无需补丁 |
原生无,后天补全 |
|
训练内性能 |
略差 |
更好(RoPE 本身优势) |
|
实现复杂度 |
极简 |
中等 |
|
生态支持 |
小众(BLOOM/MPT) |
绝对主流(LLaMA/Qwen/Mistral) |
|
最大上下文 |
84k(MPT) |
256k+(YaRN) |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)