ActionParser 从基线评测到中文微调:模型训练、结果分析与版本留存
在前几次工作中,我已经完成了 StoryVerse 项目中 ActionParser 模块的大部分前期准备工作。首先,在 AutoDL 实例中完成了项目环境搭建,将全部项目文件、模型和数据统一放在 /root/storyverse 路径下,保证后续保存镜像时能够完整保留项目状态。随后,我创建了专门的 storyverse conda 环境,安装了训练与评估所需依赖,并完成了基座模型加载测试。之后,我围绕 ActionParser 的任务目标,对 Hermes、SGD 以及中文小说数据进行了多轮处理,最终完成了中文小说动作解析数据集的半自动标注、数据划分、自检,以及评估脚本和训练流程的初步搭建。
这些前期工作为本次模型训练和评测打下了基础。因为 ActionParser 并不是简单的文本生成任务,而是要将小说交互场景中的自然语言输入解析为结构化动作 JSON,所以在正式微调前必须先确认几个问题:基座模型在不训练的情况下表现如何,warmup 后模型是否具备更好的格式输出能力,中文任务微调是否真正提升了动作解析效果,以及最终训练出的模型是否可以作为后端 FastAPI 调用的稳定版本。本次工作的重点,就是围绕这些问题完成完整的训练、评测和结果对比。
一、微调前的 Base 模型评测:建立可对比的基线结果
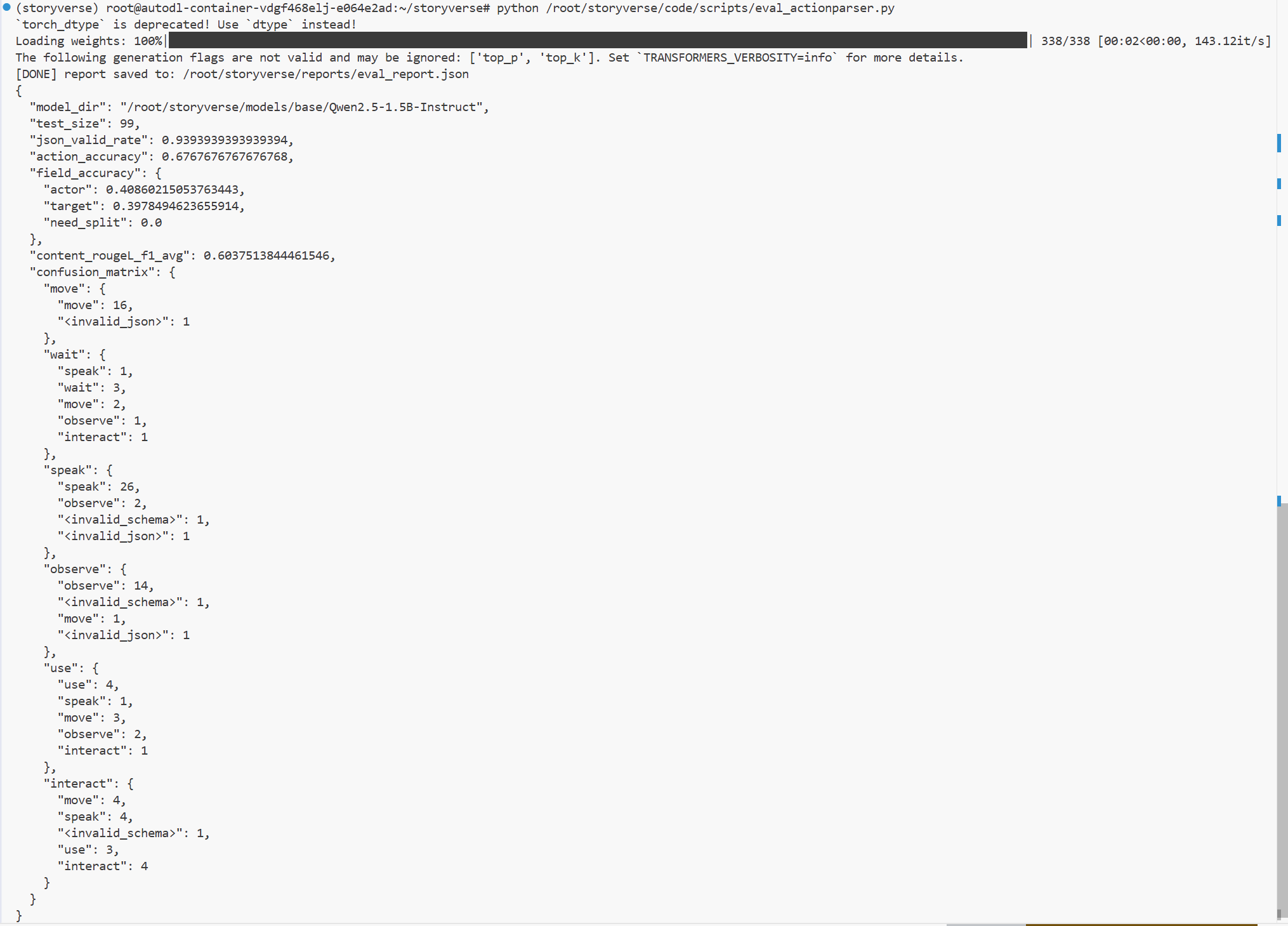
本次工作首先从基座模型评测开始。之所以要先评测 base 模型,是因为只有明确微调前模型的原始能力,后续训练结果才有比较意义。如果直接训练并查看最终结果,虽然可以知道模型是否能完成任务,但无法判断提升究竟来自哪里,也无法说明微调是否真正有效。
在评测过程中,我使用统一的 ActionParser 测试集对 base 模型进行推理,并通过评估脚本统计 JSON 合法率、动作类型准确率、actor 字段准确性、target 字段准确性以及 content 内容相似度等指标。这里我保持了和后续模型完全一致的测试数据和评估标准,确保 base、warmup 和最终中文微调模型之间可以直接对比。
从 base 模型的表现来看,它虽然具备一定的通用指令理解能力,但并不能很好地适配 ActionParser 任务。主要问题集中在三个方面。第一,输出格式不够稳定。模型有时会在 JSON 前后添加解释性文字,或者出现字段缺失、布尔值格式不规范等问题,这会影响后端解析。第二,动作类型判断不稳定。对于小说句子中的行为,base 模型容易将复杂动作泛化为普通描述,或者把多种动作都归到“说话”类,说明它还没有学习到 StoryVerse 任务中固定的动作分类体系。第三,字段抽取不够准确,尤其是 target 字段容易遗漏或误判,这说明它对小说语境中的动作对象、人物关系和隐含目标理解不足。
因此,base 评测的主要结论是:基座模型虽然可以作为训练起点,但不能直接作为 ActionParser 后端模型使用。它需要经过结构化输出训练和中文小说领域数据微调,才能满足项目需求。
二、Base 与 Warmup 阶段的中文微调训练:从通用能力到任务对齐
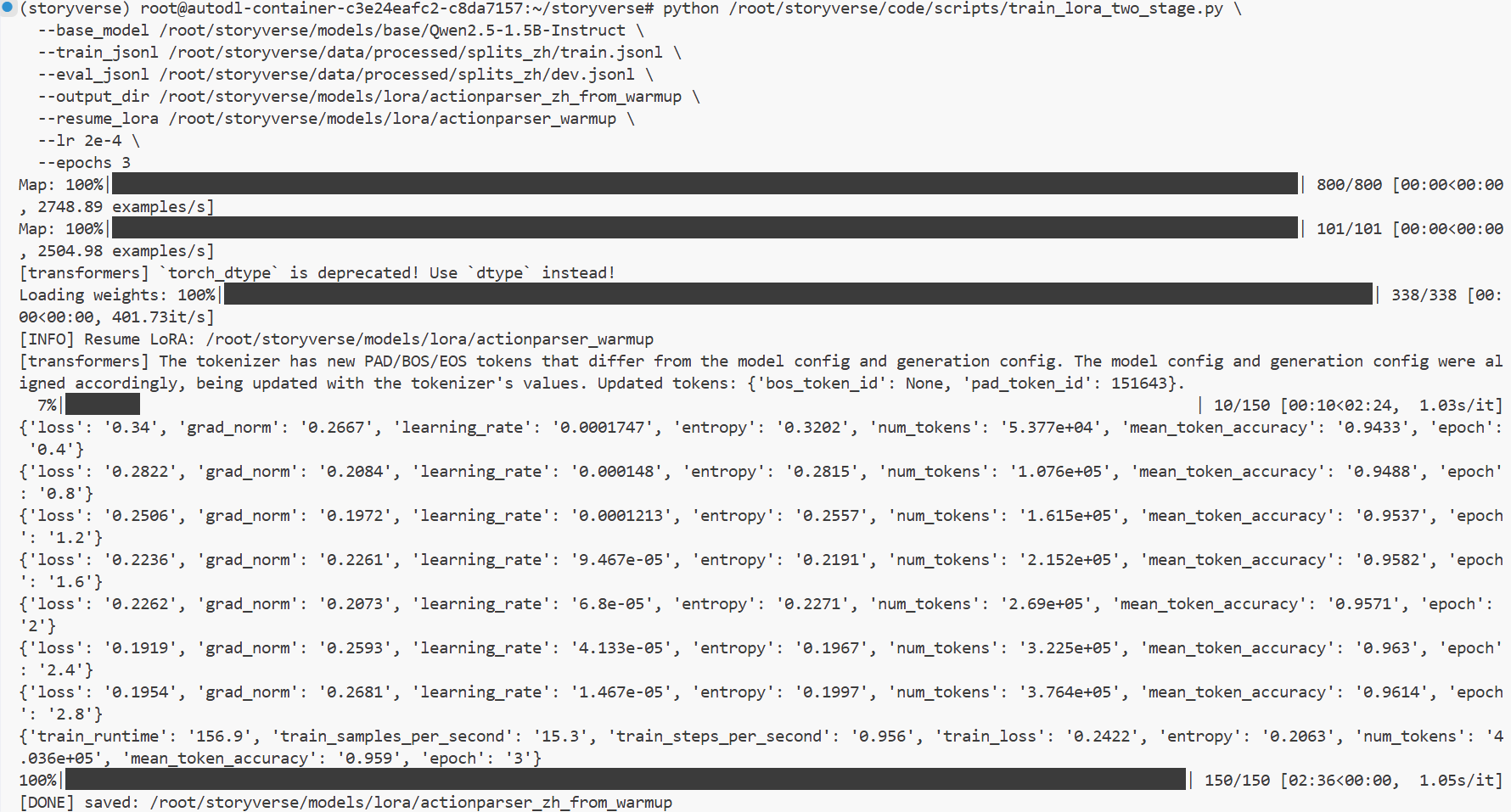
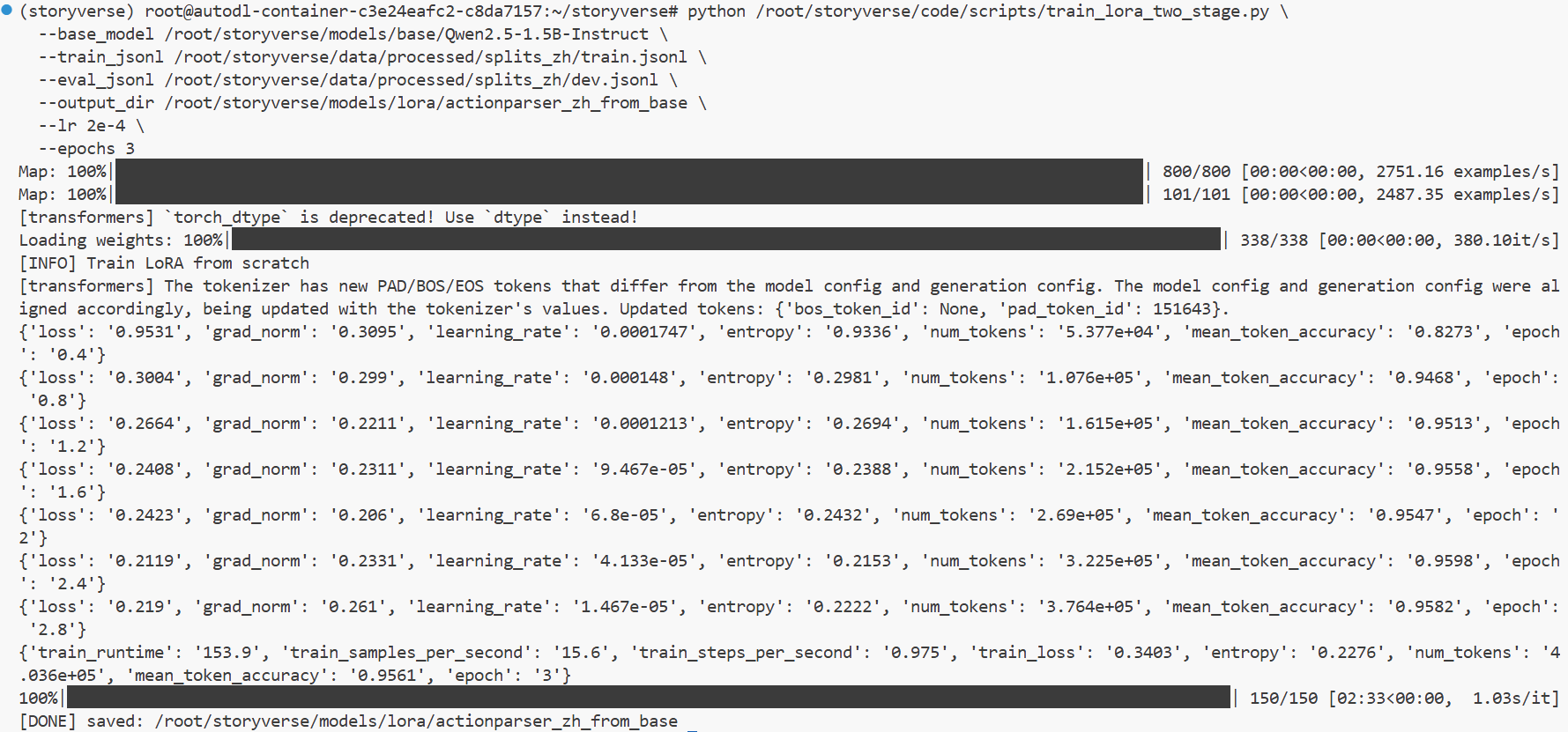
完成 base 模型评测后,我继续推进模型训练工作。本次训练不是简单地把所有数据混在一起直接微调,而是按照前期设计好的训练思路,结合 base、warmup 和中文数据集进行分阶段训练。
Warmup 阶段的主要作用,是先让模型适应 ActionParser 的输出结构和任务形式。在这一阶段,Hermes 和 SGD 数据仍然具有一定价值。Hermes 数据能够帮助模型保持指令跟随能力,使其更容易按照要求输出结构化内容;SGD 数据则更偏向意图识别和槽位抽取,可以强化“自然语言输入到结构化结果”的映射能力。虽然这两类数据和中文小说语境并不完全一致,但它们适合作为前置训练资源,帮助模型先建立基本的 JSON 输出习惯和结构化解析能力。
在 warmup 之后,我进一步使用中文小说标注数据对模型进行任务域微调。中文数据集是本项目的核心数据,因为它直接来自小说文本,覆盖了说话、移动、观察、互动、使用、等待等 StoryVerse 实际需要的动作类型。相比 Hermes 和 SGD,中文小说数据更贴近平台后续真实应用场景,能够让模型学习人物动作、角色交互、隐含对象和叙事情境中的行为边界。
这一阶段的训练过程需要同时关注数据路径、模型路径、训练参数和输出目录是否正确对应。训练前,我确认了中文数据集的 train、dev、test 划分结果,并检查了各类动作分布是否相对合理。训练过程中,我也注意区分 base 模型、warmup 权重和最终中文微调权重,避免不同阶段的模型文件互相覆盖。训练完成后,再将最终结果进行合并,形成可以直接加载推理的完整模型目录。
这一部分工作的重点不只是“把训练跑起来”,而是建立了从 base 到 warmup,再到中文微调的完整训练链路。通过这种方式,模型能力逐步从通用语言理解过渡到结构化输出,再进一步对齐到中文小说 ActionParser 任务。
三、训练结果评测:对最终模型进行统一测试
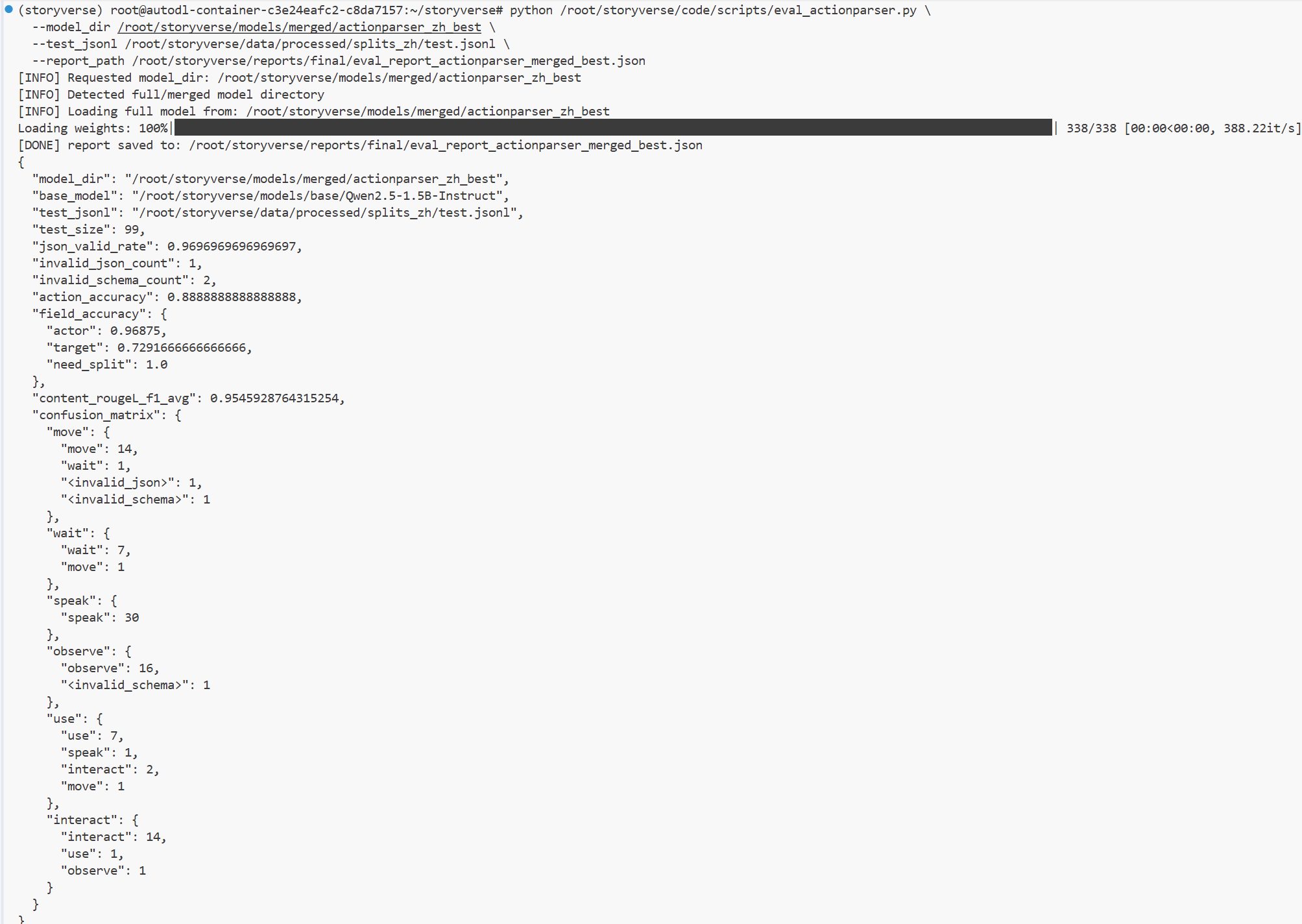
训练完成后,我对最终模型进行了正式评测。为了保证评测结果具有可比性,我仍然使用和 base 模型相同的测试集与评估脚本,并指定最终合并后的模型目录进行加载。当前确认的最终模型目录为:
/root/storyverse/models/merged/actionparser_zh_best这个目录代表经过中文任务微调并合并后的完整模型版本,可以直接用于推理和后端调用。评估脚本能够正确识别该目录为完整合并模型,并成功加载权重进行测试。最终评估报告被保存到:
/root/storyverse/reports/final/eval_report_actionparser_merged_best.json

从评估结果来看,最终模型的整体效果相比 base 阶段已经有明显提升。模型的 JSON 合法率达到 0.9697,说明大多数情况下能够稳定输出符合 ActionParser 要求的结构化 JSON。动作类型准确率达到 0.8889,说明模型已经能够比较准确地区分不同动作类别。actor 字段得分达到 0.9688,说明模型对动作执行者的识别非常稳定。target 字段得分为 0.7292,虽然已经具备一定可用性,但相比 actor 仍然存在差距。content 的 Rouge-L F1 平均值达到 0.9546,说明模型生成的动作内容摘要与人工标注结果高度接近。
这些指标说明,经过 warmup 和中文微调后,模型已经从“只能完成通用指令回答”转变为“能够较稳定执行小说动作解析任务”的模型。尤其是 JSON 合法率和动作分类准确率的提升,对后续 FastAPI 后端接入非常关键,因为后端需要稳定解析模型结果,并将其传递给世界状态更新、角色响应和剧情推进模块。
四、微调前后结果分析:模型能力提升与具体变化
对比 base 模型和最终中文微调模型,可以比较清楚地看到微调带来的变化。微调前,base 模型最大的问题是任务意识不强。它虽然能理解用户输入的大致含义,但经常不会严格按照 ActionParser schema 输出,有时会生成解释性语言,有时字段不完整,有时动作类型不在预设范围内。这类问题会导致模型即使“看起来回答了”,也无法真正进入后端系统使用。
微调后,模型在结构稳定性上明显增强。JSON 合法率接近 97%,说明前期对输出 schema 的统一、Hermes/SGD 的格式对齐,以及中文标注数据中的标准答案格式,对模型产生了有效约束。对于后端系统而言,这一点非常重要,因为结构稳定是模型服务化的前提。
在动作分类方面,微调后的模型已经能更好地区分不同动作。例如,原来 base 模型可能会把“走到门边敲了敲门”简单理解为普通叙述,而微调后的模型更可能将其解析为 move 或 interact,甚至在需要时拆分为多个子动作。这说明中文小说数据帮助模型学习到了更贴近 StoryVerse 语境的动作边界。
在字段抽取方面,actor 字段提升最明显,说明模型已经能够稳定识别动作执行者。但 target 字段仍然是当前相对薄弱的部分。原因在于小说文本中的目标对象并不总是直接出现,有时需要结合上下文推断,有时会使用代词,有时动作目标本身是环境对象而不是人物。因此,target 指标低于 actor 是符合任务难度预期的,也说明后续优化需要重点围绕目标对象识别展开。
content 指标表现较好,说明模型已经能够比较准确地概括动作内容。这一点对后续系统也很重要,因为 content 字段实际上承担了“动作语义摘要”的作用,后续角色智能体或剧情引擎会依赖它理解用户到底做了什么。
综合来看,本次微调是有效的,模型从格式、动作类型、执行者识别和内容生成等方面都表现出明显进步,但目标对象抽取和复杂多动作拆分仍然需要继续优化。
五、当前模型效果评价:已具备后端接入基础,但仍需继续优化

根据当前评测结果,我认为最终合并模型已经具备进入 FastAPI 后端联调的基础条件。它的 JSON 合法率较高,说明后端解析压力相对可控;动作准确率接近 0.89,说明其主任务能力已经比较稳定;actor 和 content 指标较高,说明模型对行为主体和动作语义的把握比较可靠。
不过,当前模型还不能认为已经完全成熟。它仍然存在几个需要继续改进的问题。首先,target 字段表现相对较弱,尤其是在目标对象省略、代词指代、环境目标和多人交互场景中容易出错。其次,部分动作类别之间仍然存在边界混淆,例如 interact 和 use、observe 和 wait 在某些场景下可能会被模型误判。再次,对于较长输入或包含多个连续动作的句子,模型虽然有 need_split 和 sub_actions 机制,但拆分稳定性仍需要进一步验证。最后,当前测试集规模有限,虽然可以反映模型基本能力,但仍需要更多跨小说、跨场景样本来检验泛化能力。
也就是说,当前模型已经从“实验可运行”走向“系统可接入”,但距离“高鲁棒性长期稳定使用”还有进一步优化空间。
六、训练模型留存:保存最终可用版本,保证后续可复现
在完成最终评测后,我对训练好的模型进行了整理和留存。当前最终模型被保存为:
/root/storyverse/models/merged/actionparser_zh_best同时,评估报告被保存为:
/root/storyverse/reports/final/eval_report_actionparser_merged_best.json这样处理的目的,是保证后续项目开发中能够明确知道“当前最优模型是哪一个”“对应的测试结果是什么”“后端应该调用哪个目录”。如果不做版本留存,后续继续训练时很容易覆盖已有结果,导致无法复现当前评测指标,也不方便和新的实验版本进行对比。
因此,这一步不仅是简单保存文件,而是为整个项目建立一个阶段性模型基线。后续无论是接入 FastAPI 后端,还是继续做数据增强和新一轮微调,都可以以这个版本作为对照。
七、下一步工作方案
在当前模型已经完成训练、评测和留存的基础上,下一步工作主要有两个方向。
第一,是将 actionparser_zh_best 接入 FastAPI 后端服务。后端接口需要加载该模型,接收用户输入文本,调用模型推理,并将输出结果解析为标准 ActionParser JSON。由于当前模型 JSON 合法率较高,已经具备接入条件,但后端仍然需要保留必要的 JSON 提取、字段校验和异常处理逻辑,防止少量非法输出影响系统稳定性。
第二,是继续优化模型薄弱点。根据当前评测结果,后续应重点补充 target 字段相关样本,尤其是目标对象省略、代词指代、环境对象交互和多人互动场景。同时,还需要进一步检查动作类别混淆案例,针对 interact/use、observe/wait 等容易混淆的类别补充更有区分度的数据。此外,对于 need_split 和 sub_actions 的多动作拆分能力,也需要单独构造测试样本进行验证。
整体来看,本次工作完成了从 base 评测、warmup 与中文微调训练,到最终模型评测、微调前后对比分析和模型留存的完整流程。它不仅证明了前期中文数据构建和两阶段训练方案是有效的,也为后续 FastAPI 后端接入提供了明确的模型版本和指标依据。StoryVerse 的 ActionParser 模块已经基本完成从数据准备到模型可用的关键跨越,下一阶段的重点将转向系统联调和针对性优化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)