本地无限Token!8G显存成功跑 Qwen3.6-35B AI大模型!附部署教程
大家好,这里是硅谷茶馆。
最近本地大模型圈子出现新玩法了:手头只有8G-12G显存的老卡,还能玩上最新最强的开源模型吗?
翻出来我的8G显卡,实测了Qwen3.6-35B这个MoE架构的新模型。结果让我惊喜:不仅成功跑通,还接入了Hermes搭建本地全能助手。视觉能力在某些场景下表现突出,生成速度也比较稳定。今天就把这套经过验证的方案分享给大家。

一、为什么低显存也能跑35B?
Qwen3.6-35B采用MoE(混合专家)架构,总参数35B,但每次实际只激活约3B左右的参数,相当于跑一个“超大号轻量模型”。再配合llama.cpp的异构推理,把部分计算卸载到系统内存,就能大幅降低对显存的需求。
我用8G显存+32G内存,日常使用完全可行。模型还支持原生256K超长上下文,特别适合做Agent和长对话。
二、实际表现如何?
它生成带简单特效的前端代码时,逻辑也比较完整,直接可用。据测试,Qwen3.6在某些Agent评测中表现优秀,速度比前代有明显提升。开源模型这次确实进步很大,让我们这些普通硬件用户也能享受到接近顶流的体验。
保姆级部署流程(Windows环境)
硬件建议:
-
NVIDIA显卡,8G-12G显存(3070、4060等)
-
内存32G或以上
-
Windows 10/11系统
三、实操部署
第一步:安装llama.cpp
按Win+R打开cmd,输入以下命令安装(Windows系统):
winget install llama.cpp
第二步:下载模型
在cmd中输入下面指令自动下载(约20G):
llama-server -hf Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF:Q4_K_M
模型会下载到默认缓存路径:C:\Users\你的用户名.cache\huggingface\hub,如果磁盘不足,可以安装到D盘某个路径下,例如:
$env:HF_HOME = "D:\AI\huggingface_cache" $env:LLAMA_CACHE = "D:\AI\llama_cache" llama-server -hf Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF:Q4_K_M
指定加载模型路径:
llama-server --models-dir D:\AI\ggufModels -hf Abiray/Qwen3.6-35B-A3B-Q4_K_M-GGUF:Q4_K_M
第三步:启动模型
下载完成后,输入以下命令启动Web界面:
llama-server -m "你的模型完整路径\Qwen3.6-35B-A3B-Q4_K_M.gguf" --webui
看到提示“server is listening on http://127.0.0.1:8080”时,在浏览器打开这个地址即可使用。
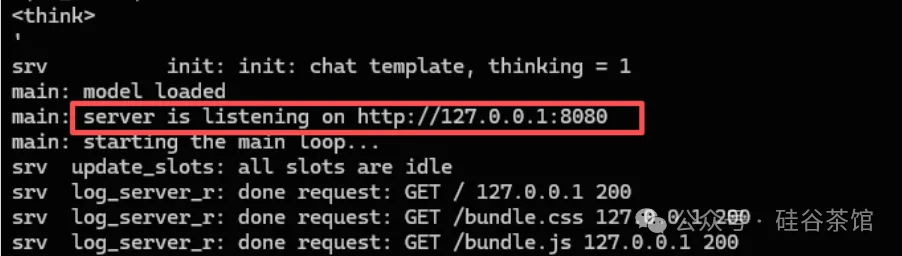
在浏览器打开就会启动模型页面:
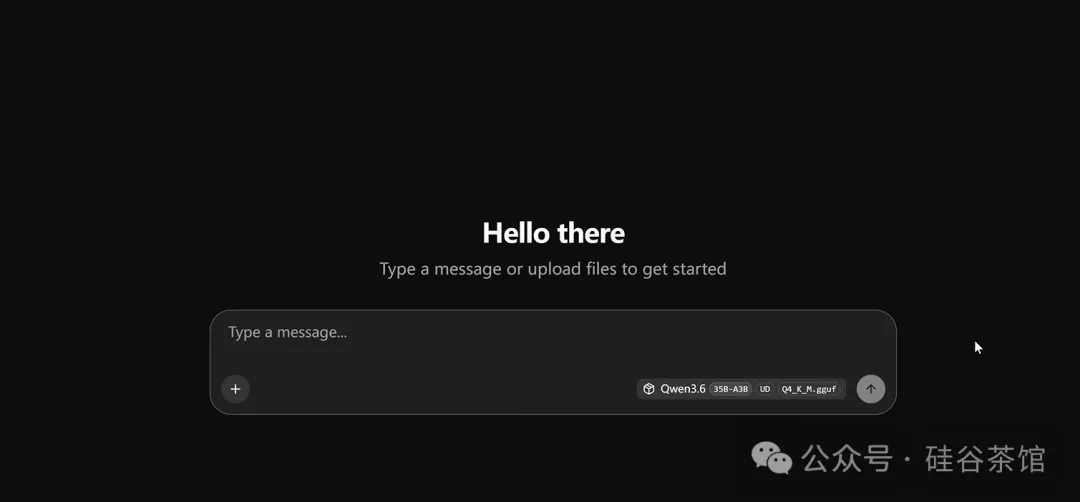
**推荐启动脚本(更稳定):**在llama.cpp目录新建start_ai.bat文件,内容如下(修改路径):
@echo off
chcp 65001 >nul
cd /d "你的llama.cpp路径\bin\cuda"
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Q4_K_M.gguf" ^
-ngl 99 ^
-ncpu-moe 999 ^
-flash-attn on ^
-c 32768 ^
-t 12 ^
--mlock ^
--host 127.0.0.1 ^
--port 8080
pause
关键参数说明:
-
-ngl 99:尽量使用GPU
-
-ncpu-moe 999:把专家层放到内存,适合低显存
-
–mlock:锁定内存防卡顿
第四步:接入Hermes搭建助手
启动后,你可以在Web界面直接聊天。如果想玩Agent系统,可以接入Hermes等工具,把模型变成本地全能助手,支持更复杂的任务链。
hermes接入本地模型的方法可以看我之前文章
告别Token焦虑!本地部署Hermes + Qwen3.6,打造你的私人AI助理
使用小贴士
-
首次加载需要耐心等待1-2分钟。
-
显存紧张时可适当降低上下文长度。
-
模型文件建议从Hugging Face可靠来源下载,版本以官方最新为准。
-
生成速度受硬件影响,8G显存下大概15-25 tokens/s,够日常使用。
过去高性能AI似乎是高端配置的专属,现在通过优化,本地部署门槛越来越低。一张二手老卡+足够内存,就能拥有隐私安全、随时可用的强大助手。
写在最后:
如果你也想试试,欢迎在评论区分享你的配置和遇到的问题,我看到会回复解答。
科技的乐趣,就是把前沿工具变成每个人都能上手的东西。如果对茶馆的分享感兴趣欢迎点赞、转发、关注,感谢大家!!!
(文中路径和参数请根据实际情况微调,llama.cpp版本更新较快,建议参考官方文档。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)