从零开始手搓 LeNet:用 PyTorch 搭建你的第一个卷积神经网络
一、前言:为什么先从 LeNet 开始?
最近在入门深度学习,从最简单的基础开始了解学习,这里是我学习的第一个卷积神经网络,是一个很好的教学级的Demo,总结一下学习流程。
如果你刚开始学深度学习,面对满屏的 ResNet、Transformer、Diffusion Model,大概率会有点懵。这些模型确实很强,但它们的复杂度也足以劝退很多新手。
我的建议是,从基础开始学习,先回到源头,从 LeNet 开始。这是 Yann LeCun 在 1998 年提出的卷积神经网络架构,虽然快三十年了,但它把 CNN 的核心思想讲得一清二楚。理解了 LeNet,再看后面的模型,你会有一种「原来都是在这个基础上搭积木」的感觉。
这篇文章,介绍从0开始,一行一行把 LeNet 搭起来,并且跑通训练流程。
特别注意
本文假设你已经装好了 PyTorch 和 torchvision。如果还没装,建议先跑通官方的安装命令,确保import torch不会报错。
二、LeNet 的架构概览
在写代码之前,我们先搞清楚 LeNet 长什么样。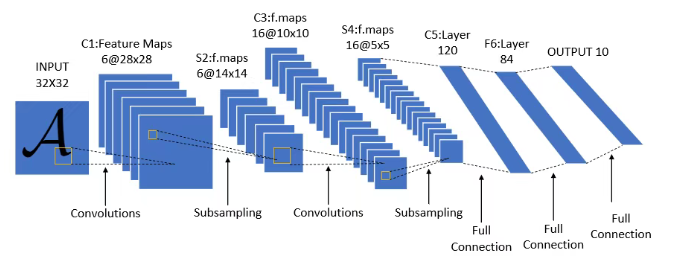
LeNet 的整体结构可以分成两大块:
-
1. 卷积层块(conv):负责从图片里提取特征
-
2. 全连接层块(fc):负责根据特征做分类判断
整个数据流是这样的:
输入图片 (1x28x28)
↓
卷积层 1 (1→6 通道, 5x5 核) + Sigmoid
↓
池化层 1 (2x2 MaxPool)
↓
卷积层 2 (6→16 通道, 5x5 核) + Sigmoid
↓
池化层 2 (2x2 MaxPool)
↓
拉平 (16x4x4 = 256 维)
↓
全连接层 1 (256→120) + Sigmoid
↓
全连接层 2 (120→84) + Sigmoid
↓
全连接层 3 (84→10) → 输出 10 个类别的分数你可以把前面的卷积层块理解成「眼睛」,它负责看图、找规律。后面的全连接层块理解成「大脑」,它负责根据看到的规律做判断。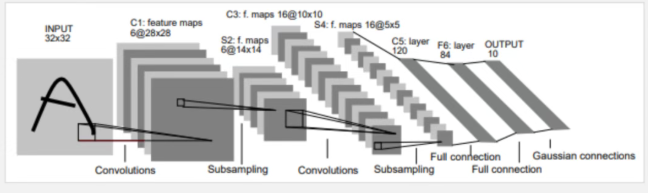
三、环境准备
3.1 确认 PyTorch 环境
我们先确认一下环境是否正常。打开你的 Python 环境,输入:
import torch
print(torch.__version__)
print(torch.cuda.is_available())如果第二行输出 True,说明GPU 可以用。如果输出 False,也没关系,CPU 也能跑,只是慢一点,这里用的Fashion-MNIST数据集很小。
常见错误
有些同学装的是 CPU 版本的 PyTorch,跑大模型的时候会特别慢。如果你确定自己有 NVIDIA 显卡,但cuda.is_available()返回 False,建议去 PyTorch 官网重新安装对应 CUDA 版本的包。
3.2 导入必要的库
我们把需要的库一次性导入:
import time
import sys
import torch
from torch import nn, optim
import torchvision
from torchvision import transforms这里 torchvision 用来加载数据集,transforms 用来预处理图片。
四、搭建 LeNet 模型
4.1 定义模型类
我们用一个类来封装整个 LeNet:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
)
self.fc = nn.Sequential(
nn.Linear(16 * 4 * 4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output我们来逐行拆解。
4.1.1 卷积层块
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # 第一层卷积
nn.Sigmoid(), # 激活函数
nn.MaxPool2d(2, 2), # 池化
nn.Conv2d(6, 16, 5), # 第二层卷积
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
)-
•
nn.Conv2d(1, 6, 5):输入 1 个通道(灰度图),输出 6 个通道,卷积核大小 5x5。 -
•
nn.Sigmoid():激活函数,把输出压缩到 0~1 之间。 -
•
nn.MaxPool2d(2, 2):2x2 的最大池化,步幅也是 2,特征图尺寸减半。
这里有个尺寸变化的细节,我们后面会详细算。
4.1.2 全连接层块
self.fc = nn.Sequential(
nn.Linear(16 * 4 * 4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)-
• 第一层
Linear的输入维度是16 * 4 * 4 = 256,这是卷积层输出的特征图拉平后的长度。 -
• 中间经过 120 和 84 维的隐藏层,最后输出 10 维,对应 10 个类别。
特别注意
最后一个Linear后面没有加激活函数。这是因为我们后面会用CrossEntropyLoss,它内部已经包含了 Softmax 操作。如果你在这里加了 Sigmoid 或者 Softmax,反而会出问题。
4.1.3 前向传播
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return outputfeature.view(img.shape[0], -1) 这一步很关键。卷积层的输出是一个四维张量 (batch_size, 16, 4, 4),但全连接层需要二维输入 (batch_size, features)。view 的作用就是把后面三维拉平成一维,-1 表示让 PyTorch 自动计算这个维度的大小。
4.2 验证模型结构
定义完之后,我们实例化一下,打印看看结构:
net = LeNet()
print(net)你应该能看到类似这样的输出:
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=10, bias=True)
)
)如果输出跟上面差不多,说明模型定义没问题。
五、数据加载
5.1 加载 Fashion-MNIST 数据集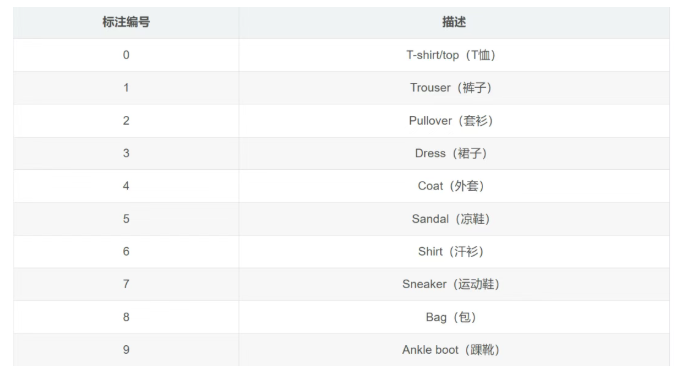

我们用一个函数来封装数据加载:
def load_data_fashion_mnist(batch_size=256):
mnist_train = torchvision.datasets.FashionMNIST(
root='~/disks/datasets/FashionMNIST',
train=True,
download=True,
transform=transforms.ToTensor()
)
mnist_test = torchvision.datasets.FashionMNIST(
root='~/disks/Datasets/FashionMNIST',
train=False,
download=True,
transform=transforms.ToTensor()
)
if sys.platform.startswith('win'):
num_workers = 0
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(
mnist_train,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
test_iter = torch.utils.data.DataLoader(
mnist_test,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers
)
return train_iter, test_iter
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)这里有几个要点:
-
•
transforms.ToTensor():把图片从 PIL Image 转成 PyTorch 的 Tensor,并且把像素值从 0255 缩放到 01。 -
•
shuffle=True:训练集需要打乱顺序,防止模型记住数据的顺序。 -
•
num_workers:Windows 下必须设为 0,不然会报错。Linux 和 macOS 可以设成 4 或更高,加快数据加载。
常见错误
Windows 用户如果num_workers > 0,大概率会遇到BrokenPipeError或者多进程相关的报错。这个坑 PyTorch 社区讨论过很多次,目前最稳的方案就是 Windows 下设为 0。
5.2 数据集简介
Fashion-MNIST 一个经典的数据集包含 10 个类别的服装图片:
|
标签 |
类别 |
|---|---|
|
0 |
T恤/上衣 |
|
1 |
裤子 |
|
2 |
套头衫 |
|
3 |
连衣裙 |
|
4 |
外套 |
|
5 |
凉鞋 |
|
6 |
衬衫 |
|
7 |
运动鞋 |
|
8 |
包 |
|
9 |
短靴 |
每张图都是 28x28 的灰度图,跟 MNIST 手写数字数据集一样的大小,但内容更复杂,更适合用来测试模型。
六、训练与评估
6.1 评估函数
我们先写一个评估准确率的函数:
def evaluate_accuracy(data_iter, net,
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval()
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
n += y.shape[0]
return acc_sum / n关键点:
-
•
torch.no_grad():评估阶段不需要计算梯度,可以省内存、加速。 -
•
net.eval():切换到评估模式,关闭 Dropout 和 BatchNorm 的随机性。 -
•
net.train():评估完切回训练模式,保证后续训练正常。
特别注意
虽然 LeNet 本身没有 Dropout,但养成eval()/train()切换的习惯很重要。等你后面用更复杂的模型时,这个习惯能帮你避免很多诡异的 bug。
6.2 训练函数
接下来是核心的训练函数:
def train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print('training on ', device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec' % (
epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))训练流程的每一步:
1. 数据移到 GPU:X.to(device) 和 y.to(device)
2. 前向传播:y_hat = net(X),得到预测结果
3. 计算损失:l = loss(y_hat, y),这里我们选择的是交叉熵比较预测和真实标签
4. 清空梯度:optimizer.zero_grad(),防止梯度累加
5. 反向传播:l.backward(),计算每个参数的梯度
6. 更新参数:optimizer.step(),用梯度下降更新权重
这个六步流程,是 PyTorch 训练的万能模板。理解了这六步,你后面跑任何模型都是这个套路。
6.3 启动训练
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)-
• 学习率lr设置
0.001,Adam 优化器,这是比较稳妥的默认配置。 -
• 训练 5 个 epoch,在 我的8G显存GPU 上大概十几秒就能跑完,没有GPU也能很快跑完。
预期输出:
training on cuda
epoch 1, loss 1.8146, train acc 0.338, test acc 0.579, time 2.1 sec
epoch 2, loss 0.4753, train acc 0.631, test acc 0.673, time 1.7 sec
epoch 3, loss 0.2591, train acc 0.709, test acc 0.706, time 1.8 sec
epoch 4, loss 0.1748, train acc 0.732, test acc 0.734, time 1.7 sec
epoch 5, loss 0.1291, train acc 0.748, test acc 0.744, time 1.7 sec5 个 epoch 下来,我测试的准确率大概在 74% 左右。这个成绩不算高,但考虑到 LeNet 是 1998 年的架构,而且我们只有 5 个 epoch,这个表现已经不错了。
七、尺寸变化详解
很多同学对卷积和池化后的尺寸变化感到困惑,我们可以手动来算一遍。
假设输入是 (batch_size, 1, 28, 28):
|
层 |
操作 |
输出尺寸 |
|---|---|---|
|
输入 |
- |
(N, 1, 28, 28) |
|
卷积 1 |
Conv2d(1,6,5), 无 padding |
(N, 6, 24, 24) |
|
池化 1 |
MaxPool2d(2,2) |
(N, 6, 12, 12) |
|
卷积 2 |
Conv2d(6,16,5), 无 padding |
(N, 16, 8, 8) |
|
池化 2 |
MaxPool2d(2,2) |
(N, 16, 4, 4) |
|
拉平 |
view(N, -1) |
(N, 256) |
|
全连接 1 |
Linear(256, 120) |
(N, 120) |
|
全连接 2 |
Linear(120, 84) |
(N, 84) |
|
全连接 3 |
Linear(84, 10) |
(N, 10) |
卷积后的尺寸计算公式:
输出尺寸 = 输入尺寸 - 卷积核大小 + 1因为没有 padding,所以每经过一次 5x5 卷积,宽高都减少 4。
池化后的尺寸计算:
输出尺寸 = 输入尺寸 / 池化核大小2x2 池化,步幅 2,所以宽高直接减半。
特别注意
如果你的输入尺寸不是 28x28,上面的计算就不成立了。比如你用 32x32 的输入,卷积后的尺寸会不一样,全连接层的输入维度也需要跟着改。这是很多新手容易踩的坑。
八、总结与延伸
8.1 本文回顾
我们跟着代码,完成了以下内容:
1. 理解了 LeNet 的整体架构(卷积层 + 全连接层)
2. 用 PyTorch 的 nn.Sequential 类搭建了模型
3. 加载了 Fashion-MNIST 数据集
4. 实现了训练和评估的完整流程
5. 手动推导了每一层的尺寸变化
8.2 可以继续尝试的
-
• 增加 epoch 数:5 个 epoch 明显不够,试试 20 个或 50 个,看看准确率能到多少。
-
• 换激活函数:把 Sigmoid 换成 ReLU,通常会有明显提升。
-
• 加 BatchNorm:在卷积层后面加
nn.BatchNorm2d,可以加速收敛。 -
• 换优化器:试试 SGD + Momentum,跟 Adam 对比一下效果。
-
• 可视化特征图:把中间层的特征图画出来,看看模型到底「看」到了什么。
8.3 下一步学习扩展
LeNet 是 CNN 的起点。建议下一步:
-
• AlexNet(2012):更深的网络,ReLU + Dropout,ImageNet 冠军
-
• VGGNet(2014):小卷积核(3x3)堆叠,结构非常规整
-
• ResNet(2015):残差连接,解决了深层网络的梯度消失问题
这些模型都是 LeNet 思想的延伸,理解了 LeNet,再看它们会轻松很多。
CSDN粉丝独家福利
这份完整版的 AI系统资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)