【SpringBoot 3.x 第209节】Spring Batch 5.x 作业模型全解析(批任务监控与失败恢复等),一文带你吃透!

🏆本文收录于《滚雪球学SpringBoot 3.x》,专门攻坚指数提升,本年度国内最系统+最专业+最详细(永久更新)。
该专栏致力打造最硬核 SpringBoot3 从零基础到进阶系列学习内容,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…欢迎大家订阅持续学习。 如果想快速定位学习,可以看这篇【SpringBoot3教程导航帖】,你想学习的都被收集在内,快速投入学习!!两不误。
若还想学习更多,可直接订阅 《Spring Boot实战合集》,一次订阅,持续学习,后续更新内容无需重复付费,适合长期收藏与系统进阶。
演示环境说明:
- 开发工具:IDEA 2021.3
- JDK版本: JDK 17(推荐使用 JDK 17 或更高版本,因为 Spring Boot 3.x 系列要求 Java 17,Spring Boot 3.5.4 基于 Spring Framework 6.x 和 Jakarta EE 9,它们都要求至少 JDK 17。)
- Spring Boot版本:3.5.4(于25年7月24日发布)
- Maven版本:3.8.2 (或更高)
- Gradle:(如果使用 Gradle 构建工具的话):推荐使用 Gradle 7.5 或更高版本,确保与 JDK 17 兼容。
- 操作系统:Windows 11
全文目录:
- 一、为什么你需要 Spring Batch?
- 二、批处理到底适合解决什么问题?
- 三、Spring Batch 5.x 的核心模型总览
- 四、Job、Step、Chunk、Tasklet 的职责拆解
- 五、Chunk 模式:批处理最常见的执行模型
- 六、Tasklet 模式:一次性任务的利器
- 七、Spring Boot 3.x + Spring Batch 5.x 项目搭建
- 八、第一个可运行批处理案例:CSV 转数据库
- 九、进阶案例:失败重试、跳过与断点恢复
- 十、如何做批任务监控?
- 十一、与普通定时任务的区别
- 十二、真实落地设计:如何组织你的批处理工程
- 十三、常见坑与最佳实践
- 十四、再补一个 Tasklet 实战案例:清理临时文件
- 十五、Spring Batch 5.x 相比旧版本需要注意什么?
- 十六、从架构角度看 Spring Batch
- 十七、一个更贴近生产的思考:批处理任务平台化
- 十八、本文小结
- 十九、进一步扩展学习
- 二十、结语
- 🧧 学习福利 · 限时开放 🧧
- 🫵 Who am I?
一、为什么你需要 Spring Batch?
在很多初学者眼里,“批处理”听上去像是一个过时的概念:
- 我有定时任务,定时扫表不就行了吗?
- 我有消息队列,消息一条条消费不就行了吗?
- 我有普通 Java 程序,写个 for 循环批量处理不就好了?
这些做法在小规模场景里往往都能工作,但一旦你面对下面这些问题,普通写法很快就会暴露出短板:
- 数据量非常大,单次处理可能有几十万、几百万条记录。
- 任务运行时间很长,可能跨分钟、跨小时甚至跨天。
- 中途容易失败,失败后需要从上次进度继续,而不是从头再来。
- 需要精确记录每次处理了多少条、成功多少、失败多少、跳过多少。
- 需要对任务运行历史进行追踪,方便审计、运维、报警。
- 需要将“读数据、加工数据、写数据”这件事标准化。
Spring Batch 就是为这些问题而生的。它不是“定时任务框架”,而是一套批处理作业框架。它关心的是:
- 任务如何定义
- 步骤如何拆分
- 数据如何分批读取与写入
- 失败后如何恢复
- 执行过程如何追踪
这也是为什么 Spring Batch 常常出现在:
- 数据迁移
- 日终结算
- 报表生成
- 历史归档
- 文件导入导出
- ETL 作业
- 大批量状态同步
这些场景里。
二、批处理到底适合解决什么问题?
先给结论:只要你的任务具备“离线、批量、可恢复、可审计”的特征,就很适合考虑 Spring Batch。
2.1 典型适用场景
1)大批量数据导入
比如把 Excel、CSV、JSON、数据库中的旧数据导入到新系统里。通常会涉及:
- 读取外部文件
- 校验数据合法性
- 转换字段格式
- 分批写入数据库
- 记录失败行
2)大批量数据清洗
例如将历史订单数据按照新规则重新计算、去重、补字段、归档到新表。
3)跨系统同步
例如从 A 系统同步商品信息到 B 系统,并且要保证可重试、可恢复。
4)统计和报表
例如每天凌晨生成订单统计报表,并把结果存到报表库或导出成文件。
5)历史归档与清理
例如将一年前的数据迁移到历史表,然后清理主表。
2.2 不适合的场景
Spring Batch 不是银弹。下面这些场景通常不是它的最佳选择:
- 低延迟在线请求:比如用户点击按钮后要立即返回结果。
- 高频实时流处理:比如秒级、毫秒级的事件流。
- 逻辑极其简单、一次性就能完成的小脚本。
一句话概括:
在线请求更关心“快”,批处理更关心“稳”。
三、Spring Batch 5.x 的核心模型总览
Spring Batch 最核心的思想,是把一个批任务拆成几个标准角色:
- Job:整个批任务的容器
- Step:Job 中的一个执行步骤
- Chunk:Step 中常见的一种批处理提交单位
- Tasklet:Step 的另一种执行方式,适合一次性逻辑
- ItemReader / ItemProcessor / ItemWriter:Chunk 模式中的读、处理、写三件套
- JobRepository:记录作业元数据
- JobLauncher:负责启动 Job
- JobExecution / StepExecution:作业与步骤的执行记录
下面先看一个最重要的结构图。
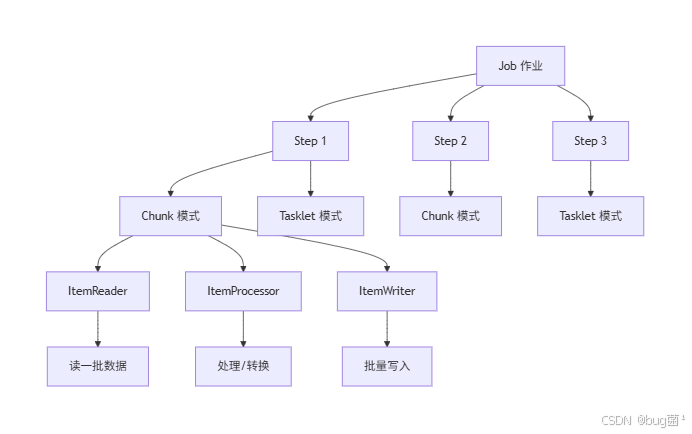
这个图背后的重点是:
- Job 不是干活的,它只是组织流程。
- Step 才是真正执行某段业务逻辑的地方。
- Chunk 是“分批处理”的模式。
- Tasklet 是“执行一次就结束”的模式。
四、Job、Step、Chunk、Tasklet 的职责拆解
这一部分是全文的核心,也是最容易混淆的地方。
4.1 Job:批处理作业的总入口
Job 可以理解为“一个完整的批任务定义”。它负责把多个 Step 串起来,定义执行顺序和流程控制。
你可以把 Job 想象成一部电影的总片名,而 Step 是每个镜头或章节。
Job 的特点:
- 一个 Job 对应一个完整业务目标
- 可以包含多个 Step
- 可以按顺序执行,也可以做条件分支
- 每次执行都会生成执行实例和执行记录
Job 本身不直接处理数据,它只是调度和组织。
4.2 Step:真正干活的步骤
Step 是 Job 中最小的业务执行单元。每一个 Step 都可以做一件明确的事情,比如:
- 读取 CSV 文件
- 校验记录
- 写入数据库
- 发送统计结果
- 清理临时文件
一个 Job 可以只有一个 Step,也可以有很多 Step。
常见设计原则是:
- 一个 Step 尽量只做一件事
- Step 与 Step 之间通过上下文或中间表传递数据
- Step 的职责越清晰,后期维护越容易
4.3 Chunk:读、处理、写的批量提交模型
Chunk 是 Spring Batch 中最经典的处理模式。
它的工作方式可以概括为:
- 读入一条数据
- 处理一条数据
- 累积到设定数量
- 一次性写入
- 提交事务
- 重复以上步骤
这里的“chunk size”就是每次提交多少条数据,比如 10、100、1000。
Chunk 的优势:
- 事务边界清晰
- 适合大批量数据
- 失败后可恢复
- 内置跳过、重试、监听能力强
Chunk 的典型三件套:
ItemReader:负责读ItemProcessor:负责处理ItemWriter:负责写
4.4 Tasklet:一次性执行逻辑
Tasklet 更像是“执行一段命令型逻辑”,例如:
- 删除临时文件
- 初始化目录
- 执行一条 SQL
- 调用外部接口
- 发一封通知邮件
Tasklet 的特点:
- 没有“读-处理-写”的固定结构
- 更适合一次性、非批量的任务
- 一般返回
RepeatStatus.FINISHED表示结束
4.5 它们之间的关系
可以用一张图来理解:
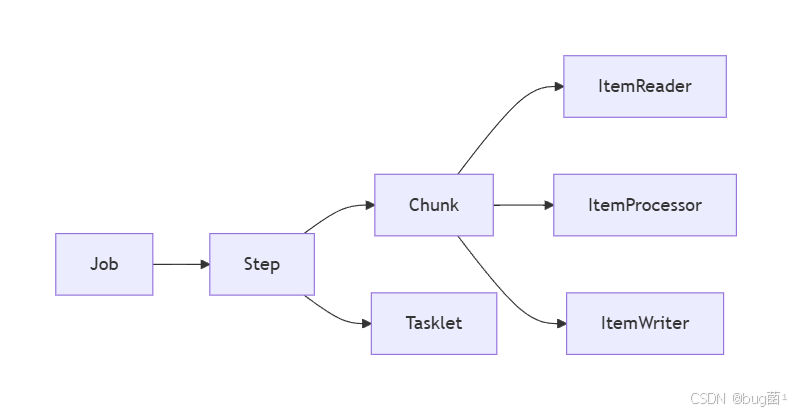
结论非常简单:
- Job 是总导演
- Step 是分镜
- Chunk 是流水线
- Tasklet 是一次性动作
五、Chunk 模式:批处理最常见的执行模型
Chunk 模式是 Spring Batch 的灵魂。
5.1 Chunk 为什么适合大数据
假设你要处理 100 万条数据,如果每条都单独提交事务,性能会很差;如果一次性加载全部数据,又容易内存爆掉。
Chunk 的解决方案是:
- 每次只处理一小批
- 处理完再统一提交
- 既控制内存,又兼顾效率
例如 chunk size = 100,那么执行过程可能是:
- 读 100 条
- 处理 100 条
- 写 100 条
- 提交事务
- 再处理下一批
这样既减少数据库交互次数,也让失败恢复更容易。
5.2 Chunk 的事务边界
这是必须搞懂的点:
- 一个 chunk 通常对应一个事务
- 事务里如果某条数据出错,整个 chunk 可能回滚
- 如果配置了跳过、重试策略,框架可以更智能地处理异常
所以 Chunk 不是简单的“每 100 条提交一次”,它还承担了事务控制。
5.3 Chunk 的执行流程
相关示意图绘制如下,仅供参考:
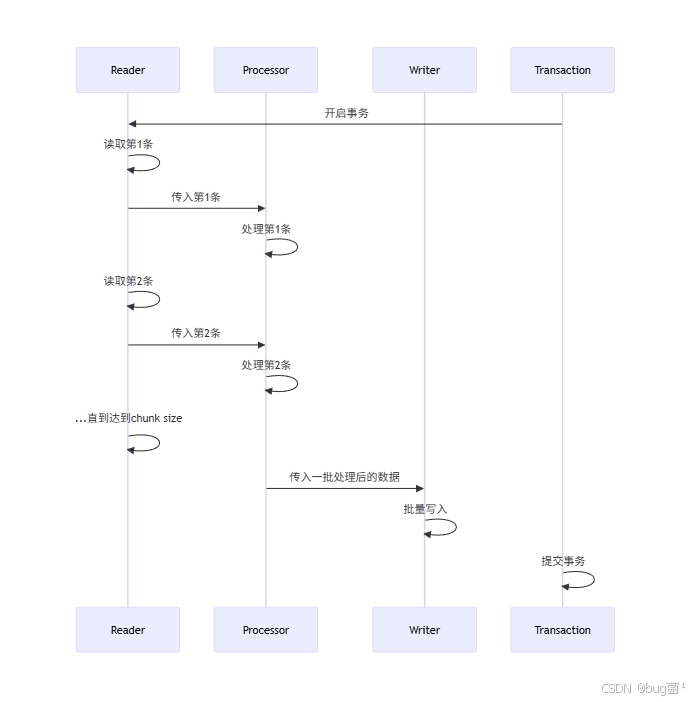
这个过程体现了一个关键思想:
Spring Batch 的 Chunk 本质上是在“批量处理”和“事务一致性”之间找平衡。
六、Tasklet 模式:一次性任务的利器
Tasklet 不是 Chunk 的替代品,而是补充品。
6.1 什么时候用 Tasklet
适合以下场景:
- 只执行一条 SQL
- 只创建一个文件
- 只做一个清理动作
- 只发一次消息
- 只写一个日志标记
比如,导入任务前要先清理临时目录,或者数据处理完成后要给运维发通知,这类动作很适合 Tasklet。
6.2 Tasklet 的核心接口
Spring Batch 的 Tasklet 本质上是一个函数式执行器。你通常会实现类似下面的逻辑:
- 执行任务
- 返回
RepeatStatus.FINISHED
如果返回继续状态,就可能被重复调用;如果返回结束状态,就退出当前 Step。
6.3 Tasklet 适合“命令式”任务
和 Chunk 相比,Tasklet 不强调“输入一批,处理一批,输出一批”,而强调“做完一件事就结束”。
所以不要把所有逻辑都塞进 Chunk。很多系统初期会犯一个错误:
明明只是一个目录清理任务,硬要搞成 Reader/Processor/Writer 三件套。
这样只会让代码更难维护。
七、Spring Boot 3.x + Spring Batch 5.x 项目搭建
下面进入实战部分。为了让代码更有参考价值,本章使用 Spring Boot 3.x + Spring Batch 5.x 的方式来搭建一个最小可运行项目。
7.1 依赖配置
下面以 Maven 为例。
<dependencies>
<!-- Spring Web,可选:如果你希望通过接口触发 Job -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Batch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<!-- JDBC -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- H2 数据库,方便本地演示 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok,可选 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
7.2 application.yml
spring:
datasource:
url: jdbc:h2:mem:batchdb;MODE=MYSQL;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=false
driver-class-name: org.h2.Driver
username: sa
password:
h2:
console:
enabled: true
batch:
jdbc:
initialize-schema: always
job:
enabled: false
logging:
level:
org.springframework.batch: info
com.example.batch: debug
这里有两个重点:
initialize-schema: always用于自动初始化 Spring Batch 元数据表。job.enabled: false表示应用启动时不自动执行 Job,方便我们手动触发。
7.3 数据表准备
我们准备一个目标表用于保存导入结果。
CREATE TABLE student_target (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
student_no VARCHAR(32),
student_name VARCHAR(64),
age INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
7.4 项目结构建议
建议把批处理项目按下面方式组织:
com.example.batch
├── BatchApplication.java
├── config
│ ├── BatchJobConfig.java
│ └── BatchCommonConfig.java
├── model
│ └── StudentRecord.java
├── reader
│ └── StudentItemReader.java
├── processor
│ └── StudentItemProcessor.java
├── writer
│ └── StudentItemWriter.java
├── listener
│ └── BatchJobListener.java
└── controller
└── JobTriggerController.java
这样做的好处是:职责清晰,后面扩展多个 Job 也不会乱。
八、第一个可运行批处理案例:CSV 转数据库
这一章我们做一个真正能跑的例子:把 CSV 文件中的学生数据导入数据库。
这个案例会同时展示:
- Job
- Step
- Chunk
- ItemReader
- ItemProcessor
- ItemWriter
- 监听器
- 手动触发 Job
8.1 CSV 文件样例
放在 src/main/resources/input/students.csv:
studentNo,studentName,age
S001,张三,18
S002,李四,20
S003,王五,19
S004,赵六,21
8.2 数据模型
package com.example.batch.model;
/**
* 学生记录模型
*/
public class StudentRecord {
private String studentNo;
private String studentName;
private Integer age;
public String getStudentNo() {
return studentNo;
}
public void setStudentNo(String studentNo) {
this.studentNo = studentNo;
}
public String getStudentName() {
return studentName;
}
public void setStudentName(String studentName) {
this.studentName = studentName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
8.3 批处理配置类
package com.example.batch.config;
import com.example.batch.model.StudentRecord;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
@Configuration
public class BatchJobConfig {
/**
* 读取 CSV 文件
*/
@Bean
public FlatFileItemReader<StudentRecord> studentItemReader() {
return new FlatFileItemReaderBuilder<StudentRecord>()
.name("studentItemReader")
.resource(new ClassPathResource("input/students.csv"))
.linesToSkip(1)
.delimited()
.names("studentNo", "studentName", "age")
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(StudentRecord.class);
}})
.build();
}
/**
* 数据处理:这里做简单校验和转换
*/
@Bean
public ItemProcessor<StudentRecord, StudentRecord> studentItemProcessor() {
return item -> {
// 中文注释:对每条记录进行基础清洗
if (item.getStudentName() == null || item.getStudentName().isBlank()) {
return null; // 返回 null 表示过滤掉该条记录
}
item.setStudentName(item.getStudentName().trim());
return item;
};
}
/**
* 批量写入数据库
*/
@Bean
public JdbcBatchItemWriter<StudentRecord> studentItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<StudentRecord>()
.dataSource(dataSource)
.sql("INSERT INTO student_target(student_no, student_name, age) VALUES(:studentNo, :studentName, :age)")
.beanMapped()
.build();
}
/**
* Step:Chunk 模式
*/
@Bean
public Step importStudentStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemReader<StudentRecord> studentItemReader,
ItemProcessor<StudentRecord, StudentRecord> studentItemProcessor,
ItemWriter<StudentRecord> studentItemWriter) {
return new StepBuilder("importStudentStep", jobRepository)
.<StudentRecord, StudentRecord>chunk(2, transactionManager)
.reader(studentItemReader)
.processor(studentItemProcessor)
.writer(studentItemWriter)
.build();
}
/**
* Job:把 Step 串起来
*/
@Bean
public Job importStudentJob(JobRepository jobRepository,
Step importStudentStep,
BatchJobListener batchJobListener) {
return new JobBuilder("importStudentJob", jobRepository)
.listener(batchJobListener)
.start(importStudentStep)
.build();
}
}
代码解析
这里最值得注意的点有三个。
第一,chunk(2, transactionManager)
表示每两条数据提交一次事务。真实项目里这个值需要结合:
- 单条数据大小
- 数据库压力
- 内存占用
- 失败恢复成本
综合评估后决定。
第二,Processor 返回 null
Spring Batch 允许 Processor 返回 null,表示过滤当前数据,不写入结果。这是一个很实用的特性,常用于:
- 过滤非法数据
- 过滤空记录
- 过滤重复记录
第三,JobRepository 和 transactionManager
Spring Batch 5.x 明确强调 Job 元数据管理,所以 JobRepository、PlatformTransactionManager 等配置非常关键。它们决定了作业执行记录、事务边界和恢复能力。
8.4 监听器
package com.example.batch.listener;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.stereotype.Component;
/**
* 作业监听器:用于记录作业开始和结束状态
*/
@Component
public class BatchJobListener extends JobExecutionListenerSupport {
@Override
public void beforeJob(JobExecution jobExecution) {
// 中文注释:作业执行前打印日志
System.out.println("批处理作业开始执行,jobName=" + jobExecution.getJobInstance().getJobName());
}
@Override
public void afterJob(JobExecution jobExecution) {
// 中文注释:作业执行后打印状态
System.out.println("批处理作业执行结束,status=" + jobExecution.getStatus());
}
}
8.5 手动触发 Job 的接口
package com.example.batch.controller;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDateTime;
@RestController
@RequestMapping("/batch")
public class JobTriggerController {
private final JobLauncher jobLauncher;
private final Job importStudentJob;
public JobTriggerController(JobLauncher jobLauncher, Job importStudentJob) {
this.jobLauncher = jobLauncher;
this.importStudentJob = importStudentJob;
}
@PostMapping("/import-students")
public String runImportJob() throws Exception {
// 中文注释:增加唯一参数,避免同一 JobParameters 重复执行被判定为同一次实例
JobParameters jobParameters = new JobParametersBuilder()
.addString("requestId", LocalDateTime.now().toString())
.toJobParameters();
jobLauncher.run(importStudentJob, jobParameters);
return "job started";
}
}
代码解析
这里的 requestId 很重要。
Spring Batch 会用 JobParameters 来区分一次作业实例。如果参数完全相同,框架可能认为这次执行和上次是同一个实例,从而出现“不能重复运行”的问题。
所以手动触发 Job 时,通常会加一个唯一参数:
- 时间戳
- UUID
- 请求流水号
8.6 启动类
package com.example.batch;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BatchApplication {
public static void main(String[] args) {
SpringApplication.run(BatchApplication.class, args);
}
}
8.7 这个案例的执行逻辑
当你调用 /batch/import-students 时:
- Controller 触发 JobLauncher
- JobLauncher 启动 importStudentJob
- Job 进入 importStudentStep
- Reader 读 CSV
- Processor 做清洗
- Writer 批量写入数据库
- 监听器记录开始和结束
这就是一个完整的 Spring Batch 批处理链路。
九、进阶案例:失败重试、跳过与断点恢复
真正的批处理系统,最有价值的不是“能跑”,而是“跑崩了也能恢复”。
Spring Batch 在这方面非常强。
9.1 为什么断点恢复重要
假设你正在处理 100 万条数据,已经处理到第 60 万条时,机器宕机了。
如果没有断点恢复,你只能从头再来。
如果有断点恢复,你只需要从第 60 万条之后继续。
这对大任务非常重要,因为:
- 节省时间
- 节省资源
- 降低重复写入风险
- 避免重新扫全量数据
9.2 Spring Batch 如何支持恢复
Spring Batch 会把作业执行信息持久化到元数据表中,例如:
- JobInstance
- JobExecution
- StepExecution
- ExecutionContext
这些表记录了作业运行到哪里、读到哪里、成功多少、失败多少。
只要你的 Reader 支持状态保存,作业就可以在失败后从断点继续。
9.3 使用 ExecutionContext 保存状态
下面给一个简单思路:记录当前处理到哪一行。
package com.example.batch.reader;
import com.example.batch.model.StudentRecord;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ParseException;
import org.springframework.batch.item.UnexpectedInputException;
import org.springframework.core.io.ClassPathResource;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
/**
* 一个示例性的可恢复 Reader,用于演示断点恢复思想
*/
public class StatefulStudentReader implements ItemStreamReader<StudentRecord> {
private BufferedReader bufferedReader;
private int lineNumber = 0;
private int currentIndex = 0;
@Override
public StudentRecord read() throws Exception {
String line;
while ((line = bufferedReader.readLine()) != null) {
currentIndex++;
// 中文注释:跳过表头
if (currentIndex == 1) {
continue;
}
lineNumber = currentIndex;
String[] parts = line.split(",");
if (parts.length < 3) {
// 中文注释:数据格式不正确,直接抛异常交给框架处理
throw new IllegalArgumentException("CSV 数据格式错误,行号=" + currentIndex);
}
StudentRecord record = new StudentRecord();
record.setStudentNo(parts[0]);
record.setStudentName(parts[1]);
record.setAge(Integer.parseInt(parts[2]));
return record;
}
return null;
}
@Override
public void open(ExecutionContext executionContext) throws Exception {
// 中文注释:打开文件时恢复上次进度
InputStream inputStream = new ClassPathResource("input/students.csv").getInputStream();
bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
int savedLine = executionContext.containsKey("lineNumber") ? executionContext.getInt("lineNumber") : 0;
for (int i = 0; i < savedLine; i++) {
bufferedReader.readLine();
currentIndex++;
}
}
@Override
public void update(ExecutionContext executionContext) throws Exception {
// 中文注释:保存当前进度,供下次恢复使用
executionContext.putInt("lineNumber", lineNumber);
}
@Override
public void close() throws Exception {
if (bufferedReader != null) {
bufferedReader.close();
}
}
}
代码解析
这个 Reader 的核心价值,不在于它是否“最优雅”,而在于它展示了 Spring Batch 断点恢复的思想:
open:恢复历史进度update:保存当前进度close:释放资源
这是 Batch 任务与普通脚本最大的不同之一。
9.4 Retry:重试机制
有些错误是临时性的,例如:
- 网络抖动
- 数据库短暂不可用
- 外部接口超时
这种情况没必要直接失败,可以先重试几次。
Spring Batch 支持在 Step 里配置重试:
@Bean
public Step importStudentStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemReader<StudentRecord> studentItemReader,
ItemProcessor<StudentRecord, StudentRecord> studentItemProcessor,
ItemWriter<StudentRecord> studentItemWriter) {
return new StepBuilder("importStudentStep", jobRepository)
.<StudentRecord, StudentRecord>chunk(2, transactionManager)
.reader(studentItemReader)
.processor(studentItemProcessor)
.writer(studentItemWriter)
.faultTolerant()
.retryLimit(3)
.retry(RuntimeException.class)
.readerIsTransactionalQueue()
.build();
}
这里的含义是:
- 遇到
RuntimeException时重试 - 最多重试 3 次
9.5 Skip:跳过坏数据
有些数据坏了,但整个任务不能因为少量坏数据而失败。比如 10 万条里只有 3 条格式不合法。
这时候可以配置跳过策略。
@Bean
public Step importStudentStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemReader<StudentRecord> studentItemReader,
ItemProcessor<StudentRecord, StudentRecord> studentItemProcessor,
ItemWriter<StudentRecord> studentItemWriter) {
return new StepBuilder("importStudentStep", jobRepository)
.<StudentRecord, StudentRecord>chunk(2, transactionManager)
.reader(studentItemReader)
.processor(studentItemProcessor)
.writer(studentItemWriter)
.faultTolerant()
.skip(IllegalArgumentException.class)
.skipLimit(10)
.build();
}
这表示:
- 遇到
IllegalArgumentException可以跳过 - 最多跳过 10 次
为什么 Skip 很重要
现实中,数据质量往往没那么完美。批处理系统不是追求“零错误数据”,而是追求:
- 能识别错误
- 能隔离错误
- 能继续处理正确数据
- 能把错误记录留下来供人工修复
十、如何做批任务监控?
批任务没有监控,就像没有仪表盘的飞机。
10.1 监控什么
通常需要关注:
- Job 是否启动
- Job 是否成功
- 运行了多久
- 处理了多少条
- 成功多少条
- 失败多少条
- 哪个 Step 失败
- 错误原因是什么
- 是否发生重试
- 是否发生跳过
10.2 Spring Batch 自带的元数据表
Spring Batch 会把执行信息写入数据库,这些元数据表非常关键。它们可以帮助你:
- 查询历史执行记录
- 分析失败原因
- 恢复上次执行
- 监控作业耗时
常见表包括:
BATCH_JOB_INSTANCEBATCH_JOB_EXECUTIONBATCH_STEP_EXECUTIONBATCH_JOB_EXECUTION_PARAMSBATCH_STEP_EXECUTION_CONTEXTBATCH_JOB_EXECUTION_CONTEXT
10.3 如何读取 Job 执行结果
你可以通过 JobExecution 来查看执行状态:
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
if (jobExecution.getStatus().isUnsuccessful()) {
// 中文注释:任务失败时做报警或补偿处理
System.out.println("任务失败,需要通知运维人员");
}
10.4 结合日志与告警
最实用的监控方案通常是三层:
- 日志:记录每个 Step 的开始结束、异常信息
- 数据库元数据:记录任务运行轨迹
- 告警系统:失败后通知短信、邮件、企业微信、钉钉
10.5 常见监控建议
- 给 Job 名称统一命名规则
- 给每个 Step 打唯一标识
- 对大任务定期打印进度日志
- 任务失败时记录输入参数
- 任务成功时记录耗时和处理量
十一、与普通定时任务的区别
很多人第一次接触 Spring Batch 时,会问一个问题:
我已经有
@Scheduled了,为什么还要 Spring Batch?
这个问题非常关键。
11.1 定时任务擅长什么?
普通定时任务适合:
- 固定时间执行
- 逻辑简单
- 无需复杂恢复
- 不需要复杂的执行历史
比如:
- 每天凌晨同步一次配置
- 每隔 5 分钟刷新缓存
- 每小时统计一次在线人数
11.2 Spring Batch 擅长什么?
Spring Batch 适合:
- 数据量大
- 逻辑复杂
- 需要分步骤
- 需要事务控制
- 需要重试和跳过
- 需要失败恢复
- 需要审计和监控
11.3 对比表
| 维度 | 普通定时任务 | Spring Batch |
|---|---|---|
| 核心目标 | 定时触发 | 批量可靠处理 |
| 数据规模 | 小到中等 | 中到超大 |
| 事务控制 | 手动处理 | 框架支持 |
| 失败恢复 | 较弱 | 很强 |
| 监控审计 | 通常自己实现 | 内置元数据 |
| 处理模型 | 逻辑自由 | 标准化 Job/Step |
| 适合场景 | 简单定时动作 | ETL、导入导出、归档、结算 |
11.4 不是谁替代谁
正确理解是:
@Scheduled是“什么时候执行”的问题- Spring Batch 是“如何可靠执行”的问题
这两个维度并不冲突,很多生产系统会把二者结合起来:
@Scheduled负责定时触发 Job- Spring Batch 负责真正执行批任务
十二、真实落地设计:如何组织你的批处理工程
做批处理项目,最怕两个问题:
- 所有逻辑堆在一个类里
- 一个 Job 配置越来越大,后面没人敢改
下面给出一些工程化建议。
12.1 一个 Job 对应一个清晰业务目标
例如:
importStudentJob:导入学生数据archiveOrderJob:归档订单数据generateDailyReportJob:生成日报
不要把多个完全不同的业务塞进一个 Job。
12.2 Step 颗粒度要合理
Step 不宜太大,也不宜太碎。建议遵循“一个清晰动作一个 Step”原则:
- 读取文件
- 校验数据
- 入库
- 生成结果文件
- 清理临时资源
12.3 Reader / Processor / Writer 分层
建议严格分离:
- Reader 只负责读
- Processor 只负责处理
- Writer 只负责写
不要在 Reader 里做复杂校验,也不要在 Writer 里拼大量业务规则。
12.4 统一错误输出
批任务中的错误不要只靠抛异常。更好的做法是:
- 记录失败数据行
- 记录失败原因
- 记录任务参数
- 记录失败时间
这样后续排查会轻松很多。
12.5 批任务要支持幂等
幂等是批任务非常重要的概念。意思是:
同一个任务重复执行多次,结果应该保持一致,或者至少不会产生不可控副作用。
实现幂等的常见手段:
- 使用唯一业务键
- 先查后写
- Upsert
- 去重表
- 任务批次号
十三、常见坑与最佳实践
13.1 chunk 太大不一定更快
很多人会觉得 chunk size 越大越好,其实不对。
chunk 太大可能导致:
- 内存压力变高
- 事务时间过长
- 回滚成本更高
- 错误定位更难
通常要根据实际场景压测。
13.2 不要忽略 JobParameters
重复启动同一个 Job 时,JobParameters 非常重要。没有唯一参数,你可能会遇到“作业已存在”之类的问题。
13.3 不要在 Processor 里做重 IO
Processor 适合做轻量转换和校验,不适合频繁访问远程接口。否则性能会明显下降。
13.4 Writer 要尽量批量
写数据库时,应该优先使用批量写入,而不是一条一条执行。
13.5 不要忽略失败补偿
当任务失败时,应该明确:
- 已经写入的数据是否需要回滚
- 是否允许重跑
- 重跑前是否要清理中间状态
- 失败记录如何人工修复
十四、再补一个 Tasklet 实战案例:清理临时文件
为了让你对 Tasklet 有更直观的理解,这里再做一个简单案例:删除临时目录下的文件。
14.1 Tasklet 实现
package com.example.batch.config;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
import java.io.File;
@Configuration
public class TempCleanupJobConfig {
@Bean
public Step cleanupTempStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("cleanupTempStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
// 中文注释:这里演示删除临时目录文件
File tempDir = new File("./temp");
if (tempDir.exists() && tempDir.isDirectory()) {
File[] files = tempDir.listFiles();
if (files != null) {
for (File file : files) {
file.delete();
}
}
}
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
@Bean
public org.springframework.batch.core.Job cleanupTempJob(JobRepository jobRepository,
Step cleanupTempStep) {
return new JobBuilder("cleanupTempJob", jobRepository)
.start(cleanupTempStep)
.build();
}
}
14.2 为什么这个适合 Tasklet?
因为它不是“批量读写数据”,只是一个一次性动作:
- 检查目录
- 删除文件
- 结束
这就是 Tasklet 的用武之地。
十五、Spring Batch 5.x 相比旧版本需要注意什么?
在 Spring Boot 3.x 时代,Spring Batch 5.x 有几个明显特点:
- 与 Jakarta EE 体系兼容
- 对 Spring 6 / Boot 3 更友好
- API 和配置方式更现代化
- 更强调显式的 JobRepository、TransactionManager 配置
对于老项目迁移而言,最重要的不是“语法是不是完全一样”,而是要理解:
- Spring Batch 的元数据管理更重要了
- 事务边界更清晰了
- 组件职责更明确了
这意味着你在设计批任务时,最好从一开始就按“Job / Step / Chunk / Tasklet”的标准模型来组织,而不是写成一个巨型业务方法。
十六、从架构角度看 Spring Batch
如果把一个批任务系统看成一套架构,通常可以分成四层:
相关示意图绘制如下,仅供参考:
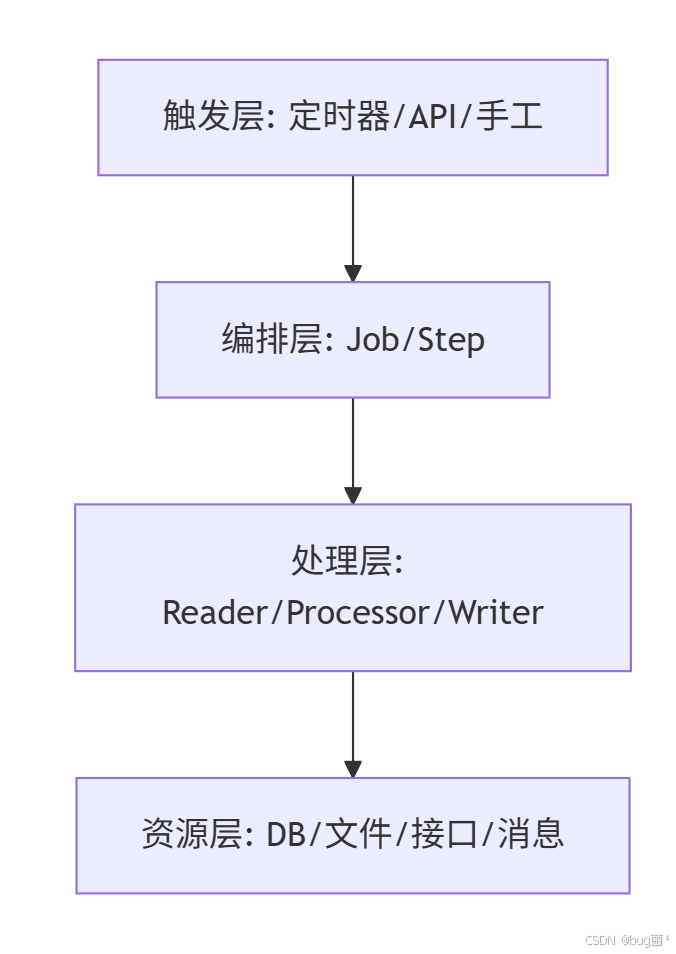
16.1 触发层
负责启动任务,可以是:
- REST API
@Scheduled- 消息触发
- 命令行启动
16.2 编排层
负责任务流程控制:
- 先做什么
- 后做什么
- 失败如何处理
- 是否并行
- 是否条件分支
16.3 处理层
负责实际业务逻辑:
- 读取
- 校验
- 转换
- 写入
16.4 资源层
真正的输入输出来源:
- 数据库
- 文件
- 第三方 API
- 对象存储
- 消息队列
这种分层思路,会让你的批处理系统更可维护,也更容易横向扩展。
十七、一个更贴近生产的思考:批处理任务平台化
当你的批处理任务逐渐增多,你会发现一个现实问题:
不是“能不能写一个 Job”,而是“能不能管理几十个 Job”。
这时候就会出现批任务平台化的需求:
- 统一触发入口
- 统一参数校验
- 统一日志与监控
- 统一重试与告警
- 统一失败恢复
- 统一权限控制
Spring Batch 本身更偏框架层,平台层通常还需要你自己做一些封装:
- Job 注册中心
- 任务配置中心
- 运行历史查询页面
- 手工重跑按钮
- 失败记录导出
如果你的系统已经进入这个阶段,Spring Batch 往往会成为非常合适的底座。
十八、本文小结
到这里,你应该已经对 Spring Batch 5.x 的作业模型有了比较完整的认识。
我们从最基础的概念讲起,逐步串起了:
- Job 是什么
- Step 是什么
- Chunk 和 Tasklet 的区别
- 批处理适合解决什么问题
- 与普通定时任务的差别
- 如何做失败恢复
- 如何做监控
- 如何写出可运行的案例代码
最重要的是,你应该形成这样一个思维:
Spring Batch 不是“把一段代码批量执行”这么简单,而是一套围绕“可靠批处理”而设计的完整模型。
当你真正理解这一点后,再去写导入导出、归档清理、报表生成、数据同步这类任务时,思路会清晰很多。
十九、进一步扩展学习
如果你要继续精进学习,接下来可以顺着这些方向继续补充拓展:
- 多 Step Job 的条件流转
- JobExecutionDecider 的使用
- 分区处理(Partitioning)
- 并行 Step / 并发执行
- Job 参数校验器
- 自定义 Listener
- 远程分片 / 分布式批处理
- 批任务中的事务传播策略
- 批处理与 Quartz 的组合
- 批处理结果落库与可视化看板
这些内容相关知识点,你一旦补齐,本期内容将会把你从“入门级”成长为“可用于实战”的入门开发者。
二十、结语
Spring Batch 的价值,不只在于“能跑批任务”,更在于它把批处理从“经验活”变成了“工程化能力”。
当你开始重视:
- 流程拆分
- 事务边界
- 失败恢复
- 任务审计
- 可观测性
你就已经从“写脚本的人”,迈向“设计批处理系统的人”了。
…
ok,同学们,本节课就上到这儿,下课~
🧧 学习福利 · 限时开放 🧧
当然,无论你是计算机专业在读学生,还是对编程充满兴趣的入门者,都强烈建议系统学习SpringBoot全体系专栏:👉 「滚雪球学 Spring Boot」;涵盖SpringBoot所有教学内容。
该专栏以“循序渐进 + 实战驱动”为核心理念,从基础到进阶到就业到架构师逐层展开,帮助你快速建立完整的 Spring Boot 技术体系,带你玩转SpringBoot框架。
📌 学习承诺:
通过该专栏,你将能够:
- 快速掌握 Spring Boot 核心开发能力
- 构建完整的后端项目认知体系
- 实现从“入门”到“独立开发”的跃迁
就像“滚雪球”一样,知识不断积累、能力持续放大,实现指数级成长 🚀
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注技术号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G PDF编程电子书、简历模板、技术文章Markdown文档等海量资料。
ps:本文涉及所有源代码,均已上传至Gitee开源,供同学们直接对照学习 Gitee传送门,同时,原创开源不易,欢迎给个star🌟,想体验下被🌟的感jio,非常感谢❗
🫵 Who am I?
我是 bug菌,一名深耕 Java 后端领域数十年的一线研发老兵,曾担任独角兽企业后端技术经理、研发架构师等职位,长期专注于 Java 后端、分布式架构、微服务治理、高并发系统、工程效能与研发管理等方向。
目前活跃于多个主流技术社区,包括:
CSDN|稀土掘金|InfoQ|51CTO|华为云开发者社区|阿里云开发者社区|腾讯云开发者社区|开源中国|博客园|墨天轮 等平台。
曾获得:
- CSDN 博客之星 Top30
- 华为云多年度十佳博主 & 卓越贡献奖
- 掘金多年度人气作者 Top40
- CSDN、掘金、InfoQ、51CTO 等平台签约作者 / 优质作者
截至目前,全网技术内容累计影响读者众多,全网粉丝已超过 30w+。
如果你也关注 Java 后端、架构设计、技术成长、职场进阶与研发管理,欢迎关注我的技术内容合集入口:👉 点击查看 👈️
硬核技术号 「猿圈奇妙屋」 期待你的加入。
这里不仅分享技术干货,也记录一线研发人的成长、踩坑、思考与进阶路径。
愿我们一起打怪升级,在技术路上持续进阶。

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)