10条演示数据,超越pi0.5近24%!PriorVLA正在回答如何低成本完成高效后训练
近日,Neuracore AI CEO、RLBench 一作、前Dyson机器人技术负责人 Stephen James在X平台上发表了一个帖子。
主要观点是,“全量微调VLA正在摧毁你花预训练预算建立的那些先验知识”,同时也引出了一个名叫PriorVLA的模型(来自原力灵机和中科院自动化所),并剖析方法是如何轻成本微调,同时保留了先验知识。
这也引出了,行业对VLA的微调任务长期以来的态度和痛点。
把“预训练只是更聪明的随机初始化”来对待,是许多具身团队长期以来的处理方式。
一些团队开启全量微调,但往往一不小心,就很可能把预训练阶段砸进来的大额算力和资金投入,变成一场彻头彻尾的“知识拆迁”。
费尽心思,拿一个预训练好的VLA模型,准备在目标场景上大展拳脚。结果变成:在测试集(In-Distribution)上跑一跑,嗯,还行,能交差。但一拉到真实场景(Out-of-Distribution),模型拉胯到怀疑人生。
背后根本的原因,全量微调的本质还是一场暴力覆盖。
模型在预训练阶段中的浩瀚数据里练就了一身“见多识广”的本事,“世界观”非常宏伟。结果一微调,直接拿细分数据,把原有脑子里那些丰富的先验知识给“格式化”了。
客观上,模型确实学会了新任务,但它也把曾经学会的规律给忘得一干二净。
丢了西瓜,捡了芝麻的方式不可取。
“如何在适配时不遗忘先验”,是当下VLA领域中需要重点解决的问题。
01 大规模预训练的价值不能被“浪费”
模仿学习方案,预训练和基建是一个非常重要的存在,特别是相关数据集。从计算机视觉领域的ImageNet到具身领域的AGIBOT WORLD。
先行者们,总是在为领域提供各种各样的研究基石,没有Scaling,就没有通用泛化。
大规模预训练的价值不仅在于为下游微调提供优质初始化,更在于提供从观测信息到执行的广泛先验。
因为即使是预训练阶段,模型也能编码了许多结构化的知识。
对VLA亦是如此,真正有效的适配应当保留并利用这些先验。特别是在训练数据非常有限的下游任务,先验信息更能帮助模型处理OOD下的新观测,生成更加可靠的动作。
无论是从经济的角度,还是学习效果的角度上看,都不能浪费掉这样的信息。
具身的底层智能来自于大规模预训练
02 现有下游任务适配的方法真的靠谱吗?
然而,不少工作一旦在具体的场景中微调,多数都会把模型积累的经验都忘掉。
基于下游任务专属数据集训练的机器人操作策略,很难泛化到训练分布之外。最好的例子就是 Figure 03最近的包裹分拣直播,Figure 03 基本上只会抓取近处的包裹,这是比较典型的训练集场景拟合所展示出的效果。
那些全量微调的,分布内有些任务可以把准确率拉到90%以上甚至更高,只要数据足够多。然而,分布外的任务能力可能被拉到不足20%。
固定VLM,去调整动作expert的,之前已有动作先验信息则被丢失。曾经那些用来做饭的动作细节,对拧螺丝任务也是很有参考价值的。折衣服和折被单,许多动作可以通用。
我们希望通过已有的规律,去教VLA模型即使在很少的数据下,也能从容。
再看当下,依然缺少一种机制,既能保留先验,又能为适配策略提供可学习接口来使用这些先验。如何在动作生成中保留并利用预训练先验仍未被充分探索。
而上述博客中的PriorVLA则提供了一个不同的视角,这篇由原力灵机、中科院自动化所等机构联合提出的工作,不仅保存了这些先验信息,还基于这些先验,做有效适配。
论文链接:https://arxiv.org/pdf/2605.10925
项目链接:https://priorvla.github.io/

03 PriorVLA的破局:留住“场景”与“动作”双先验
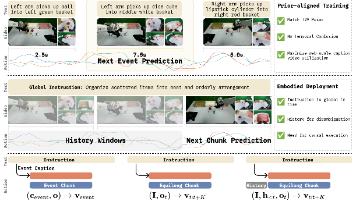
面对全参微调、LoRA、冻结VLM三条路径,PriorVLA提出了第四种范式:把预训练模型当作"只读先验库"持续调用而非一次性起点。
不同于之前的方案,PriorVLA选择了保留VLM和动作expert的先验信息,并基于这些先验信息做适配学习。
把场景先验和动作先验信息都输入到模型中,最终得到新的action。两个action expert(双动作专家),一个冻结提供前向先验信息,一个自适配学习。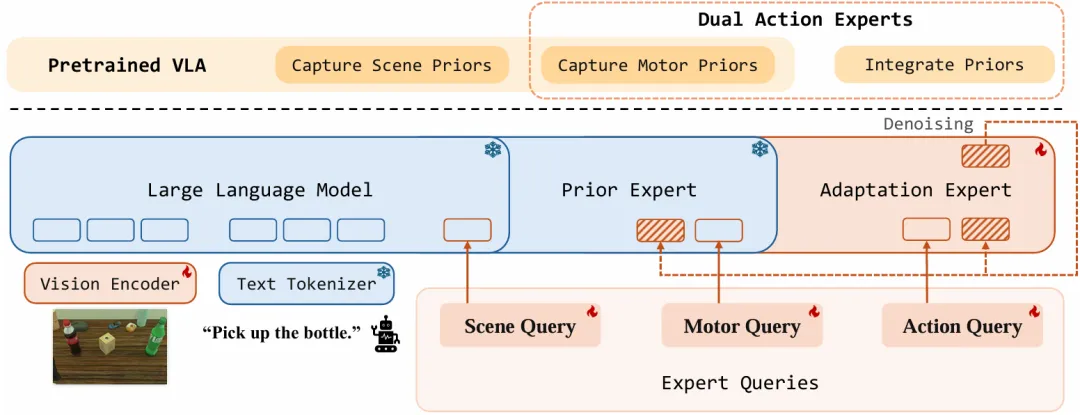
PriorVLA网络结构
这种设计把「保留先验」和「适配任务」拆开处理。
传统全参数微调中,模型既要保存过去的能力,又要学习新任务,两件事混在同一套参数更新里。PriorVLA 让冻结分支稳定提供已有先验,让可训练分支专注于下游任务学习。
那个被遗失的信息,这次被重新用起来了。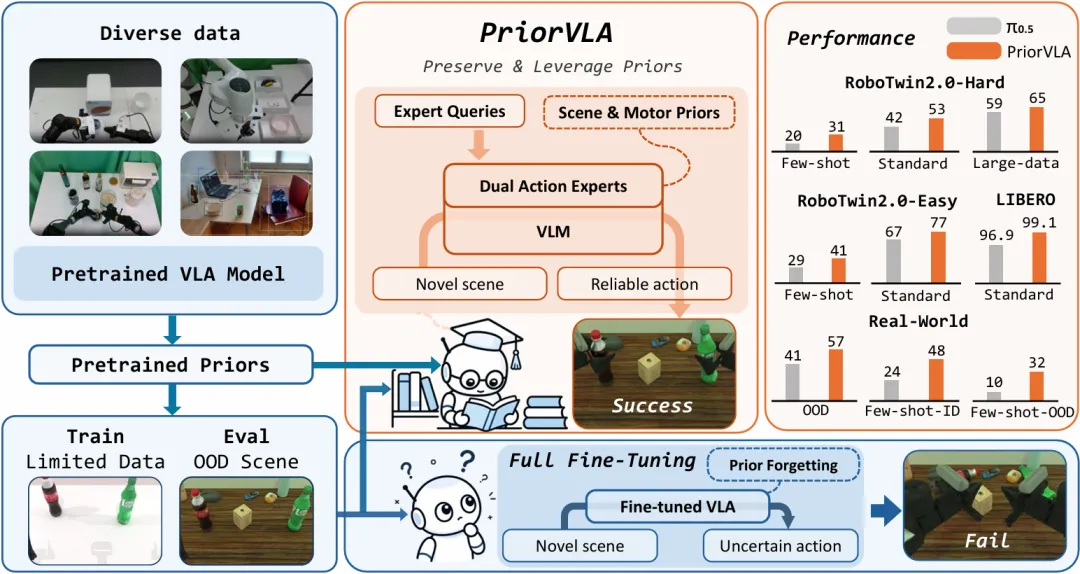
PriorVLA全流程一览
如果只看数字,PriorVLA仅需更新全量微调所需参数的25%,整体性能即可优于全量微调和当前最优的 VLA 基线。
RoboTwin 2.0 上,PriorVLA 在大多数任务上超过pi0.5,特别是在Hard OOD上。这也验证了,保留和利用预训练先验可以提升泛化能力。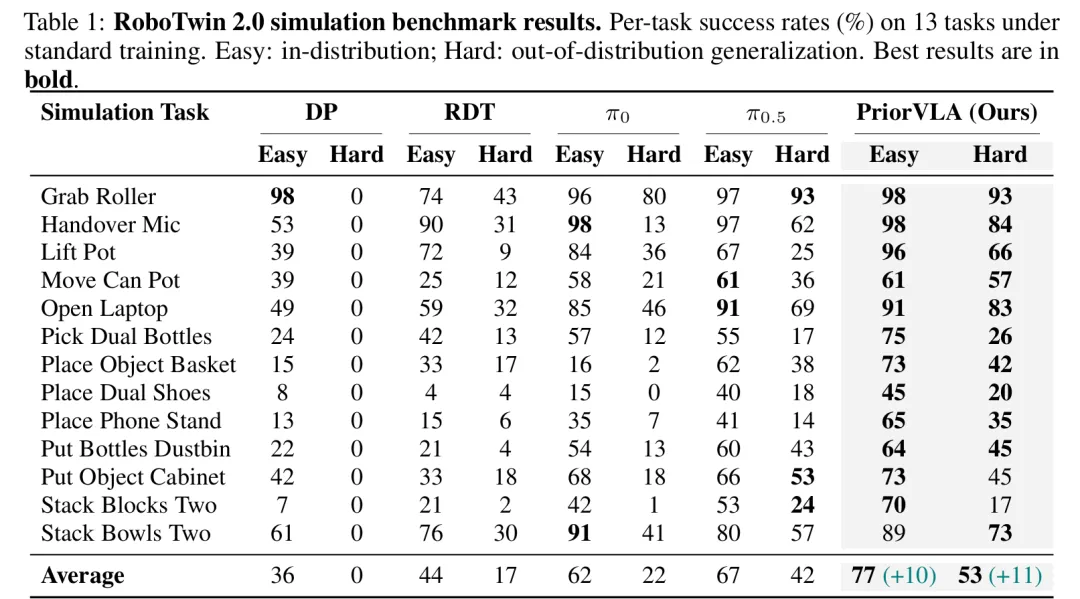
LIBERO 上平均成功率更是达到99.1%!
然而,最该关注的并不是99.1%的指标,而是仅用10条示范数据,在小样本下就能比π0.5高出22-24个百分点。
机器人每换一个新场景,就要采集成百上千条数据的高昂成本的故事被改写了,下游数据有限时,PriorVLA方式提升更显著。
这也让交付边际成本和回本周期大幅降低,多场景的可复制能力也进一步被提升。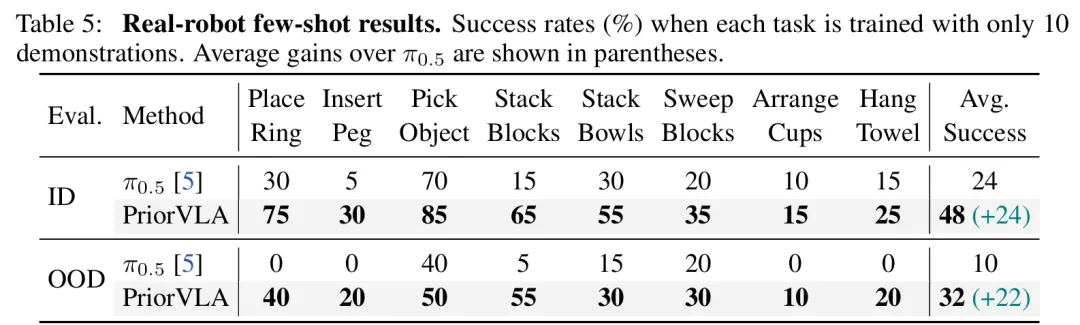
在8 个真实世界任务与两种机器人平台上,使用标准数据时 PriorVLA 达到81%分布内(ID)成功率与57%分布外( OOD) 成功率。该维度上的对比,相比于pi0.5提升了10多个点。
这也说明,PriorVLA的提升可以迁移到跨平台的机器人上。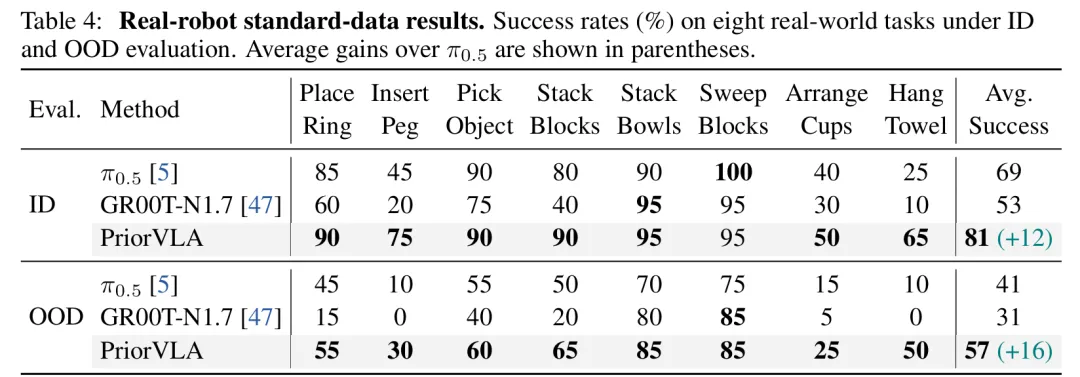
消融实验也证明增益确实来自预训练学到的真知识,而非多挂网络模块,预训练是可反复支取的长期资产。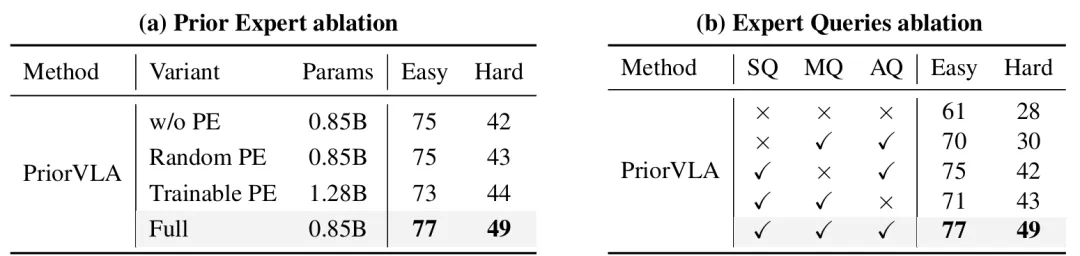
04 它在回答一个什么问题?
大规模VLA预训练是行业最贵的投入,但全参数微调在落地时把模型当"初始权重"推倒重学,导致预训练积累的通用能力在每次客户交付中被悄悄"折旧"——分布内表现亮眼,一换场景就崩。
PriorVLA要回答的是:能不能既适配客户,又不浪费预训练资产?
当下,业界要么抱紧开源的模型或者闭源的预训练模型做微调,喂大量数据适配下游任务。而PriorVLA提供的思路是:“只给模型几张数据,同时还能把预训练时攒下的家底全拿出来,泛化和专精都有”。
换句话说,就是给“高效后训练”重新写个定义。
给出的答卷也非常nice,不仅用极低的代价跑出了高性能,还顺带把基模与生俱来的泛化能力给“盘活”了,让模型在下游任务里执行得更稳、更鲁棒。
正所谓,“花小钱,办大事”。
重磅!
全网首个!具身智能开源知识库来啦(技术/产业/投融资/上下游)
推荐阅读
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
1v1 科研论文辅导来啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)